
科学数据中心综合运行评价体系赋权研究
2021-09-01 01:08:52王瑞丹陈祖刚李国庆高孟绪
中国科技资源导刊 2021年4期
徐 波 王瑞丹 陈祖刚 李国庆 石 蕾 高孟绪
(1.国家科技基础条件平台中心,北京 100038;2.中国科学院空天信息创新研究院,北京 100094;3.国家对地观测科学数据中心,北京 100094)
0 引言
科学数据中心是用来集中管理(存储、计算、交换)科学研究数据的地方。在科学研究进入以数据驱动的“第四范式”背景下,科学数据成为科研工作乃至国家发展的重要战略资源,科学数据中心成为科研工作取得重大突破性创新的关键基础设施之一。近10年来,我国开展了不同层面的科学数据共享中心建设与运行工作,形成了一批层次不同、类型多样的科学数据中心,为推动科学数据共享利用、提高资源利用效率发挥了积极的作用[1]。然而,我国现有的数据中心及其运行管理水平良莠不齐,降低了科学数据对科技创新的支撑和保障能力急需通过建立完善的评价体系,促进数据中心提升能力建设[2]。
科学数据中心的评价工作较早地受到国外相关部门和国际组织的重视,并且有较多的科学数据中心主管机构或第三方组织对科学数据中心进行系统的评价。如由互联网基金会发起的“开放数据晴雨表”对全球各国政府数据开放和使用进行评估[3],对115 个国家15 个领域的1 725 个数据集进行调查、分析和评估,并在此基础上形成了大量的科学数据中心多指标评价体系;国际数据系统(WDS)的数据仓储核心认证(CTS)作为国际上领导性的科学数据中心评价和认证标准,采取包括仓储背景信息、组织结构、存储内容管理和技术基础4 个维度在内的17 项指标进行多指标评价,这一方案普遍适用于数据存储机构的评估。
我国也有很多机构和科学研究团队对科学数据中心运行绩效评价指标开展了研究和实践,并初步建立了多指标评价体系。尤其是2011年随着包含科学数据的国家科技基础条件平台正式运行服务,我国相关管理部门对国家科技基础条件平台的考核评价工作也同步启动[4],建立了针对平台运行绩效的评价体系。评价体系从资源整合、运行管理、服务成效和服务数量4 个方面[5],建立了资源增量与质量等12 个评价指标,有效地促进了我国国家科技基础条件平台的发展。
