
基于随机森林的高寒草地地上生物量高光谱估算
2021-09-07 05:56高宏元侯蒙京包旭莹李元春冯琦胜梁天刚贺金生钱大文
草地学报 2021年8期
高宏元, 侯蒙京, 葛 静, 包旭莹, 李元春, 刘 洁, 冯琦胜, 梁天刚*, 贺金生,2, 钱大文
(1. 兰州大学草地农业科技学院, 兰州大学草地农业生态系统国家重点实验室, 兰州大学农业农村部草牧业创新重点实验室, 兰州大学草地农业教育部工程研究中心, 甘肃 兰州 730020; 2. 北京大学城市与环境学院, 北京 100871;3. 中国科学院西北高原生物研究所, 青海 西宁 810008)
草地地上生物量(Above ground biomass,AGB)是指某一时刻单位面积内的草地植物在地上部分的有机物的总量[1],它不仅是衡量草地群落生长状况与生产力水平的关键参数,还是表征群落能量流动和物质循环的重要指标之一[2]。在高寒地区,草地是家畜的主要食物来源与能量供给[3],草地AGB变化还能反映草地的退化与土壤的侵蚀程度[4]。因此,测定高寒草地AGB十分有必要。传统的草地AGB测定通常采用实地收获法,耗时费力,时效性较差,且对草地破坏性大。
高光谱遥感能在不直接接触目标物体的同时,获得其丰富的光谱信息[5]。对草地高光谱数据进行挖掘和分析,可以获得植被的物理化学组分和生理生态情况等指标,这使实时监测草地植被成为了可能,如纪童等[6]用高光谱数据实现了草坪草叶绿素含量的监测,高金龙等[7]利用高光谱数据构建了高寒天然草地氮、磷养分的估测模型,王磊[8]用高光谱反演了草地的叶面积指数,韩万强等[9]用高光谱数据识别了3种草地主要植物等。对于草地AGB的高光谱监测,目前也有不少相关研究。胥慧等[10]的研究表明基于光谱红谷吸收深度D和光谱绿峰反射高度H的高光谱特征参数(D-H)/(D+H)和草地生物量有较高的相关性;夏浪等[11]使用NDVI反演生物量并得到较高的模型精度;马维维[12]用高光谱卫星数据提取NDVI等5个植被指数用于反演草地生物量。这些研究大多直接以植被指数为建模特征,少有考虑原始光谱特征及其转换参数对模型的影响。张凯等[13]筛选了甘南地区草地冠层的6个光谱特征变量并分别进行AGB的线性、对数等模型的构建;安海波等[14]用不同植被指数对内蒙古天然和人工草地进行了AGB指数、对数等的非线性回归建模。上述研究构建的AGB反演模型大多为单因素或多因素参数统计模型,更注重数据的空间分布,这在研究样本较少且草地类型均一时是有效的,当样本较多且研究区情况复杂时模型的预测能力存在不稳定的问题[15]。因此,在进行草地AGB的高光谱研究时,建模特征的选择和模型算法是影响AGB估算模型的关键因素,在模型简化和稳定性方面有重要意义。
目前,用于高光谱研究的算法较多,连续投影算法(Successive projections algorithm,SPA)由于其良好的光谱冗余信息消除能力,常用于连续光谱数据的选择,杨晨波等人[16]研究表明SPA可以极大减小原始光谱数据的维度,从而简化模型;递归特征消除算法(Recursive feature elimination,RFE)是一种用于筛选最优特征子集的贪心算法,一般与机器学习结合使用,在降低数据维度的同时可找到精度最高的模型[17-18];随机森林(Random forest,RF)是一种决策树集成算法,具有不易过拟合和普适性广的优点[19],在植被生理生态等指标的研究中,常用于估测模型的构建[20-22]。综上,本研究基于SPA和RFE特征选择方法和RF模型,开展高寒地区草地AGB的高光谱研究,以期对高寒地区的放牧强度、草畜平衡和生态环境实时监测提供科学依据。
1 材料与方法
1.1 试验设计
