
APSO_LightGBM模型在高血压风险预测中的应用
2021-08-24 08:04胡逾航
湖北工业大学学报 2021年4期
郑 列,胡逾航
(湖北工业大学理学院, 湖北 武汉 430068)
我国心血管疾病患者绝大多数也是高血压患者[1]。高血压早期可能无症状,容易被患者所忽视,因此其早期排查与及时干预有着重要意义。谭恒[2]使用决策树算法对高血压发病风险进行预测;Pei[3]构建了基于支持向量机的高血压预测模型,讨论了环境因素和遗传因素对患原发性高血压的影响,并使用Laplace核函数对模型进行改进;赵书颖[4]探讨了中医症候和高血压之间的联系;Ren[5]使用双向长期短期记忆模型(BiLSTM)捕获电子病历中的文本信息,探讨高血压疾病对肾脏疾病的影响。龚军等[6]使用logistic、随机森林、神经网络等多种算法构建高血压风险分类模型,发现XGBoost模型的诊断精度最高。支持向量机和神经网络在处理非线性问题上都有其独特优势,然而支持向量机算法会随着数据规模的增大而计算变得低效。神经网络在建立模型时需要大量的参数,其输出结果通常难以解释,更适合对非结构化数据进行建模。本文使用LightGBM集成算法构建高血压风险预测模型。为了进一步提升模型性能,利用自适应粒子群算法对LightGBM算法进行优化,以精准定位高血压的致病因素,辅助医疗人员通过早期干预降低其发病率。
1 APSO_LightGBM模型
1.1 LightGBM模型
1.1.1梯度提升决策树梯度提升决策树(Gradient Boosting Decision Tree,GBDT)是一种以回归树为基学习器的集成算法。同时,它也是一个加法模型,即所有基学习器的线性组合作为其最终的结果。该算法可以用于解决回归问题与分类问题,其思想是在每次迭代中通过拟合负梯度作为残差的近似值来学习一个基学习器。GBDT的主要计算成本在于学习决策树。由于决策树在计算分割节点的信息增益时会对每个特征遍历所有数据点,随着样本量与特征维度的增大,其计算代价也会成比例上升。
1.1.2LightGBM算法LightGBM是一种基于GBDT的算法,由微软团队于2017年提出[7]。为了解决GBDT在计算复杂度上的问题,可以从两个角度进行改进——减少特征数和减少训练样本数。基于这个思想,LightGBM提出了单边梯度采样(GOSS)和互斥特征捆绑(EFB)两种策略,在保证模型精度的同时,提升了模型的计算速度。
