
面向特定科研任务的著者姓名消歧方法
2021-08-23 05:24吴柯烨孙建军权昭瑄
情报学报 2021年7期
吴柯烨,闵 超,孙建军,权昭瑄
(1.南京大学信息管理学院,南京 210023;2.南京大学人文社会科学大数据研究院,南京 210023)
1 引 言
近年来,科研人员数量不断增加,论文数量呈现指数级增长,随之而来的论文著者重名的问题频频出现。尤其是某些特定的研究任务,虽然不以著者姓名消歧为主要研究工作,但是著者姓名消歧是其基础性的重要环节。譬如,科学家流动、技术人才迁移、学术评价等人文社科类研究课题[1-4]。这类研究大多数从论文数据入手,依赖于准确的科学家-出版物对应关系,然而,姓名歧义问题始终在两个方面掣肘着相关研究的开展:第一,由于特定研究的最终目的不是为了解决姓名歧义问题,因此,在研究数据中,关于人本身的信息可能十分稀疏,甚至在论文数据中存在缺失著者机构等关键消歧依据的现象;第二,特定研究中的姓名消歧相较于一般消歧技术难度不高,但效果要求较高。如果歧义问题不能较好地解决,那么对于这些研究任务存在毁灭性地打击。譬如,姓名歧义可能导致科学家流动识别不准确,学术评价不客观等问题。因此,本文提出了一个简单易行且效果良好的面向特定任务、特定数据集的姓名消歧方法,为人才评价、人才流动等研究与实践任务提供相对可靠的方法支持。
姓名消歧作为实体消歧的子任务之一,其复杂性较为突出。普遍意义上的姓名歧义包含两方面:一是同名异人,即不同的人拥有相同的姓名;二是同人异名,即同一个人的姓名有不同的书写形式或是存在别名。然而,同人异名问题往往不需要借助其他信息。消歧直接从姓名本身入手,如寻找别名中的最长公共子序列的方式,来判定不同的姓名是否指代同一个人[5-6]。但是,同名异人问题则涉及相同研究领域、相同姓名,甚至是相同供职机构中不同的人,这就需要根据现有信息深度挖掘出更细粒的、更多源的、更权威的信息作为消歧依据,有时还需要进行语义挖掘才能达到精准消歧[7-8]。因此,如何充分利用有限的本地数据进行关系发现,并结合外源数据进行消歧依据补充就成了姓名消歧的研究重点。
本文充分结合本地关联数据和外部权威数据,提出二阶段著者姓名消歧框架,为学者层面的研究奠定了坚实的数据基础。其中,一阶段:本地关系发现,组织论文间关系网络;二阶段:外部数据爬取,补充权威消歧依据。两阶段相辅相成,互相补充,达到全面客观消歧。为了体现该框架的实际效用,本文聚焦人工智能领域顶尖学者,抽取微软学术知识图谱(Microsoft Academic Graph,MAG)中人工智能领域的论文数据进行验证。经过抽样统计证明,一阶段解决数据中大部分同名异人问题。二阶段在一阶段的基础上,不仅在准确率和F1 score等聚类评价指标上有进一步提升,而且解决了部分同人异名的问题。此外,为了证明该方法的普适性,本文还选取了Aminer姓名消歧数据集进行有效性验证,同样在准确率和F1 score上取得了良好的效果。
2 文献综述