本研究的试验区位于青海海北高寒草地生态国家野外科学观测研究站(简称海北站,37°37′ N,101°19′ E)附近(图1),坐落于青藏高原东北隅,草地类型属于典型的高寒草地,年平均气温-1.7℃,年降水量范围为426~860 mm,植被类型是以金露梅(Potentillafruticosa)为建群种的高寒灌丛草甸和以嵩草属(Kobresia)植物为建群种的高寒嵩草草甸[23]。试验区A,B是两块典型的高寒草地,每块试验地有15个小区(每个小区面积0.2 ha),设有禁牧(CK)、轻度放牧(Light,L)、中度放牧(Medium,M)和重度放牧(Heavy,H)4个放牧梯度,对应的放牧强度分别为0头·ha-1(CK)、0.5 头·ha-1(L)、1.0 头·ha-1(M)和2.0 头·ha-1(H)。放牧家畜为牦牛,放牧方式为轮牧,时间为每年7—9月。放牧设置主要模拟了天然草地的复杂情况,能反映本研究构建的AGB模型的普遍适用性。

图1 研究区位置图Fig.1 Location of the study area
1.2 数据获取与预处理
草地冠层光谱数据测量采用美国ASD公司的双光谱仪系统,该系统由移动端和固定端两台ASD Field Spec 4光谱仪组成,其波段范围为350~2 500 nm。双光谱仪系统通过无线通讯,实时获得反射率数据,并且能自动完成波长交叉校准,可消除不同时间太阳辐射变化带来的误差,因此在多变的天气条件下也可以获得良好的特征光谱图[24]。测量草地冠层光谱要在晴朗少云的天气下进行,测量时探头垂直向下,距冠层高度大约1 m,每个小区随机选取3个测量点,每个测量点测定9条光谱曲线,去掉异常光谱曲线,将其余光谱的平均值作为该小区的草地冠层反射率光谱。在小区的每个光谱测量位点放置样方框,齐地面刈割样方内的植物地上部分,带回实验室在65℃烘箱中烘48 h至恒重,得到每个小区的草地AGB。
由于光谱曲线有一定的噪声,用Savitzky-Golay平滑法[25]进行平滑去噪处理,得到原始光谱曲线,进而得到一阶微分光谱。此外,考虑到水分、氧气和仪器敏感性波动等因素的影响,剔除了1 301~1 450 nm,1 801~2 050 nm和2 301~2 500 nm波段的光谱曲线[26]。本研究在2019年5月、6月、7月、8月、9月和2020年7月、9月总计开展了7次外业调查,在2020年的7月和9月,由于B放牧地封锁无法获得实测数据,因此共获得180个样本数据,去掉无效或错误数据,共有179个样本数据,具体的样本分布和描述性统计如表1所示。

表1 AGB数据描述性统计结果Table 1 Descriptive statistical result of AGB data
1.3 特征变量
本研究的特征变量有原始光谱(Original spectrum,OR)、一阶微分光谱FD(First derivative spectrum,FD)、光谱位置面积参数(Spectral parameters of spectral position and area,PA)和植被指数(Vegetation indices,VI)4类(表2),这些不同类别的特征变量,将用于后续的特征选择和模型构建。

表2 特征变量及其定义Table 2 Variables and definition
1.4 特征选择与建模
本研究先用连续投影算法SPA对原始光谱和一阶导光谱数据进行特征波段反射率的提取,再用递归特征消除算法RFE对特征波段反射率和其他特征变量进行特征选择,最后用随机森林RF算法构建草地AGB的反演模型,以上算法均由Python编程语言实现。
SPA是一种使矢量空间共线性最小化的前向变量选择算法,它的优势在于可提取全波段的几个特征波段,能够消除光谱矩阵中冗余的信息[28],因此本研究用SPA提取OR和FD的光谱特征波段,从而降低数据维度,使模型更简单高效。
RFE是一种寻求最优特征子集的贪心算法[29],基本思想是构建底层模型进行初始特征集的训练,并给每个特征赋予权重,然后去掉权重最小的特征,将其他特征组成新的特征子集,再进行训练,递归重复此过程直至达到最终所需的特征数目。在本研究中,RFE构建RF底层模型时选取默认参数,选取训练结果决定系数R2最大时对应的特征子集作为构建模型的特征组合。
