
空间金字塔与局部感受野相结合的相关熵极限学习机
2021-08-26 08:09杨有恒
电子与信息学报 2021年8期
刘 彬 刘 静 吴 超 杨有恒
①(燕山大学电气工程学院 秦皇岛 066004)
②(燕山大学信息科学与工程学院 秦皇岛 066004)
1 引言
近年来,随着图像分类领域的飞速发展,词袋模型[1]作为一种简单有效的图像分类方法得到了广泛的关注和研究。该方法将图像特征量化为视觉单词,通过统计出视觉单词的频率直方图完成图像表示。然而,仅统计单词特征出现次数来表示图像,使得特征分布中的空间信息未被有效利用。因此,Lazebnik等人[2]提出了空间金字塔词袋模型(Spatial Pyramid Matching,SPM),将图像划分成不同尺寸的子区域分别进行直方图统计,有效提高了词袋模型的分类能力,因此很多算法均基于SPM进行改进。
为提高分类效率,Li等人[3]在SPM中引入极限学习机(Extreme Learning Machine,ELM)[4],利用其对提取出的SPM特征进行分类。由于ELM具有良好的特征,因而广泛应用于分类、预测和回归等领域[5–7]。然而传统ELM只能利用已提取好的特征向量来训练网络,无法考虑特征的空间分布信息。因此,Huang等人[8]提出局部感受野极限学习机(Local Receptive Fields based Extreme Learning Machine,ELM-LRF),通过将局部感受野与ELM相结合,使得网络可以利用空间信息以增加特征辨识度。然而对于复杂图像,单层网络提取出的特征信息表达能力有限,无法进一步提高网络分类能力。随着计算机性能的不断提升,研究学者提出了AlexNet,GoogleNet等深度学习网络结构[9–12],然而其训练网络所需的计算量远超传统分类算法。而ELM-LRF网络简单、易于训练、泛化性强,在处理一些分类任务时同样能够获得较高精度。
由于传统ELM训练方法通常使用的均方根误差(Mean Square Error,MSE)准则对训练数据中的离群点和脉冲噪声较为敏感。因此,Xing等人[13]引入相关熵度量作为网络损失函数,并利用半2次优化求解满足相关熵准则的ELM,提高了算法在噪声破坏和遮挡条件下的识别精度。吴超等人[14]利用拉格朗日乘子法求解基于相关熵的ELM(Correntropybased Fusion Extreme Learning Machine,CFELM),并将其用于训练网络中各层权重以提高网络分类性能。然而这些基于相关熵准则的改进算法没有考虑向量之间的角度问题,降低了网络的通用逼近能力。当网络的实际输出无限接近于期望输出时,不仅向量模长应无限趋近,两者所成角度也应为最小。
针对以上问题,本文提出空间金字塔与局部感受野相结合的相关熵极限学习机(Correntropy Extreme Learning Machine based on Spatial pyramid matching and local Receptive field,SR-CELM)。在特征提取部分,将SPM特征与ELM-LRF充分结合,提取出空间中的局部特征分布信息。按照字典顺序重新排列空间金字塔区域内的各个字典特征,并统计其在每个子区域内的出现频率,利用多尺度局部感受野提取各层级字典特征分布图的卷积特征。同时,为提高特征多样性,引入局部位置特征和全局轮廓特征。在特征分类部分,提出一种新的网络对各部分特征进行编码和融合。为提高网络的鲁棒性与分类性能,构建出基于相关熵准则的模长差值与角度约束,推导出相关熵循环更新公式以训练网络的输出权重。最后在Caltech 101,MSRC和15 Scene数据库上进行实验,以验证SR-CELM的有效性。
2 空间金字塔与感受野相结合的相关熵极限学习机
为充分提取与利用图像中的可辨识特征信息,本文提出了空间金字塔与感受野相结合的相关熵极限学习机(SR-CELM),SR-CELM主要由特征提取和特征分类两部分组成,其整体结构如图1所示。
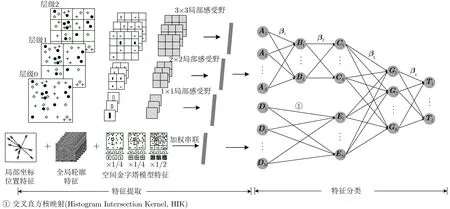
图1 SR-CELM结构图
2.1 特征提取