GOSS算法保留所有梯度较大的样本,并对剩下梯度样本进行随机采样,这样可以在不改变数据分布的同时,使得训练误差大的样本得到更大的关注。在GBDT算法中,信息增益通常是通过分裂后的方差来度量的,假设O为单棵决策树一个固定节点内的数据集,此节点处特征j在分割点d的信息增益定义为:
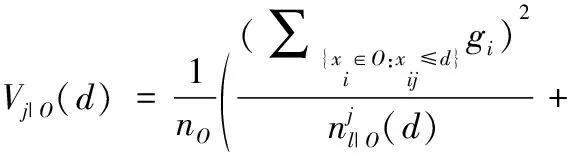
(1)
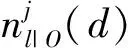
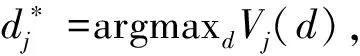
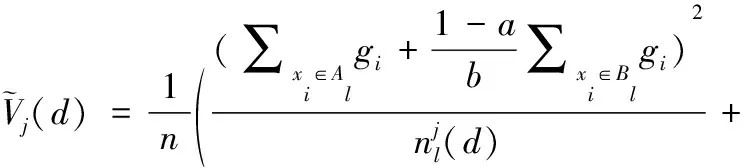
(2)
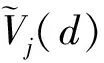
EFB算法的思想是将很多互斥特征捆绑成少量的稠密特征。互斥特征指的是不同时取非零值的特征。高维数据通常具有稀疏的特点,并且在稀疏特征空间中,许多特征是互斥的,通过EFB算法可以减少很多针对特征取值为0的多余运算。
1.2 APSO_LightGBM模型
1.2.1自适应粒子群优化算法粒子群优化算法(Adaptive Partical Swarm Optimization, APSO)是一种生物启发式算法,它被通常认为是群集智能算法的一种,其思想是通过模拟鸟群捕食的行为——即模拟其集体协作的方式——寻找最优解[8]。在搜寻食物的过程中,食物附近的鸟会向其他的鸟传递位置信息,使得整个鸟群都能聚集到食物附近。该算法中,鸟被抽象为没有质量的粒子,且仅具有速度和位置两个属性。
PSO算法先随机地初始化一群粒子,即事先给定这群粒子的初始速度与初始位置,并定义适应度函数。粒子在搜索空间中运动受到其自身过去最佳位置的影响以及整个群体过去最佳位置的影响,在两个最佳位置的引导下,种群逐渐收敛,慢慢靠近最优解。粒子i在n维空间中的速度和位置:
(3)
式中:k表示当前迭代次数;c1和c2称为学习因子,是两个正数;r1与r2是[0,1]范围内生成的两个随机数;vij表示粒子i在维度j上的速度;xij表示粒子i在维度j上的位置。粒子i到达过的最佳位置表示为pi=(pi1,pi2,…,pin)T,整个群体所有粒子达到的最佳位置表示为pg=(pg1,pg2,…,pgn)T。
PSO算法参数少并且操作简单,是目前较为实用的优化算法之一,但是其存在收敛速度慢且容易陷入局部极值等缺点。针对上述问题,Shi[9]引入了惯性权重的概念,将之作为一个平衡因子。当惯性权重的值较大时,粒子有更好的全局搜索能力;其值较小时,粒子有更好的局部搜索能力。惯性权重因子记为ω,速度
(4)
