
无人机平台下的行人与车辆目标实时检测
2021-09-07 00:48黄梓桐阿里甫库尔班
计算机工程与应用 2021年17期
黄梓桐,阿里甫·库尔班
1.新疆大学 软件学院,乌鲁木齐830046
2.新疆大学 软件工程技术重点实验室,乌鲁木齐830046
近年来,随着摄影技术和航空技术的飞速发展,无人机已经大量应用在生活中的各个方面,比如:抢险救灾、军事侦察以及交通管制等[1],特别是在处理危险事件的过程中,起着至关重要的作用。这使得无人机地面目标检测技术成为计算机视觉领域的重要研究方向。
传统的目标检测算法首先需要手动设计图像特征如HOG[2](Histogram of Oriented Gradient)或SIFT[3](Scale-Invariant Feature Transform),然后使用支持向量机(Support Vector Machine,SVM)[4]或AdaBoost[5]进行训练。这需要丰富的经验和完整的先验知识。此外,以这种方式训练得到的检测器大多数只在特定的环境中有效,因此它们的泛化能力比较差。随着深度学习在图像分类与识别领域的快速发展,使用卷积神经网络来进行目标检测已经成为研究热点[6]。
目前,基于深度学习的目标检测算法主要有两种:基于候选区域的目标检测算法和基于回归的检测算法。其中基于候选区域的检测算法属于两阶段算法,首先根据不同的区域选择算法(如BING[7])从图像中选出很多个感兴趣区域ROI(Region of Interest),然后通过卷积神经网络对感兴趣区域进行自动特征提取,再进行分类和检测。2014年,Girshick等[8]提出R-CNN算法,该算法使用卷积神经网络提取图像特征,提高了检测精度,但是其区域选择算法使用的是selective search,对于一幅图使用selective search选2 000个候选区域,这个过程本身就比较慢再加上这2 000个区域都要使用卷积神经网络进行特征提取就更慢了,同时这些区域还有很多重叠部分。此外,R-CNN也使用了SVM,导致算法训练和检测效率较低。基于R-CNN的不足,2015年Girshick[9]提出Fast R-CNN,该算法将R-CNN中的图像特征提取、目标分类识别和定位三个独立的模块整合在一起,提高了检测速度,但仍然无法满足实时需求。同年,Ren等[10]提出Faster R-CNN,该算法去掉了selective search,并使用区域候选网络(RPN)作为代替,使得检测速度大幅度提升。可以看出,以R-CNN家族为代表的基于候选区域的目标检测算法虽然精度很高,但是实时性比较差。而基于回归的一阶段检测算法在速度方面更有优势。2016年,Redmon等[11]提出YOLO目标检测算法,该算法使用单个前馈神经网络直接预测对象的位置和类别,其速度明显比二阶段网络快。2016年,Liu等[12]提出SSD算法,该算法融合了YOLO和Faster R-CNN的思想,使得该算法兼具YOLO的速度和Faster R-CNN的精度。2018年,Redmon等[13]提出YOLOv3算法,借鉴了SSD在不同特征图上进行预测的思想,并引入了残差层和跳跃连接,其检测速度和精度大幅度提升。
上述目标检测算法的提出,为无人机目标检测技术的实际应用提供了更多的可能。目前,国内外已经有很有学者针对无人机目标检测进行了研究。Gaszczak等[14]提出了一种基于多个分类器的车辆自动检测方法,并在热图像中进行了二次确认。Zhang等[15]通过对YOLOv3的卷积层进行剪枝来学习高效的目标检测器,从而实现快速高效的无人机目标检测。李斌等[16]针对无人机目标小且环境复杂的问题,提出一种基于深度表示的复杂场景无人机目标检测方法。姜尚洁等[1]搭建了小型无人机视频采集平台,使用YOLO算法进行车辆检测,实现了车辆的自动检测,并优化了检测结果。裴伟等[17]针对无人机目标检测分辨率低、遮挡、小目标漏检、重复检测、误检等精度低下问题,提出一种基于残差网络的航拍目标检测算法,修改了SSD的主干网络,并引入特征融合机制,在检测的准确性和实时性方面均具有不错的表现。但是上述算法在实时性和准确性方面仍有较大的改进空间。
本文主要针对无人机目标检测实时性的需求和现有模型检测精度不高的问题,以SSD算法为基础,设计了轻量级的基准网络来满足实时性要求,同时提出轻量级感受野模块和上下文模块来提高小目标检测精度。实验结果表明,该方法在无人机小目标检测任务中具有良好的检测精度和实时性,可以更好地应用到检测服务中。
1 算法框架
本文以SSD算法为基础,设计了一种轻量级的基准网络,并加入了轻量级感受野模块和上下文模块来提高小目标检测的准确性和实时性。算法的具体网络结构如图1所示。

