
一种面向协同过滤的快速最近邻居搜索方法
2021-09-07 00:48:04赵旭辉李晓光
计算机工程与应用 2021年17期
王 永,赵旭辉,李晓光,肖 玲
重庆邮电大学 电子商务与现代物流重点实验室,重庆400065
互联网的发展带来了信息的爆炸式增长,在为人们提供生活便捷的同时也带来了信息过载问题[1-2]。推荐算法利用用户历史数据,挖掘其兴趣爱好,提供个性化推荐服务,是解决信息过载问题的有效手段之一。基于邻居的协同过滤模型是最典型的推荐算法,被广泛运用于电子商务等领域[3-4]。该模型通常分为两类,分别为:基于邻居用户的推荐模型和基于邻居项目的推荐模型,即通过最近邻居用户(项目)的已有信息预测目标用户对目标项目的评价。以此为基础,邢长征等[5]将用户评论集和物品评论相结合,提出一种联合评论文本层级注意力和外积的推荐方法;陆航等[6]针对传统的协同过滤算法中单一评分相似性计算不准确的问题,提出一种融合用户兴趣和评分差异的推荐方法;王宇琛等[7]将LDA模型与Bandits相结合提出了一种新的推荐方法,这些方法均有效提高了推荐的准确性。
在基于邻居的协同过滤模型中,邻居数据集的确定是非常关键的步骤,同时由于在该步骤中需要计算目标用户(项目)与其余所有用户(项目)间的相似性,邻居集的确定也是该模型中最耗时步骤。为了提高推荐的准确性与计算效率,许多研究者对此进行了深入的研究[8-12]。Choi等[8]认为邻居集应该随目标项目的改变而改变,因此以用户的共同评分项与目标项目间的相似性作为权重因子,调节其余用户与目标用户之间的相似性。Koohi等[9]通过子空间聚类为目标用户寻找最近邻居,有效缓解了数据的稀疏性问题。Liang等[10]采用局部敏感的哈希方法,通过哈希表查找最近邻居,以提高算法效率。Hwang等[11]选择部分用户作为类别专家,然后依据目标用户与类别专家间的相似性来选择最近邻居,以此缩短寻找邻居的时间。Chae等[4]依据相似性度量方法的约束条件,设计了新的数据结构,有效减少了相似性度量中的无效计算,提高了算法的运行效率。此外,在实际应用中常通过在离线条件下提前计算所有用户(项目)间的相似性的方式来提高模型的运行效率。但这种方法有一个突出的缺点:忽略了用户的最新评分,难以发现用户的最新变化,特别是在稀疏数据的环境中,这种影响尤为明显[12]。此外,离线确定邻居的方式还会加剧冷启动问题。
当前多数方法是围绕推荐准确性与推荐效率之间的平衡展开研究,对推荐模型进行改进,很难同时提升推荐质量和算法效率。此外,大多数研究侧重如何提高相似性度量的准确性,从而找到更合适的邻居。然而却忽略了找到邻居后,该邻居是否能有效用于预测值的计算中。针对这些研究不足,提出了一种新的搜索最近邻居的方法。该方法利用相似性测量方法与预测方法中所隐含的约束条件首先对潜在邻居进行筛选,仅对那些对预测评分值产生影响的用户或项目才进行相似性计算。为此构建了项目的用户评分列表与用户的项目评分列表来筛选出有效的用户或项目。这样一方面极大地降低了相似性的计算量,另一方面也能保证每一位邻居的评分信息都对预测值的计算做出了贡献,从而实现了推荐质量与推荐效率的同时提升。
1 预备知识
为了描述方便,列出了协同过滤模型中常用的符号及意义,如表1所示。

表1 协同过滤模型中常用的符号及意义Table 1 Notations related to collaborative filtering model
1.1 典型的相似性度量方法
