
茶叶全产业链大数据中心功能设计与开发进展
2021-09-03 03:20陈富桥
农业大数据学报 2021年2期
陈富桥 凌 晨
(中国农业科学院茶叶研究所,杭州 310008)
1 引言
近年来,国家高度重视智慧农业、数字农业的建设。应用大数据可以为农业生产者提供实时、准确、完善的农业数据信息、相关政策与法规[1]。我国是全球最大的茶叶生产与消费国家,茶产业也是我国重要的传统优势特色产业,生产模式仍比较传统[2],产业数字化应用水平仍然比较低[3]。主要表现为如下方面:一是数据采集难度大,由于茶叶产业链条长,涉及经营主体多,数据采集困难,采集标准体系不完备,采集手段比较落后,导致茶产业基础数据匮乏,现有数据不够系统,不能支撑产业高质量发展需求;二是现有数据缺乏有效的统一管理平台,现有和茶产业相关的数据资源零散分布在互联网各终端中,没有专门针对茶行业领域的数据中心平台,导致茶产业数据整合困难;三是缺乏茶叶全产业链数据决策平台,不能使现有数据发挥效用。
为了适应茶产业对大数据技术采用的迫切需要,根据农业农村部发布的《关于抓紧申报2019 年数字农业建设试点项目的通知》,2018年10月中国农业科学院茶叶研究所上报了茶叶全产业链大数据建设试点项目的可行性研究报告,2019 年4 月2 日,中华人民共和国农业农村部(以下简称“农业农村部”)农规发〔2019〕9 号文件批复了项目可行性研究报告,2019年11 月14 日,农业农村部以农办规〔2019〕58 号文件批复了项目初步设计和概算。随后,项目进入正式实施建设阶段。截至目前,按照初步设计批复的规模、功能、平面布局和建设内容完成了全部建设任务,实现了预期的建设目标。2021 年3 月22 日,取得了茶叶数手机软件V1.0、茶叶全产业链大数据平台采集系统V1.0 和茶叶全产业链大数据平台门户网站平台V1.0 三个软件著作权。通过前期的建设,项目目前已经具备数据采集、分析和发布能力,茶数APP 作为数据采集终端,显著提升了数据采集的效率和质量。消费趋势数据、电商数据、舆情监测数据已经具有明显的辅助决策能力,对全面把握茶产业年度运行规律、产业政策制定、指导科学决策开始发挥作用。同时作为数据采集平台,项目显著提升了全国茶产业数据的汇聚能力,对协调统筹产业数据发挥了枢纽作用。
2 茶叶全产业链大数据平台设计
2.1 茶叶全产业链大数据平台定位
平台定位为国家级茶叶全产业链大数据中心,专业开展茶产业数据的采集、存储、挖掘工作,为涉茶政府部门、经营主体、科研机构、公众等提供专业权威的数据服务。
2.2 茶叶全产业链大数据平台建设目标
中心致力于解决茶产业基础数据分散匮乏的问题,支撑茶产业科学决策,助推我国茶产业数字化转型。项目完成后将形成一个“1+3”的大数据中心体系,即建成1 个国家茶叶全产业链大数据中心机房,依托大数据中心机房建成1 个大数据采集系统,1 个大数据挖掘系统,1 个大数据共享系统。项目正式运转后,依托大数据中心发布一系列茶产业分析报告,发布茶产业杭州指数,打造成国家新型茶产业智库,支撑茶产业科学决策精准施策。同时,依托项目带动我国茶业经济与信息研究学科的发展。
2.3 茶叶大数据系统技术路线
茶叶大数据中心总体技术实现基于现有机房环境,以面向SOA 服务的方式进行总体设计,通过服务总线接入、整合各种资源和服务,确保大数据中心工程应用、内部应用协同、部门间协同过程中提供的各种资源和功能,以虚拟集群服务的方式提供服务,实现内部各种资源的整合、融合与有效共享,以降低各个模块之间的耦合度,增强系统的柔性和扩展性[4][5]。茶叶大数据中心将充分利用云计算资源中心,通过虚拟化技术对服务器、存储、网络的池化和有效管理,为整个农业大数据中心提供按需获得、即时可取的计算、存储、网络、操作系统及基础应用软件等资源,整体技术架构如下:
其中,数据层是大数据技术的核心,它实现了数据采集,数据存储以及数据预处理三大重要功能,数据层处理的数据也将直接影响到数据挖掘的准确性,其运用到的核心技术组件及架构如下:
(1)数据资源层:
数据源层主要描述大数据平台的源数据格式,分为结构化数据,包括各业务数据库数据;半结构化数据,包括Json 格式及XML 格式数据流;非结构化数据,包括图片、视频、word 文件、excel 文件等及流式数据等[6]。
(2)数据采集层:
数据采集层主要描述如何从数据源层中获取有价值的数据。数据采集层采用各类ETL 组件,包括Kettle,Sqoop 实现不同数据源数据的全量采集及增量采集的需求。采用Spark Streaming+Kafka 的方式实现流式数据采集[7]。
(3)数据存储层:
数据存储层主要满足包括结构化数据、半结构化数据、非结构化数据的存储需求。由HDFS 满足非结构化数据存储;HBase 满足半结构化及非结构化数据存储;Hive 构建数据仓库;选用Redis 作为内存数据库;MySQL 满足结构化数据存储需求[8]。
(4)分析挖掘层:
分析挖掘层提供基于Spark 实现的分布式内存计算框架,基于MapReduce 实现的分布式离线计算框架,由Spark Streaming 实现流式数据分析,由Spark MLlib 及Tensorflow 提供机器学习算法及深度学习框架,由Apache Kylin 提供支持超大规模数据的,基于Hadoop/Spark 之上的SQL 查询接口及多维分析(OLAP)能力,由Apache Phoenix 提供HBase 上的OLTP 分析及事务处理能力[9][10]。
(5)平台运营:
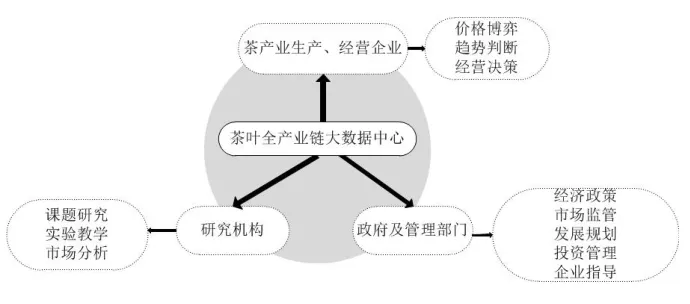
图1 建设目标Fig.1 Construction target