图2 不同子区域特征频率统计图
2.2 特征分类

由于传统ELM-LRF在训练时均使用MSE作为损失函数,利用式(4)训练的各层权重会使网络整体易受噪声干扰。因此本文改进相关熵准则的判别性约束,推导出相关熵循环更新公式以求解输出权重。
2.3 相关熵准则输出权重的求解方法



3 实验结果与分析
为验证所提方法的有效性,本文从Caltech 101,MSRC和15 Scene数据库中分别提取出图像的SPM特征、局部位置特征和全局轮廓特征,将特征组合后输入SR-CELM中。为公平比较,所有数据库上的实验均参照文献[8]的实验步骤进行。
在特征分类部分各层权重的训练过程共需要5个参数,即惩罚项系数K与P,循环次数,局部感受野个数和相关熵参数d=2σ2。本文在各数据集上分别进行大量实验,确定最优参数组合。本文的实验环境为:Intel Xeon Silver 4110@2.1 GHz 8核CPU,64 GB RAM,MATLAB 2014a。
3.1 Caltech 101数据库
本节使用Caltech 101数据库中101类物体图像进行实验。选取训练、测试图像方式和数量与文献[14]一致,共使用5948幅图像进行实验。

首先对参数d,K和P进行优化,当感受野个数为1,任意固定迭代次数为7,惩罚项P为 2−1,K和d变化时SR-CELM正确率变化曲面如图3(a)所示。在图3(a)中,K为2−10可获得最高正确率,将其固定并调节惩罚项P, P和d变化时的正确率变化如图3(b)所示。由此可得到图3(b)中最优参数组合,即d,K和P分别为0.5,2−10和2−5。
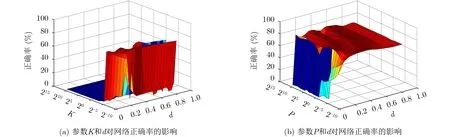
图3 不同参数变化时网络正确率曲面图
在此基础上改变循环迭代次数和感受野个数所得网络分类正确率如图4所示。由折线图可知,当字典维数为400维,感受野个数为21,迭代次数为8时,SR-CELM能达到最高正确率83.72%。当字典维数为600维,感受野个数为24,迭代次数为9时,能够达到最高分类正确率84.13%。

图4 不同字典维数下循环次数和感受野个数对网络正确率影响折线图
Caltech 101数据库中部分图像背景嘈杂,将图像中的嘈杂背景视为干扰噪声,选取几类背景嘈杂图像进行测试以验证网络抗干扰能力。将SRCELM、文献[15]、CF-ELM和多尺度局部感受野极限学习机(Extreme Learning Machine with Multi-Scale Local Receptive Field s,ELMMSLRF)[16]的分类正确率进行比较,由图5中不同方法正确率对比可知,在嘈杂背景噪声干扰下SRCELM具有更好的抗干扰能力。

图5 4种方法对Caltech 101数据库中具有嘈杂背景图像的正确率
表1列出了不同方法在Caltech 101数据库上的训练时间和正确率。由表1可知,与传统方法相比,SR-CELM分类正确率分别比SPM,支持向量机(Support Vector Machine,SVM),核极限学习机(Kernel Extreme Learning Machine,KELM),文献[15]和表示级特征融合的极限学习机(Fusion Extreme Learning Machine,F-ELM)高19.59%,5.79%,4.88%,5.79%和3.53%。SR-CELM因其编码特征的网络结构,正确率比文献[17]高0.23%。与深度学习网络Alex Net,GoogleNet相比,SRCELM以相对更简单、层数更少的网络获得较高分类正确率,由此可证明在物体分类的数据集上,SR-CELM能够有效利用图像中蕴含的各部分特征,提高分类正确率。