基于邻居的协同过滤模型中,根据邻居集的不同,可分为基于用户的协同过滤算法和基于项目的协同过滤算法。PCC与ACOS分别为最常用的用户相似性度量方法与项目相似性度量方法,其计算公式如下[13-16]:
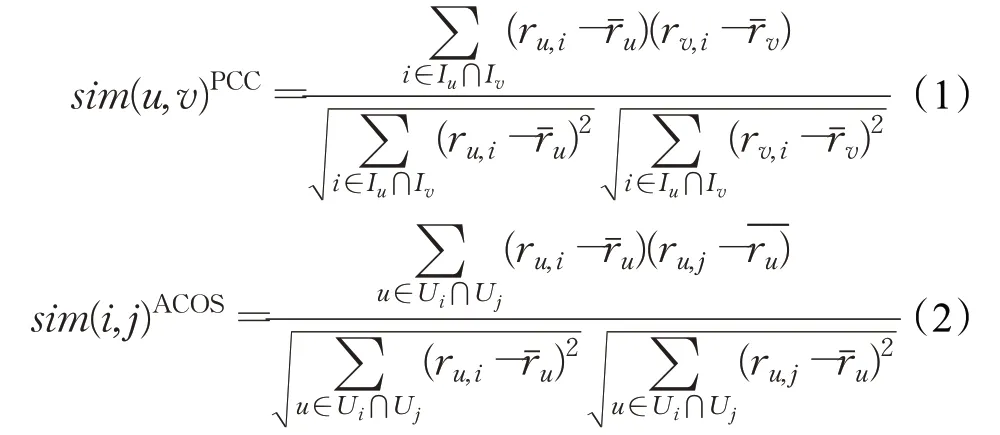
上述相似性度量方法具有结构简单、计算便捷的特点,强调了共同评分项的重要性,对所使用的数据有严格的条件要求。
1.2 典型的预测方法
传统协同过滤模型根据相似性计算结果确定邻居集,然后依据邻居信息展开预测。对于基于用户的协同过滤算法与基于项目的协同过滤算法,最为常用的预测公式如下[17-19]:

上述预测公式通过邻居的评分信息来计算预测值,虽然计算简单,但却具有邻居利用率低的缺陷。
2 问题的引出与分析
本章通过引导性实验说明当前协同过滤算法中存在的问题。选取典型的公开数据集Movielens100k与Movielsn1M作为实验的数据集(https://grouplens.org/datasets/movielens),对基于用户的协同过滤算法(UBCF)和基于项目的协同过滤算法(IBCF)进行测试。分别以PCC与ACOS作为UBCF和IBCF的相似性度量方法,以公式(3)与公式(4)作为相应的算法的预测公式。实验内容包含两部分:(1)模型运行时间比较;(2)邻居利用率统计。
2.1 运行时间
在协同过滤推荐算法中,确定邻居集是其中最为耗时的步骤,因为该步骤需要计算并比较目标用户(项目)与其他所有用户(项目)之间的相似性。在实际应用中,一种常用的处理方式是在线下事先计算出用户或项目之间的相似性,在推荐时直接使用该计算结果确定邻居集,从而提高推荐的效率。这种方式被称之为线下推荐方式。此处,将采用这种方式的UBCF和IBCF称之为UBCF_offline和IBCF_offline。相应的,将采用线上直接计算相似性和推荐结果的UBCF和IBCF称之为UBCF_online和IBCF_online。
完成一次推荐,线上的推荐方法(UBCF_online和IBCF_online)所需的时间主要包含两个部分,即计算相似性并确定邻居集的时间和通过加权组合计算预测评分的时间。对线下的推荐方法(UBCF_offline和IBCF_offline),由于已经提前完成了相似性计算和邻居集的确定,因此完成单次推荐所需时间仅包括通过加权组合计算预测评分的时间。借鉴文献[4]中的实验设计,在测试中将最近邻居的数量设置为80。在配置为CPU I5,内存8 GB的台式电脑上,测试上述方法完成单次推荐所需时间的均值、标准差、最大值以及最小值如表2和表3所示。

表3 线下方法完成单次推荐所需时间Table 3 Run time for offline methods to complete single recommendation ms
通过表2、3可以得到,无论是线上推荐方法还是线下推荐方法,均需要大量的时间来搜索最近邻居。当系统中的用户数和项目数较大时,寻找邻居所需时间显著增长。线下推荐的方法,由于预先计算了用户(项目)间的相似性,在进行推荐时,可以跳过该步骤,直接进行预测评分计算与推荐,从而获得远高于线上方法执行效率。

表2 线上方法完成单次推荐所需时间Table 2 Run time for online methods to complete single recommendation ms
另一方面,由于线下方法采用定时批量更新数据的方式,因此无法实时获取用户或项目的最新信息,这会导致其预测准确性低于线上方法。关于这一现象本文将在4.2节做进一步的分析。综上所述,实验结果表明非常有必要为线上推荐方法设计一种高效的搜寻邻居的方法,以提高整个模型的运行效率。