值得注意的是,虽然国内外相关的数据中心评价形成了多指标体系的共识,但体系赋权的定量化程度都还较低,评估重点难以根据实际确定,权重系数易根据某些政策性因素约束采用“一刀切”方式固定不变。这种自上而下制定的规则,很难与同行专家的专业认知相结合,不能有效输入专家的智慧,加强评价指标的科学性。
科学数据中心评价的指标权重是评价体系的关键技术之一,赋权是否合理直接影响评价的科学性。无论是从科学数据中心管理实践还是理论研究的角度出发,在当前背景下,构建一套适应我国科学数据战略需求的合理数据中心评价体系的赋权机制,对推动数据中心的管理和运行能力的提升,更好地利用科学数据价值,支撑国家重大战略需求,具有十分重要的意义。本文将面向科学数据中心运行状况综合评价的重大需求,针对已有的多指标评价体系,提出了一套耦合层次分析法和相关性分析法的高可操作性、高可靠性赋权方法,为实现科学数据中心运行状况科学合理评价以及类似任务的赋权提供方法借鉴。
1 研究现状
赋权是各个评价体系的关键技术之一,已经有较多的研究人员针对具体的应用场景开展了研究。现有的赋权方法主要分为主观方法、客观方法和主客观组合权重分配法3 种形式。
主观方法由具有专业经验的专家结合指标体系,通过主观判断的方式实现,这类方法主要适用于评价体系的初创期,提出合理的指标权重分配。杨行等[6]运用层次分析法,从站点品牌、性能外观、数据范围、数据渠道以及数据价值5 个方面构建科学数据共享网站的资源可见性评价框架,对科学数据共享网站的资源可见性评价进行分析和讨论;司莉等[7]选择运营管理、数据资源、平台功能、服务效率和影响4 个一级指标,利用分析层次结构过程来设置指标权重,并使用专家评分方法给出指标的分数,对中国8 个主要的科学数据类国家平台进行绩效评估。
客观方法是指根据决策矩阵的指标取值情况,利用客观数据实现指标权重的分配[8],适用于评价体系广泛应用期的优化与改进。刘永志[9]经过对《中国统计年鉴》中分地区科学技术相关的统计数据进行主成分分析,将51 个属性变量降维用8 个主成分来表示,计算主成分得分,得到31 个行政单位的科学技术相关的综合得分,并且给出参考意见。
主客观组合权重分配法是将主观法和客观法组使用,利用决策者主观知识与经验和决策数据的客观事实综合确定指标权重,达到相互补充的目的。
