
基于MobileNet-SSD和Bi-GRU的车牌检测识别系统设计与实现
2021-09-02 02:11何颖刚郑新旺阮佳坤
通化师范学院学报 2021年8期
何颖刚,郑新旺,阮佳坤
车牌检测和识别是指从自然背景下的车辆图像中检测并定位出含有车牌的区域,并对车牌区域进行字符分割和识别,最终获得车牌号码信息的过程,在停车场管理、交通道路监控等场合具有广泛地应用.车牌检测和识别包括三方面关键技术:车牌定位与提取、车牌倾斜校正与字符分割、字符识别,其中车牌定位与字符识别的速度和精度是核心[1].
目前,国内外学者对车牌检测识别已经有众多研究成果.针对车牌检测任务,主要方法有纹理特征法、颜色特征法、边缘检测法、多种特征混合方法等.文献[2]提出了一种基于边缘检测并二值化的方法,从背景中分割出车牌;文献[3]采用特征颜色边缘检测方法进行车牌定位;文献[4]使用Sobel垂直算子对图像边缘进行检测,获得车辆牌照的区域;文献[5]利用汉字字符笔画中的角点,提出了一种改进Harris算法的车牌定位方法,该算法较好地解决了车牌变形、光照变化的干扰,但是需要使用较高分辨率的图像进行检测.上述车牌检测方法算法复杂度较高,精度和速度存在一定的提升空间.
针对车牌字符识别任务,目前主要的方法有基于模板匹配的字符识别方法、特征信息方法和基于神经网络的字符识别方法.相对于英文车辆牌照,中国车辆牌照字符包括汉字、英文字母和阿拉伯数字,因此识别难度较大.文献[6]通过设计字符模板,使用重合度和差别函数度量车牌字符和字符模板之间的相似度,从中选择最佳的模板匹配结果.该方法的缺点是受光照变化、分辨率大小、污渍和变形影响较大;文献[7]提出了一种模板匹配法,结合局部HOG特征的车牌识别算法,提高了识别的准确率和速度.文献[8]采用粒子群算法优化BP神经网络进行车牌号码识别.这些方法均需要人工设计特征模板,并对车牌中的字符进行分割,算法对数字和英文字符识别较好,对汉字识别效果尚需提高.
传统的车牌检测识别技术方案流程较为复杂.在特定的应用场景下具有良好的效果.但在复杂的自然环境场景下,受到光照、异物、背景干扰等因素影响,检测识别率降低,难以取得令人满意的效果.随着深度学习技术的发展,基于神经网络的目标检测和图像识别技术获得了重大突破,其中以卷积神经网络为基础的AlexNet在2012年的ILSVRC(ImageNet Large Scale Visual Recognition Challenge)大赛上获得图像分类冠军,之后涌现了诸如Faster R-CNN、ResNet、SSD、YOLO等优秀的图像分类/检测算法.为了提升各类自然场景下的车牌检测率和识别率,本文提出了采用两种深度神经网络MobileNet-SSD+Bi-GRU的车牌检测识别方案,通过MobileNet-SSD实现车牌检测和定位,利用Bi-GRU对检测区域进行车牌字符识别.实验结果表明,本文所设计的方案能够满足实时检测和识别的需求,并达到了较高的识别精度.
1 基于MobileNet-SSD和Bi-GRU的车牌检测识别系统设计
1.1 系统整体架构
本文设计的车牌检测识别系统主要由视频采集、车牌检测定位、车牌识别组成.首先由摄像机实时采集视频并传入计算机形成数字图像.然后将图像输入训练好的MobileNet-SSD网络模型,进行车牌检测定位;在确定车牌区域后,从图像中将车牌区域剪裁出来,输入到Bi-GRU字符识别网络模型中,并输出车牌号码信息.系统整体架构如图1所示.