表1 Caltech 101正确率(%)与训练时间(s)
3.2 MSRC数据库
本节选择MSRC中的18个类别和MSRC-21数据库中的3个类别,共21类物体图像进行实验。选取训练、测试图像方式和数量与文献[14]一致,共使用1260幅图像进行实验。将提取出的SPM特征、局部位置特征和全局轮廓特征按照文献[15]中[1,12,0.2]的系数进行加权串联并输入网络。
当感受野个数为1,任意固定迭代次数为6,惩罚项P为2−6, K和d变化时,网络正确率变化由图6(a)所示。选取并固定此时最高正确率所对应的参数K,调节P和d,网络正确率变化曲面图如图6(b)所示。当参数组合d,K和P值分别为0.6,2−8和2−1时,网络可达到最高正确率为95.82%。调整循环迭代次数和感受野个数,可得到如图7所示折线图。在字典维数为400维,迭代次数为7,感受野个数为18时,网络最高正确率为96.35%。当字典维数为600维,迭代次数为8,感受野个数为15时,网络能够达到最高正确率96.83%。
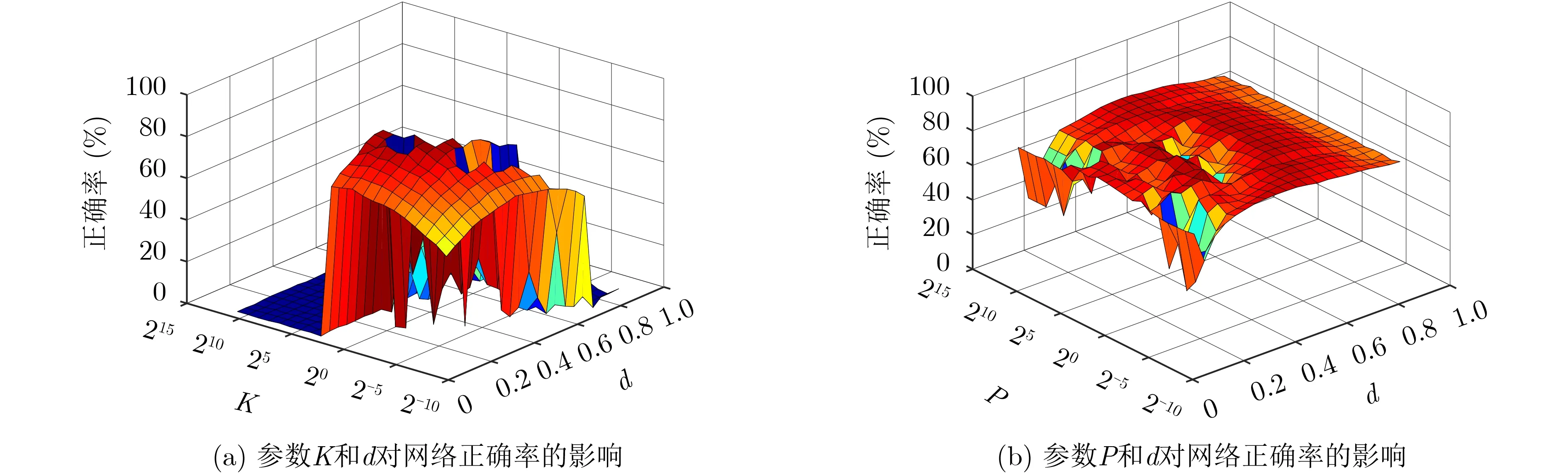
图6 不同参数变化时网络正确率曲面图