图1 本文算法的网络结构图Fig.1 Network structure of proposed algorithm
1.1 轻量级骨干网络
近年来,卷积神经网络(CNN)已经成为研究各种计算机视觉任务的主要手段,如图像分类[18]、目标检测[19]和图像分割[20]。大规模的数据集和高性能GPU使得CNN模型可以很大。例如在ImageNet图像分类大赛中,从8层的AlexNet[18]模型已经演变到100多层的ResNets[21]。虽然越深的网络层次表示能力越强大,但是随着网络层数的加深,对计算资源的需求也在不断变大。例如152层的ResNet具有超过6 000万个参数,VGG16[22]的模型大小有533 MB,VGG19更是达到了574 MB。而在资源受限的移动设备上很难进行这样的计算,使其在实际应用中使用是不现实的。综上所述,本文基于SSD(Single-Shot Detector)设计了轻量级的骨干网络,目的是为了降低模型复杂度,减少计算量,从而提高无人机平台下小目标检测的速度和精度。
本文提出的轻量级骨干网络主要基于以下3点事实:(1)SSD最初是在Pascal VOC和MS COCO数据集上进行训练的,其中Pascal VOC有9 963张图片和20种类别的待检测目标,而MS COCO的图像数量达到328 000张,包括了91类目标。所以,深度网络才能更好地进行分类和检测。而本文所用的数据只包含行人和车辆这两个类别,且图片数量相对较少,太深的网络层数会使得模型很难训练,并且容易产生过拟合。(2)SSD用在每个特征图上预先定义好的不同大小的默认框来预测目标的类别和得分,浅层特征图用于检测最小的物体,深层特征图用于检测相对较大的物体。与以上两种数据集不同的是,无人机图像中的行人和汽车都是小目标。所以原始SSD的设置并不适合小目标检测。(3)传统图像中待检测目标较大且居于图像中心位置,与背景差异明显,而无人机图像中待检测目标很小,图像中包含多种物体,背景复杂,同时CNN所能提取到的小目标特征很少。此外,原始SSD没有很好地利用上下文信息,而大量实验证明[23-24],上下文信息能够有效地提高小目标检测效果。
针对以上事实,本文主要做了3点改进:(1)为了适应小型移动设备设计了轻量级的骨干网络,降低了训练难度和参数量。另外,只选择了4个检测层并为每个检测层设置了恰当的默认框参数。(2)为了增强高分辨率特征图对小目标的特征表示能力,在Conv4后添加了轻量级感受野模块(LRFB)。(3)为了进一步提高小目标的检测能力,在Conv5后添加了上下文模块(CIM)。
本文提出了如图1所示的轻量级网络,网络的详细信息如下:
(1)骨干网络。为了更适用于移动设备,重新设计了卷积层的数量,仅仅使用6个卷积层,并且通道数最大为128。具体参数如表1所示。
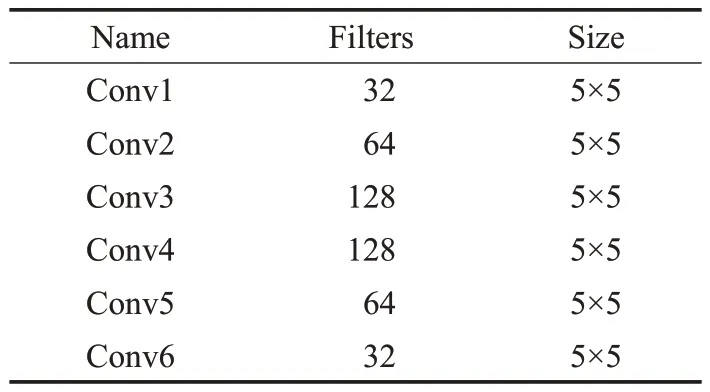
表1 骨干网络参数Table 1 Parameters of backbone network
(2)检测层。选择Conv3、LRFB、CIM和Conv6作为检测层。其中感受野增强模块(LRFB)和上下文模块(CIM)分别追加在Conv4和Conv5后面。
(3)默认框参数。为了使默认框可以和待检测目标的大小更加吻合,对待检测目标的大小进行了k-means聚类分析,设置了更加适合的默认框。默认框参数如表2所示。
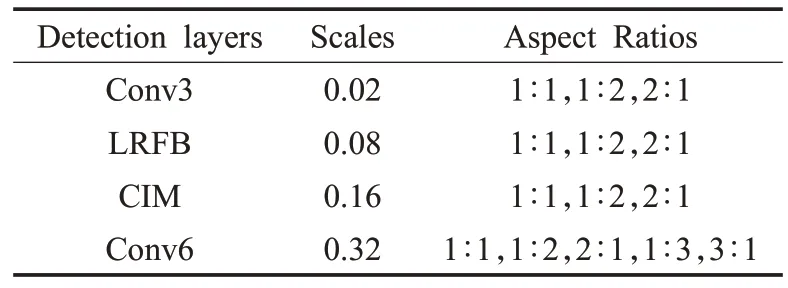
表2 默认框参数Table 2 Parameters of default boxes
1.2 轻量级感受野模块(LRFB)
感受野是卷积神经网络每一层输出的特征图上的像素点在输入图片上映射的区域大小,其类似于人类的视觉系统。为了更好地提取特征信息,提出轻量级感受野模块。文献[25]模仿人类视觉系统中感受野的结构探讨了具有不同尺寸和偏心率的感受野对目标的辨别力和鲁棒性。实验证明,融合不同尺寸和偏心率的感受野,可以有效地提高目标检测精度,而且可以嵌入到主流的目标检测模型中。
受文献[25]和Inception[26]结构的启发,本文提出轻量级感受野模块(LRFB),目的是为了在尽量减少网络参数增加的前提下增强网络对小目标的特征表示能力。使用类似于Inception的多分支结构和带洞卷积来构造感受野增强模块,通过在每个分支设置不同尺寸的卷积核和扩张率获得不同尺寸的感受野,最终通过融合不同的感受野来获得最终的特征。轻量级感受野模块(LRFB)的结构如图2所示。其中带洞卷积也称膨胀卷积,最早在Deeplab[27]中提出,旨在不增加参数的情况下增大卷积层的感受野。3×3大小的卷积核,扩张率(dilation)为1的空洞卷积操作等同于普通卷积。3×3大小的卷积核,扩张率为2的空洞卷积操作,其感受野相当于7×7的卷积核,但是参数数量不变。