图2 茶叶全产业链大数据中心整体技术路线Fig.2 Overall technical route of big data center of tea industry chain

图3 大数据技术核心架构Fig.3 Core architecture of big data technology
基于Ambari 大数据管理平台实现统一配置化管理,集群监控告警,自动化部署等功能,集成Zoo‐Keeper 实现分布式程序协调,Azkaban 实现作业的调度监控管理。
(6)数据应用
数据应用层为数据的各类业务应用及可视化展示提供支持,对应用层各数据应用基于业务进行功能拆分,使用Spring Cloud 搭建微服务框架提供对内及对外服务;采用Spring Boot +Vue.js+Mybatis 为业务应用层框架,ECharts.js提供可视化图表库[11][12]。
3 平台模块化布局与主要功能
整个大数据平台涵盖了数据获取与数据管理、数据存储与数据处理、数据分析与数据理解等任务,搭建统一的数据交换和协同工作的信息平台,建设统一应用接口支撑引擎系统,实现对茶业全产业链大数据的综合管理与服务。
3.1 大数据中心平台门户网站及其布局
门户网站为大数据中心集展示、共享、管理、服务为一体的中枢系统。门户首页根据项目内容和目标设置8 个专栏模块菜单,分别为:首页、中心动态、数据仓库、全球茶业、中国茶业、服务平台、决策平台、运维平台、登录注册。中心动态栏目用于发布中心建设、内容更新、交流进展;数据仓库主要为全部数据库概览和使用入口,是数据库查阅使用的唯一入口;全球茶业与中国茶业是基于地图可视化的茶业大数据指挥舱系统,按照主体内容进行国内外茶数据概况的演示;服务平台为面向产业开展基础服务的功能集成,包含审评系统、专家系统、咨询系统和调研系统,每个服务板块与数据库或管理系统进行匹配关联。决策平台是基于大数据开展的可视化决策模块,设置茶叶指数、舆情热点、竞争态势、消费趋势、科技前沿、茶业电商、数字标本和研究报告子栏目,部分与指挥舱关联,可调用指挥舱或GIS 地图,与BI 或数据挖掘运算系统关联。运维平台主要是针对大数据管理工具系统的集合,包括采集系统、运算系统和发布系统。同时在首页醒目位置添加了基于移动端的茶数APP二维码。

