
融合低阶特征与全局特征的图像语义分割方法
2021-09-07 00:48董立红李宇星符立梅
计算机工程与应用 2021年17期
董立红,李宇星,符立梅
西安科技大学 计算机科学与技术学院,西安710600
图像语义分割是计算机视觉领域中的一项基本任务。其主要目标是通过某个特定的算法,将输入的整幅图像分割成多个具有特定含义的像素区域块,并对每个像素区域标注特定的语义标签,最终得到一幅像素级的语义分割图像[1]。目前,在图像语义分割方面的研究特别广泛,自动驾驶、遥感测绘、人机交互和医疗影像分割等领域都有深入的研究与应用[2-3]。例如,在自动驾驶领域,车体配备有图像采集装置,通过对采集到的图像进行语义分割,精确定位车辆、道路、建筑物等目标,辅助驾驶系统做出正确的决策,从而提高驾驶之安全性。
随着深度学习的兴起,基于卷积神经网络(Convolutional Neural Network,CNN)的图像语义分割方法取得了突破性的成就。卷积神经网络能够自动地从图像中学习像素的特征表示,有效减少了人工提取特征的工作量。通过在大量的图像样本中反复训练,可以学到深层的语义特征。近年,基于全卷积的图像语义分割算法得到了快速的发展[4-7],为计算机视觉领域的发展带来了新的契机。
2015年,Long等人[4]提出的全卷积神经网络(Fully Convolutional Networks,FCN)用卷积层替换了分类网络的全连接层,然后通过上采样将特征图扩展到原始尺寸,实现了像素到像素的类别预测,然而经过多次连续的卷积池化操作后使得特征图的分辨率降低,导致上下文信息丢失。Kendall等人[8]提出的SegNet网络是一种基于“编码器—解码器”的结构。编码过程中,通过卷积层提取特征,利用池化法扩大感受野。在解码过程中,通过相应编码器在最大池化过程中存储的索引来进行非线性上采样,减少了对上采样过程的学习,虽然在一定程度上降低了时间复杂度,却以牺牲分割精度为代价。Chen等人[9]提出的DeepLab网络采用了空洞卷积层,在不增加参数的同时扩大感受野,可以更出色地提取全局信息,结合马尔科夫随机场的概率模型以提高分割图的边界信息来提升精度,但将不同尺度的特征图裁剪成相同尺度后进行简单求和,容易造成局部区域误识别。并且这些方法也没有充分利用全局信息来提升语义分割结果。
本文设计了一个用于图像语义分割的深度全卷积网络,该网络采用了“编码器—解码器”的结构,编码器前端通过下采样来减少模型参数以加深网络深度;编码器后端通过空洞卷积替换传统的卷积下采样组合来缓解因多次下采样造成的信息损失;加入了低阶特征融合模块将浅层语义信息融合到解码过程来精细化边缘信息;通过引入全局特征融合模块来提升模型的感知能力。
1 相关理论与方法
1.1 基于全卷积神经网络的语义分割方法
一个全卷积神经网络模型如图1所示。

图1 全卷积神经网络模型Fig.1 Fully convolutional neural network model
(1)输入层。若干张图片组成的像素矩阵。
(2)卷积层。组成卷积神经网络的重要部分。一个卷积层由多个尺寸相同的卷积核构成,每个卷积核经过多次迭代后学习到图像的不同特征参数。学习过程可以表示为:

其中,x代表卷积层的输入,y代表卷积层的输出,w为卷积核,⊗为卷积运算操作,b为偏移量,f(⋅)为非线性激活函数。
(3)池化层。池化层又称为聚合层,用下采样的方法将前一层特征图中一定邻域内的特征值在本层特征图中用一个特征值表示,即用一个像素值来代表一个邻域内的像素信息。在多层卷积运算中,会产生大量的可学习参数,采用池化的方法可以降低参数数量,从而降低学习代价。在连续的下采样过程中,可以逐渐扩大感受野,随着感受野的扩大,卷积核所覆盖的特征范围越大,可以学习到的全局特征范围也越大。目前常用的池化法主要有平均池化法(Average-Pooling)和最大池化法(Max-Pooling),平均池化法是用本层特征图中一个特征值表示对应上层特征图中一定领域内特征的平均值,最大池化法是用本层特征图中一个特征值表示对应上层特征图中一定领域内特征的最大值。
(4)上采样层。上采样是一种使图像变成更高分辨率的技术,此处的主要目的是将特征图逐层恢复至输入图像尺寸。
(5)输出层。输出具有像素级的语义分割图像。在图像分割任务中,常见的输出层为Softmax层。它把所有输入映射为0~1之间的实数,并保证这些值的总和为1,第i类特征的概率定义为:

特征值越大的类,输出的概率值越大。最后取最大输出值的类标签作为预测类标签。
1.2 批归一化
批归一化(Batch Normalization,BN)是Ioffe等人[10]在2015年提出的,该方法保证了网络中数据传输的一致性。特别在较深的神经网络模型中,训练过程容易出现“梯度爆炸”“梯度消失”的现象,导致训练结果难以收敛。批归一化在一些网络模型[11-12]中表现出了良好的性能,加快了模型的训练,提高了模型的泛化能力。
神经网络中每层的特征分布在训练过程中会不断变化,使得网络训练困难。归一化方法标准化了每层的均值与方差,使网络中任何一层参数学习到的都是比较稳定的分布,从而提高网络的训练速度。对于给定一批特征图x∈RN×C×H×W,公式如下:

其中,μ(x)、δ(x)是特征图的均值和标准差,γ和β是数据优化的仿射参数。通常,批量归一化方法在批量较大、数据分布相近的情形下作用更加明显。
1.3 空洞卷积
空洞卷积(Dilated Convolution)又称膨胀卷积,由Yu等人[13-14]提出,空洞卷积可被视为一种特殊的卷积操作。在图像语义分割领域中,输出的标签尺寸需要同输入图像保持一致,而深度卷积网络结构中都包含有多次下采样操作,随着网络的加深语义信息更加抽象,但是在这个过程中不可避免地损失了大量的细节信息,且不可恢复。空洞卷积在一定程度上缓解了这个问题,在不降低特征图分辨率的同时扩大了感受野,并且不会增加卷积核的可学习参数。
在一维情形中,公式可表示为:

其中,一维卷积核为w[n],n为卷积核长度,y[i]为空洞卷积的输出,r对应了输入的采样步长,其值为1时即标准卷积。二维情形如图2所示。

图2 空洞卷积感受野Fig.2 Receptive field of dilated convolution
图2中的(a)对应了大小为3×3,步长r为1的卷积核,即标准卷积核。(b)对应了大小为3×3,步长r为2的卷积核。此时卷积核大小实质上仍为3×3,但空洞为1,即对7×7的区域只有9个点参与了运算,其他点可视为对应的卷积核权重为0。所以在步长r为2的情况下,大小为3×3的卷积核将感受野扩展到了7×7。
1.4 反卷积
反卷积(Deconvolution)由Zeiler等人[15]于2010年提出,在图像语义分割领域中主要用来上采样。反卷积运算是卷积运算的逆过程,即反卷积运算的前向传播过程即为卷积运算的反向传播过程,所以也可以视反卷积的相乘矩阵为卷积的置换矩阵,故也常称作置换卷积。反卷积运算可以增大特征图的分辨率,扩大感受野。
反卷积过程如图3所示,输入特征图尺寸为3×3,卷积核大小为3×3,步长为2,填充为1,计算得到的输出特征图大小为5×5。公式如下:

其中,i为输入,o为输出,s为步长,k为卷积核大小,p为填充。
2 融合低阶特征与全局特征的图像语义分割
在图像语义分割领域,深度全卷积网络通常需要进行多次连续的下采样操作,在下采样过程中特征图的分辨率不断降低,最终导致大量的语义特征信息丢失,容易造成分割精度的损失。针对这个问题,本文方法基于深度全卷积网络进行改进,融合低阶语义信息和全局语义信息进行图像语义分割,使得分割结果更加精细,有效提高分割精度。
2.1 低阶特征融合模块设计
在基于深度学习的图像语义分割任务中,融合低阶特征是提高分割性能的一种重要方法。低阶语义信息通常在深度网络的前几层,经过的卷积和下采样操作比较少,相较高阶语义特征而言,其语义性低,但分辨率高,存在丰富的边缘纹理等低阶信息。而高阶特征虽有更抽象的语义特征,但经过多次卷积和下采样操作降低了分辨率,缺乏低阶特征的细节信息。
通过设计一个简单的特征融合方案,对每次下采样前产生的低阶语义特征进行降维保存,然后将这些不同分辨率的低阶特征融合到每次上采样后对应分辨率的高阶特征上,然后通过卷积和上采样继续对融合后的特征图进行运算,直到特征图恢复至初始分辨率大小。为了达到更好的融合效果,本文采用了特征图通道叠加的方法进行融合。
在网络解码器端得到的融合特征既包含了低阶语义信息又包含了高阶语义信息,相较于只经过编码器和解码器提取的特征,融合低阶语义特征后可以提供更多的细节信息,有利于提高分割精度,如图4所示。

图4 低阶特征融合模块Fig.4 Low order feature fusion module
2.2 全局特征融合模块设计
在以往的研究中[16],卷积神经网络在提取高阶特征信息的任务中展示了良好的性能,对经过多层卷积操作提取的高阶语义信息进行分类时经常会丢失一部分全局信息,容易使目标的边缘部分或者复杂场景中的物体出现误分类。
全局特征可以进一步提高网络模型对场景的感知能力,从而提高模型的分割性能。全局结构主要以特征图的全局信息为特征,在逐像素分类过程中起到一定的作用。如图5所示,本文引入了一个全局特征融合模块,其由池化层和卷积层共同构成。全局池化层对输入大小为C×H×W的特征图的每个通道都进行了全局池化,形成大小为C×1×1的全局特征图。其中,C为特征图的通道大小,H为特征图的高度,W为特征图的宽度。

图5 全局特征融合模块Fig.5 Global feature fusion module
C×1×1的全局特征图包含了所有通道的全局信息,然后用1×1的卷积运算降低全局特征的通道数,并通过复制特征值的方法对全局特征的每个通道扩张分辨率,最后将学习到的全局特征融合到解码器产生的高阶特征当中。
2.3 总体结构
本文的网络架构由一个16层的编码器和一个10层的解码器组成,对网络输出的特征图进行逐像素分类。同时,通过引入低阶语义融合模块将编码阶段产生的不同分辨率下的低阶特征融合到解码过程,补充浅层特征以精细化特征图目标的边缘信息,并且在网络中引入了全局特征融合模块,进一步提高网络模型对场景的感知能力。所以,整个网络是26层的全卷积网络结构,其结构如图6所示。