RF是多棵决策树构成的集成模型,模型的最终输出结果由森林中的每一棵决策树共同决定,在RF中以每棵决策树输出的均值为最终结果。RF算法的具体过程[30]如下:在原始训练特征集中用Bootstrap抽样方法获得n个特征子集;对每个特征子集选择m个特征,并对每个训练特征子集构建决策树,得到n个决策树模型,建立起随机森林;计算每棵决策树的结果,将n棵决策树输出结果的均值作为最终结果。此外,RF算法提供了特征重要性(总和为1)的接口,方便比较建模特征的重要性。经过参数优选和多次训练,确定RF的主要参数决策树数量为1 000。
1.5 模型评价
为了减少训练样本划分偶然性带来的结果误差,本研究采用10折交叉验证确保模型的稳定性。在10折交叉验证中,试验数据样本被划分为10份,轮流将其中9份作为训练集,1份作为测试集,将测试集结果取平均值作为模型最终的评价结果。
本研究采用决定系数(Coefficient of determination,R2)和均方根误差(Root mean square error,RMSE)评价AGB估测模型的精度,计算公式如下:
(1)
(2)
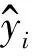
2 结果与分析
2.1 原始光谱和一阶微分的SPA特征波段提取

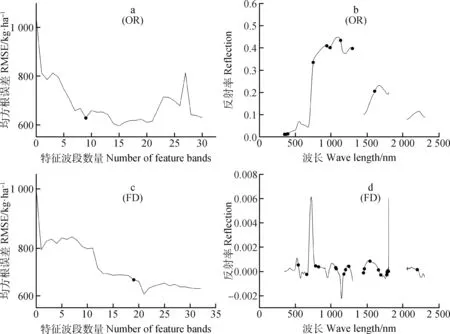
图2 SPA特征波段提取及波段分布Fig.2 SPA feature bands extraction and bands distribution
2.2 基于不同类型特征变量的AGB模型分析
对OR特征波段、FD特征波段、光谱位置面积参数PA和植被指数VI(表2)4类特征变量分别先进行RFE特征选择,将RFE选择出的特征子集作为RF的建模特征,再经过10折交叉验证,计算得到训练集和测试集的RMSE和R2(表3),并利用RF自带的特征重要性接口分析建模特征的重要性(图3)。

图3 不同RF模型的特征重要性Fig.3 The importance of features in different RF models

表3 不同类别特征变量的RF估测模型结果Table 3 Results of RF estimation model based on different class of features (n=179)
从模型精度来看,基于植被指数VI构建的RF模型精度最高(R2=0.70,RMSE=557.87 kg·ha-1),对应7个建模特征为NDBleaf,OSAVI,TCARI,MTCI,PRI,SIPI,VARIg;光谱位置面积参数PA和一阶光谱特征波段FD的模型精度次之,分别为R2=0.64(RMSE=596.42 kg·ha-1)和R2=0.57(RMSE=685.96 kg·ha-1);精度最差的是原始光谱OR特征波段构建的RF模型,测试集R2仅为0.52(RMSE=700.06 kg·ha-1)。从RF模型构建的特征来看,经过RFE特征选择后,4种模型的特征数量都有所降低,尤其是VI构建的RF模型,特征数量从26减少到7,在较大降低数据维度的同时,模型精度也最高,其中由R800和R450构建的结构不敏感色素指数SIPI的重要性最高(0.47),其次是由R531和R570构建的光化学反射系数PRI(0.25),这两个特征为模型贡献了72%的重要性。
对全集数据(n=179)进行实测生物量与估测生物量的相关性分析,结果表明,在4类特征变量中,基于植被指数VI的RF地上生物量反演模型的估测效果最好,其线性决定系数R2达到0.72,其次是光谱位置面积参数PA(R2=0.68),再次是一阶光谱特征波段FD(R2=0.59)(图4),模型估测效果最差的是原始光谱特征波段OR,其实测AGB和估测AGB的决定系数R2为0.56,这和测试集的10折交叉验证评价结果相一致。
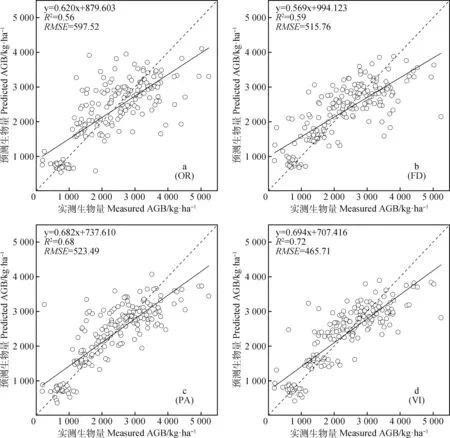
图4 不同RF估测模型的实测AGB与估测AGB的相关性Fig.4 Correlation between measured AGB and predicted AGB in different RF estimation models
2.3 基于不同类型特征变量组合的AGB模型分析