图4 门户网站及其布局Fig.4 Portal website and its layout
3.2 茶数APP及其布局
为了顺应无线网络和移动端数据化应用的趋势,同时拓展大数据中心数据采集和查询的方便性和可及性,茶叶大数据中心专门开发了茶数APP 手机端软件,作为整个大数据平台的一个有机整体,茶数APP 与大数据中台进行直接关联。茶数APP 设计以简洁实用为主要原则。设置首页、报数、查数、供求、我的5 个功能菜单。首页主要用于动态与成果发布,让用户及时了解茶产业相关咨询。报数功能主要方便基于移动端的数据采集,内置了不同产业主体需要定期固定填报的数据指标;查数部分主要方便用户基于移动端随时随地进行大数据中心的数据查询;供求主要让茶叶主产区政府、协会、龙头企业、消费者、经销商进行茶叶供求信息的发布,同时兼顾品牌推广与宣传功能。
3.3 数据采集与数据仓库
目前,我国茶产业数据共享的主要问题是缺乏完善的数据采集与管理机制,科研人员普遍重视成果产出,而对数据汇集和利用重视不足,制约了我国茶产业数据共享及数据中心的可持续发展。数据采集是茶叶全产业链大数据建设最基础也是最具亮点的系统,本项目结合茶产业的实际情况,按照PC端与移动端相结合的方法,采用线上汇聚、数据直报和问卷调查三种数据采集方式,同时对采集的数据进行分类统一进入相应数据仓库。
3.3.1 线上汇聚
线上汇聚可实现对互联网上与茶产业发展相关的数据进行专业性、精准性的数据采集。可对新浪博客等社交平台的舆情热点进行跟踪监测采集,可对各大电商数据关于茶叶销售数据的监测汇聚,可对FAO、ITC 等机构网上公开的与茶相关数据进行自动下载管理,可对中国茶叶网等平台的新闻进行抓取,采集完成后自动形成专题数据库。
3.3.2 直报系统
直报系统可建立面向茶产业种植、加工、流通、消费等环节数据采集点,相关管理部门、调研员的网上数据直报系统,可实现通过PC、手机、PAD 等终端进行数据的实时在线填报,实现各项直报数据进行集中式管理。为茶叶行业企业、政府机构、科研单位等用户提供了基于可定制流程进行数据采集和报送的功能。支持流程的定制修改,多层级的填报下发,流程和填报权限控制,能灵活应对各种数据报送的需求。针对茶产业用户中实际的应用场景和业务需求,设计定制流程,进行流程化的填报任务下发,完成数据填报采集、数据审核、数据汇总等一系列工作,提高数据采集和业务运转的效率。
3.3.3 问卷调查系统
问卷系统是结合不同主题的茶产业研究课题、针对分布在各互联网终端的用户而设计的。在线问卷调查系统能够便捷直观的进行问卷设计,问卷可以实现在线发布或通过第三方平台进行发布,可进行问卷数据实时回收与管理,具备在线问卷调查筛选识别功能,避免重复填报,是针对消费者行为跟踪的调查模块。
3.3.4 数据仓库
在经过多种采集手段后,得到的数据将汇聚到数据仓库。中心面向茶叶全产业链开展数据采集,建有基于第三方数据的基础公共性数据库和基于大数据中心自行采集的独有专业性数据库。未来会持续扩充与完善数据仓库体系,实现茶产业经济、文化与科技数据库全覆盖,实现茶叶数据的一站式查询。
3.4 数据挖掘与决策系统
中心建有功能相对完善的数据汇聚与挖掘平台。数据挖掘系统可实现混搭数据的融合和数据价值发掘,具备分析系统的功能、分析能力和计算能力。通过数据采集系统的治理及清洗,数据挖掘系统将基于这部分数据,进行指数编制、数学建模、查询统计、机器学习、可视化展示等工作,实现对数据的综合利用,为茶产业生产、管理与科学研究提供各类统计、检索、分析、识别、评估、预测、决策等服务。
3.4.1 可视化数据计算与通用计量模型运算平台

