
改进cell密度聚类算法在空战目标分群中的应用
2021-08-24 03:17闫孟达杨任农左家亮嵇慧明尚金祥
国防科技大学学报 2021年4期
闫孟达,杨任农,王 新,左家亮,嵇慧明,尚金祥
(1. 空军工程大学 空管领航学院, 陕西 西安 710051; 2. 中国人民解放军94994部队, 江苏 南京 210019;3. 中国人民解放军94701部队, 安徽 安庆 246000; 4. 中国人民解放军94347部队, 辽宁 沈阳 110042)
空战目标分群是态势感知[1]阶段的关键步骤,其目的在于根据当前空战环境,综合分析速度、航向和位置等态势要素,将敌方参战力量按一定的层次结构划分为不同的空间群和相互作用群[2],帮助指挥员将纷繁复杂的目标信息规整为不同类型的目标群组,有助于减少冗余态势信息,降低态势评估难度,提高空战决策准确度[3-4]。
目前,目标分群主要有两大类方法。一类是基于相似性度量、优化算法和神经网络的模型法。文献[5-7]通过建立目标位置、航向等属性的相似度函数,将相似度较大的目标划分到同一群组。该方法虽然计算简单,但需根据属性的不同设置多种相似度调节系数和决断阈值,实际应用效果不佳。文献[8-10]分别利用蚁狮优化算法[11]、自组织特征映射(Self-Organizing Feature Mapping, SOM)神经网络[12]、遗传算法和支持向量机(Support Vector Machine, SVM)处理目标分群问题,这四种方法虽然实时性较好,但其稳定性相对较差且SOM和SVM的训练数据难以获得。另一类是对目标属性进行聚类分析的属性聚类法。文献[13]首开基于聚类算法处理目标分群问题的先河,此后研究主要集中于如何使聚类算法更好地适用于目标分群问题。文献[14-15]运用改进的K-means和模糊C均值聚类算法解决目标分群问题,上述算法只适用于编队数目已知的聚类问题,虽然可以通过算法改进推理出可能的编队数目,但其准确度相对较差。文献[16-17]基于Chameleon算法处理目标分群问题,虽然该算法可处理类数未知问题且准确度较高,但其实时性相对较差。文献[18]通过改进迭代自组织数据分析技术算法(Iterative Self-Organizing Data Analysis Techniques Algorithm, ISODATA)的分裂标准提高了分群效率,但该方法以欧式距离衡量目标相似度,只对球形分布数据有良好的聚类效果[19],而空中目标往往呈流形列队,故该方法难以适用于目标分群。文献[20-21]基于流形距离分别改进密度峰值算法和二阶段聚类算法,使其能够处理流形分布聚类问题,提高了目标分群的准确度,但流形距离计算复杂,容易造成实时性较差的问题。因此,发现一种能够实现流形聚类,且实时性和准确度相对较好的聚类算法,是处理目标分群问题的关键。