图7 不同字典维数下循环次数和感受野个数对网络正确率影响折线图
与3.1节相同,选取MSRC数据库中具有嘈杂背景的5类图像进行实验。SR-CELM、文献[15]、CF-ELM和ELM-MSLRF的正确率对比如图8所示。由图8可知,SR-CELM在各图像小类的分类正确率高于其余3种方法,证明SR-CELM在物体图像分类中能够有效减少嘈杂噪声对分类结果的影响。
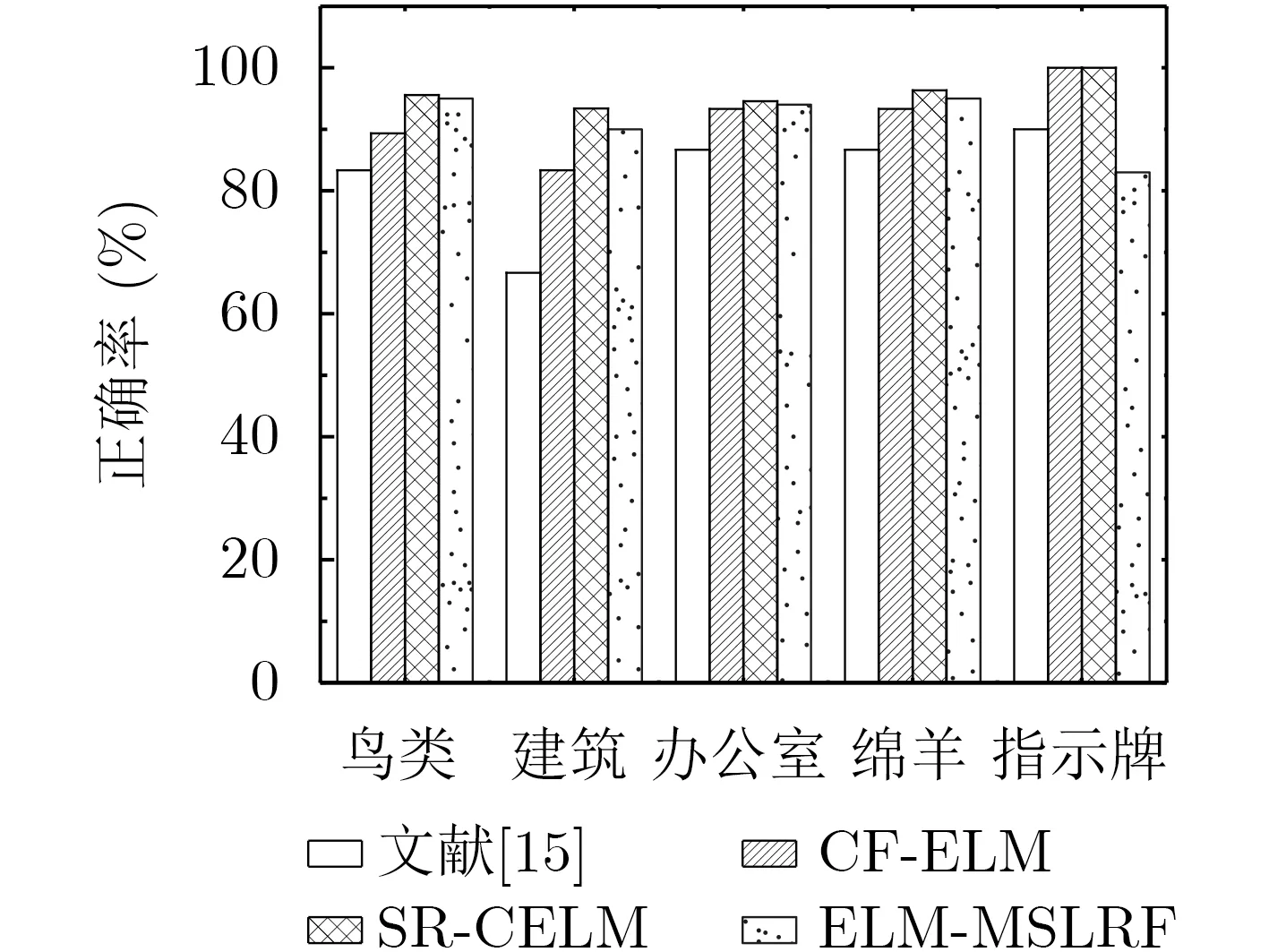
图8 4种方法对MSRC数据库中具有嘈杂背景图像的正确率
表2为不同方法在MSRC数据库上的训练时间和正确率。与其余改进方法相比,在字典维数相同时,SR-CELM分类正确率分别比文献[15],SVM和F-ELM高出2.38%,2.22%和2.86%,具有较高分类精度。

