
基于H-op组合算法的财务数据特征预测系统设计
2021-09-06 08:55吴笛
喀什大学学报 2021年3期
吴 笛
(新疆财经大学 统计与数据科学学院,乌鲁木齐 830012)
我国市场存在着严重的信息不对称问题,投资者能够获取的财务信息大多来自企业的公告,但是由于利益问题,上市公司的实际财务情况往往与预测值相差巨大,这非常有损于投资者的利益[1-2].因此与财务数据特征相关的预测就成为当前研究的热点,其中预测的核心指标就是围绕着企业核心利润展开的[3].当前一部分财务状况较差的企业,并不是很愿意披露自身的盈利状况及预测情况,并且这类企业的财务披露问题也与其所在行业存在一定关联[4].在互联网时代,大量学者已经开始对企业相关的财务数据进行处理,并应用科学的方法找到数据间存在的关联,同时采用模型选择最优算法[5].随着计算机算法的不断发展,越来越多的高级算法开始应用于各大行业,尤其是一些非常适合某种行业的机器学习算法[6].本研究将混合最优选择算法(Hybrid optimization,H-op)应用到研究样本数据中,以便对企业财务数据进行有效的预测,旨在找出当前行业研究适用的最优算法,为用户或企业提供财务盈利预测结果.
1 基于H-op 组合算法的财务数据特征预测系统设计
1.1 预测系统模块及混合最优选择H-op 算法设计
本次系统设计的目的主要是为了提升用户对企业财务特征预测的判断能力,预测系统主要包括企业活力、风险评估、固定资产以及利润四大模块,财务数据特征预测系统的功能模块如图1 所示.
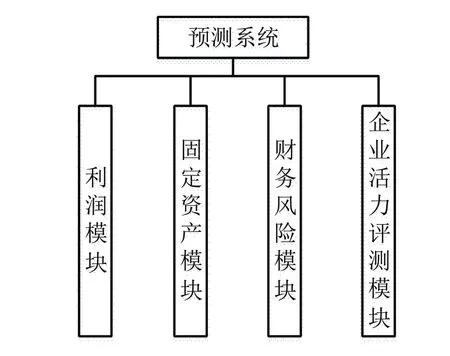
图1 财务数据特征预测系统的功能模块
预测系统中的四大模块在不同程度上反映出了企业的财务状况,不仅有与财务状况密切相关的模块,也有与活力、风险等潜在因素相关的模块.这些模块的应用,能够为用户提供企业当前的财务状况及未来可能发生的情况[7].采用图例及文字表情将预测信息传递给用户,同时系统会自动进行预测结果的存档,以便于以后的搜索[8].本研究主要针对数据处理与算法最优选择方面的问题,采用对不同学习算法进行对比的方式,优选出适用于不同行业的学习算法,以对不同行业自动进行算法筛选,从而提升运算效率.
本文主要研究的算法为混合最优选择算法,同时对7 种机器学习算法进行对比研究.该算法主要对行业特征进行构建后,对不同的行业运用了不同的机器学习算法与归一化处理方法,Hop 主要是对不同行业的样本数据进行了训练,并依据行业预测评价标准进行预测对比,选取出最优模型应用到行业预测工作中[9].本研究的样本数据是由网易财经所提供,均为我国上市公司历年来的季度财务报表,运用爬虫方式将数据保存至表格中备用,包括了现金流量表、利润表、资产负债表.整理相关样本数据,由于不同表格的数据存在着相对独立性,对机器学习的训练造成一定影响,所以本研究将现金流量表、利润表、资产负债表进行了合并,并采用上市公司股票代码作为标识,再转置得出表格,这样便能得到合并后的表.该表纵轴表示按照时间序列分布的数据值,横轴表示数据特征,如图2 所示.