基于cell的密度聚类(Cell-based Density Spatial Clustering of Applications with Noise, CBSCAN)算法[22]可以在事先不知道簇类数目的情况下,在含有噪声点的数据集合中发现任意形状的簇,对流形分布数据有较好的聚类效果。本文通过改进CBSCAN算法的簇类扩展方式,在保证算法准确度的同时,提高目标分群的实时性。
1 目标分群模型
目标分群是空战态势评估的首要任务。现代空战中,敌方往往以多编队协同空战的方式向我方目标发起进攻,其主要编队样式为图1所示的流形分布。若对敌方每架飞机逐一进行态势评估,工作量很大且耗时较长。目标分群技术可以将编队内部战机划分为一个整体,用对整体的评估预测代表对内部每架战机的评估预测。
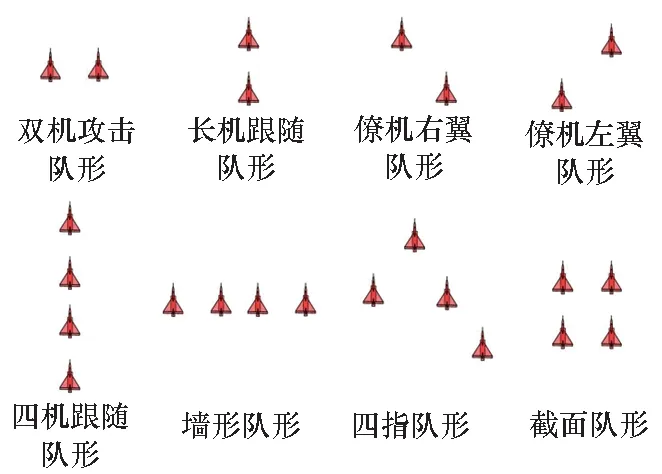
图1 基本编队队形Fig.1 Basic formation style
1.1 分群类型
目标分群抽象层次如图2所示,空战目标分群是自底向上的分析推理过程,其主要分为:
1)空战目标——参与空战过程的作战飞机(歼击机、轰炸机等)及部分导弹。
2)空间群——空间位置相近且类型相同的空战目标。
3)相互作用群——执行相同任务的空间群。
4)中立、敌、我方目标群——根据敌我属性进行划分后的相互作用群。
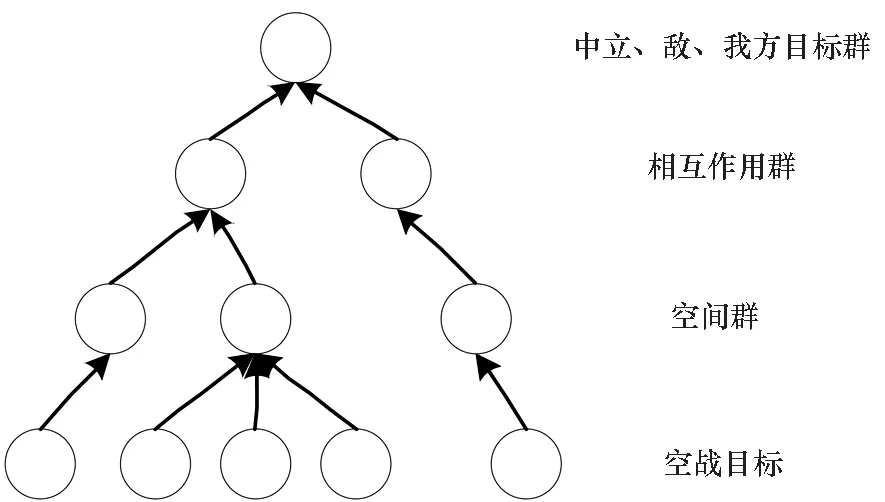
图2 目标分群抽象层次Fig.2 Target grouping abstraction level
1.2 分群模型
令空战目标数据集合为D={d1,d2,…,dn},其中di=(Fofi,Typei,xi,yi,θi,vi)(i=1,2,…,n)表示第i个空战目标。目标各属性参数如下所示。
Fof:空战目标的敌我属性。该参数可以由战机上的敌我应答机自动判定,是进行目标分群的前提,只有当目标的Fof值一致时,才可将它们归为一类。Fof=0表示目标为中立方目标;Fof=1表示目标为我方目标;Fof=2表示目标为敌方目标。
Type:作战飞机类型,主要包括直升机、歼击机、轰炸机等。不同类型的飞机一般执行不同的任务,处于不同的空间群。