为了进一步提升PSO的性能,本文提出一种自适应粒子群优化算法,自适应主要体现在寻找合适的惯性权重因子,改进策略如下。
1)先对第t次迭代的所有粒子求其适应值。若适应度函数期望取得最大值,就将所有粒子适应值按大小降序排序;若适应度函数期望取得最小值,就将粒子按适应值升序排序。随后将所有粒子分成两半,并计算每一部分的平均值,分别记为favg1,favg2。
2)将每一个粒子适应值与favg1、favg2进行比较。若优于favg1,则认为粒子已趋近全局最优,此时惯性权重ω取0.2;若次于favg2,则认为该粒子仍离全局最优值较远,此时惯性权重ω取0.9,利于其进行全局搜索;若在两者之间,则ω在[0.4,0.6]之间随机取值。
1.3 APSO_LightGBM模型
LightGBM算法超参数较多,选取不同的超参数会直接影响最后的模型预测结果。目前常见的超参数优化方法包括网格搜索法与随机搜索法。
网格搜索是目前最普遍的超参数优化算法,通过对各种需要优化的超参数组合空间进行暴力搜索来寻找使得目标函数达到最佳的那组超参数。然而,网格搜索法并不适用于连续参数空间,并且随着超参数的增多,其搜索空间大小会呈指数型增长,相当耗费时间。
与网格搜索相比,随机搜索并未尝试所有参数值,而是通过对搜索范围的随机取样选取超参数,因此随机搜索一般会比网格搜索要快一些,但是它高度依赖初始值。Bergstra[10]在实验中证明了参数优化时随机搜索比网格搜索更有效。
APSO_LightGBM可以很好地解决上述问题,其伪代码如图1所示。其中M为种群数量,K为迭代次数,c1与c2为学习因子,需要优化的参数个数为N。

图 1 APSO_LightGBM伪代码
2 实证分析
为了验证APSO_LightGBM在高血压风险预测上的性能,使用美年大健康有限公司2018年公开的体检数据集进行研究。数据集提供收缩压、舒张压的值作为高血压患病的评估标准。对数据进行统计,共计有47749条数据,2800个变量,每个变量代表一个体检项目。
2.1 数据预处理
首先对数据进行初步筛选,将缺失值达到95%的特征删除,并且删除仅有单一值的特征。完成初步筛选后,特征数从2800减到了378。
因为数据中存在着较多的文本特征,而文本特征与数值类特征需要进行不同的处理,因此需要先对特征进行分离,分离的过程如图2所示。对于数值型特征,先进行异常值处理,超过上四分位1.5倍IQR距离的样本点为异常值,对其进行删除,并将缺失值用均值填充;对于文本类特征,短文本提取关键字并直接进行编码,长文本使用Doc2Vec方法进行处理,并设置其向量维度为5,缺失值使用null字符进行填充。最后对数据进行整理,预处理之后的数据一共包含38191条数据,790个特征。