姓名消歧本质上是关系发现的过程,将关联性强的文章聚集为一类。由此出发,大多数研究均将姓名消歧具体为出版物聚类问题[9-17]。其中,同名异人的消歧流程大致分为三个步骤:特征抽取、相似度计算和聚类[18];而同人异名消歧则在特征抽取之前,增加了一步模块映射操作,即将可能是同一个人的别名下的出版物均映射到一个模块上[12,19-20],再进行消歧。针对每一个步骤,不同的研究有其自己的创新点。从本文的二阶段划分角度出发,本章节分别从本地关系发现和外部数据关联两个层面对现有研究进行归纳总结。
2.1 本地关系发现
从姓名消歧一般流程来看,每个阶段都在尽可能揭示出版物之间关系。
在特征抽取方面,大多数研究选取了关联性较强的特征。譬如,尚玉玲等[21]选取了合作者和隶属机构信息进行同名排歧;Saha等[13]和Zhang等[22]为保护作者隐私,选取了论文题目和合作者等特征进行消歧任务。有些研究则加入对消歧有显著效果的其他特征作为消歧项。例如,Louppe等[19]利用种族特征作为消歧依据;周杰等[23]通过一些关键的关联证据为增量数据生成消歧候选集。此外,有些研究为更好地体现出版物之间的语义关联,采用诸如摘要等能体现文章语义的特征作为消歧项。譬如,翟晓瑞等[24]用稀疏矩阵组织摘要文本特征;Han等[7]和Jia等[8]根据上下文的语义信息来对命名实体进行消歧。因此,在进行消歧任务时,能够揭示出版物之间关联性的消歧特征受大多数研究的青睐。
在相似度计算方面,最直接的是将特征映射到向量空间上,进行向量间距离计算。但是仅依据文章本身的特征可能无法做到精准的关系发现。因此,图模型和网络表示[25]等框架常常被应用于组织关联出版物特征上。被称为“GHOST(GrapHical framewOrk for name diSambiguaTion)”的方 法[26],利用合作者信息构建无向图,并利用关联传播算法进行聚类。此外,图模型还可以灵活地加入概率,Tang等[27]提出将隐马尔可夫模型应用在组织各个出版物的特征上。也有学者利用多图嵌入的方式学习出版物的嵌入向量。譬如,Zhang等[22]基于表征构建paper-paper、author-paper、author-author三个子图,再用网络嵌入的方式学习,得到每个出版物包含这三层关联信息的语义向量。
最后的聚类效果是建立在前两个阶段基础之上。由传统的特征向量出发,大多数学者采用无监督学习中的聚类算法进行聚类操作[9-11,16,28]。譬如,邓可君等[28]发现,相较于其他机器学习算法,K近邻和Softmax分类器更适应于其数据集。又如,为解决无法确定聚类数目这一问题,章顺瑞等[9]和阳怡林等[10]基于自适应阈值的凝聚层次聚类算法进行消歧。另外,为进一步揭示关联信息,有些学者在图模型的基础上进行了聚类操作。譬如,On等[16]在聚类阶段提出多级图划分和合并算法,通过不断合并和拆分子图的方式,得到给定聚类数目k下的最优解;Shin等[5]利用合著者和标题信息,提出GFAD(Graph Framework for Author Disambiguation)图模型框架,对已知图进行结点拆分和循环探测,将每个非重叠子环对应到每一个人。