{x,y}:作战飞机的横纵坐标。一般情况下,根据目标在xy平面上的分布即可将它们划分到不同的空间群中。为节省时间开支将忽略目标的飞行高度数据,只根据横纵坐标进行空间群划分。
{θ,v}:作战飞机的航向和速度值。由于航向和速度可以体现战机执行任务的对象和任务类型,因此划分空间群后,基于每个空间群的平均航向和速度,利用分群算法划分相互作用群。
根据如图3所示的模型框架,利用分群算法,最终可将探测到的空战目标分为敌我识别群CC1、空间群CC2和相互作用群CC3。对于每种分群类型CCi,都包括多个群体Cj。例如CC3={C1,C2,…,Ck}表示将目标分成了k个不同的相互作用群。
在获取空战目标数据的基础上,寻求一种可以快速准确得到空间群的方式。
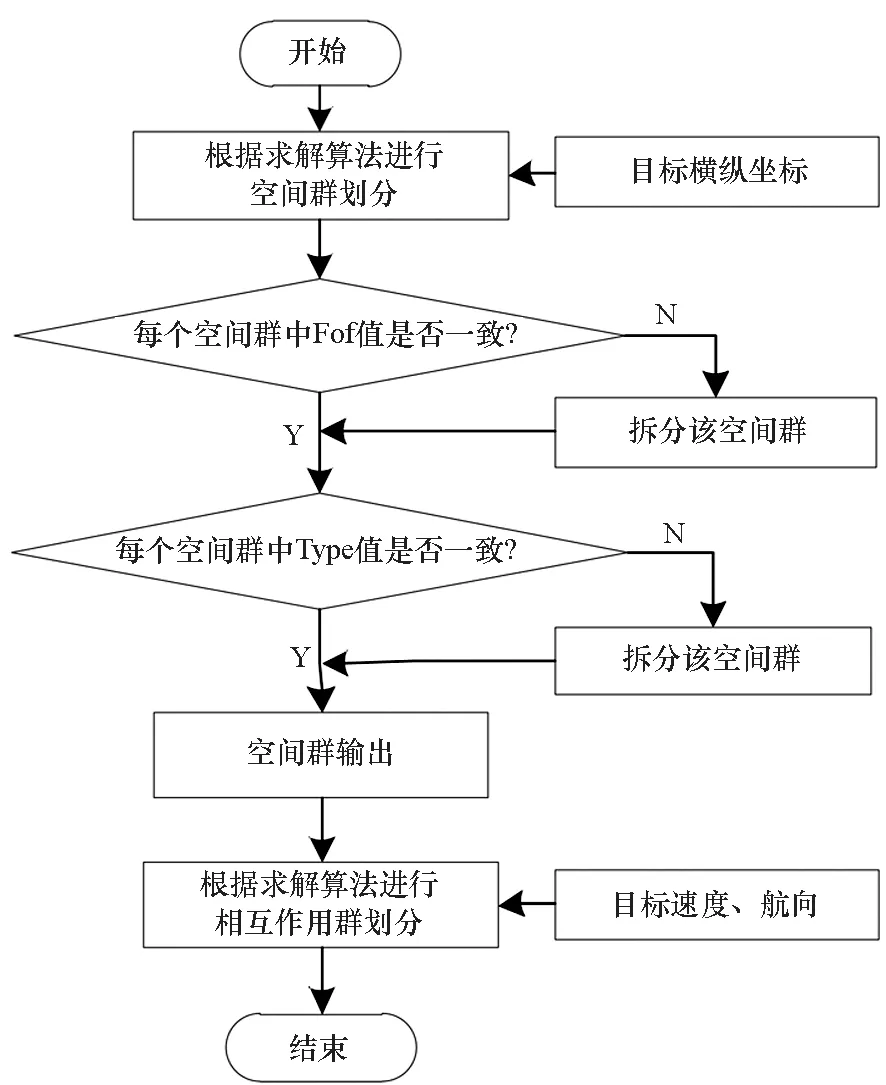
图3 目标分群模型框架Fig.3 Target grouping model framework
2 改进的CBSCAN算法
CBSCAN是一种基于密度聚类(Density-Based Spatial Clustering of Applications with Noise, DBSCAN)算法[23]进行划分改进的聚类算法。进一步改进CBSCAN的簇类扩展方法,以提高CBSCAN算法的聚类实时性。
2.1 DBSCAN算法
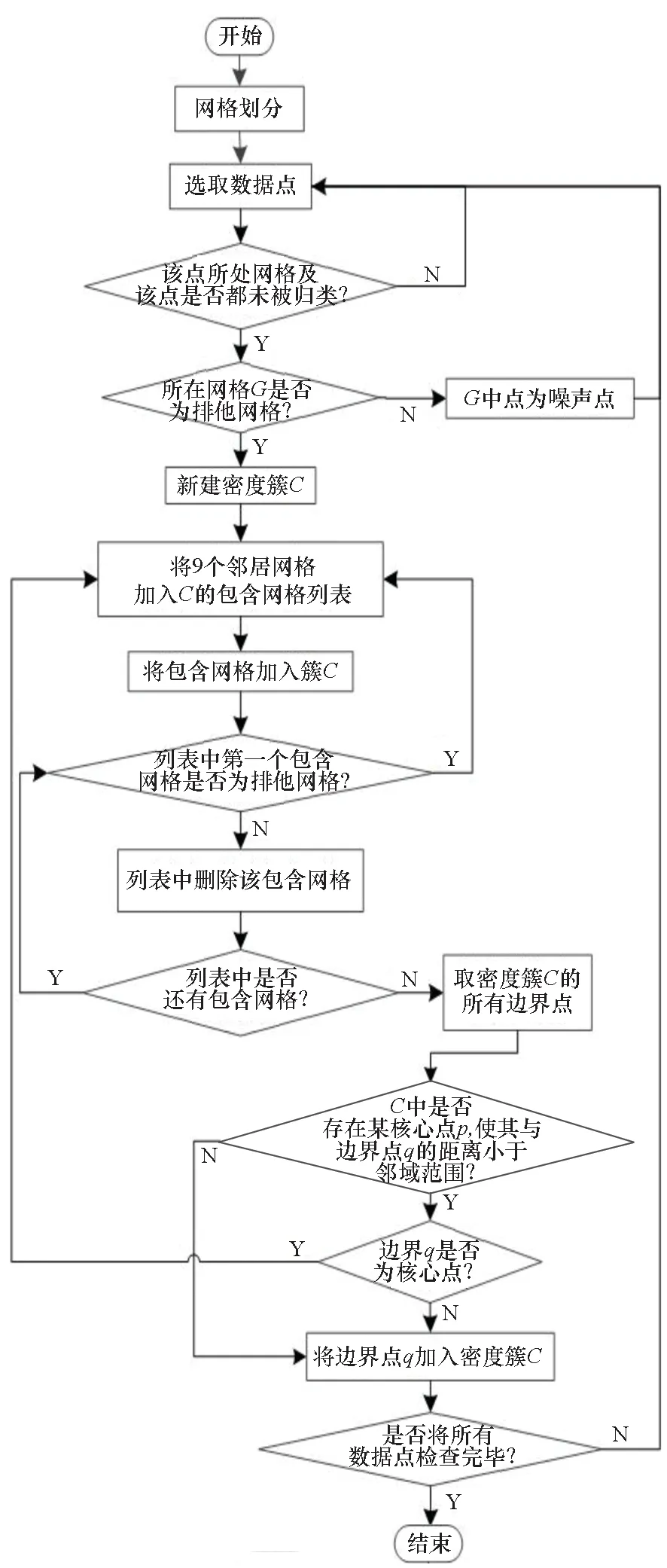
DBSCAN算法是一种应用广泛的聚类算法。该算法主要通过邻域范围半径ε和最小邻域点数目阈值MinPts将数据点划分为核心点、边界点和噪声点,继而通过数据点之间的密度关系进行簇的划分。DBSCAN算法的基本概念及其流程如下所述。
2.1.1 点的划分
DBSCAN算法根据数据点密度及其位置关系,将数据点分为核心点、边界点和噪声点。划分方法如图4所示。
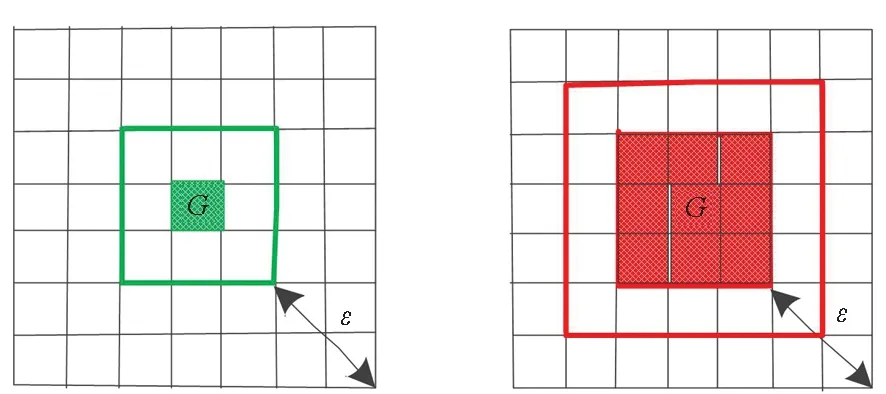
邻域Nε(p):以数据点p为圆心,以邻域范围ε为半径的圆形范围内的数据点。表示为Nε(p)={q∈D|dist(p,q)≤ε},其中D为数据点集合,dist(p,q)为p,q两点间的欧式距离。|Nε(p)|为p点ε邻域内的邻居点个数,以此表示数据点p的密度。
核心点:如果点p的邻居点个数满足|Nε(p)|≥MinPts,则点p为核心点。
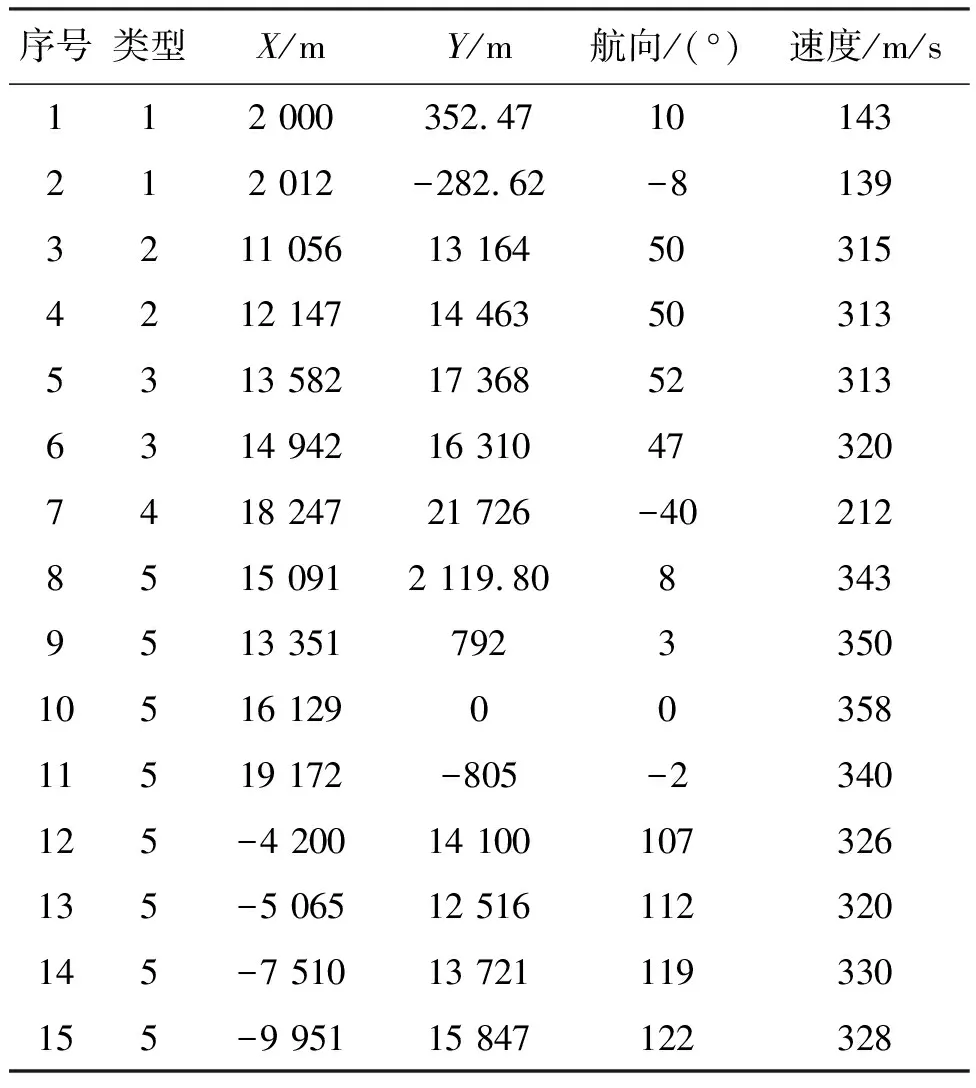
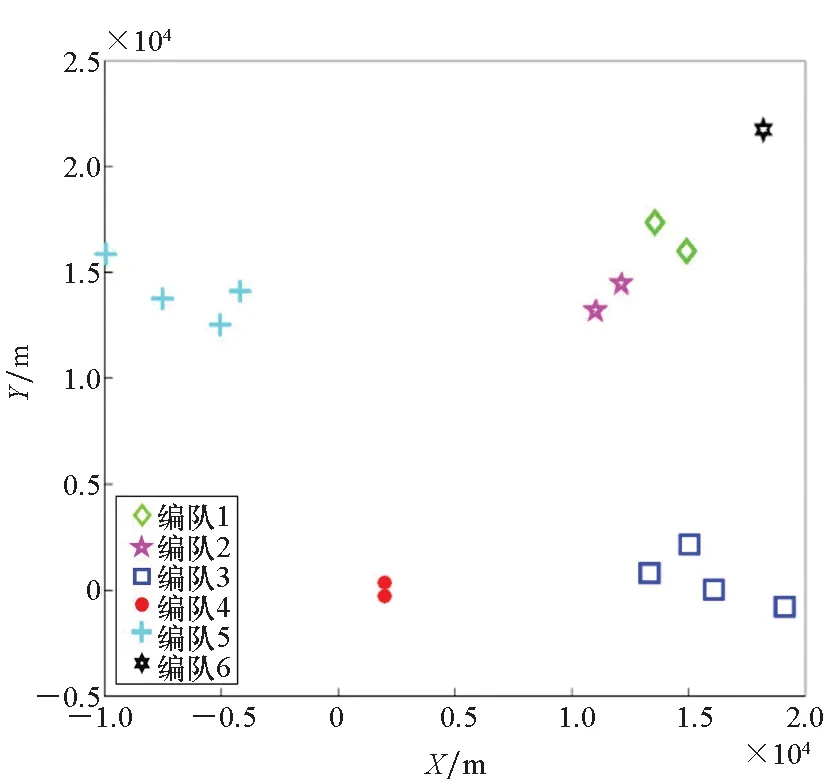