表2 MSRC正确率(%)与训练时间(s)
3.3 15 Scene数据库
本节利用15 Scene数据库测试SR-CELM对场景图像的分类能力,选取训练、测试图像方式和数量与文献[14]一致,总共使用4485幅图像进行实验。将提取出的SPM卷积特征、局部位置特征和全局轮廓特征串联,并将这3部分特征按照[1,0.15,0.35]进行系数加权并输入网络。
当感受野个数为1,迭代次数为6,任意固定惩罚项P为2–6,K和d变化时,SR-CELM的正确率如图9(a)所示。将K固定为图中最高正确率所对应的参数值,并调节惩罚项P,当P和d变化时,网络正确率变化曲面图如图9(b)所示。当d,K和P分别为0.4,2–5和2–4时,网络能达到最高正确率85.86%。

图9 不同参数变化时网络正确率曲面图
为确定循环迭代次数和感受野个数对网络正确率的影响,分别对两个参数进行实验,得到实验结果如图10所示。当字典维数为400维,循环次数为6,感受野个数为21时,网络能够达到最高正确率88.34%;当字典维数为600维,,循环次数为4,感受野个数为21时,网络能够达到最高正确率88.71%。

图10 不同字典维数下循环次数和感受野个数对网络正确率影响折线图
为验证SR-CELM对含嘈杂背景的场景图像的分类性能,选取数据库中具有嘈杂背景的5类场景图像进行测试,SR-CELM,文献[15],CF-ELM和ELM-MSLRF的正确率对比如图11所示。由于不同场景类图像中可能存在相似物体,因此在办公室这一小类上SR-CELM分类正确率略低于CF-ELM。但从整体分类正确率来说,SR-CELM仍然具有良好的抗干扰能力。
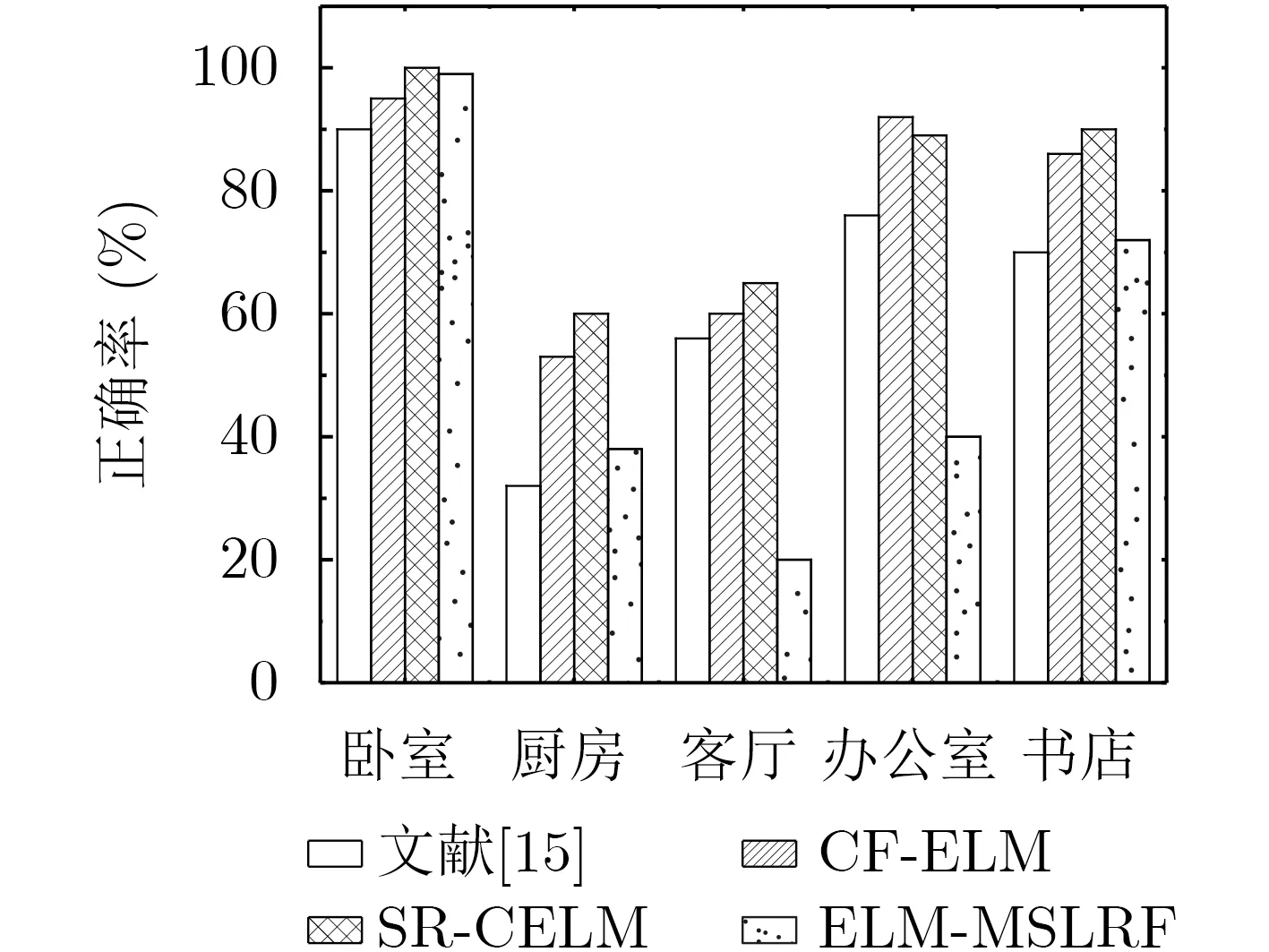
图11 4种方法对15 Scene数据库中具有嘈杂背景图像的正确率