2.2 邻居利用率的统计
基于邻居的协同过滤算法中,选择邻居的主要依据是相似性度量的结果。在预测评分时,预测公式对邻居的可用性往往是有一定要求的。在公式(3)所示的基于邻居用户的预测计算中要求rv,i存在,即要求邻居用户必须评论过目标项目。同样的,在公式(4)所示的基于邻居项目的预测计算中要求ru,j存在,即要求目标用户必须评论过邻居项目。然而,在选择邻居时并未考虑这些要求,且由于数据集的稀疏性,在实际应用中,往往存在相当多的邻居用户(项目)并不满足预测公式的要求。这些邻居无法应用到预测公式中,从而造成邻居利用率很低的现象。为了验证该观点,在数据集Movielens100k与Movielens1M上,采用公式(3)和公式(4)所示的预测方法,统计邻居的利用率情况。测试结果如图1所示。通过观察可以发现,在分别设置邻居数大小为20至100的条件下,UBCF与IBCF的邻居利用率均低于10%,这意味着邻居集中的大多数成员均未在计算预测值的过程中发挥作用。由此可见,即使能够构建与目标用户(项目)的相似性很高的邻居集,也会因为邻居利用率低而降低了预测的可靠性与准确性。因此,有必要设计一种新的搜寻邻居的方法,以提升邻居的利用率。

图1 UBCF和IBCF的邻居利用率Fig.1 Neighbor utilization of UBCF and IBCF
3 搜寻最近邻居的方法
上述引导性实验的结果表明,推荐模型中常采用的“先计算全部相似性,再根据相似性程度搜寻最近邻居集”的方法不仅耗时,而且还由于没有考虑预测方法的要求,容易造成邻居的利用率低。为此,本文结合相似性度量和预测方法的约束条件,提出一种新的搜寻最近邻居的方法。该方法在提升邻居利用率的同时,也显著降低了计算的规模,有效提高了推荐模型的执行效率。
3.1 适用于UBCF的最近邻居选择方法
在UBCF模型中,以公式(1)和公式(3)作为相似性度量和预测值计算的公式,归纳总结的约束条件如下:
(1)由公式(3)可知,对于目标用户u与目标项目i,若rv,i不存在,则预测计算不可行。因此只有评价过项目i的用户v才能被选作用户u的邻居。
(2)由公式(1)可知,对于任意两用户u与v,若Iu⋂Iv=∅,则sim(u,v)计算不可行。因此必须与u有共同评分项的用户v才能被选作用户u的邻居。基于上述约束条件,提出适用于UBCF的最近邻居用户搜寻方法如下:
步骤1构建项目的用户评分列表。根据用户项目评分矩阵,为每个项目构造相应的用户评分列表ListU。对于项目i,其对应的用户评分列表为ListU(i)={(uk,ruk,i)|uk∈Ui},其中二元组(uk,ruk,i)表示用户uk和它对项目i的评分ruk,i。在实际操作中,将评分矩阵中评论过项目i的所有用户和他们对i的评分组织到一起,即得到ListU(i)。
步骤2筛选满足预测计算要求的用户集合。假设当前任务是预测目标用户u对目标项目i的评分。根据约束条件(1)可知只有评论过项目i的用户才可能作为用户u的邻居。因此,从ListU(i)中提取出所有的用户构建用户集合UA。
步骤3根据约束条件(2),从用户项目评分矩阵中筛选出用户u评论过的项目集合Iu。然后,根据Iu,获得列表集合LU={ListU(i)|i∈Iu}。从LU中挑选出所有的用户构建用户集合UB。
步骤4将集合UA与集合UB的交集UC作为用户u的备选邻居集。计算用户u与UC中各用户的相似性,根据相似性值的大小确定最终的邻居用户集。