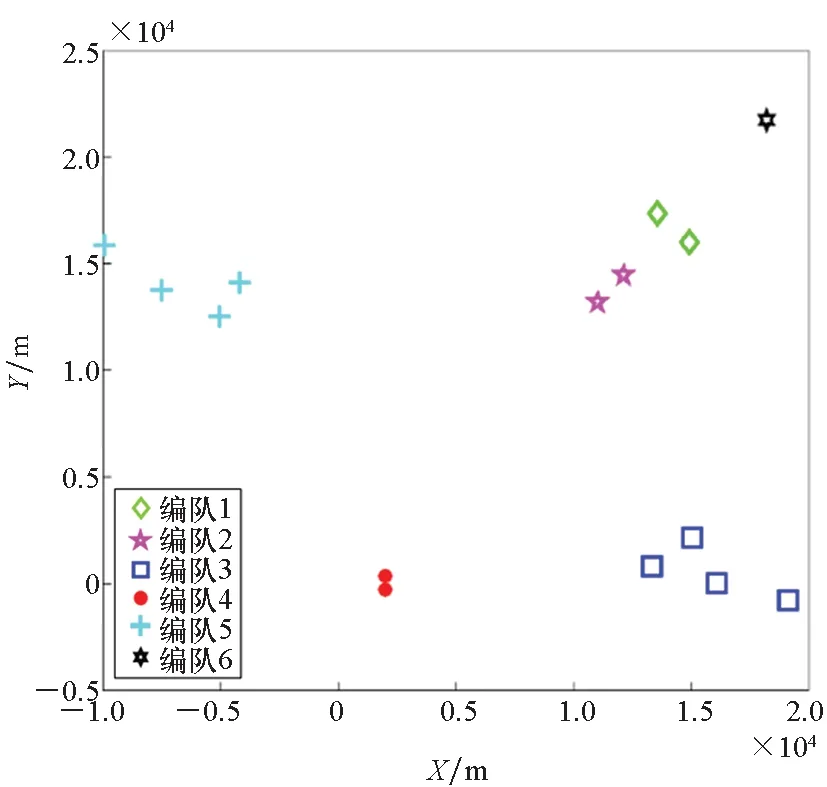
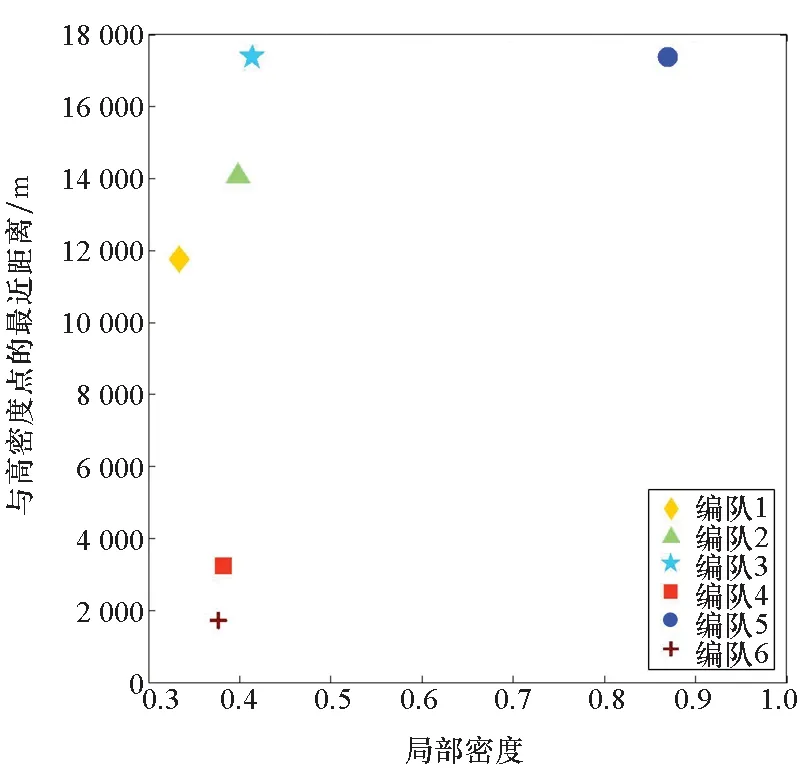
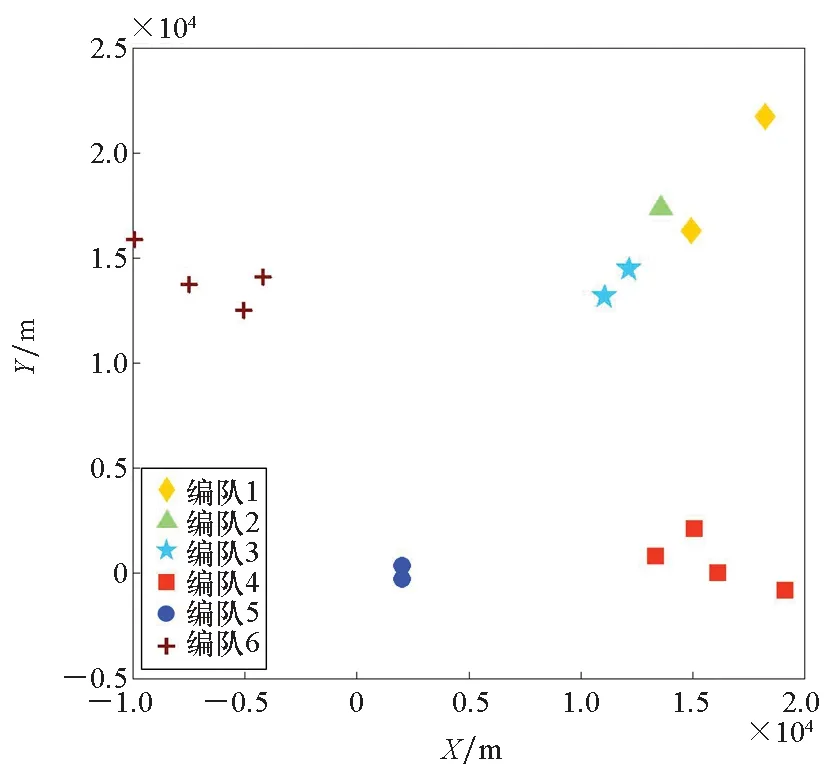
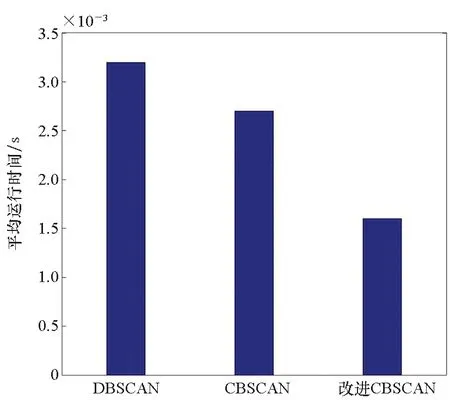
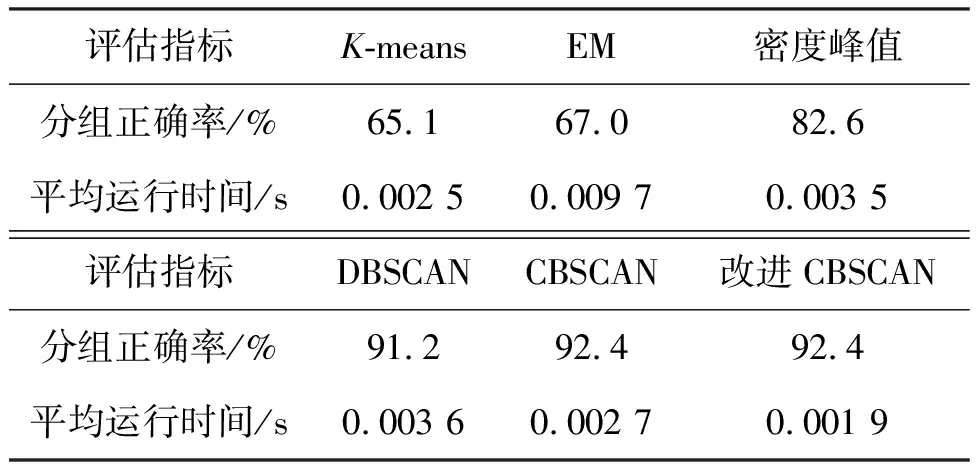
边界点:如果点p的邻居点个数满足|Nε(p)| 噪声点:如果点p既不是核心点,又不是边界点,则该点为噪声点。即邻居点个数满足|Nε(p)| 图4 划分流程Fig.4 Division process 2.1.2 密度关系 DBSCAN算法将同一簇中任意两点间的密度关系分为直接密度可达、密度可达、和密度相连三种情况,进而由密度可达关系导出最大密度相连的样本集合,以此为最终簇。 直接密度可达:如果位置点p满足p∈Nε(q),且q为核心点,则点p直接密度可达点q,即点p直接密度可达其ε邻域内的任一核心点。 密度可达:给定位置点p1,p2,…,pn,如果pi直接密度可达pi+1(i=1,2,…,n-1),则p1密度可达pn。 密度相连:如果点p和点q都密度可达点l,则点p与点q密度相连。 密度簇:所有密度相连数据点构成的数据集合。 2.1.3 算法流程 DBSCAN算法流程如图5所示,DBSCAN算法从数据集合D中的任意一点p开始,检索其ε邻域中的数据点。如若|Nε(p)|≥MinPts,则将建立一个新的密度簇C,并对该簇进行扩展。由于DBSCAN算法需计算每个点的邻域点数目,计算量较大,耗时较多。 图5 DBSCAN 算法流程Fig.5 DBSCAN algorithm flow 图6 CBSCAN算法网格划分Fig.6 Meshing of CBSCAN algorithm 1)包含网格:给定某单元格G(b1,b2)和密度簇C,对于∀p(p∈G(b1,b2)),若满足p∈C,则G(b1,b2)是C的包含网格。 2)XG1型排他网格:若式(1)成立,则G(b1,b2)中数据点都是核心点,此时定义G(b1,b2)是某密度簇的XG1型排他网格。 (1) 由于G(b1,b2)周围8格中任一点与G(b1,b2)中任一点(核心点)的距离都小于等于ε,根据直接密度可达关系,可以将包括G(b1,b2)在内的9格都划为同一密度簇,此时G(b1,b2)周围8格均为密度簇的包含网格。 