对于目前我国科学数据中心的评价,尚未完全达到成熟期,体系中的客观数据还不够完善,所以指标赋权方法主要在主观方法中选择。主观方法中,最具代表性的方法有层次分析法、专家调查法、相关系数法、网络层次分析法、效用函数法和基于证据推理的权重分配法。根据相关学者的调研,发现各个学科领域的专家开展的指标权重确定方法研究中,层次分析法和专家调查法所占比例较大。这两种方法在实际使用案例中分别占了约37.02%、30.80%[10],可见这两种方法具有很强的实用性。但是,层次分析法的主观性较强,如何剔除主观性是提高层次分析法精度必须解决的问题。本文提出一种层次分析法和相关系数法相结合的权重计算方法应用于科学数据中心评价指标权重研究,为评价指标体系提供可操作性强、可靠性高的权重计算方法,保证科学数据中心评价的科学性。
2 评价指标体系
随着数据量的增加和科学数据中心的急速发展,数据中心的业务链变得更长,信息化程度提升更快,对数据中心的学科综合性和发展方向差异性要求也越来越高。同时,随着我国科研创新能力和学术影响力逐步增强,国际化需求也更加强烈。因而,本文在国内外的多套数据中心评价指标体系的基础上,根据《科学数据管理办法》[11]对科学数据中心包括科学数据整合汇交、分类分级、加工整理和分析挖掘,保障科学数据安全,推动开放共享,加强国内外交流与合作等职责的内在要求和《国家科技资源共享服务平台管理办法》[12]对科学数据中心“进行分类评价,重点考核科技资源整合能力、服务成效、组织运行管理及专项经费使用情况”等内容考核内容的相关规定,结合科学数据中心管理机构的统一管理需求,本文提出了一套全流程全体系化的多指标评价体系,从资源整合、平台服务、分析与挖掘、运行管理、支撑条件、可持续能力和国际影响力7 个方面对科学数据中心现状以及运行成效进行综合评价。7 个一级指标包括清单任务完成度、资源数量、增量与质量等27 个二级指标(图1)。在科学数据中心评价时,各科学数据中心只需填报二级指标的资料,经过对二级指标进行横向量化以后,成为各科学数据中心总的运行分数。该指标体系涵盖了科学数据中心现有实力的评价指标和指定时间段内的运行绩效指标,是一个综合的评价系统,其目的是为各个数据中心生成一个既考虑数据中心现状又发挥数据中心主观能动性的综合评价分数,管理机构可以依据综合评价分数的高低,为各个数据中心分配运行经费。在27 个二级指标中属于科学数据中心现有实力评价的指标包括现有资源量、数据管理能力、数据分析挖掘能力、工具应用能力、工作场地、信息设施、人才团队与培养、国际化人才、国际用户。