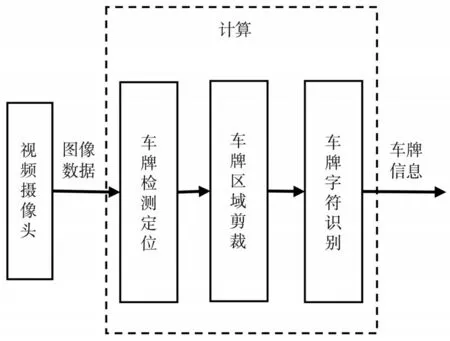
图1 车牌检测识别系统
1.2 基于MobileNet-SSD的车牌检测定位
车牌检测识别首先需要获取图像信息,检测图片中是否存在车牌并定位.近年来计算机视觉领域涌现出许多基于深度学习的目标检测算法.其中,以SSD、YOLO为代表的一阶段目标检测算法因速度快、准确率较高,成为研究的热点.
①SSD算 法.SSD[9](Single Shot MultiBox Detector)目标检测算法是由LIU W等人提出的一阶段目标检测方法.相比于RCNN、SPPNet等两阶段目标检测方法,一阶段检测方法不需要生成候选区域(Region Proposal)后再进行目标分类,而是直接采用端到端的方式进行目标类别预测和边界回归,结构简单,效率更高,仅有小幅度的精度损失.SSD网络模型结构如图2所示.

图2 SSD模型结构图
SSD模型输入尺寸为300×300×3的图像,检测框架由特征提取网络和多尺度检测网络两部分组成.前端特征提取网络结构为VGG16,在VGG16后附加多个卷积层用于不同尺度特征提取.为了同时实现目标类别识别和位置检测任务,模型从网络结构的多个卷积层中选取了六个不同尺度的特征图用于检测不同大小的目标物体.输入图像经过VGG16和其后的卷积层,生成大小为38×38×512、19×19×1 024、10×10×512、5×5×256、3×3×256、1×1×256六 个特征图.然后,在六个特征图中使用不同尺寸和多种长宽比来生成先验框,进而在这些先验框中预测包含目标的概率.先验框的尺寸使用公式(1)生成.
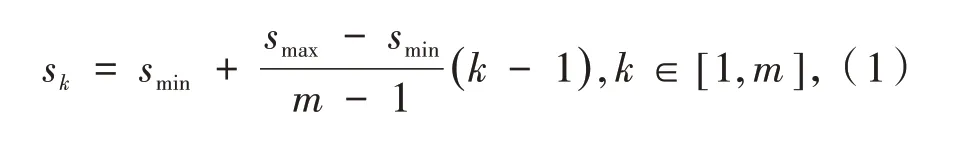
其中:m为特征图个数,sk为候选框尺寸相对于输入图像尺寸的比例,smax和smin为比例的最大值和最小值.先验框的长宽比从{1,2,3,1/2,1/3}中进行选取.SSD先验框总数为38×38×4+19×19×6+10×10×6+5×5×6+3×4×4+1×1×4=8 732.在实际训练中,可根据车牌形状特征,调整先验框的长宽比选项.
之后,在先验框上进行位置回归和softmax分类,并通过非极大值抑制方法产生最终的检测结果.SSD网络损失函数由位置损失函数和置信度损失函数两部分加权组成,如公式(2)所示.
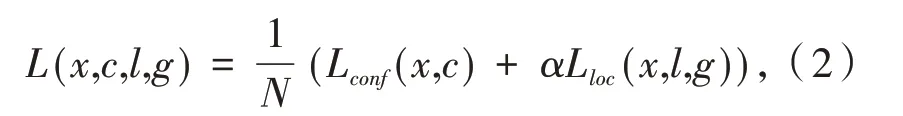
其中:N为先验框的正样本数量,c为类别置信度预测值,l为预测框位置预测值,g为真实框的位置参数,α为权重因子,Lconf(x,c)为分类损失函数,Lloc(x,l,g)为位置损失函数,x为预标注框与先验框匹配值,x∈[1,0].
②MobileNet卷积神经网络.2017年,谷歌公司HOWARD A G等人在文献[10]中提出了MobileNet卷积神经网络模型.MobileNet是一种轻量化的卷积神经网络模型,原理是通过深度可分离卷积设计(图3)提高卷积网络的计算效率,大幅减少网络参数数量.从而使网络计算速度得到提升,减少内存占用量.