3)XG2型排他网格:若式(1)不成立,则检查G(b1,b2)周围45格中数据点与G(b1,b2)中所有点间的距离关系。若∃p(p∈G(b1,b2)),使得式(2)成立,则G(b1,b2)中存在核心点p,此时定义G(b1,b2)是簇的XG2型排他网格。由于G(b1,b2)周围8格中的点与G(b1,b2)中核心点p的距离均小于等于ε,与XG1型排他网格相同,也可以将包括G(b1,b2)在内的9格划为同一密度簇。 ∑qk≥MinPts (2) 此后,检查排他网格的邻居网格和含有边界点的网格是否为排他网格,以此进行密度簇的扩展。CBSCAN算法流程如图7所示。 图7 CBSCAN算法流程Fig.7 CBSCAN algorithm flow 分析图7所示流程可知,CBSCAN算法运用网格划分的方式将数据点划分到网格中,把数据点的查询归类转化为网格的查询归类,较大地减少了DBSCAN算法的时间开销。但该算法仅通过1个排他网格附带周围8个包含网格的方式进行簇类扩展,在高密度区的扩展效率依然相对较低。 1)XG3高密型排他网格:对于单元格G(b1,b2),若式(3)成立,则G(b1,b2)是XG3高密型排他网格。如图8(b)所示,此时网格G(b1+i,b2+j),(i=-1,0,1;j=-1,0,1)均是XG1型排他网格,可向外扩展25个包含网格。 |G(b1,b2)|≥MinPts (3) (4) (5) (c) XG4中密型排他网格(c) XG4 exclusive grid (d) XG5次密型排他网格(d) XG5 exclusive grid图8 排他网格示意图Fig.8 Exclusive grid diagram 由上述定义分析可知,在CBSCAN算法中,当确定某网格G(b1,b2)为排他网格时,最多只能将9个包含网格扩展到密度簇中。通过提出高密、中密和次密型排他网格等概念,一次查询最多可以扩展25个包含网格。 1)剔除异常值。空战态势数据中难免会存在部分异常值,常见的异常值处理方法主要包括删除元组、数据补齐、缺失值处理和不处理等,采用删除元组的方式处理异常值。孤立森林算法是一种无监督的异常检测方法,它可以通过随机分割数据集的方式,快速发现分布稀疏且离密度较高群体较远的孤立点,能够在低维数据集中取得良好的检测效果。因此,采用孤立森林算法检测并删除飞行态势数据中的异常值。 2)坐标系转换。为了定量分析战机间的相对态势,将各型雷达获取的目标数据统一到同一坐标系中。 3)归一化处理。当态势数据范围不一致时,需要通过归一化方法进行数据处理。 (6) 3.2.1 作战空间网格划分 分群模型在数据预处理的基础之上,需要根据目标点di横纵坐标的最大最小值和单元格边长,由式(7)和式(8)确定网格的行数与列数。此后模型根据式(9)将所有坐标点分配到相应的单元格中,当坐标点处于网格边线时,将该目标点归属到其右上方的网格中。 (7) (8) (9) 3.2.2 目标空间群扩展 基于改进CBSCAN算法进行空间群扩展的方式与图7所示CBSCAN算法的执行流程大致相同,其区别在于改进CBSCAN算法有更多的排他网格扩展选择。图9所示为基于改进CBSCAN算法的目标分群模型。 图9 基于改进CBSCAN的目标分群模型Fig.9 Target grouping model based on improved CBSCAN 同一空间群中的目标往往具有相同的敌我属性和飞机类型。根据图3目标分群模型框架,通过改进CBSCAN算法进行分群后,需根据敌我属性和飞机类型的不同,对空间群进行拆分。 仿真硬件环境为:Intel(R) Core(TM) i7-7700HQ 2.8GHz处理器,16 GB内存,Win7 64位操作系统,软件平台为MATLAB 2014a。 多任务编队协同空战中的参战飞机较多,涉及大量的飞行态势数据。给出30组作战场景想定,利用其中的飞行态势数据检验改进CBSCAN算法处理空战目标分群问题的适用性。每组想定中参战飞机的数量不等,共有476个数据元组,每个元组都包括一架飞机的敌我属性、飞机类型、坐标、飞行速度和航向等态势数据。由于只针对敌方目标进行空间群分类实验,所以设定所有数据元组中的Fof值为2。 图10所示为其中一组典型空战态势,敌方共有15架飞机参与战斗,他们欲通过侦察编队、掩护编队、轰炸编队、伴随干扰编队和预警指挥编队间的协同配合攻击我方地面目标。 图10 作战想定Fig.10 Battle plan 表1数据为图10作战想定中的态势数据。其中,类型 1为无人侦察机,类型2为歼击轰炸机,类型3为电子干扰机,类型4为预警机,类型5为战斗机。 表1 作战想定飞行态势数据 为验证改进CBSCAN算法处理目标分群问题的有效性,分别利用K-means、最大期望(Expectation-Maximization, EM)算法、密度峰值、DBSCAN算法、CBSCAN算法和改进CBSCAN算法处理30组作战想定中的飞行态势数据。只分析算法处理空间群分类问题的有效性,故只对数据中的坐标位置进行聚类分析。 