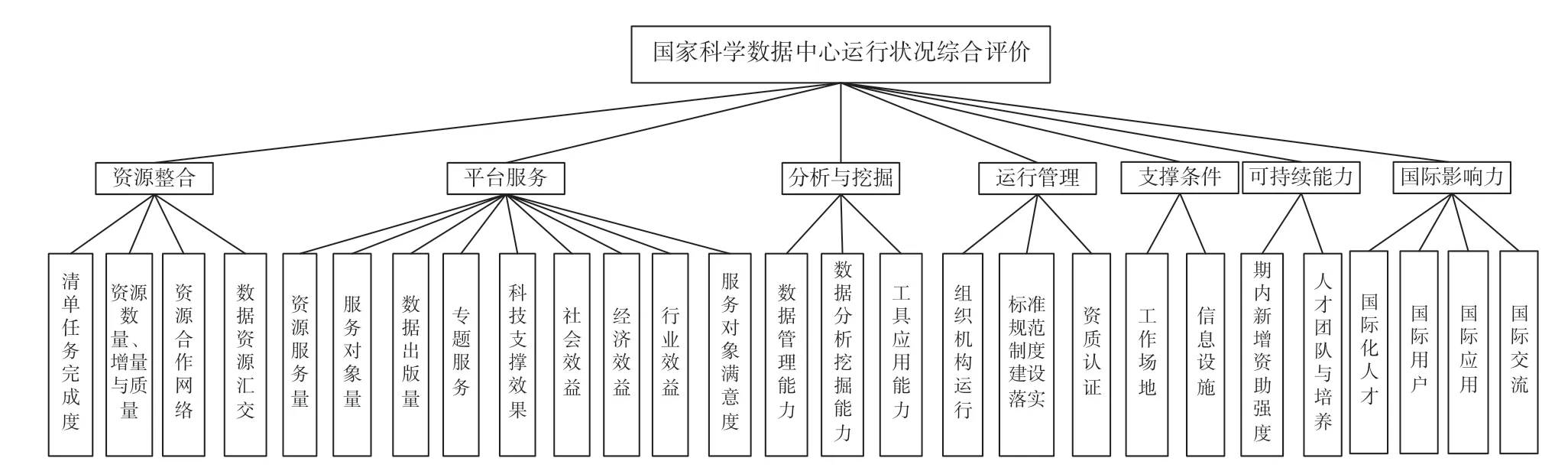
图1 科学数据中心运行状况综合评价指标体系
3 研究方法
3.1 层次化系统建立
层次分析法是指将与决策有关的元素分解成目标、准则、因素等层次,在此基础上进行定性和定量分析的决策方法。该方法是美国运筹学家匹茨堡大学教授萨蒂于20 世纪90年代初提出的[13]。它将一个复杂的多目标决策问题看作一个系统,将目标分解为多指标(或准则、约束)的若干层次,建立判断矩阵,并求解矩阵特征向量的办法,求得每一层次的各元素优先权重。层次分析法的判断矩阵是通过一致矩阵法获取,不把所有因素放在一起比较,而是两两相互比较,采用相对尺度,以尽可能减少性质不同的诸因素相互比较的困难,提高准确度。
使用层次分析法计算科学数据中心评价赋权,首先需要对评价指标体系进行层次化分解,形成有序的递阶结构。如图2所示,建立的科学数据中心评价指标体系的一级指标层次化系统,目标层为科学数据中心运行评价A,因素层主要包括资源整合情况(A1)、平台服务情况(A2)、分析与挖掘(A3)、运行管理情况(A4)、支撑条件情况(A5)、可持续能力(A6)、国际影响力(A7),A=A1+A2+A3+A4+A5+A6+A7。
如图3所示,建立的关于资源整合情况的二级指标层次化系统,目标层为资源整合情况A1,因素层包括清单任务完成度(A11),资源数量、增量与质量(A12)、资源合作网络(A13)、数据资源汇交(A14),A1=A11+A12+A13+A14。
依次建立各个二级指标层次化系统,最终共建立8 个层次化系统,即一级指标构成1 个层次化系统,7 个二级指标分别构建一个层次化系统,共计8 个层次化系统。
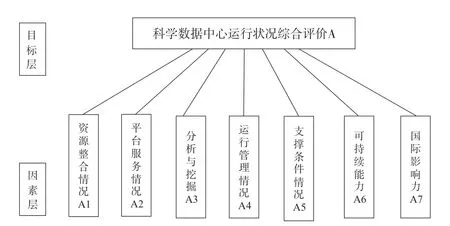
图2 科学数据中心评价指标体系的一级指标层次化系统
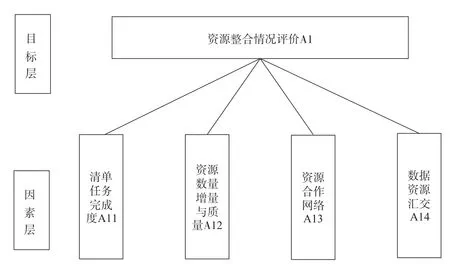
图3 科学数据中心评价指标体系资源整合情况二级指标层次化系统
3.2 科学数据中心评价体系权重确定
3.2.1 构造各层次化系统两两比较矩阵