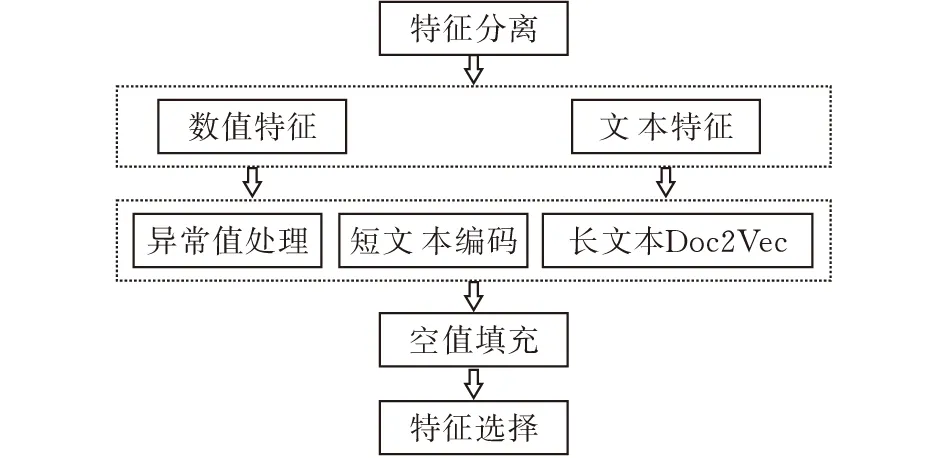
图 2 特征分离流程
2.2 特征选择
在机器学习中,训练数据的维度并不是越高越好,高维度必然伴随着高计算复杂度,且并不是所有的特征都与预测结果相关,一些不相关的变量会对模型预测效果起到负面影响[11],适当的特征选择会提高模型的效率与精度。采用了递归特征消除(RFE)[12]与交叉验证结合的方式(RFECV)进行特征选择。递归特征消除的思想是使用一个基模型来进行多轮训练,每轮训练后,移除特征重要性较低的一部分特征,再基于新的特征集进行下一轮训练。由于每一轮去除的特征中可能保留部分有效信息,所以模型在特征选择后的数据集上的表现可能会差于原数据集。对收缩压与舒张压建立预测模型,并分别对两个模型进行特征选择,选择使得得分最高的一些特征。表1为各预测模型对应的特征数。

表1 各预测模型对应的特征数
2.3 超参数优化
LightGBM有较多的超参数,不同的超参数对模型起到不同的作用。本文选取LightGBM模型的6项主要参数。对于传统寻参方法存在的缺陷,本文提出自适应粒子群优化算法寻找其最佳参数。
根据粒子群优化算法的特点以及数据集的大小,设置初始种群数为100,每个个体包含6个参数,参数在所给范围内随机生成;设置进化次数为50,以均方误差作为适应度函数,设置学习因子c1与c2的值为1.5。优化过程如图3所示。可以发现,相比原始的PSO优化算法,APSO算法收敛得更快,并且表现出更好的全局搜索能力。
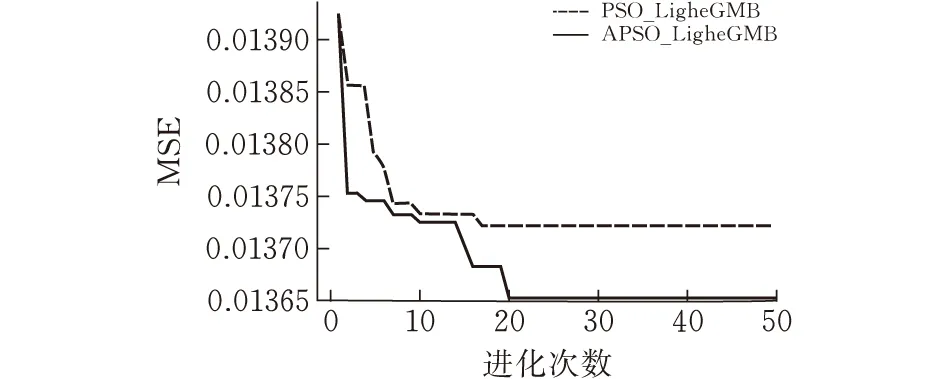
(a)收缩压模型参数优化过程
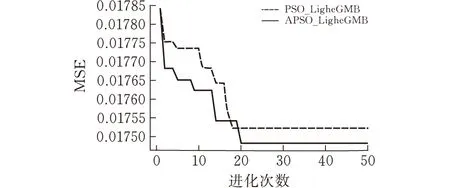
(b)舒张压模型参数优化过程图 3 粒子群优化算法寻找超参数
2.4 实验结果及分析
采用python语言对数据进行分析,以收缩压、舒张压为预测指标分别建立对应的预测模型。
2.4.1验证RFECV合理性体检数据是一个高维数据。为了降低其维度,使用RFECV进行特征选择。为了验证该算法的有效性,实验使用经过RFECV算法选择后的特征进行模型训练,并将其与原始特征训练的模型进行对比。模型均使用默认超参数,并以5折交叉验证的方式进行训练。两者在时间与精度上的对比如表2所示,表格中的平均均方误差指的是两个模型均方误差的平均值,运行时间指的是两个模型训练的总时间。实验分析可得,使用RFECV降维后,模型在时间效率上提高了31.8%,而在评估指标上只下降了0.37%,所以使用RFECV方法进行特征选择是合理的。