图6 融合低价特征与全局特征的网络结构Fig.6 Network structure with fusion of global and low order features
在该网络的16层编码结构中,前8层采用了VGG-19[17]的前8层卷积层,每一组卷积核将前一部分的输出进行卷积操作生成一组特征图,卷积操作均采用了大小为3×3的卷积核。为了维持数据传输过程的一致性,将每层卷积生成的特征图通过BN层进行批正则化处理,接着再通过修正线性单元(Rectified Linear Unit,ReLU)进行非线性映射。在下采样过程中采用了核大小为2×2,步长为2的最大池化法来扩大感受野,为保存边缘信息,采用了边缘扩充的方法。经过3组连续的卷积池化操作将特征图大小降低到了原始分辨率的1/8。同时,低阶语义信息提取模块将每组池化前的特征图通过1×1的卷积核将维度降低至原来的1/4作为低阶语义信息,以期融合到解码过程。
编码器后8层使用了8层空洞卷积进行特征提取。由于池化层对特征图进行降采样后,虽然在一定程度上扩大了感受野,但每经过一层池化操作特征图尺寸就会缩小为原来的1/2,多次池化后会使图像的细节信息严重损失。为了缓解这个问题,故而采用空洞卷积在不降低特征分辨率的同时来扩大感受野。为了不因空洞卷积采样步长过大而过多地损失细节信息,本网络将前4层空洞卷积层的采样步长r设为2,后4层的采样步长r设为4。然后将前四层空洞卷积层的输出与后四层空洞卷积的输出按1∶1进行融合作为编码器的输出。经过多层空洞卷积后能有效获取特征图的全局特征信息,用全局特征提取模块将编码器的输出进行全局平均池化,然后用1×1的卷积核进行降维,以期融合到最后的解码过程。
在解码过程中,本文方法采用了反卷积操作进行上采样,通过每次上采样将上一组输出特征图的尺寸扩展为原来的2倍,经过三次上采样操作将特征图尺寸恢复到原始输入尺寸。并且在每次上采样后,将低阶特征融合模块提取的低阶语义特征以维度扩展的形式融合到解码过程中对应尺寸的高阶语义特征图中,本文低阶特征与高阶特征的比例设为1∶4。最后将全局特征融合模块提取的全局特征融合到解码器后端,全局特征与高阶特征比例设为1∶8。并在表1中列出了网络主结构的配置参数。

表1 网络配置参数Table 1 Network parameter configuration
3 实验结果与分析
3.1 实验环境与数据集
为了节约时间,通过Google发布的tesorflow深度学习框架来构建网络。采用的GPU型号为RTX 2080Ti,该卡显存大小为11 GB,352位显存位宽与4 352个CUDA核心单元。实验环境的主要参数如表2所示。

表2 实验环境参数Table 2 Experimental environmental parameters
在本次任务中采用CamVid(Cambridge-driving labelled Video database)[18]数据集来训练网络。其中,标签图为单通道,每一个像素值对应了物体类别的ID号。将数据集中的所有像素区域共分成了11种目标的语义标签,即sky、building、pole、road、pavement、tree、signsymbol、fence、car、pedestrian、cycle。因此在本次实验中将对以上11种目标实现语义分割。
3.2 实验方案及结果分析
在训练网络时,为了增强网络的泛化能力,输入图像在第一层卷积前经过了局部响应归一化(Local Response Normalization)处理,α=0.000 1,β=0.75。通过使用学习率为0.001的Adam算法优化目标损失函数,并迭代至损失函数收敛。在训练过程中,训练数据集随机打乱,然后将每5个训练图像作为一个批次,即batchsize设为5。网络的目标函数选用了交叉熵损失(cross-entropy loss)函数,并在网络最后一层加入了L2正则化防止过拟合。由于数据集中各个类别的像素数量偏差较大,通过中值频率均衡法进行类间平衡处理。
实验评估过程中使用了如下的评估指标:全局平均精度(PA)和平均交并比(mIoU),公式如下:

其中,nij表示第i类像素被预测为第j类像素的数量,ncl表示目标的类别数,表示第i类目标的像素总数。
由于mIoU的代表性强,高效简洁,已经成为目前通用的语义分割评价指标,所以,将mIoU作为本实验主要的评价指标,而PA值作为mIoU的一个补充。
由于CamVid数据集比较小,为了防止在训练网络的过程中发生过拟合现象,通过裁剪和左右翻转的方法对其进行了数据增强。本次实验中数据集的语义类别总共分为11类,在测试过程中将分割出11种语义目标。经过50 epochs后停止训练,训练过程中验证集的mIoU值、平均像素精度和损失值的变化如图7所示。
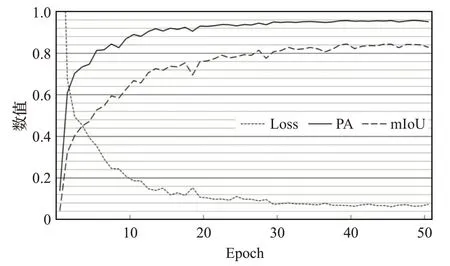
图7 mIoU、PA与Loss曲线图Fig.7 Curves of mIoU,PA and Loss
从图7中可以看出,网络训练到第12个epoch时mIoU值就达到了70%,迭代到27个epoch后mIoU达到了80%,在之后的训练中,mIoU虽然有非常缓慢的提升,但效果并不明显。PA值在网络迭代到37个epoch时就达到了95%。Loss值在网络迭代到21个epoch时降低到10%左右,在接下来的训练过程中,模型基本开始收敛。经过50个epoch迭代之后模型的mIoU达到了83%,PA值基本保持在了95%左右,Loss降低到了7%以下。
当网络在训练过程中精度不再显著提高后,用测试集对此时的网络模型进行测试,并使用PA和mIoU作为评价指标。将测试结果与近期文献所提的一些网络结构[19-23]进行了比较,各方法评价结果的具体数值如表3所示。结果表明本文方法的mIoU值高于当前大多方法,并且PA值也达到了90%,特别在区域平滑方面有很好的性能。

表3 与其他网络的比较Table 3 Comparison with other networks %
同时为了测试本文各个模块的性能,在表4中列出了消融实验的结果,D表示加入了空洞卷积,L表示为融合低阶语义特征,G表示为融合全局语义特征。

表4 消融实验测试结果Table 4 Ablation experiments %
从表4可以看出,本文所使用的各模块都能对分割精度提升起到一定的作用,各模块相互组合可以进一步提高网络的分割结果。当所有改进模块联合训练时,测试结果最终达到了90.14%的PA值和71.95%的mIoU值。加入空洞卷积后网络结构变深,可以提取更加丰富的高阶特征,并且没有降低特征图的分辨率,保留了更多的特征信息。融合低阶语义特征后,结合丰富的边缘纹理等细节信息,使分割结果的边界更加精确。在分割特征图时融合全局特征信息后提高了模型的感知能力,可以有效降低误分类的概率。实验表明,融合低阶特征和全局特征的深度全卷积网络可以在输入图像中预测出更加平滑的像素级标签,深层网络架构可以有效提高图像语义分割精度。
最后,图8展示了本文设计的网络在训练了50个epoch后得到模型在测试集上分割的结果。其第一行为输入图像;第二行为手工标注图;第三行为本网络分割结果。在CamVid数据集中,地面、天空、建筑物等大型目标在图像中占据了很大的比例,对这些目标的分割效果极大地影响着全局分割精度。

图8 CamVid测试集上的分割结果Fig.8 Results on CamVid test dataset
4 结束语
本文设计了一个用于图像语义分割的26层深度全卷积网络。该网络基于“编码器—解码器”的结构,采用了空洞卷积来降低信息损失,并且设计了低阶特征融合模块和全局特征融合模块通过融入低阶语义信息和全局语义信息来提升分割精度。最后,在CamVid数据集上进行了训练和测试。实验结果表明,在样本数量充足的情况下,本文的网络可以很好地学习图像特征,并且准确保留图像的边缘信息,特别在区域平滑方面有很大的提升。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
矿产勘查(2020年11期)2020-12-25
开放教育研究(2020年2期)2020-03-31
数学物理学报(2019年3期)2019-07-23
金桥(2018年4期)2018-09-26
数学物理学报(2018年3期)2018-07-17
现代语文(2016年21期)2016-05-25
中国煤层气(2015年3期)2015-08-22
大连民族大学学报(2015年2期)2015-02-27