现通过一个示例说明上述搜寻邻居的过程。假设评分矩阵中有7个用户(u1,u2,…,u6,u)和6个项目(i1,i2,…,i6)。根据评分矩阵构造项目的用户评分列表如图2所示,目标用户u的评分向量为[4,−,3,−,2,−],需要预测用户u对目标项目i2的评分。根据ListU(i2)得集合UA为{u1,u2,u4}。用户u评论过的项目集合Iu为{i1,i3,i5},由此得到集合LU为{ListU(i1),ListU(i3),ListU(i5)},从而得到UB为{u2,u3,u4,u6,u}。集合UA与集合UB的交集UC为{u2,u4}。所以,为用户u寻找最近邻居时,只需计算u与u2和u与u4间的用户相似性。相较于传统方法,本文方法不需要计算u与u1、u3、u5、u6之间的相似性,极大提高了推荐模型的执行效率。

图2 最近邻居用户搜寻示例Fig.2 Example of searching nearest neighbor user
3.2 适用于IBCF的最近邻居选择方法
在IBCF模型中,以公式(2)和公式(4)作为相似性度量和预测值计算的公式,归纳总结的约束条件如下:
(1)由公式(4)可知,对于目标用户u与目标项目i,若ru,j不存在,则预测计算不可行。因此只有被用户u评价过的项目j才能被选作项目i的邻居。
(2)由公式(2)可知,对于任意两项目i与j,若Ui⋂Uj=∅,则sim(i,j)计算不可行。因此必须与项目i有公共的评分用户的项目j才能被选作项目i的邻居。
基于上述约束条件,提出适用于IBCF的最近邻居用户搜寻方法如下:
步骤1构建用户的项目评分列表。根据用户项目评分矩阵,为每个用户构造相应的项目评分列表ListI。对于用户u,其对应的项目评分列表为ListI(u)={(ik,ru,ik)|ik∈Iu},其中二元组(ik,ru,ik)表示项目ik和用户u对它的评分ru,ik。在实际操作中,将评分矩阵中用户u评论过的所有项目和用户u对这些项目的评分组织到一起,即得到ListI(u)。
步骤2筛选满足预测计算要求的项目集合。假设当前任务是预测目标用户u对目标项目i的评分。根据约束条件(1)可知只有被用户u评论过的项目才可能是项目i的邻居。因此,从ListI(u)中提取出所有的项目构建项目集合IA。
步骤3根据约束条件(2),从用户项目评分矩阵中筛选出评价过项目i的用户集合Ui。根据Ui,获得列表集合LI={ListI(u)|u∈Ui}。从LI中挑选出所有的项目构建项目集合IB。
步骤4将集合IA与集合IB的交集IC作为项目i的备选邻居集。计算项目i与IC中各项目的相似性,根据相似性值的大小确定最终的邻居项目集。
此处同样通过一个示例来说明算法的工作过程。假设评分矩阵中有6个用户(u1,u2,…,u6)和7个项目(i1,i2,…,i6,i)。根据评分矩阵构造用户的项目评分列表如图3所示,目标项目i的评分向量为[3,−,2,−,5,−],需要预测用户u2对项目i的评分。根据ListI(u2)得集合IA为{i2,i3,i5}。评论过i的用户集合Ui为{u1,u3,u5},根据LI={ListI(u1),ListI(u3),ListI(u5)}可得IB为{i1,i2,i4,i5,i},进而得到IC为{i2,i5}。所以此例中,找寻邻居集合只需计算i与i2和i与i5间的用户相似性,同样极大提高了推荐模型的执行效率。
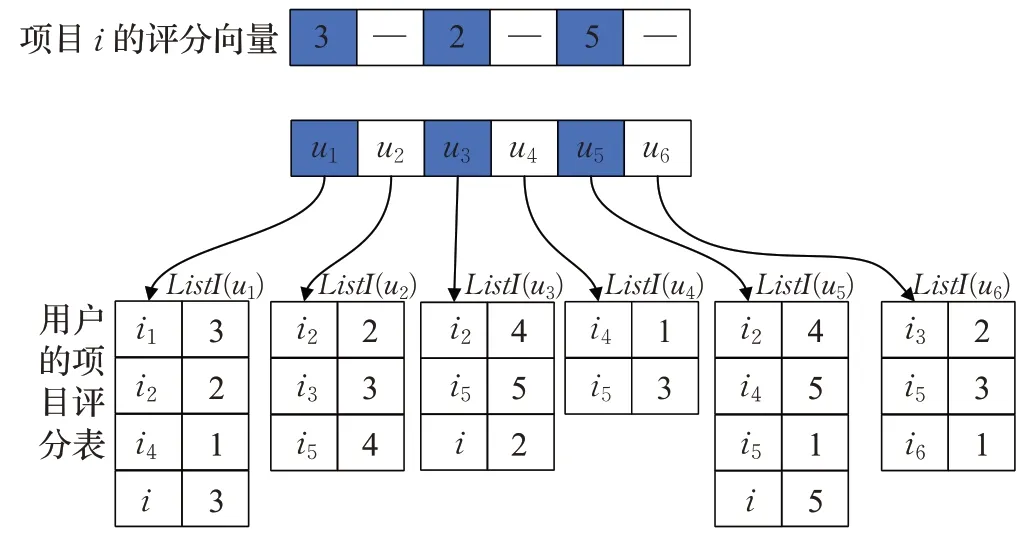
图3 最近邻居项目搜寻示例Fig.3 Example of searching nearest neighbor item
3.3 算法分析