对于每个层次化系统,首先建立其因素层的各个因子两两之间的相对重要性的评价表,8 个层次化系统共建立8 张评价表。然后邀请熟悉数据工作的专家对各个指标相对重要性进行评分,采用Saaty 1-9 标度评分标准进行评估赋分[14],见表1。最后,邀请我国熟悉科学数据中心工作的20 位专家。专家遴选需满足以下条件:(1)熟悉科学数据中心管理工作;(2)对科学数据发展理论有一定的研究和认识;(3)来自不同领域不同专业的数据中心。请专家分别对8 张评价表进行评分,形成了指标重要性两两比较判断矩阵,获得多个比较矩阵,如式(1)所示为其中一位专家对科学数据中心评价一级指标的相对重要性打分形成的判断矩阵。

表1 Saaty 1—9 标度评分标准
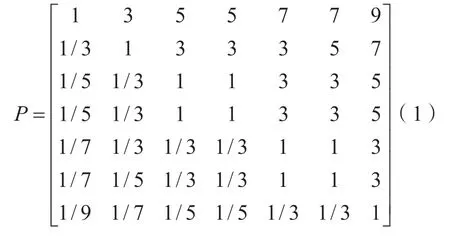
可以发现对于同一层次化系统的n个指标,两两判断矩阵P=[pij]应满足pii=1,pij×pji=1。
3.2.2 数据分析与结果
对获得的关于8 个层次化系统多个比较矩阵,首先计算一级指标对总目标A的权重,计算方法为对所有的有关总目标A的比较矩阵进行矩阵的一致性检验。一致性检验的目的是考察专家打分内在的逻辑一致性以排除随机或错误给出的相对重要性评分。一致性检验的具体方法为计算矩阵的最大特征值λmax,获取一致性指标C1,见式(2),C1的值越大,判断矩阵的不一致性越严重,不一致性通过矩阵检验系数CR表达,CR的计算方法如式(3)所示,其中RI为随机一致性指标[15],其值根据表2获取。当CR的值小于0.1时,判断矩阵被认为通过一致性检验,这时,其最大特征值λmax对应的归一化后的特征向量可以作为相应指标的权重向量。若CR>0.1,则此判断矩阵未通过一致性检验,其提供的值不可信。
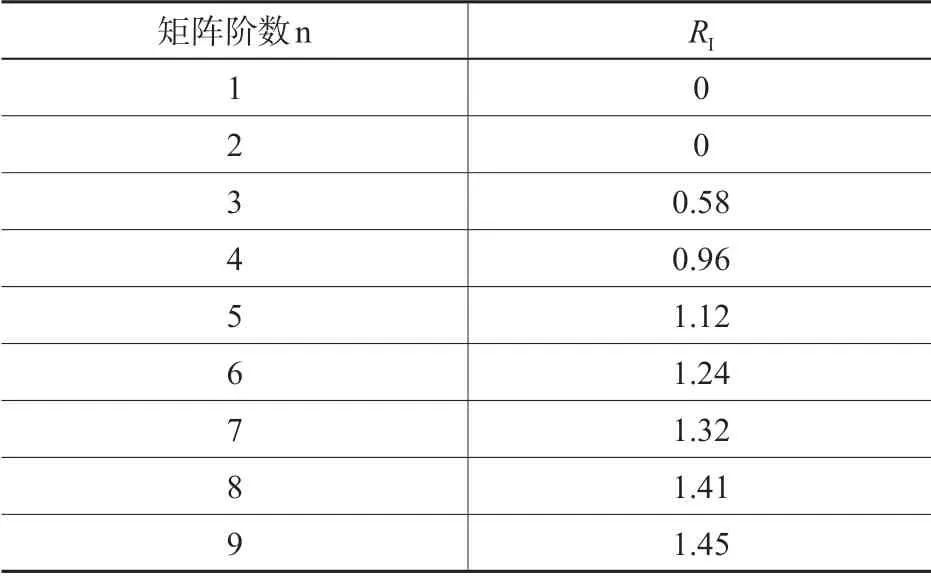
表2 随机一致性指标RI取值表
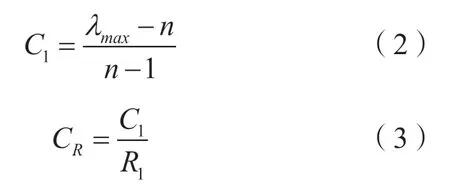
例如,式(1)中矩阵P的最大特征值为7.300 7,C1=(7.300 7-7)/6=0.05;CR=0.05/1.32=0.037 9,由于CR的值小于0.1,可以把矩阵P的最大特征值对应的特征向量R=[-0.837 0,-0.428 8,-0.216 4,-0.216 4,-0.102 8,-0.095 0,-0.048 7]归一化后的值[0.430 3,0.220 5,0.111 3,0.111 3,0.052 9,0.048 8,0.025 0]作为A1—A7 这7 个指标的权重值。