A3、A4、B2、B3、C1(无人死亡时)、C2(无人员死亡时)、D1(无人员死亡时)区域为一般风险区域. 风险水平在一定有条件下可接受,需要进一步采取措施予以预防. 其中C1、C2和D1区域发生人员死亡时升级为较大风险区域;
定义输入图像的尺寸为DF×DF,图3(a)中DK为卷积核大小(即为其长和宽),M为输入图像的通道数,N为卷积核的个数.传统标准卷积的计算量为:
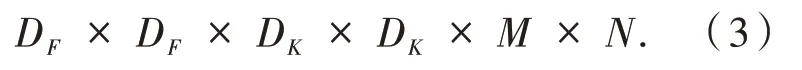
MobileNet通过将图3(a)所示标准卷积分解为图3(b)所示深度卷积和图3(c)所示1×1逐点卷积,总计算量为:
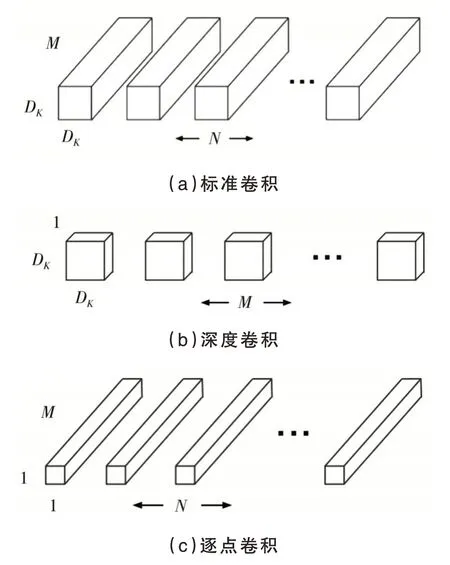
图3 深度可分离卷积

相比于标准卷积,MobileNet计算量减少为:

通过公式(3)、公式(4)和公式(5),可以看出MobileNet采用的深度可分离卷积设计改进了传统卷积网络结构参数冗余问题,优化了整个网络的结构.在ImageNet数据集上MobileNet准确率较AlexNet提高了3%,模型参数仅有AlexNet的1/50,计算量为AlexNet的1/10.
③MobileNet-SSD车牌检测定位算法.针对SSD模型参数多、计算量大,不适合计算资源有限嵌入式平台的应用.文献[11]提出MobileNet-SSD,改善了SSD模型的性能.作为SSD模型轻量化的解决方案,MobileNet-SSD模型使用MobileNet网络替代原有VGG16网络作为SSD模型的基础网络结构.在保持原有SSD网络结构的同时,减少了原有冗余参数,使得计算量和内存资源消耗降低,加快了网络模型收敛速度,改善了算法的性能.
MobileNet V2是MobileNet网络的第二个改进版本.相比于MobileNet V1,MobileNet V2在网络中加入了残差结构,去掉部分ReLu,从而保留特征多样性,更加充分利用了特征信息,提高了准确率.本文选用MobileNet V2作为MobileNet-SSD基础网络结构.
1.3 基于Bi-GRU的车牌识别
循环门单元(Gated Recurrent Unit,GRU)是由CHO K等人在文献[13]中提出的.GRU是长短期记忆神经网络(LSTM)的变体,属于循环神经网络(RNN)的一种.相比于LSTM输入门、遗忘门和输出门的三门结构,GRU只有重置门(Reset gate)和更新门(Update gate)两个门,参数更少,更容易收敛.
传统循环神经网络的结构中,信息传播是单向的.为了使得网络模型可以同时学习输入序列的正向信息和反向信息,可以在原有循环神经网络基础上,增加一层相反方向的循环神经网络,通过两层分别处理相反方向的输入序列,学习到更多的信息.双向GRU神经网络(Bi-directional Gated Recurrent Unit neural network,Bi-GRU)是将GRU作为双向循环神经网络的循环神经元,图4为Bi-GRU网络结构图.通过前向GRU层和后向GRU层,以两层相反方向处理数据来获得上下文特征信息,能够从序列数据中更加充分提取有用的特征信息.