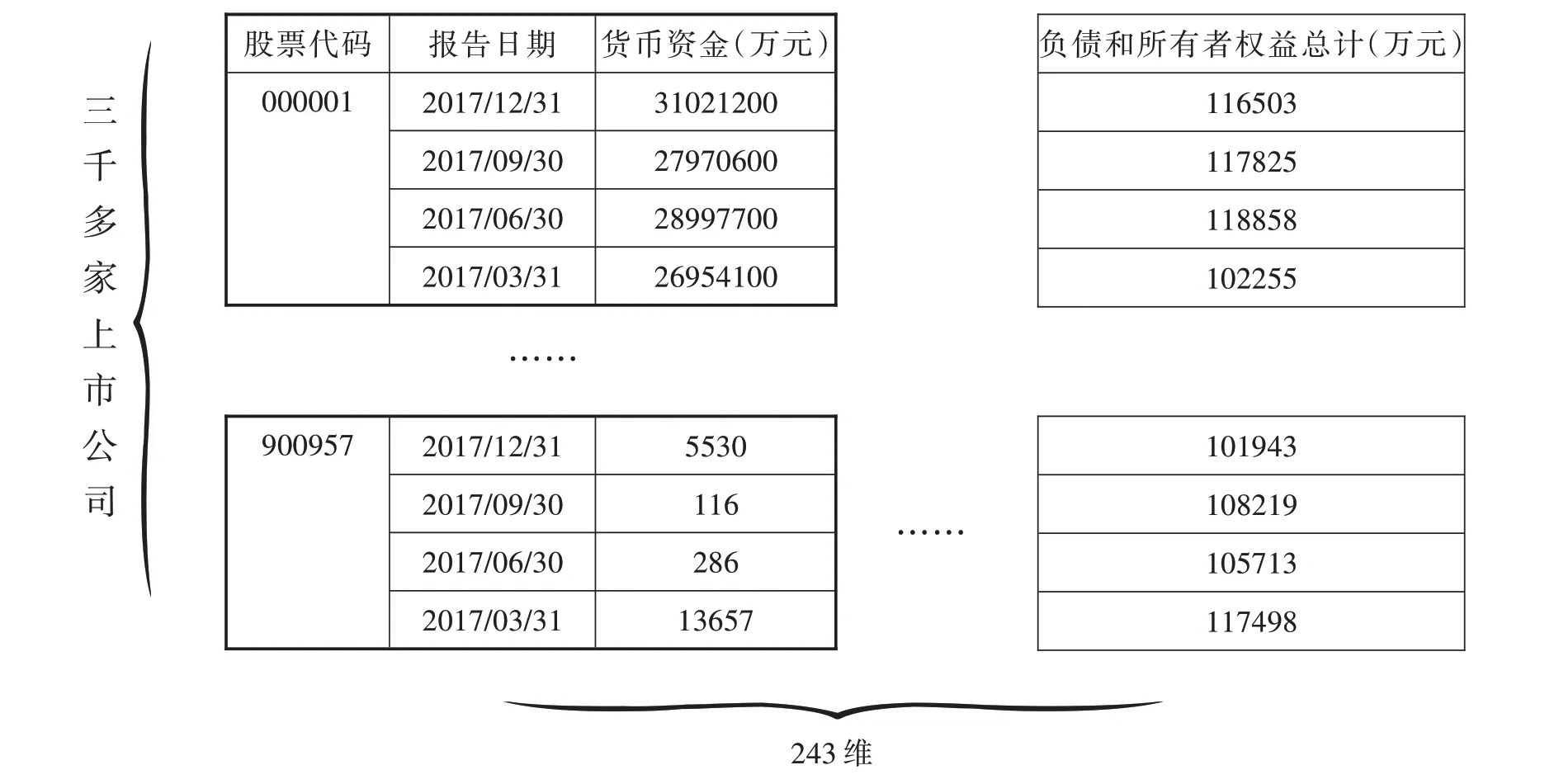
图2 数据资料整合
由图2 可以看出,合并后的数据特征综合了现金流量表、利润表、资产负债表的数据特征,包含了243 个数据特征,上市公司数量超过了三千家,并且均包括了十年以上的季度报表数据.通过对数据特征进行观察后,可以看到随着各年度季度的增加,数据值也随之增加,为了使本研究不会受到数据值逐年增加的影响,对数据进行一次递减,并按照季度划分的方式将表格数据进行相对独立的整理.
由于不同行业之间存在着不同的影响因素,财务数据特征的预测是否合理,还是要对具体的行业进行区分,这样也能够有效提升模型的训练效率.这就需要对数据集提前进行行业划分,对独立的行业样本数据进行独立表格整理[10].本研究根据当前上市企业行业划分标准,对我国三千多家上市企业进行了行业划分,划分出61 种行业,并单独对各个行业进行独立表格整理,行业分类如表1 所示.