首先,本文所提方法具有高效性与高准确性。该方法的原理是利用相似性测量方法与预测方法中所隐含的约束条件对潜在邻居进行筛选,仅对那些对预测评分值产生影响的用户或项目才进行相似性计算。具体的,以预测用户u对项目i的过程为例,在基于用户的协同过滤算法中,由PCC的理论计算公式可知,两用户间存在共同评分项时才能计算其相似性,即用户u的邻居只能在评论过Iu中的项目的用户集合UB中选择。通过访问事先构建的项目的用户评分表可以很容易获得该用户集合。此外,通过公式(3)易知,用户u的邻居必须评论过项目i,这样才能保证rv,i的存在。故用户u的邻居应在评论过项目i的用户集合UA中选择。该用户集合也可以通过访问事先构建的项目的用户表轻易获得。将用户集合UA与UB做交集即可获得到用户u的备选邻居集合UC。在基于项目的协同过滤算法中也存在类似约束条件,故本文类似地构造了用户的项目评分列表,用于获得集合Ui中各用户所评论过的项目集合IB以及用户u评论过的项目集合IA,将这两项目集合做交集即可获得项目i的备选邻居集合IC。本文所提方法在缩小邻居搜寻范围同时也显著性地提升了邻居的利用率,从而保证其高效性与高准确性。此外,虽然为每个项目(用户)构建相应的用户评分表(项目评分表)需要消耗一定时间,但是在实际应用中该操作是可以依据用户项目评分矩阵事先构造的。
其次,本文所提算法具有经济性。上述最近邻居用户搜寻方法中,项目(用户)的用户评分表(项目评分表)仅仅只是更改了评分矩阵中数据组织方式,采用另外一种方式关联了基本数据之间的联系,但并未添加新的数据信息,因此在系统的实现中可以通过在评分矩阵添加指针的方式来指明基本数据之间的关系,无需为用户评分列表再分配新的存储空间,从而保证了本文搜索算法的经济性。
最后,本文方法具有实时性。当评分矩阵中出现数据更新时,只需要相应地更新用户评分列表即可,在实现中主要体现为数据指针的增删与修改,不会带来新的计算,因此可以有效保证本文搜索算法的实时性,此外本文所提方法的高效性也保证了算法的实时性。
4 算法的实验结果与分析
4.1 数据集与评价指标
采用公开数据集Movielens100k、Movielens1M作为算法测试的数据集。表4列举了两个数据集的详细信息。对于每个数据集,随机选取80%的记录作为训练集,剩下的记录作为测试集。评价推荐系统的指标有多种,主要可以分为三类:预测的准确性、推荐的准确性、计算的有效性[13]。平均绝对误差(MAE)与均方根误差(RMSE)是评价算法预测准确性的常用指标。其定义如下[20]:

表4 实验数据集的详细信息Table 4 Detailed description of experiment datasets
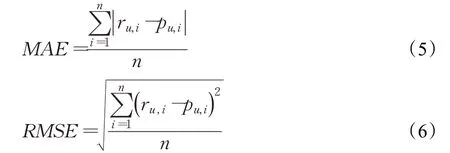
其中,ru,i是用户u对项目i的实际评分,pu,i是用户u对项目i的预测评分值,n为预测次数。
F1值作为Precision和Recall的调和平均值,常被用于评价算法的推荐准确性。其定义如下[21-22]:
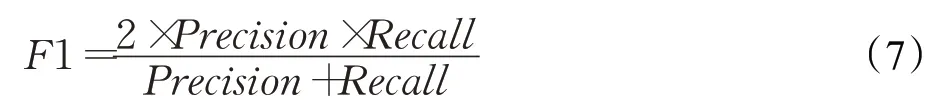
此外,计算有效性的评价指标为有效预测数,它表示在所有需要预测的数据中,模型可以成功计算出预测结果的数量。
4.2 结果分析
将第3章提出的邻居选择方法分别融入UBCF和IBCF模型中,将得到的新模型命名为UBCF_prop和IBCF_prop。在相同的数据集上对UBCF_prop和IBCF_prop进行测试,并将实验结果与第2章中的结果进行对比,以验证本文所提出的邻居选择方法的有效性。
(1)效率分析