总而言之,消歧研究的每个阶段都在尽可能地挖掘出版物之间的关系,具体体现为利用图模型和网络表示组织出版物特征,使出自同一位学者的不同论文具有较高的相似性。虽然这种方式能够有效直观地体现了出版物之间的关联信息,但是复杂的图模型对于自然语言处理技术以及计算机算力提出较高的要求。如果数据量大,那么对应的出版物关联图也会随之增大,图模型推理计算的复杂度同样会呈现指数级的增长。然而,综合过往研究发现,姓名消歧中图模型和网络构建也都依赖以下假设:①每个学者都拥有较为稳定的合作学术圈;②每个学者的研究领域相对稳定。本文基于这两条原则,简化了图模型复杂的计算过程,做到高效率的组织文献关系。
2.2 外部数据关联
由于现有的姓名消歧研究大多都面向机构知识库,为学术资源库提供更高质量的数据[10,29-31]。这就带来本地数据覆盖面有限的问题,因此,需要加入外部来源的数据进行补充。譬如,Han等[7]为解决数据缺失的问题,利用多源网络知识信息来挖掘出版物之间的语义层面的关联信息。Zhu等[32]提出基于的姓名消歧框架,不仅包含了本地数据中的隐含信息,也包含了网页类型信息。另外,有学者采取其他方式补充元数据缺失,譬如,孙笑明等[33]搜集专家意见为消歧提供依据;柯昊等[34]利用BP(Back Propagation)神经网络为元数据中的字段进行贡献度打分,从而选取最有价值的字段进行消歧。
但是,外部数据源对于姓名消歧任务在带来更多依据的同时也带来一些问题:一是外部数据源,大多是网页数据或是非结构化数据,处理起来很难做到精准;二是网络信息的可利用率较低,与需要消歧的姓名相关的信息可能很少,即使有,可能也是不完整的或是无法考证真实性的。
为了解决图模型计算复杂和外部数据利用率不高的问题,本文将面向人文社科领域的特定研究任务,提出一个简便易行的学术论文作者姓名消歧方法。第一阶段,本文将结合图模型背后的原则,对于本地论文数据的表征关联特征项选择抽取,并进行预处理,为姓名实体所对应的论文集建立同作者合并机制;第二阶段,为解决本地数据覆盖率有限,且外部数据利用率不高的问题,本文将利用专注于区分不同学者的平台——ORCID(Open Re‐searcher and Contributor Identifier),更权威、更客观地进行逐个姓名的消歧。
3 姓名消歧框架与流程
3.1 姓名消歧整体框架
3.1.1 消歧特征项选择
与过往研究一样,在面向科研任务的姓名消歧任务中,需要筛选合适的消歧依据。这些依据应该尽可能凸显学术论文的本质属性,又能与相关论文产生较强的联系。