表3将本文实验结果与其他算法进行比较。在字典维数相同时,SR-CELM分类正确率分别比SVM,F-ELM高出1.88%, 4.01%,较同系列的ELM-MSLRF具有明显优势。文献[17]比本文方法高1.39%的正确率,然而其算法的复杂性远高于本文方法。与深度学习网络相比,SR-CELM使用更少的层数和较少的节点数,分别比AlexNet和VGGNet高出13.8%,3.59%,略低于GoogleNet,但SR-CELM利用简单的结构模型和较快的训练速度同样能够达到较高正确率。

表3 15 Scene正确率(%)与训练时间(s)
4 结束语
本文针对空间金字塔SPM特征空间分布信息利用不足的问题,提出了空间金字塔与感受野相结合的相关熵极限学习机,并将其用于图像分类中。通过大量实验并分析实验结果可知,在特征提取时,将空间金字塔与局部感受野相结合能进一步利用特征的空间信息,并利用所提出网络对特征进行编码,有效实现了多特征的融合。在网络权重训练时,利用相关熵准则分别构建实际输出与期望输出的角度和模长约束,提高了网络分类能力和稳定性。因此理论推导和实验结果表明,SR-CELM具有良好的鲁棒性和分类性能,但是,基于相关熵准则求解网络输出权重需要迭代调整,如何不通过迭代直接解析地求解权重是下一步研究的方向。
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
中华养生保健(2020年7期)2020-11-16
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学阅读指南·低年级版(2019年11期)2019-07-01
小学生学习指导(低年级)(2018年9期)2018-09-26
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
创新作文(小学版)(2016年19期)2016-08-22