图6 线上汇聚Fig.6 Online convergence

图7 直报系统Fig.7 Direct report system

图8 问卷系统示例Fig.8 Example of questionnaire system
针对茶产业研究的不同主题所需要用到的不同的计量模型或机器学习算法,大数据平台也内置了数据挖掘平台,实现常用算法的封装,抽象为可以操作的各个组件,通过图形化拖拽的方式可以开发不同数据分析模型,同时提供命令行工具,集成目前主流的计量统计分析模型,可简单便捷的进行计量模型的抽取与运算。建成数据分析集成算法库后,通过对底层的分布式算法封装,提供拖拉拽的可视化操作环境。通过可视化运算平台,使用者不必了解算法的具体实现逻辑,方便以结果为导向选择合适的算法模型。
以决策树模型举例:1.从Data文件夹拖拽自定义的数据源到工作间2.从program 文件夹拖拽文件分割组件到工作间3.从program 文件夹拖拽模式识别与回归向量包到工作间4.从program 文件夹拖拽决策树工具包到工作间。
3.4.2 茶叶舆情监测系统
茶叶舆情与热点监测系统对互联网上涉及茶叶全产业链的政策信息、消费趋势、敏感事件等信息进行全面汇聚,开发舆情分析产品与服务,包括茶叶舆情预警服务系统、茶叶互联网舆情年度报告,为政府部门、生产经营者提供茶叶产业链社会关注焦点,进而为提前研判茶叶产业形势提供依据。利用NLP(自然语言处理)技术对带有情感色彩的主观性文本数据进行分析、处理、归纳和推理,得到消费者对某一地域、某一品牌或某一茶叶品种的情感分析。可以将消费者对产品的评价以数字的形式直观地展现,可以形成关键字云图。

图9 数据仓库Fig.9 Data warehouse
3.4.3 中国与世界茶业指挥舱系统
中国与世界茶业指挥舱系统分全球茶业和中国茶业,其中,中国茶业指挥舱主要从茶叶概况与布局、经营主体、地理品牌以及经济效益四大主题模块直观展示中国茶叶基本生产情况。茶叶概况与布局监测全国各省市县的历年茶叶种植面积、历年茶叶采摘面积、有机、无性系茶园面积、六大茶叶产量以及历年茶叶产量。经营主体模块监测全国茶叶合作社、龙头企业、批发市场、零售系统和茶馆茶楼的GIS分布情况。地理品牌模块记录全国各省份与茶相关的地理标志与驰名商标的详细情况。经济效益模块从茶叶总产值、茶叶单位面积产值、茶叶单位重量产值、茶叶生产价格指数、茶叶投入产出指数、茶叶采摘工平均工价六个维度解读茶产业经济效益发展情况。
3.4.4 茶叶消费趋势监测系统
茶叶消费趋势监测系统分季度监测电商平台的绿茶销售额数据、红茶销售额数据、普洱茶销售额数据、乌龙茶销售额数据、茉莉花茶销售额数据以及其他品种茶叶销售额数据。
3.4.5 茶叶电商大数据监测系统
茶叶电商大数据监测系统按时间维度监测各省份茶叶销量订单、各月份茶叶销量订单、热点城市茶叶销量订单、各茗茶销量订单以及各品牌销售金额情况。
3.4.6 数据挖掘应用场景案例