根据过往研究中对于消歧特征项的选择[21-22,31],本文将所有与论文相关的字段分为两类。第一类是有助于直接揭示出版物之间关系的强关联特征项,如合著者、隶属机构、发表年份等信息[21]。这些信息不需要深入挖掘其内涵,只需要通过表征就可以组织关系。例如,同名的两位学者如果合作圈有较多重合,那么这两位学者大概率是同一个人,无需深究其每个合作者更细粒度的信息。因此,这些字段在本地数据中就可以加以利用,达到消歧的效果,适用于本研究的一阶段关系发现。
第二类则是间接揭示出版物之间关系的弱关联特征项。例如,关键词、题目、摘要等。这些特征项往往隐藏着论文所属的研究领域,而每位科研工作者一般又会专注于固定的研究领域。因此,如果能够充分挖掘弱关联特征项的内涵,揭示论文所属的研究领域,那么将会给消歧任务带来巨大的便利。在本文提出的消歧框架第二阶段中,在原本的消歧依据上,增加弱关联特征项,通过与外源数据关联的方式进行深入挖掘。
3.1.2 二阶段消歧框架
根据上述两类消歧特征项,本文提出了二阶段消歧框架①代码网址:https://github.com/wukeye/Two-stage-author-name-disambiguation,分别对应本地关系发现与外源权威数据关联,操作简便,且提高了姓名消歧的准确率。二阶段消歧的整体思路和框架如图1所示。
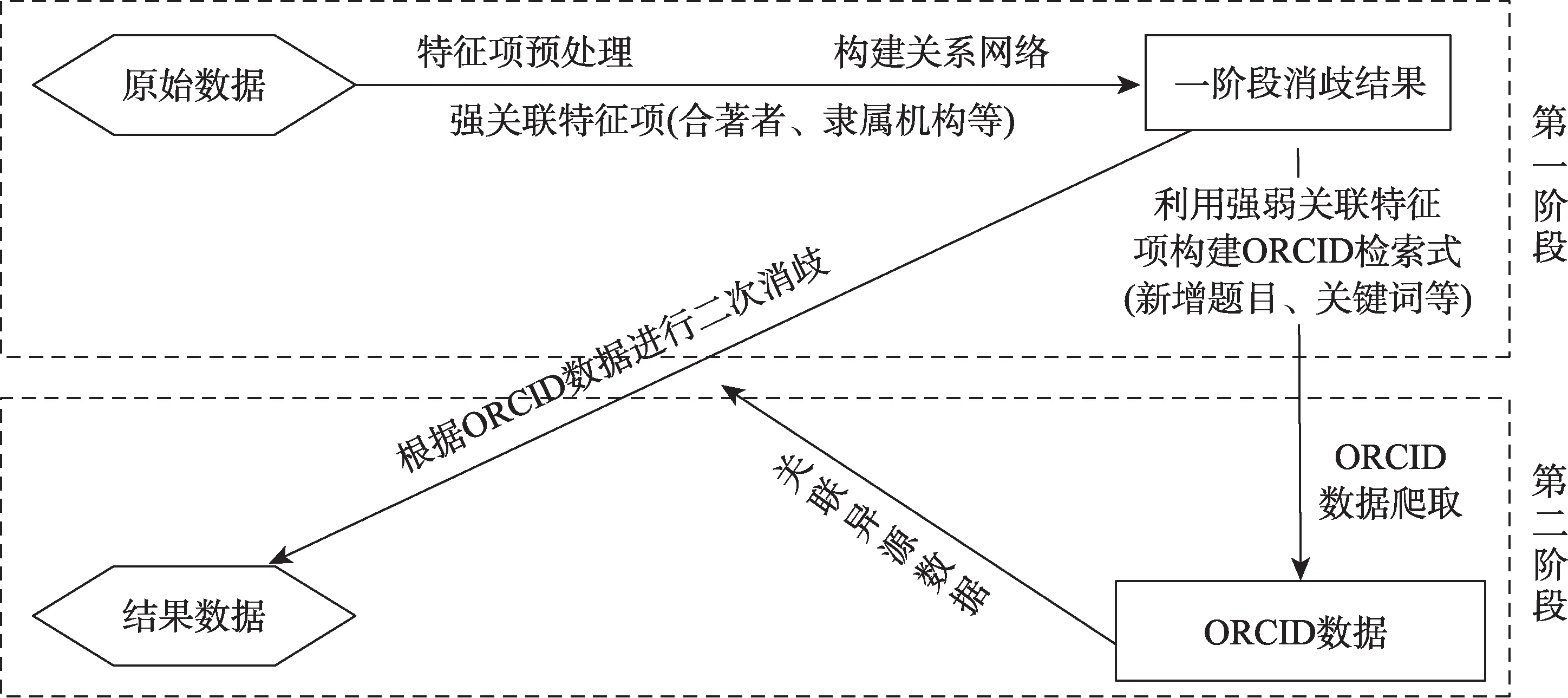
图1 二阶段姓名消歧框架
第一阶段首先为所有消歧特征项做数据清洗工作,其次基于高质量的强关联特征项组织论文间的关系网络。在此过程中,为弥补原数据中某些强关联项的缺失,通过原始数据中的其他信息进行深入挖掘补充。例如,本文通过经纬度信息定位著者所在地,弥补著者所属机构的缺失。
接下来,利用第一阶段的消歧结果以及经过处理的消歧特征项,进行第二阶段消歧,将无法在本地发现的相关文档,通过与外部数据连接的方式聚为一类。首先制定ORCID半模糊检索策略,对消歧特征项进行优先级抽取,最大限度保证检索精度。其次,利用半模糊检索式在ORCID官网提供的API(Application Programming Interface)接口实施数据爬取。最后,将外源数据与本地数据关联,把具有相同ORCID号的作者合并为同一个人。至此,得到了同姓名下属于不同学者的论文集。接下来的第3.2节和第3.3节将分别介绍两个阶段的详细步骤与算法。
3.2 第一阶段消歧
3.2.1 消歧特征项预处理
在大多数学术领域的姓名消歧任务中[14,19,22-23,25,28,30],原始数据都以论文为单位,然而,对姓名歧义的研究,则需要将数据重组成以姓名为单位的形式,便于发现同一姓名下所著的两篇文章是否属于同一个人。在某些原始数据中难免存在一些错误,为保证数据一致性,对消歧所需的特征项进行数据清洗和正则化工作。本文就以姓名A.Ad‐am为例,展示部分包含这一著者姓名的论文数据重组与特征项预处理过程,如图2所示。