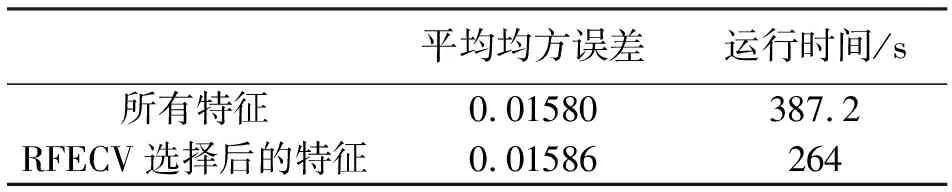
表2 RFECV特征选择前后性能对比
2.4.2验证APSO算法的优越性由于特征选择后可以大大降低计算成本,且对模型的精度不会有太大的影响,所以超参数的优化实验都是基于RFECV选择后的特征。为了验证自适应粒子群优化算法的优越性,实验同时使用网格搜索与随机搜索两种传统方式对超参数进行优化,最后将三者的结果进行对比。由于网格搜索会消耗大量的时间成本,所以本次对比实验只选用了收缩压预测模型,实验中优化的参数空间如表3所示。
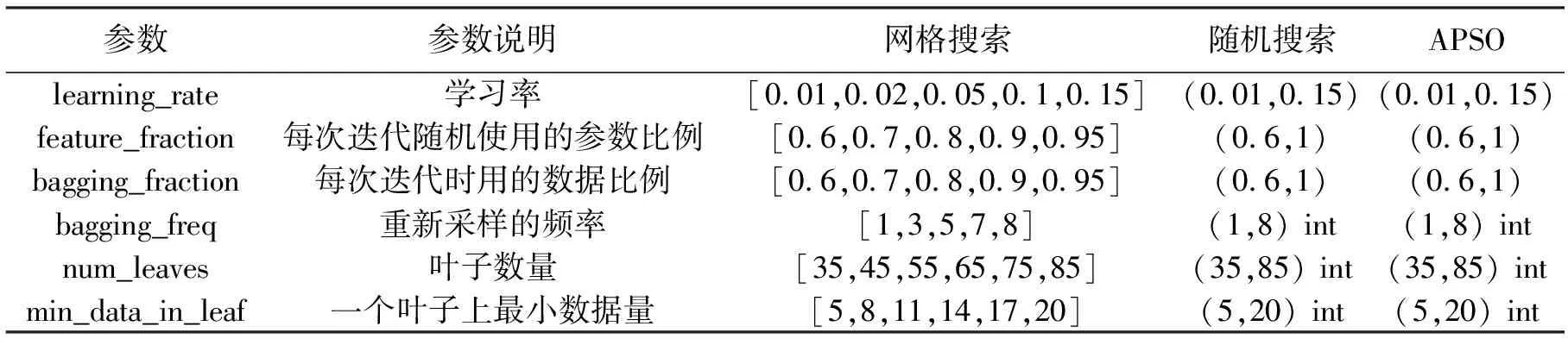
表3 参数空间
将APSO_LightGBM与网格搜索、随机搜索以及LightGBM的默认参数进行对比,不同的优化方法选择相同范围的参数空间,并使用运行时间与均方误差MSE作为评估指标。由于APSO算法设置了种群大小为100,50次的进化,即相当于5000次迭代,故将随机搜索的迭代次数也设置为5000以方便对比。实验结果如表4所示,表中网格搜索的运行时间为其搜索完待选参数空间所需的时间,随机搜索的运行时间为其迭代5000轮的时间,APSO的运行时间为其精度不再变化后的时间,即完成收敛所需的时间。参数列表的顺序为learning_rate、feature_fraction、bagging_fraction、bagging_freq、num_leaves和min_data_in_leaf。
从表4中的数据看出,网格搜索虽然有精度上的提升,但是会花费大量的时间成本;随机搜索的运行时间相比网格搜索大大减少了,而且在精度上也比网格搜索略好一些;自适应粒子群优化算法相比网格搜索与随机搜索,在精度上有显著的提升,而且运行时间远远小于网格搜索与随机搜索,所以使用自适应粒子群优化算法寻找超参数是有效的。
2.4.3验证APSO_LightGBM算法的有效性为了验证APSO_LightGBM模型对高血压风险预测的有效性,选择线性回归、决策树、支持向量机以及LightGBM与其进行对比分析。采用MAE(平均绝对误差)、MSE(均方误差)和R-squared(决定系数)作为模型的评价指标,其中MAE与MSE两个评价指标用于评估真实值与预测值之间的差异,数值越小代表预测越准确,R-squared用于评估模型的解释度,数值越大,说明模型解释性越强。实验结果如表5所示,其中的数值为两个预测模型对应指标的平均值。可以发现APSO_LightGBM的预测精度优于其他模型,并且在解释性上也得到了增强。