图10 数据挖掘平台决策树算法示例Fig.10 Data mining platform decision tree algorithm example
通过上述数据采集手段,平台将汇聚一批科学、权威、专业的的独有数据库,已建成数据库包括全球茶叶产销数据库(依据FAO、Trademap、国家统计局)、中国茶产业发展数据库(依据统计年鉴、各级政府统计数据)、茶叶企业成本收益数据库(依据茶叶所调研数据)、春茶产销数据库(依据茶叶所调研数据)、凯度城市家庭茶叶购买行为数据库、公共品牌与地理标志数据库(依据中国地标产品数据库)、经营主体数据库(依据高德地图、企查查)、昆虫标本数据库(依据茶叶所积累数据)、标准数据库等;其中茶叶主产区竞争力评估和决策能力将基于中国茶产业发展数据库的基础数据进行数据汇聚,将基于已有的计量分析模型计算县茶产业发展竞争力总得分,识别县茶产业发展竞争力提升的障碍因子,对所有已采集指标的障碍度进行排序,从而了解哪些因素对该地区的茶产业发展阻力最大。
4 总结与展望
目前茶叶全产业链平台在功能上已经实现了初步设想,具体来说:一是强化了数据采集能力,建设有多元化实用型的数据采集手段,根据不同的填报对象和业务,设置直报系统、线上汇聚、问卷系统以及移动app 等方式,使数据积累灵活、方便,为数据挖掘打下坚固的数据基础[13]。二是以结合已有工具手段,立足茶产业特点进行数据挖掘模型构建。三是采用模块化思路进行设计,本着从解决实际问题角度出发建成三大系统模块,各系统模块使用上耦合度低,独立性强,又在功能上相互联系,形成一个完整的数据分析闭环,达到可行、可用、易用的目标。

图11 茶叶舆情与热点监测系统Fig.11 Tea public opinion and hot spot monitoring system

图12 茶叶消费趋势监测系统Fig.12 Tea consumption trend monitoring system
平台各项功能尚处于调试完善阶段,根据调试和试用结果,后期拟进一步进行深化细化。重点包括如下方面:一是持续更新迭代软件系统。在后期使用中复现漏洞、排查漏洞、修复漏洞,同时在功能性和实用性上进一步提升,优化各项功能的使用体验。二是加快推进数据库建设和治理,对已有数据进行整理入库,同时开展数据采集点和网络建设。三是制定和推行茶叶大数据采集和治理标准与规范建设,为数据采集提供可以遵循的行业标准,特别是在数据采集标准、格式标准、端口兼容标准方面尽快出台细化标准,便于降低数据采集成本,提高采集特别是交互效率。四是积极探索大数据中心的运营模式。由于数据共享开放不足,制约了跨部门、跨区域和跨行业的互连互通、协作协同和科学决策[14]。本项目今后重点是基于数据资源交换共享提高各方数据汇聚意愿,基于主产区竞争力评估和决策能力提高地方政府的参与意向。五是尽快发挥大数据中心辅助决策能力。农业大数据中心主要是利用大量的数据进行加工处理,使用定量方法预测农业领域中存在的问题[15]。本中心拟通过数据挖掘推出系列高质量的研究报告,为各级政府、经营主体开展数据化管理提供基础支撑。

图13 茶叶电商大数据监测系统Fig.13 Tea e-commerce big data monitoring system
猜你喜欢
茶叶通讯(2022年2期)2022-11-15
电子乐园·下旬刊(2022年5期)2022-05-13
快乐作文(1.2年级)(2021年9期)2021-10-18
建材发展导向(2021年7期)2021-07-16
中国计算机报(2017年25期)2017-07-15
百家讲坛(2017年4期)2017-05-22
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