图4 Bi-GRU结构
基于卷积神经网络和Bi-GRU的车牌识别模型结构如图5所示.首先输入MobileNet-SSD检测出的车牌区域,通过两层CNN进行特征提取并转换为序列化特征向量;然后输入两层Bi-GRU层进行处理;最后输出车牌字符识别的结果.车牌识别模型损失函数采用CTC(Connectionist temporal classification)损 失函数.
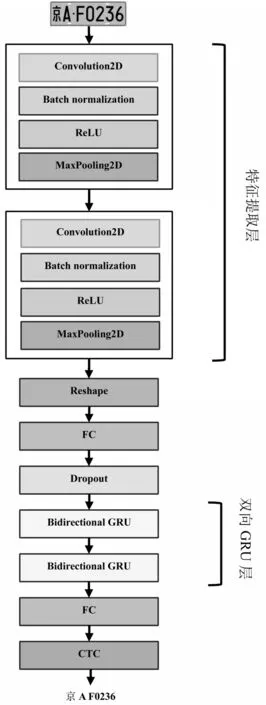
图5 基于卷积神经网络和Bi-GRU的车牌识别模型结构
2 实验数据和开发平台
2.1 实验数据
实验数据集采用了中科大开源数据集CCPD[14],另外加入了自行收集的中文车牌图像样本库,从中选取10 000张图片进行模型训练和验证.其中,随机选取7 000张图片作为训练集,2 000张图片作为测试集,1 000张图片作为验证集.自建数据集中的图像采用labelImg工具进行图像标注,并生成对应的xml文件.数据集同时应用于车牌检测定位网络模型训练和车牌字符识别网络模型训练.
2.2 实验平台和开发环境
实验环境为Windows 10操作系统,16 GB RAM,Nvidia GeForce 1660 Ultra6G显卡,CUDA10加速,使用基于Tensorflow机器学习框架的Keras深度学习库和OpenCV计算机视觉库进行开发和实现.Keras提供了构建和训练深度学习模型的高级API,具有用户友好、模块化、易于扩展等优点,是研究人员和开发人员实现快速原型设计、研究和验证的高效工具.OpenCV是一个开源的计算机视觉库,提供了丰富的图形图像处理函数,功能非常强大.实验采用GPU进行网络模型的训练.模型训练完成后模型结构保存为model文件,权重参数保存为.h5文件,方便在生产环境中快速部署和使用.
3 系统开发
3.1 系统设计方案
本文设计的车牌检测识别系统由视频采集模块、图像识别模块组成.摄像头采集实时视频并传入计算机形成数字图像,然后利用Keras加载网络结构模型和权重数据文件,对输入的图像进行检测和识别,最后输出车牌的位置和车牌字符.系统流程图如图6所示.