图2 轻量级感受野模块(LRFB)Fig.2 Structural diagram of lightweight receptive field block(LRFB)
1.3 上下文模块(CIM)
由于无人机航拍图像中的行人和车辆较小,所以其特征不明显,和背景差异较小。文献[28-29]通过对VGG-16[22]提取的图像特征进行可视化,发现浅层特征图包含更多的小目标特征,所以浅层特征图更适合作为小目标的检测层。浅层特征图的分辨率高,包含更多的小目标特征,但是却缺少语义信息,不能充分地利用上下文信息来提高检测效果。而上下文信息在常规图像目标检测任务中起到了不错的效果[23],所以在无人机小目标检测任务中也引入上下文信息。
为了更准确地检测行人和车辆,设计上下文模块(CIM)来引入上下文信息。通过反卷积操作,将分辨率低但语义信息丰富的特征图进行上采样,然后和分辨率高但语义信息缺乏的特征图进行融合,最终形成高分辨率且语义信息丰富的上下文模块。上下文模块(CIM)的结构如图3所示。

图3 上下文模块(CIM)Fig.3 Structural diagram of context information module(CIM)
2 实验
2.1 实验环境
实验在CPU E5 2450 2.10 GHz,16 GB内存,Ubuntu 16.04系统下搭建的Keras环境下进行,显卡为GeForce GTX1080TI,实验环境的配置参数如表3所示。

表3 实验环境配置参数Table 3 Experimental environment configuration parameters
2.2 数据准备
实验使用的数据是使用大疆Mavic mini无人机拍摄的4 000张图片。数据集划分为训练集和测试集,其中训练集包含3 500张图片,每张图片里的车辆和行人都使用图像标注软件labelImg进行了仔细标注,所标注的目标数目如表4所示。图4展示了部分实验数据。