按照以上方法对所有专家评价产生的比较矩阵进行分析,得到了有效权重向量(有的专家的比较矩阵未通过一致性检验,为无效权重向量),如表3所示。可以发现,各个专家的权重向量存在一定差距,但总体上差别不大,可见各个专家对指标的重要性程度有着较为一致的认识。为了进一步选出低质量的专家评价矩阵,把有效权重向量求取平均值,计算每位专家的权重向量和平均值向量的皮尔逊相关系数,把相关系数较小的权重向量剔除,计算剩余权重向量的平均值,作为考核指标的最终权重。皮尔逊相关系数的计算方法如下:
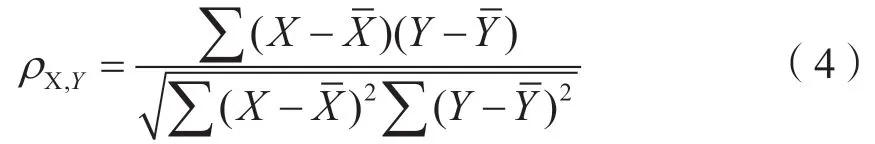
其中,X、Y是两个权重向量,分别是X、Y的平均值。皮尔逊相关系数越接近于1或-1,相关度越强(1 为正相关,-1 为负相关),相关系数越接近于0,相关度越弱。通常情况下,皮尔逊相关系数的值为[0.8,1]代表二者极强相关,[0.6,0.8]代表强相关,0.6 以下的相关系数代表中等程度及以下相关。有效权重向量和平均值的权重向量的相关系数分别为如表4所示。
从表4可以发现第3、4、5、20 位专家对一级指标的权重向量与平均值的相关系数低于0.6,可以判定为低质量的评价,予以剔除,最终把第1、8、9、10、11、12、14、……、19 位专家的权重向量求取平均值作为一级指标的最终权重,即资源整合情况的指标权重为0.309、平台服务情况的权重为0.254、分析与挖掘权重为0.094、运行管理情况为0.108、支撑条件情况为0.088、可持续能力为0.087、国际影响力为0.060。
用以上方法,分别对各个二级指标层次化系统的指标求取权重,然后用二级指标的权重乘以相应的一级指标的权重,获取最终的权重系数,如图4所示(所有的系数都以百分比显示)。
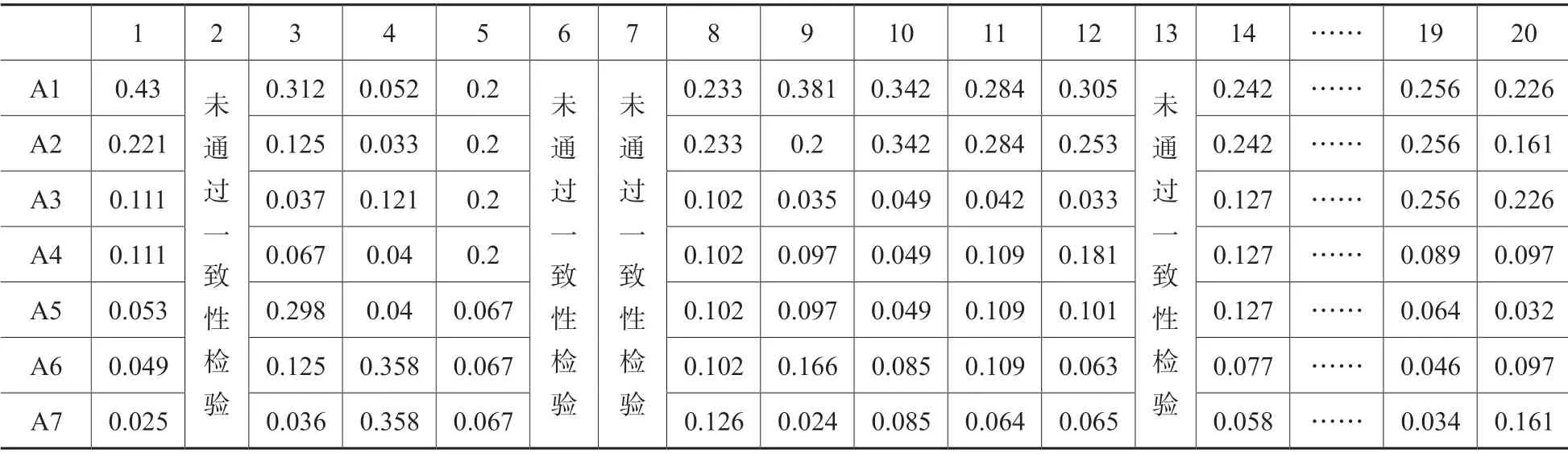
表3 各个专家的比较矩阵对应的国家科学数据中心一级指标的权重
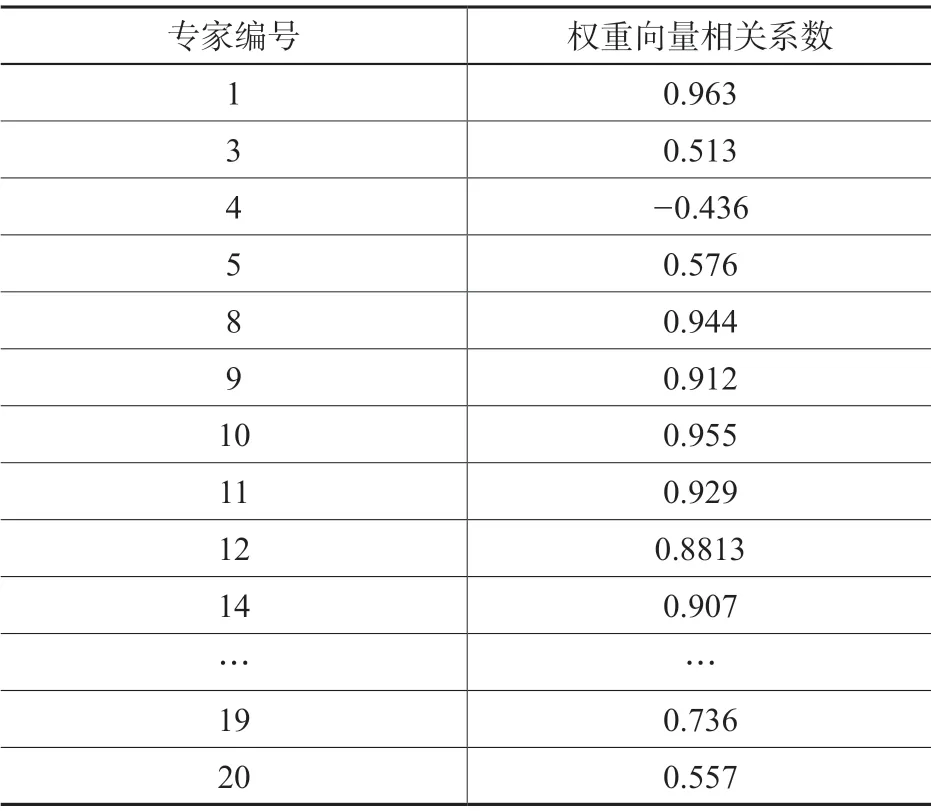
表4 各个专家权重向量与平均值向量的相关系数
4 结论与讨论