如图2所示,原始数据中的一条论文数据被分解为多条数据②这里每一篇论文应该分为多条数据,每条数据表示一位作者的有关信息,为方便叙述,这里只展示了拆分后关于A.Adam的部分数据。,这里展示了论文著者姓名包含A.Adam的三篇论文拆分情况。其中,Aff Nor是对于原数据中Aff的正则化结果,Key_in_title则是抽取论文题目中关键词组织而成,其中可能包含名词和形容词,在第二阶段还将进一步处理利用。最终,得到关于A.Adam所有的论文集publication_set,下一步需要将这些论文聚为几类,分别对应几位同名的不同学者。

图2 某篇论文的数据重组与特征项预处理
3.2.2 构建关系网络
经过初步的数据重组与预处理之后,将过往研究中图模型的假设经过改编应用到本研究场景中,将同名作者的论文关系组织起来,总结为以下两个规则。
(1)由于学术圈每个人有自己的合作网络或是学术圈子,合作者信息可以用来协助判断同名的两个人是否是同一个学者。
(2)从论文数据来看,同一位作者几乎不可能短时间内在不同的机构下以第一作者发表文章。作者论文的所属机构信息和发表年份信息,也可以协助判断两个同名的人是否为同一作者。
由于学者在职业生涯中可能会辗转多个工作单位,在第二条规则中,本文特意添加了年份信息进行联合筛选。也正是充分考虑到学者流动的情况,本文认为第一条规则较第二条而言更加客观。因此,在算法实现时优先考虑第一条原则,当第一条原则无法判断时,再采取第二条原则。算法伪代码如下。
算法1Constrcut Relationship Network
输入:数据重组与特征项预处理后的结果。其中每一行代表当前需要消歧姓名下的每一篇论文信息。
输出:出自同一位学者的论文索引号集合。
Step1.对每个姓名下的publication_set中每一篇论文进行遍历for p in publication_set:寻找可能与当前论文p_index为同一人所著的论文行号集合p_set。Step1.1.遍历除p以外的所有论文,逐一对照合著者Coauthor字段,如果有重复就将其行号加入集合p_set中。如果没有重复就跳入Step1.2,否则进入下一跳。Step1.2.比较当前论文与没有合著者重复论文的年份Year字段和正则化机构AffNor字段,若正则化机构信息相同且年份在前后两年内,则加入集合p_set。
Step2.对publication_set中每一篇论文的相关论文集p_set进行重复元素探寻,最终由局部关系网络组织成全局关系网络。
算法中,Step1实现了根据强关联特征项构建出需要消歧姓名下所有论文的关系网络,具体操作是为每一篇论文找到一个相关论文集合p_set。以A.Adam的论文集为例,由于p_index为9766与32931两篇论文中合著者有重复,因此,p_index为9766的相关文档集就包含索引号32931以及其自身索引号9766。Step2则是将论文级别上的相关文档集组织成姓名级别上的关系网络,最终9766与32931两篇论文被认为是出自同一个人,而p_index为56272的作者暂时被认为是另一位学者,需要外部数据进行第二阶段的消歧。整体来看,一阶段消歧在原数据上进行了预处理、构建关系网络等操作,实现了将有相同学术合作圈的学者或是隶属于同一机构较长时间的学者合并为同一作者。