为了说明本文所提方法对算法效率的影响,首先将传统搜寻最近邻居方法的时间复杂度与本文所提方法的时间复杂度进行对比。假设数据集中共有m个用户,n个项目,待预测记录数为l。UBCF_online在搜寻邻居时需要计算某一用户与其余m-1个用户间的相似性,且该过程需重复l次,故UBCF_online的时间复杂度为O(lm)。假设平均每个项目的UA中所包含的用户数为s1,平均每个项目的UB中所包含的用户数为s2,UA与UB的交集UC中所包含的用户数的平均值为s。故UBCF_prop的时间复杂度为O(ls)。类似的,易知IBCF_online的时间复杂度为O(ln)。假设平均每个用户的IA中所包含的项目数为r1,平均每个用户的IB中所包含的用户数为r2,IA与IB的交集IC中所包含的用户数的平均值为r,易知IBCF_prop的时间复杂度为O(lr)。由于s与r远远小于m与n,故UBCF_prop的时间复杂度O(ls)远远低于UBCF_online的时间复杂度O(lm),IBCF_prop的时间复杂度O(lr)远远小于IBCF_online的时间复杂度O(ln)。
在与第2章相同的数据集和运行环境下,测试UBCF_prop和IBCF_prop完成单次线上推荐所需的时间。所得结果如表5所示。比较表5与表2中的数据,在采用本文所提出的邻居搜寻方法后,模型的运行效率得到显著提高。在数据集Movielens100k与Movilens1M上,UBCF_prop完成单次线上推荐所需时间的均值分别为3.12 ms与26.21 ms,而UBCF_online在这两个数据集上完成单次线上推荐所需时间的均值分别为67.01 ms与836.96 ms。UBCF_prop完成推荐所需时间远小于UBCF_online。类似的,在数据集Movielens100k与Movilens1M上,IBCF_prop完成单次线上推荐所需时间的均值分别为21.81 ms与109.06 ms,而IBCF_online所需时间的均值分别为538.38 ms与11 110.63 ms。IBCF_prop的运行速度同样远快于IBCF_online。上述比较结果说明,本文算法可以根据历史记录迅速提供实时推荐,弥补传统算法线上推荐方法耗时的缺陷。
比较表5和表3中的实验结果,UBCF_prop和IBCF_prop的运行效率与离线方法UBCF_offline和IBCF_offline之间仍存在显著的差距。但正如前文所述,线下推荐的方式未考虑数据更新对推荐质量的影响,且其推荐质量也会随着未更新数据的增加而变差。
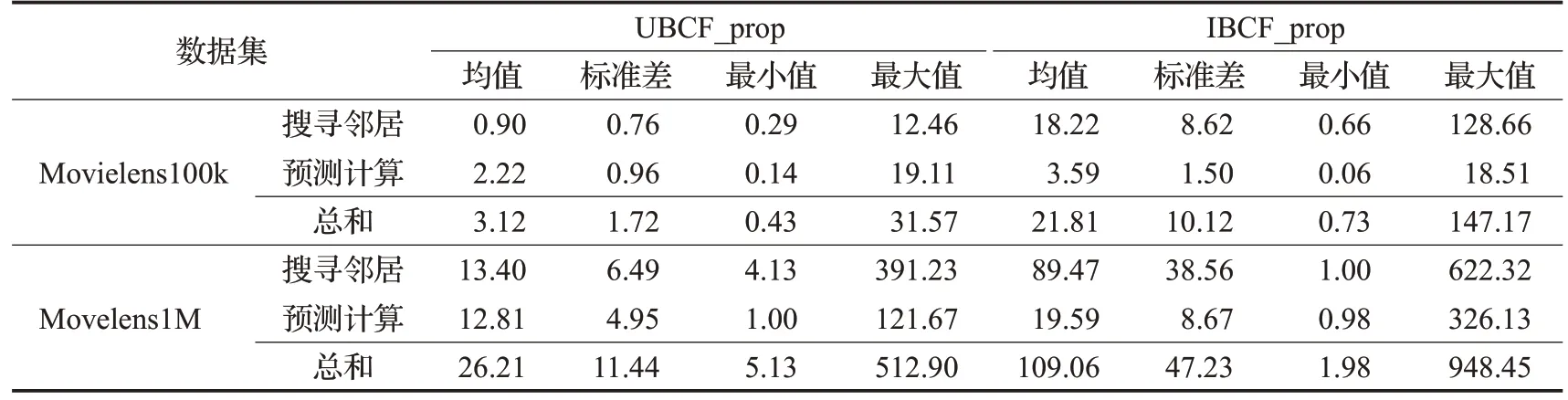
表5 UBCF_prop、IBCF_prop完成单次线上推荐所需时间Table 5 Run time for UBCF_prop and IBCF_prop to complete single recommendation ms
(2)数据更新的影响分析
为说明数据实时更新对预测准确性的影响,进行如下的实验测试:对数据集Movielens100k重新进行划分。根据数据产生的时间戳,提取出最新的10%的数据作为测试集,其余的数据作为训练集。这样划分的目的是为了测试算法对最新数据的预测是否准确。同时,为了考虑数据更新情况对预测的影响,在训练集中,根据数据产生的时间戳,删除每个用户2%的最新的评分数据。这样可以将余下的数据视为有2%最新数据未更新的数据集。在此数据集上测试UBCF_offline和IBCF_offline的MAE和RMSE。采取同样的方式,以2%为步长,继续删除最新的评分数据,再次对UBCF_offline和IBCF_offline进行测试,重复此过程,直至10%的最新数据被删除为止。对UBCF_offline和IBCF_offline的测试结果如图4所示。