表1 行业分类(部分)
由于本研究的样本数据较为特殊,报表合并后存在大量的数据特征,因此要提前筛选出适用的数据特征,并统计数据特征的个数.由于部分数据特征存在缺失情况,故将该类部分数据进行剔除,以避免对预测结果的干扰[11].保留85%以上的数据特征,并选取剩余部分数据的特征.还要对某些行业的数据存在的特殊情况进行分析,有时某一个数据的特征,在绝大多数行业中数值极低,然而在个别行业中数值却极高,甚至高于90%.本研究列举了个别特征进行观察,如数据“手续费及佣金收入”的特征,在大部分行业中均低于10%;然而在券商信托与银行行业中,数值却非常高,银行行业竟达到了99%.如图3 所示.

图3 比较不同行业的“负债合计”“手续费及佣金收入”特征数值
由图3 可看出,全部行业中“负债合计”均保持在100%左右,然而“手续费及佣金收入”,却只有银行行业与券商信托行业最特殊.同样也有许多相似的情况,例如“保险合同准备金”与“所得税费用”的数值统计情况,如图4 所示.由图4 可知,全部行业中“负债合计”均保持在95%左右,但“保险合同准备金”在大部分行业中保持在0上下,只有保险行业数值最为特殊,在75%上下.此外,有许多数据特征具有显著的行业差异性.
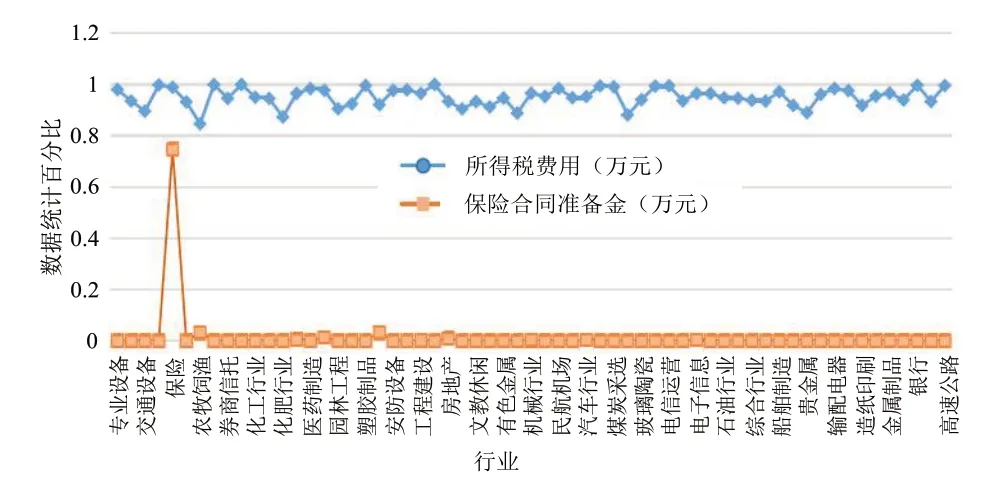
图4 比较不同行业的“所得税费用”“保险合同准备金”特征数值
为了确保预测结果的准确性,本研究应用了python 软件对数据特征与利润进行了相关性分析.画出每个行业的独有的特征图,并进行对比观察,筛选出二者中呈现正相关的数据特征,进行数据记录.通常会因为数据量过于巨大,导致分析时间与成本较高,并且难度也非常高.本研究对相同行业中的公司进行随机抽样,共进行3轮,每轮抽取2 个公司,总计对6 个不同的公司进行数据特征的相关性分析.将数据相关性较高的特征选作行业预测特征,剔除相关性较差的数据,并将分析结果进行整合.例如“保险合同准备金”特征在保险行业中的呈现出较高的正相关性,所以该特征相对于保险行业为有效特征,而该特征在安防设备行业却显示非常杂乱,因此在安防设备行业中应剔除“保险合同准备金”特征.因此,相同的数据特征会在不同行业中具有不同的相关性.
从分析整理完成的数据,可以看到数据特征不同也会引起数据量级的不同,造成在预测时结果会偏向于数据差值较大的特征,因此要对样本数据运用归一化处理方法,以使不同数据特征间具有可比性[12].例如某些大型企业经营状态良好,盈利远高于中小型企业,因此其本身盈利值数据特征相对大很多.为了能够消除这种差距给预测结果带来的影响,本次研究将对样本数据进行归一化处理,以便数据之间具有可比性,提升了后期训练优化的准确度,最终可得到相对准确的预测值.归一化主要包括了极差、标准、正则三种方法,分别如下式所示:

式(1)-(3)中,max为最大值,min为最小值,xi为当前数据,std为标准差,mean为平均值,l1,l2均表示正则化.归一化处理是将数据转化成[0,1 ]之间的数值,且不同归一化处理方法得出的结果不同,所以归一化处理也会影响到算法的优化,选取合适的归一化处理方法能够很好提升算法效率.