3.3 第二阶段消歧
一阶段消歧在本地数据的基础上充分挖掘了关联信息,但是只依赖本地数据存在一些弊端,具体体现为以下三点:①本地数据来源学术资源数据库,其中难免存在数据缺失问题。如果缺失情况严重,那么就无法利用本地数据进行关系发现。②同人异名问题没有得到解决。同一学者在发表不同论文时的署名会有不同程度的缩写,仅仅依靠本地数据无法准确合并同人异名的学者。③除本地数据中合著者、机构、年份等强关联字段,本地数据中还有许多揭示学者研究方向的弱关联项没有得到充分利用,如摘要和关键词信息。需要进一步加工和处理才能挖掘出不同论文之间的关系。
针对上述问题,第二阶段的消歧任务主要围绕外源数据展开。在补充本地缺失数据的同时,利用关键词等弱关联项揭示学者的研究领域,将同一研究领域的学者指向同一个外源标识符——ORCID。因此,为了更好地利用外援权威数据为本论文中的姓名消歧服务,本文制定了ORCID数据的检索策略。根据爬取到的ORCID数据,将具有相同OR‐CID号的作者合并为同一个作者。
3.3.1 ORCID半模糊检索
ORCID是国际上公认的研究人员唯一数字标识符,并建立了学者及其研究贡献之间的直接联系,解决了部分学者的姓名歧义问题。许多学者在OR‐CID网站上公开其个人信息,对于姓名消歧来说,这些是非常宝贵的消歧依据。因此,本文利用开放研究者与贡献者身份官网提供的API,根据已知有关作者的信息,爬取相应作者的ORCID号。
为解决数据缺失以及利用率不高等问题,本文通过半模糊检索的方式得到作者的ORCID号。之所以称之为“半模糊检索”,是因为在检索时加入了Keywords字段进行模糊检索。但是与模糊检索不同的是,半模糊检索首先在原始数据上抽取强关联特征项,做到精确字段限定,如明确作者的Familyname、Given-names以及Affiliations等。如果精确字段有缺省的话,再抽取其他字段信息作为Keywords进行限定条件下的全局检索,保证半模糊检索的精度。图3为构建半模糊检索式的流程。
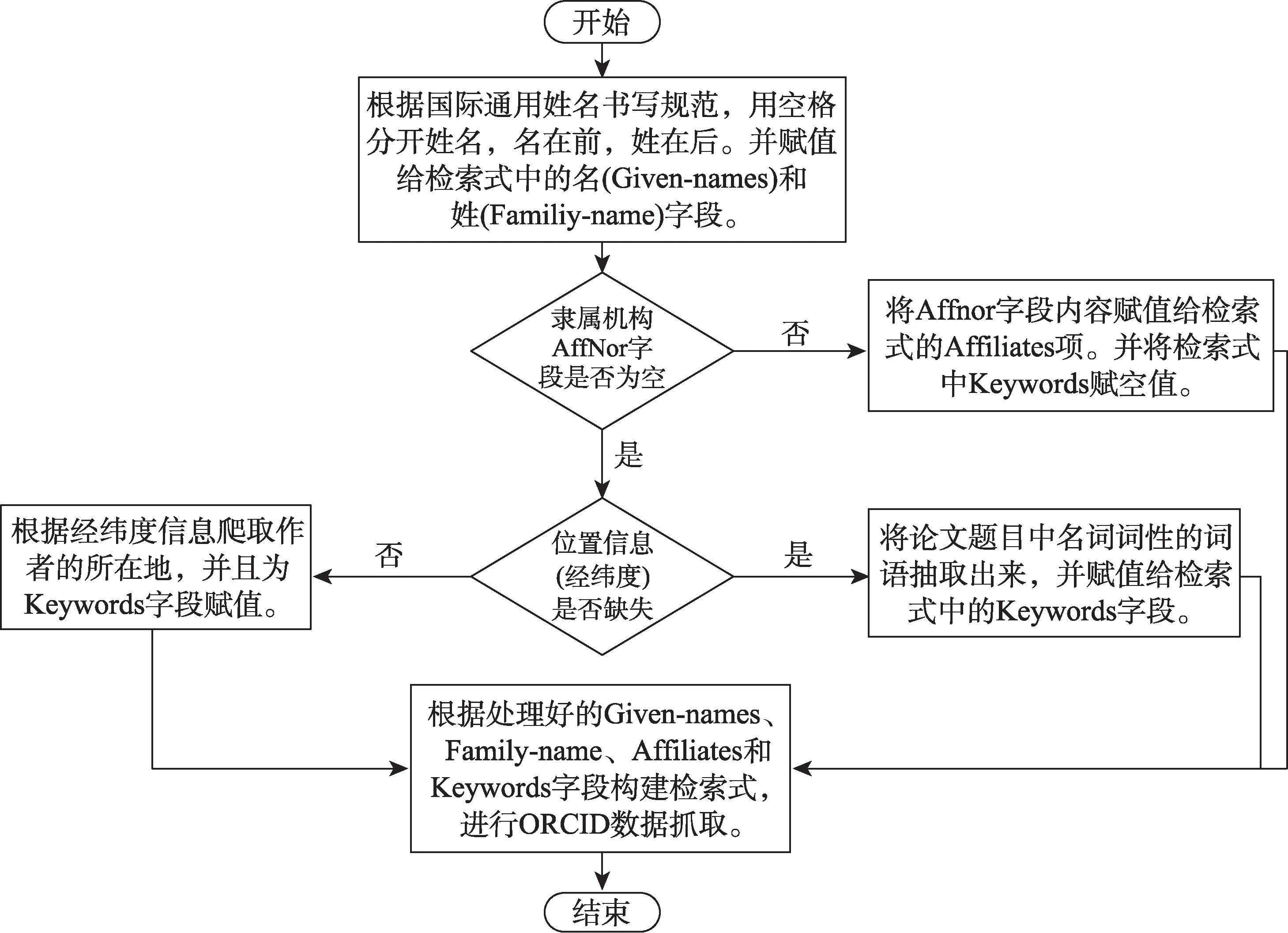
图3 半模糊检索式构建
在爬取过程中,明确了不可空缺的为姓名字段。除此之外,利用位置信息进行了原数据的扩充,并且依据丰富后的原数据和一次消歧结果充分挖掘论文作者的所在地和揭示论文研究领域的关键词。依旧以A.Adam为例,在该阶段,A.Adam会与ORCID进行两次关联,一是检索在第一阶段已经聚为一类的学者的相关信息,该学者著有p_in‐dex为9766与32931两篇论文,并且隶属于Israel In‐stitute of Technology,因此Affiliates字段限定为Isra‐el Institute of Technology。第二次检索则是寻找有关p_index为56272的著者的相关信息,通过地理位置信息找到其所在地也为Israel,因此,限定Key‐words为Israel,而机构信息为空值。最终,比较两次检索所获得的ORCID号。