同时,为了对比在线算法和线下算法之间的差异,对UBCF_online、IBCF_online、UBCF_prop和IBCF_prop进行测试。由于在线算法是在实际中实时使用最新的数据,所以在此处的测试中不对训练集中的最新数据进行任何删除。测试结果同样列于图4。
由于UBCF_online、IBCF_online、UBCF_prop和IBCF_prop为线上预测方法,不存在更新数据的问题,它们以全部测试数据作为基础,展开对10%最新数据构成的测试集进行预测。由于没有数据更新的问题,因此得到的测试结果也不会随数据未更新率的变化而变化,所以在图4中表示为水平直线。从图4(a)中可得,UBCF_online和IBCF_online的MAE值 分 别 为0.95和1.07。UBCF_offline和IBCF_offline的MAE值变化趋势是随着未更新数据率的增加而增大。由图中可以看出,UBCF_online和IBCF_online的MAE值均略微优于UBCF_offline和IBCF_offline。这说明实时更新数据对预测最新的评分有积极的影响作用。从图4(a)中还可以看到,UBCF_prop,IBCF_prop的MAE值分别为0.87和0.79,分别明显优于UBCF_online、UBCF_offline和IBCF_online、IBCF_offline。主要的原因是UBCF_prop和IBCF_prop不仅能有效使用所有最新的数据展开预测,而且还由于采用了本文提出的邻居搜索算法,有效提升了邻居的利用率,保证了预测计算的全面性,因此获得了更好的MAE值。在图4(b)中,UBCF_offline和IBCF_offline的RMSE值虽有波动,但整体趋势是随着未更新数据率的增加而增大。同样的,UBCF_online和IBCF_online的RMSE值均略微优于UBCF_offline和IBCF_offline,而UBCF_prop和IBCF_prop的RMSE值则分别明显优于UBCF_online、UBCF_offline和IBCF_online、IBCF_offline。综上所述,本文提出的算法不受数据更新的影响,且更好地利用了邻居数据集的信息,具有更好的预测准确性。

图4 预测准确性随未更新数据率的变化情况Fig.4 Prediction accuracy versus un-update data
(3)推荐质量分析
由于本文主要是依据相似性计算和预测计算的约束条件提出的邻居搜索方法,因此搜索得到的邻居均可用于模型的预测计算中,有效提高了推荐模型的推荐质量。为验证本文搜索方法对推荐质量的提升,在Movielens100k和Movielens1M数据集上,测试并比较UBCF_prop、IBCF_prop与UBCF_online、IBCF_online的推荐结果。
①MAE和RMSE
图5和图6为UBCF_prop、IBCF_prop、UBCF_online和IBCF_online算法在Movielens100k和Movielens1M数据集上测试得到的MAE和RMSE。在这两个数据集上,UBCF_prop的MAE最佳值分别为0.75和0.71,远低于UBCF_online的MAE的最佳值0.85和0.93。同样的,IBCF_prop的MAE最佳值分别为0.76和0.69,远低于IBCF_online的MAE最佳值0.95和0.92。各方法在RMSE方面的表现与MAE类似,UBCF_prop与IBCF_prop的RMSE最佳值均远低于UBCF_online与IBCF_online的RMSE的最佳值。总体说来,采用本文提出的最近邻居搜索方法后,推荐模型的MAE和RMSE比原模型提升了10%~38%,模型的预测准确性得到进一步的提高。