机器学习算法通常有较多参数,本研究对各种学习算法设定了固定参数,例如在LSTM 中设定迭代次数为80,学习率为0.0001,神经元个数为100.决策树参数选取为默认,随机森林决策树个数选取为80~100,支持向量机迭代次数为1000~10000,并且LSTM主要由pytorch框架来进行优化.
1.2 设计评估标准
通常对算法的评判标准为算法的准确度,本研究的重点为回归问题中的数值误差.对于系统中财务样本数据的评判,要对行业规范具有一定的了解.盈利预测可靠性的计量指标为平均预测误差率与预测误差率.由于本研究主要是对企业财务特征进行预测,因此只对误差进行判别,不考虑具体误差的乐观度.在进行预测过程中,为了确保预测结果不为负,需要对公式进行调整,对公式取绝对值,预测误差率的计算如下式:
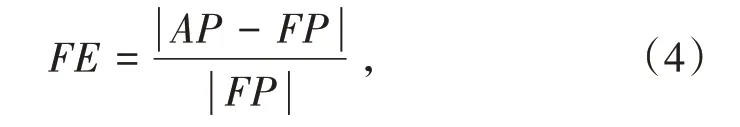
式(4)中,FP表示预测值,AP表示实际值.而平均预测误差率如式
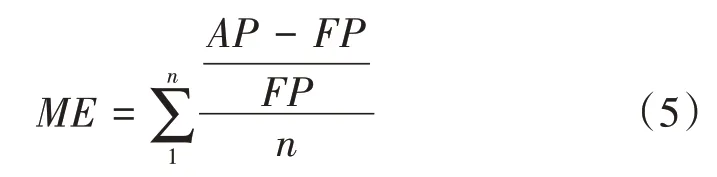
所示.
将我国上市公司财务特征预测可靠性标准设定为三类:一是FE≤10%,可靠性较高;二是10%<FE≤20%,可靠性一般;三是FE>20%,可靠性很差.上述标准为评判标准,为确保算法的有穷性,若预测结果收敛于迭代范围内,则将结果输出;若预测结果不能在迭代范围内收敛,则对比最大迭代次数.选取上文中所述适合的归一化处理方法能够较好地提升运算准确度.因此,本研究将按照以上评判标准,以银行行业、软件服务业为例,对比三种归一化处理方式的结果,能够较好地看出不同归一化方式对结果准确率的影响.
2 系统算法混合最优选择H-op测试分析
2.1 不同机器学习预测算法在不同行业中的应用对比
本研究首先以银行金融业为例,应用归一化方法对测试数据进行了处理,并将实际结果与机器学习预测结果进行对比,如图5 所示.
由图5 可以发现各种算法对银行业存在不同程度的影响,为了方便观察对比结果,这里将以准确率的形式进行各种算法的对比,结果如图6 所示.
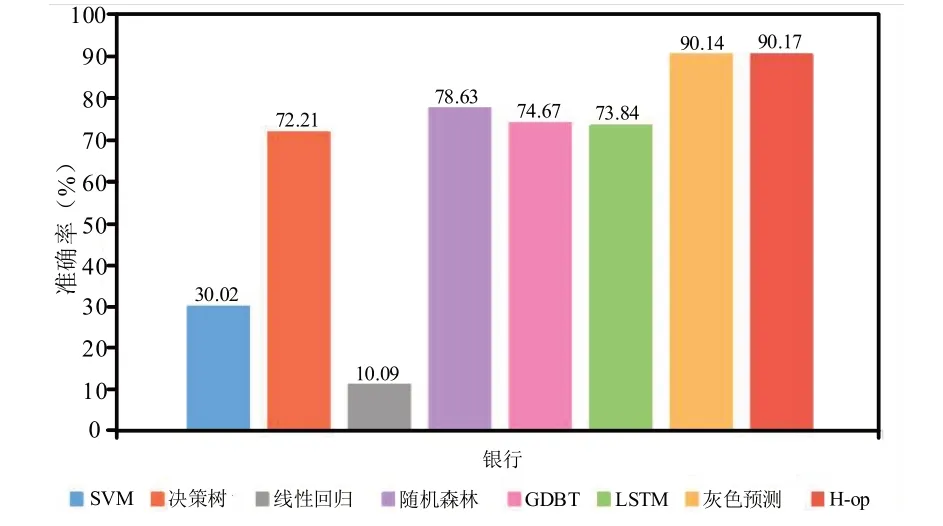
图6 银行行业结果准确率对比
由图6 可以看出,H-op 在学习与归一化方法组合后,选取了银行行业中准确率最高的灰色预测算法.为了能够更为全面的展示结果,本研究还针对软件服务业,对该行业的相关数据进行了不同机器学习方法的预测,并与实际结果进行对比,结果如图7 所示.