本研究通过邀请科学数据领域的专家,对提出的科学数据中心评价指标体系的一级、二级指标的相对重要性进行评分,生成指标相对重要性矩阵,计算矩阵的特征值和特征向量,把特征向量归一化后获取各个指标的权重。对各个专家的指标权重求取平均值,再由平均值和各个专家的权重值进行相关性分析,剔除相关系数较低的值,剩余值再求平均数作为各个指标最终权重。把层次分析与相关系数相结合的方法应用于科学数据中心运行状况的评价之中。本方法具有两个方面的优点:一是把专家的专业知识作为科学数据中心指标权重大小的判断依据;二是减少层次分析法的主观性,提取熟悉科学数据工作的专家共识。
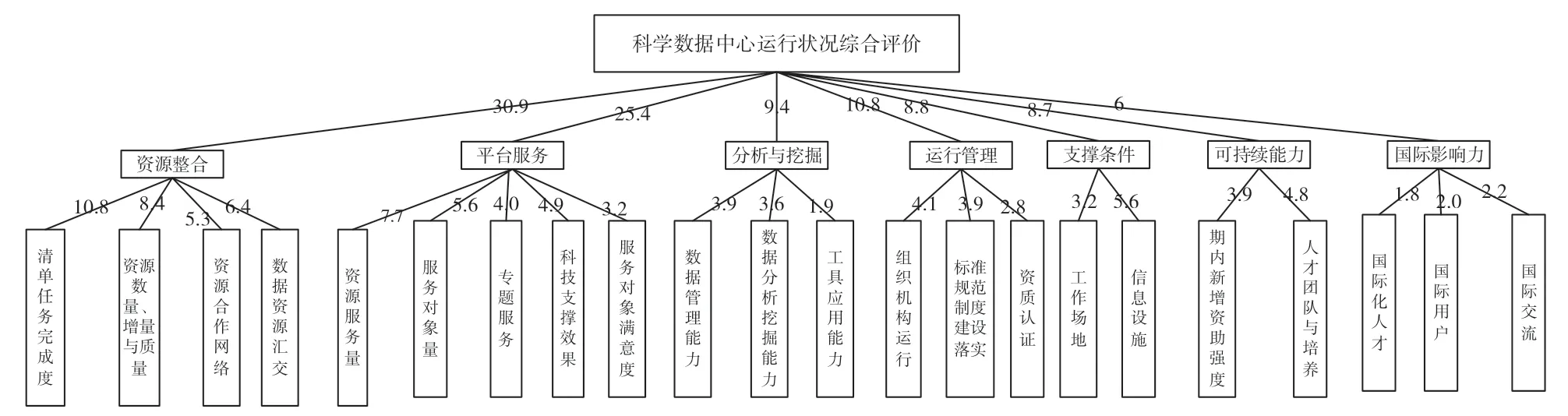
图4 科学数据中心绩效考核评价指标体系及其权重
从计算的评价体系指标的最终权重中可以看出(图4),其7 个一级评价指标的权重并不相同,甚至相差很大,其中数据“资源整合”和共享“平台服务”是科学数据中心评价指标体系中权重最大的因子,这也暗示了各个科学数据中心必须把数据资源整合和数据共享服务作为工作的重中之重。在二级指标中,“清单任务完成度”“资源数量、增量与质量”“资源服务量”和“数据资源汇交”在数据中心的工作中占有较大权重,是数据中心较为核心的具体工作。从总体上看,本文提出的方法能有效支撑科学数据中心开展量化评价,指导数据中心明确工作的重心,具有重要的评价和指导意义。未来,可以对二级指标进一步细化,形成更加详细的三级指标,利用本研究提出的方法计算三级指标的权重,实现各个科学数据中心提供其运行状况数据资料后,其运行绩效分数的自动生成,增强评价的自动化和智能化水平。
猜你喜欢
机械研究与应用(2022年4期)2022-09-15 02:21:32
北京航空航天大学学报(2022年8期)2022-08-31 08:57:30
电子测试(2018年11期)2018-06-26 05:56:24
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:34
领导决策信息(2017年11期)2017-05-17 04:49:12
铁道通信信号(2016年1期)2016-06-01 12:10:17
中国交通信息化(2015年3期)2015-06-05 03:53:30
中国舰船研究(2015年2期)2015-02-10 06:45:44
航天返回与遥感(2014年5期)2014-07-31 17:57:09
河南科技(2014年11期)2014-02-27 14:16:49