利用上述6种算法对图10和表1所示飞行态势数据进行10次目标分群实验,将K-means和EM算法的聚类数目设置为6,实验结果如图11、图12和图13所示。 (a) K-means分群错误结果(a) Poor grouping results of K-means (b) K-means分群正确结果(b) Good grouping results of K-means (c) EM分群错误结果(c) Poor grouping results of EM (d) EM分群正确结果(d) Good grouping results of EM图11 K-means、EM目标分群结果Fig.11 K-means, EM target grouping results (a) 决策图(a) Decision diagram (b) 聚类中心选择(b) Cluster center selection (c) 分群结果(c) Grouping results图12 密度峰值算法分群结果Fig.12 Density peak algorithm target grouping results (a) 目标分群结果(a) Target grouping results (b) 平均运行时间(b) Average running time图13 DBSCAN及其改进算法分群结果Fig.13 DBSCAN and its improved algorithm target grouping results 图11为K-means算法和EM算法对作战想定中15个空战目标进行多次聚类后产生的部分不同结果。通过仿真实验可以看出,在流形分布数据中,选择不同的初始聚类中心会使K-means和EM产生不同聚类结果,这就使上述两种算法的稳定性较差,且正确率较低。图12为密度峰值算法的分群结果。在10次聚类中,该算法均产生了相同的错误分群结果,说明其稳定性较好,但正确率不高。图11和图12说明传统聚类方法难以对流形分布的战机编队进行正确分群。图13为DBSCAN、CBSCAN及改进CBSCAN算法的仿真结果。图13(a)表明,DBSCAN及其改进算法对图10所示作战想定均得到了稳定且正确的分群效果,图13(b)说明改进CBSCAN算法可以在保证正确率的同时,提高算法的执行效率。 为进一步说明改进算法的准确度和实时性,对30组作战想定进行10次分群实验,得到表2所示的仿真结果。 由表2结果可知:K-means算法执行效率较高,但其正确率较低且稳定性较差;EM算法执行效率低、正确率差且稳定性不好;此外,利用这两种算法进行目标分群时,均需手动输入类别数目,但目标分群属于类数未知问题,故K-means和EM算法不适合处理空战目标分群问题。