由图7 可知,在各种算法中预测值与真实值几乎完全重合,并且不同学习方法对软件服务业也具有不同预测效果.本研究以准确率为标准,比较各种学习算法之间的准确率,结果如图8 所示.
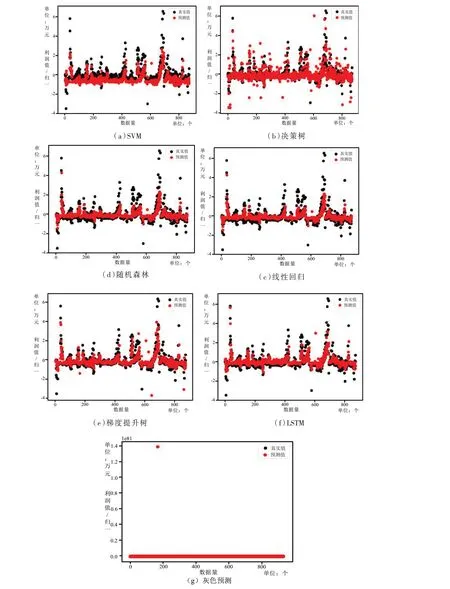
图7 软件服务业误差图

图8 软件服务业结果准确率对比
由以上分析对比可以得出,银行行业中采用灰色预测算法更为合适,而软件服务业则除了灰色预测算法外,其他算法均表现较好,因此,应该针对各自行业的适用学习算法进行进一步优化,以提升相关行业的预测准确率.
2.2 财务数据特征预测系统算法性能测试
根据相同的对比方法,本研究整理60 多类行业的算法选择表,作为系统算法选择的依据.如表2所示.

表2 系统算法选择表(部分)
在设计的系统中导入表2内容,由表格内容来决定行业预测算法的选择.在进行系统预测时,首先要输入行业代码,系统会根据行业代码进行行业判定,从而选择合适的学习算法进行预测,并将预测结果进行记录,把预测结果显示在初始财务整合表内,以备今后数据的查询.这样节省了学习算法的学习耗时,增强系统的运算效率.其次,要对本研究所提出的H-op 组合算法进行测试,测试内容包括了算法的搜索时间和搜索结果的验证.在系统中输入行业代码时,系统会直接进行行业判定,并依据行业的不同选择计算效率最高的算法进行预测,并将预测结果返回,预测结果如表3所示.

表3 算法预测结果
由表3 可知,在系统中输入不同行业代码时,系统响应速度快,且输出结果均正确,反映出算法性能优越,同时具有非常高的稳定性.所以文中提出的算法测试结果优良,整体测试效果符合设计预期.
3 结论
本研究针对企业财务数据的预测问题,对基于H-op 组合算法的财务数据特征预测系统进行了设计研究.结果显示,在银行行业中采用灰色预测算法更为合适,而软件服务业则在各种算法中预测值与真实值几乎完全重合,并且不同学习方法对软件服务业也具有不同预测效果,除了灰色预测算法外,其他算法均表现较好;设计算法节省了学习算法的学习耗时,增强系统的运算效率;整理60 多类行业的算法选择表,作为系统算法选择的依据;在系统中输入不同行业代码时,系统响应速度快,且输出结果均正确,反映出算法性能优越和非常高的稳定性.因此本文提出的算法测试结果优良,整体测试效果符合设计预期.
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
当代陕西(2019年10期)2019-06-03
证券市场红周刊(2018年33期)2018-05-14
证券市场红周刊(2018年10期)2018-05-14
证券市场红周刊(2018年5期)2018-05-14