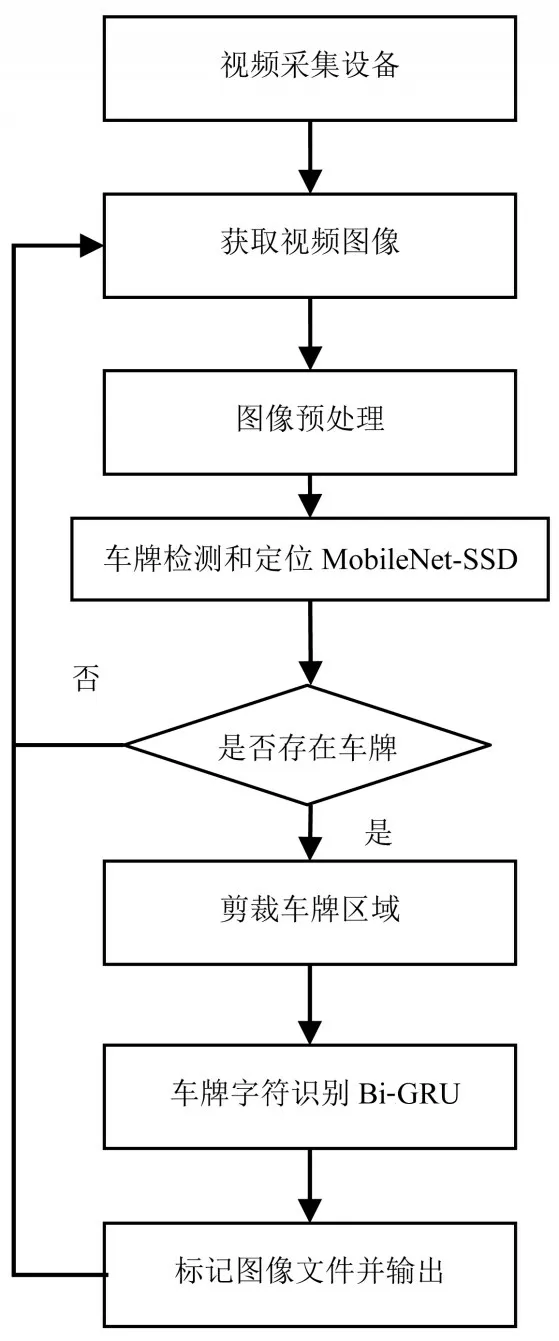
图6 系统流程图
系统通过USB接口摄像头完成图像采集,使用OpenCV-python库实现摄像头调用和视频数据的捕获.对摄像头编程使用了Video-Capture(0)、read()、release()等函数.
程序的具体步骤如下:
①使用cap=cv2.VideoCapture(0)获取摄像头,其中参数0表示第一个摄像头.通过capture.set(CV_CAP_PROP_FPS,2)设置摄像头帧率为每秒2帧.
②在while循环语句中,利用摄像头对象cap的read()函数循环读取视频帧,语句ret,img=cap.read()将read()函数的返回值保存到img对象中.
③将img对象输入到加载训练权重参数的MobileNet-SSD网络模型进行检测,输出结果为包含车牌概率和车牌位置的List.
④选择概率大于80%的先验框,以红色框标注出位置,并剪裁出对应的车牌图片,输入到字符识别模块中,进而获得识别结果车牌号码.保存图像为磁盘文件,并将文件名以识别的车牌号码进行命名.
⑤回到步骤②,继续读取下一帧的图像数据,重复整个检测识别步骤.图7为车牌检测定位模块输出结果.

图7 车牌检测定位效果
3.2 静态图像车牌检测和识别测试
分别从CCPD数据集中额外挑选100张图片,输入到上述系统进行车牌检测和识别测试,其中正确检测并定位车牌的有92张,未能检测到的有8张,检测率为92%.车牌字符正确识别有95张.图8为部分静态图像的车牌检测识别结果.

图8 静态图像检测识别效果
3.3 动态图像车牌检测和识别测试
在停车场出入口设置摄像头,连接到笔记本电脑,在电脑上运行本系统,采集进出车辆图像数据测试系统,对进场车辆都能检测并标记的视为实验成功.测试期间选定不同时间段进出车辆50辆,检测成功次数47次,成功率为94%.测试结果表明,系统可以较好地进行车牌检测和识别.但是也存在着不足,例如在光照较暗、较亮或车辆行驶速度较快的情况下,会降低检测成功率.
4 结语
本文设计并实现了一种基于MobileNet-SSD和Bi-GRU的车牌检测识别系统.从车牌的检测定位、车牌字符的识别等方面阐述了系统的设计思路,并对系统进行测试,达到了预期目标.相较于工业级应用目标,本文提出的方案在检测速度、检测准确率、识别准确率等方面还有待提高.未来将研究通过改进模型结构和图像预处理方法来提高算法的准确度.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年12期)2019-07-16
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
小猕猴智力画刊(2017年5期)2017-05-25
电子制作(2017年22期)2017-02-02
现代电子技术(2016年22期)2016-12-26
软件导刊(2016年11期)2016-12-22
科学与财富(2016年28期)2016-10-14