进行不同类型特征变量组合时,考虑到OR特征波段和FD特征波段都属于单波段特征变量,因此可以将其作为整体,与光谱位置面积参数PA和植被指数VI任意组合,进而进行RFE特征选择和RF模型构建。表4结果显示,在5种组合中,PA+VI组合的模型精度最高,R2达到了0.71,其对应的RMSE也最小,为548.97 kg·ha-1;精度次之的是所有变量构建的模型,拟合系数R2=0.70(RMSE=562.93 kg·ha-1);OR+FD组合与OR+FD+PA组合的模型精度居中,R2分别为0.69和0.67(RMSE分别为579.00和591.17 kg·ha-1);OR+FD+VI的模型精度最差(R2=0.64,RMSE=620.05 kg·ha-1)。从模型的建模特征及其重要性结果(图5)来看,模型精度最高的PA+VI组合,是所有组合中特征数量最少的,仅有5个建模特征H,Dr,VI2,PRI和SIPI,其中特征重要性最高的是VI2和PRI,分别为0.37和0.30,二者为整个模型贡献了67%的重要性;模型精度次之的全部变量组合,有6个建模特征,其中PRI和VI1的重要性最高,分别为0.30和0.26;OR+FD组合有7个建模特征,最重要的特征是R350,重要性为0.24;OR+FD+PA组合和OR+FD+VI组合的建模特征最多,均为10个,重要性最高的特征分别是VI2和PRI。

表4 不同类别特征变量组合的RF估测模型结果Table 4 Results of RF estimation model based on different combination of class of features (n=179)
利用全集数据(n=179),对不同类型特征变量组合RF模型的实测生物量与估测生物量进行相关性分析(图6),可以得出,在不同的特征变量组合中,基于光谱位置面积参数PA和植被指数VI的组合PA+VI的模型AGB估测效果最好,其线性决定系数R2达到0.73,均方根误差RMSE为476.93 kg·ha-1;估测效果次之的是OR+FD+PA+VI所有变量组合(R2=0.72);OR+FD组合和OR+FD+PA组合的AGB模型估测效果一致(R2=0.68);OR+FD+VI组合的RF模型的AGB估测效果最差,其实测AGB和估测AGB的决定系数R2为0.66。可见,不同类型特征变量组合模型的整体估测效果和其测试集10折交叉验证的评价结果基本一致。

图6 不同RF估测模型的实测AGB与估测AGB的相关性Fig.6 Correlation between measured AGB and predicted AGB in different RF estimation
3 讨论
与传统的统计方法相比,机器学习模型适用于较大规模数据和复杂场景,更关心模型的可用性与预测能力[15]。本文用RF构建的最优高寒草地AGB估测模型(PA+VI组合)的测试集精度为R2=0.71,全集的预测精度为R2=0.73,在不破坏草地的同时能够快速测定AGB。
特征选择是高光谱数据模型构建前的一个重要步骤,主要起数据降维和模型简化的作用。本研究先后用SPA和RFE算法进行草地AGB建模变量的筛选,其中SPA算法主要用于连续光谱的特征波段提取。本研究表明,SPA将OR和FD的波段数量从1 551个分别减少到9个和19个(图2),可极大地降低数据的维度,但在特征波段提取时,SPA并未选择RMSE最小时的波段数量,而是综合考量波段数量和RMSE对模型的影响,选择了适宜数量的特征波段,这和王承克[31]、吴迪[32]等的研究结论相一致。此外,OR的SPA特征波段主要集中在740,950,1 100和1 300 nm等附近,其中740 nm属于红边范围,950,1 100和1 300 nm属于近红外范围。有研究表明红边包含了可以表征生物量、叶绿素等参量的光谱信息[33],而920~1 120 nm之间的近红外波段很有可能与叶片水分和干物质的吸收有关[34],1 300 nm波段则和杨晨波等[16]对冬小麦的地上干生物量的敏感波段的提取结果相近。