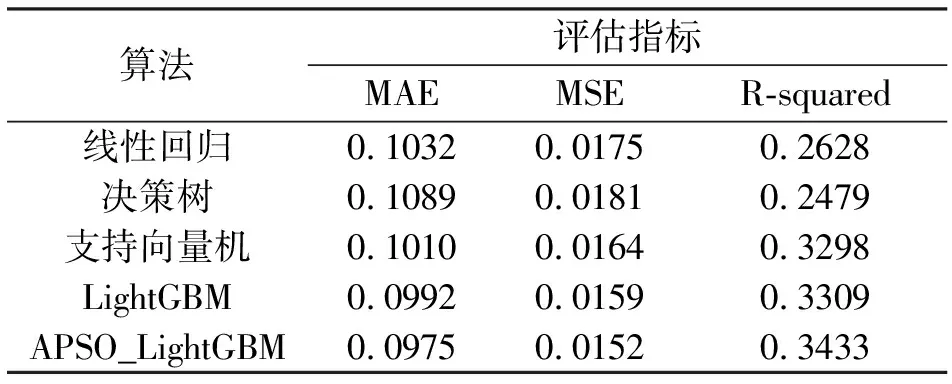
表5 算法对比
3 结果与分析
通过验证,APSO_LightGBM算法性能最优。图4给出了基于该算法的两个预测模型最相关的15项文本特征。结果显示,收缩压、舒张压与心率、是否具有病史、肝功能、甲状腺、子宫以及前列腺等的健康程度呈高度相关。有研究表明,高血压与血清甲状腺激素有着密切的关系[13];对前列腺增生实施药物或者手术干预能在一定程度上降低血压[14];子宫内膜异常可能导致患高血压的风险增高[15]。从本文研究结果可以看出,模型得到的重要性特征与医学结果大部分契合。因此心率不齐、甲状腺功能低下、子宫或是前列腺异常、肝胆疾病的患者或曾有类似病史的人群通过早期检测这些强重要性特征,可以实现高血压的精准预防。
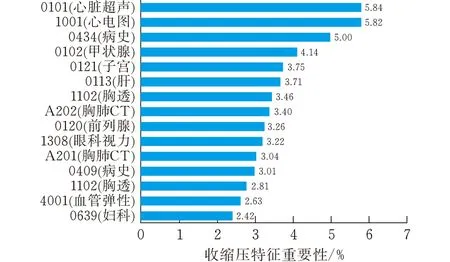
(a)收缩压
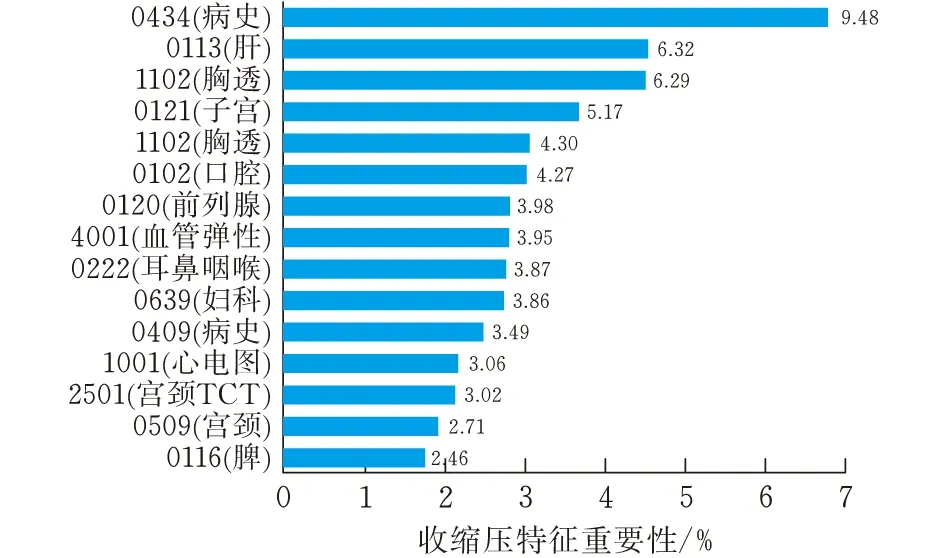
(b)舒张压图 4 收缩压与舒张压模型特征重要性排名
4 结论
本文提出一种基于集成算法LightGBM的高血压风险预测模型,并根据体检数据指标冗余的问题,引入RFECV算法进行特征选择,实验表明其在降低维度的同时保证了模型的精度。此外,为了提升模型的性能,引入自适应粒子群优化算法寻找最优超参数。结果表明,改进的模型相比传统的超参数优化算法性能有很大的提升,并且比常用的线性回归、决策树和SVM方法有更好的预测精度。APSO_LightGBM模型结合了自适应粒子群算法的全局搜索能力和LightGBM算法的高效性与广泛性,除了本文的应用场景外,该模型还可以应用于其他疾病的预测问题。但在实验过程中,模型的运行时间比较长,降低自适应粒子群优化算法的计算复杂度有待进一步研究。接下来的工也会考虑优化LightGBM算法的损失函数,进一步提升模型精度。
猜你喜欢
昆明医科大学学报(2022年1期)2022-02-28
北京信息科技大学学报(自然科学版)(2021年2期)2021-05-20
华人时刊(2021年23期)2021-03-08
作文新天地(初中版)(2019年6期)2019-08-15
分析化学(2018年12期)2018-01-22
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
飞碟探索(2015年8期)2015-10-15