图4 无人机图像数据示例Fig.4 Some samples from dataset

表4 数据标注目标数目Table 4 Statistical details of annotated dataset
2.3 实验分析
首先分别使用目前比较受欢迎的主流目标检测算法和本文算法进行实验对比。训练时图片大小被设定为640 pixel×360 pixel,batch_size设置为12,final_epoch设置为100,steps_per_epoch也设置为100。初始学习率设置为0.001,训练时如果val_loss超过5个epoch没有降低,则降低学习率,学习率最低设为0.000 01。对比结果如表5所示。与原始SSD相比,本文算法的mAP提高了12.32个百分点,达到了86.21%,并且FPS达到了85。此外与YOLOv3相比,虽然FPS低于YOLOv3,但mAP高出其7.39个百分点。

表5 不同算法测试结果对比Table 5 Comparison of detection results of different algorithms
为了进一步验证所提出方法的有效性,进行了消融实验。消融实验设计了4个实验做对比分析。第一个实验为原始SSD;第二个实验为仅使用设计的轻量级主干网络来进行训练,不添加本文提出的任何模块,网络结构如图5所示;第三个实验在第二个实验的基础上,在Conv4后追加了轻量级感野模块(LRFB),网络结构如图6所示;第四个实验在第三个实验的基础上,加入了上下文模块(CIM),实验结果如表6所示。

表6 消融实验Table 6 Ablation experiments

图5 实验二网络结构Fig.5 Network structure diagram of experiment two
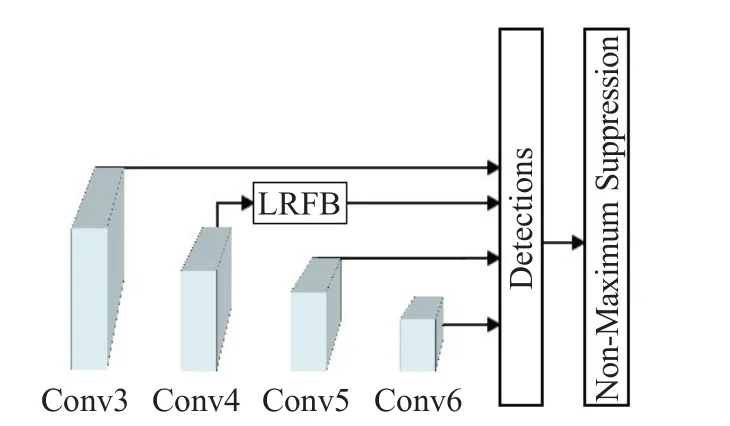
图6 实验三网络结构Fig.6 Network structure diagram of experiment three
从表6可以看出,实验二与原始SSD相比,mAP和FPS都得到了很大的提升。FPS的提升是由于和原始骨干网络相比,设计的轻量级骨干网络的通道数和卷积层数减少了,参数量更少,同时只使用了4个检测层,比原始SSD少了2个检测层。而mAP的提高主要是由于设置了恰当的默认框参数,恰当的默认框可以更好地匹配到待检测目标。实验三在加入了轻量级感受野模块后,mAP得到进一步提升,但同时也由于LRFB的加入,使得FPS有所下降。可以看出,最终在实验四加入CIM后,mAP达到了86.21%,此时FPS为85。损失函数的变化如图7所示,从中可以看出,原始SSD在训练过程中损失函数波动幅度较大,虽然最终达到收敛,但损失要明显高于其他三个实验。而其他三个实验,损失函数波动幅度很小,其中效果最好的是实验四,其曲线下降得非常平滑,得到的训练效果也是最好的。以上实验很好地证明了本文所提方法的有效性,在mAP和FPS两个方面都取得了不错的表现。

图7 损失函数变化Fig.7 Curves of loss function change of ablation experiment
为进一步验证本文算法在无人机图像中行人和车辆检测效果的提升,从测试集中选取3张图片进行测试,结果如图8所示,本文算法在检测到的行人和汽车的个数以及对目标分类的准确率两个方面都要优于传统的SSD,尤其是在行人检测上。

图8 检测效果对比Fig.8 Comparison of detection results
3 结束语
本文提出了一种实时高效的基于无人机的行人与车辆目标检测方法。一方面针对SSD算法模型过大、运行内存占用量过高、无法在无人机设备上运行的问题,精心设计了轻量级的骨干网络。另一方面,为了提升检测精度,设计了每个检测层的默认框参数,并引入轻量级感受野模块和上下文模块。实验结果表明,本文算法在无人机小目标检测任务中具有良好的检测精度和实时性,可以更好地应用到检测服务中。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
北京航空航天大学学报(2021年9期)2021-11-02
疯狂英语·新策略(2019年10期)2019-12-13
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
电视技术(2014年19期)2014-03-11
河南科技(2014年23期)2014-02-27