不同类型特征变量的RF估测模型结果表明,PA和VI的建模精度好于OR,FD特征波段的建模精度,这可能与PA和VI是由多个波段组合计算的指数,而OR,FD特征波段是单波段有关,在一定程度上说明了PA和VI等波段组合指数比OR等单波段包含的光谱信息丰富。在不同类型特征变量组合的RF估测模型结果中,精度最高的是PA+VI组合,其仅有5个建模特征,是所有组合中建模特征数量最少的组合,其中特征VI2和PRI为整个模型提供了67%的重要性。VI2是红谷吸收深度D和绿峰反射高度H的归一化指数(表2),能较好地反映草地生物量等参量,如胥慧等[10]的研究表明(D—H)/(D+H)和草地生物量的相关系数达到0.660。PRI指光化学反射系数,是R531和R570的归一化指数[35],能反映植物光合作用过程中光能利用效率,可用于研究植被生产力[36],道日娜[37]研究发现,重度放牧时草地生物量最小,此时的PRI也最小,因此PRI也能较好的反映草地的AGB。
然而,本研究也存在一定的局限性。例如,机器学习是个典型的数据驱动的问题,通常需要大量的数据[15],而本研究的样本数为179条,这对机器学习而言数据量较小,可能对模型的精度造成一定的影响。放牧干扰行为也可能影响到模型最终结果:苏日古嘎[38]研究发现,与未放牧草地相比,放牧会改变草地植被的群落物种多样性、优势度和植物种群的空间异质性,且不同放牧家畜对草地植被的影响程度不同;还有研究表明,由于长期围栏放牧家畜的践踏和选择性取食,导致植被环境斑块化[39],以上行为都会改变草地植被冠层的结构组成,使获取的高光谱反射率呈现不同的特征,进而对RF模型的精度造成一定的影响。此外,由于ASD光谱仪测定的是目标物“点”的光谱数据,是350~2 500 nm全光谱段(间隔1 nm)的观测结果,由大量窄波段组成,所选最优模型变量也由其中部分特征波段组成,但目前可用的高时空分辨率的光学遥感卫星通常只有宽波段的观测结果,后续将进一步研究最优模型变量的特征波段和遥感影像波段的对应关系,进而实现大面积草地AGB的模型构建和反演。无人机高光谱成像技术具有获取数据快、操作灵活等特点,现被越来越多地应用到农作物等的监测,如陶惠林等[40]借助无人机高光谱遥感平台,获取了冬小麦各生育期的无人机影像,提取了植被指数和红边特征,最终构建了冬小麦产量模型。与ASD地物光谱仪相比,无人机高光谱成像技术的覆盖面积更广,因而可以构建较大尺度的生物量估算模型,这对高寒草地AGB的遥感估测具有参考意义。
4 结论
SPA可有效降低高光谱数据维度,使原始光谱OR和一阶微分光谱FD的波段数量分别减少了99.4%和98.8%。在4种特征变量分别构建的草地AGB估测模型中,基于VI的RF模型精度最高(测试集R2=0.70,RMSE=557.87 kg·ha-1),建模特征为NDBleaf,OSAVI,TCARI,MTCI,PRI,SIPI,VARIg,其中特征SIPI和PRI共为模型贡献了72%的重要性,实测AGB和估测AGB的线性决定系数R2达到0.72。不同类型特征变量组合构建的草地AGB估测模型中,PA+VI组合的RF模型精度最高(R2=0.71,RMSE=548.97 kg·ha-1),建模特征为H,Dr,VI2,PRI和SIPI,其中特征VI2和PRI共为模型贡献了67%的重要性,实测AGB和估测AGB的线性决定系数R2达到0.73。整体而言,相对OR,FD等特征变量,PA,VI的特征变量组合构建的草地AGB的RF模型精度较高,建模效果更好。
猜你喜欢
今日农业(2020年19期)2020-12-14
幼儿100(2020年31期)2020-11-18
疯狂英语·初中版(2019年4期)2019-09-10
小太阳画报(2018年6期)2018-05-14
电子制作(2018年2期)2018-04-18
制导与引信(2017年3期)2017-11-02
高师理科学刊(2016年8期)2016-06-15
中国科技信息(2015年2期)2015-11-16
西藏科技(2015年4期)2015-09-26
植物营养与肥料学报(2014年1期)2014-03-11