图5 MAE的结果比较Fig.5 Comparison of MAE results

图6 RMSE的结果比较Fig.6 Comparison of RMSE results
②F1值
F1值的测试结题如图7所示。在Movielens100k数据集中,UBCF_prop与UBCF_online的F1值间的差距随着邻居数的增加而减小;IBCF_prop的F1值始终明显高于IBCF_online的F1值。在Movielens1M数据集中,UBCF_prop的F1值始终优于UBCF_online的F1值;邻居数较低时,IBCF_prop的F1值明显高于IBCF_online的F1值,在邻居数为100时,二者的F1值十分接近。整体而言,UBCF_prop与IBCF_prop的F1值优于UBCF_online与IBCF_online的F1值,推荐准确性提升幅度大约在1%~15%的范围。上述实验结果表明,采用本文提出的最近邻居搜索方法后,推荐模型的推荐准确性比原模型仍有一定的程度的提高。
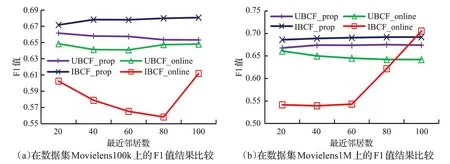
图7 F1值的结果比较Fig.7 Comparison of F1 value results
③有效预测数
在数据集Movielens100k与Movielens1M中,待预测的记录数分别为20 000条和202 451条。各算法的有效预测数测试结果如图8所示。从图中可以看出,UBCF_prop与IBCF_prop的有效预测数都远远超过了UBCF_online与IBCF_online的有效预测数。
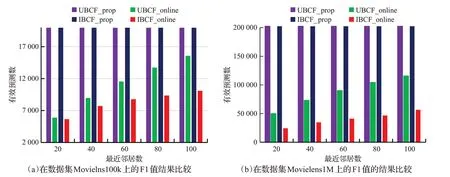
图8 有效预测数的比较Fig.8 Comparison of number of valid prediction
5 结语
针对协同过滤模型中存在的寻找邻居耗时和邻居利用率低的问题,本文深入分析了用户(项目)相似性计算以及预测评分值产生过程中存在的约束条件,以此为基础,提出了一种新的最近邻居搜索方法。该方法将相似性计算和预测计算中的约束条件转化为对数据的筛选条件,从而有效地缩小了搜寻最近邻居的范围,极大地提高了协同过滤模型的运行效率。同时,该方法还提高了协同过滤模型对邻居的利用率,提高了推荐结果的质量。在公开数据集上的测试结果表明,采用本文所提出的邻居搜索方法后,协同过滤模型在运行效率和推荐准确性方面均有明显提高,这也说明了本文方法具有很好的应用潜力与价值。
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
科学大众(2020年23期)2021-01-18 03:09:08
河北画报(2020年8期)2020-10-27 02:54:20
汽车观察(2019年2期)2019-03-15 06:00:50
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
中国卫生(2016年5期)2016-11-12 13:25:26
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