密度峰值算法的时间复杂度较高,且由于该算法利用欧式距离作为相似性度量,无法准确对流形分布的空战目标进行正确分类,导致其准确度与DBSCAN及其改进算法相比较差。DBSCAN、CBSCAN和改进CBSCAN三种算法的准确度较高,但改进CBSCAN算法的分群实时性在CBSCAN算法基础上提高了约30%,达到了算法改进的目的。综上,改进CBSCAN算法与其他算法相比,稳定性较好、准确度和实时性较高,能够较好地处理编队协同空战中的目标分群问题。 表2 分群算法结果对比 1)K-means、EM和密度峰值算法难以对流形分布目标进行准确稳定的分群操作。 2) DBSCAN、CBSCAN和改进CBSCAN算法都可以对流形分布目标进行准确分群。 3) 通过改进CBSCAN算法的簇类扩展方式,可以在保证原始算法准确度的同时,将分群实时性提高约30%。 4)改进后的CBSCAN算法能够在多编队协同空战背景下,对空战目标进行准确且更加快速的分群编组。

2.2 CBSCAN算法
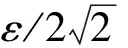

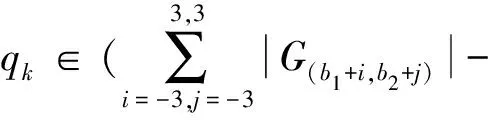
2.3 改进的CBSCAN算法
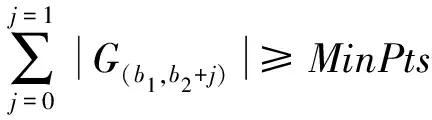
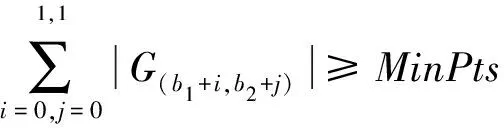

3 基于改进CBSCAN的目标分群模型
3.1 飞行态势数据处理
3.2 模型的算法处理
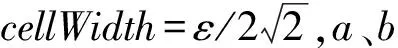
3.3 空间群拆分
4 仿真实验
4.1 作战想定分析

4.2 仿真结果




5 结论
猜你喜欢
小哥白尼(军事科学)(2022年1期)2022-04-26微型电脑应用(2020年6期)2020-06-29数学物理学报(2020年2期)2020-06-02数学年刊A辑(中文版)(2019年3期)2019-10-08数学物理学报(2019年1期)2019-03-21现代畜牧科技(2018年7期)2018-10-21军营文化天地(2017年6期)2017-06-28电测与仪表(2016年14期)2016-04-11百科探秘·航空航天(2015年10期)2015-11-07振动工程学报(2015年2期)2015-03-01