3.3.2 二次消歧
由于在论文数据中,同一姓名下论文的所属机构信息或者关键词信息有所不同,但可能均是出自同一作者在不同时期的工作、学习场所,或是由于每篇发表论文中所填写信息并不完全一致。因此,本文发现在同一姓名下,原本被认为是不同学者的数据被赋予了相同的ORCID号。
二次消歧的主要工作就是将具有相同ORCID号的作者信息做合并处理,将同一作者的机构信息和发表论文信息做时间线的梳理工作,更有利于后续分析该作者与其他同名作者的关系,评估消歧质量真实性。
4 实证研究与结果分析
4.1 研究任务与数据来源
著者姓名消歧是许多科学研究的基础性任务,不同的科学研究对于姓名消歧的要求不相同,因此,结合具体的研究任务才能体现姓名消歧的价值。假定有一个研究任务,主要研究某领域高端科学家的流动模式与影响因素,如刘玮辰等[4]的研究。为了完成该研究任务,需要从学术出版物中采集该领域论文,从中析出科学家的任职与流动信息。其中,一个关键的前提工作就是对论文中的作者进行姓名消歧。对于这个任务,可以采用本文提出的二阶段姓名消歧方法。为验证该方法的实际效用,本文以人工智能领域高端人才流动为研究任务,采集微软学术知识图谱中的顶级会议与期刊论文数据集,对数据集中的所有著者进行姓名消歧,为后续流动研究提供高质量数据支持。
4.1.1 数据范围限定
由于研究任务中限定了人工智能领域“高端人才”,因此,限定数据范围在顶级期刊与顶级会议内的论文数据,为人工智能领域学者进行姓名消歧工作。根据2019年中国计算机学会推荐国际学术会议和期刊目录,具体落实到人工智能(Artificial In‐telligence,AI)领域的4本A类期刊和7个A类会议。详细信息如表1与表2所示。

表1 中国计算机学会推荐国际学术期刊(人工智能A类)

表2 中国计算机学会推荐国际学术会议(人工智能A类)
4.1.2 微软数据介绍
在数据源方面,本文选择了微软学术图谱数据。目前,微软学术知识图谱是全球最大的学术论文公开数据集,经过长期发展,数据质量,尤其是作者字段数据,得到了较大的提高。其对此类研究任务有十分明显的优势:①数据完全公开,可以免费获取;②提供API接口,方便采集;③微软公司利用先进的AI技术,如自然语言理解(Natural Language Understanding,NLU)、知识推理、强化学习等方法,进行一定程度的数据清洗工作,数据质量较高;④数据字段丰富,如包含作者机构经纬度信息。
根据上述限定的范围,本文在微软学术知识图谱中检索到了91557条论文数据,其中每条数据包含作者ID、作者姓名、作者隶属机构等20个的字段。在所有字段中,与姓名消歧任务直接相关的是AuthorId字段。首先,将所有论文中出现的作者都分配一个AuthorId,再根据其他信息对同名作者进行一定程度的合并,最终被分配相同ID号的同名作者大概率是同一个人。这一过程类似于层次凝聚算法[9]的自下而上的聚类过程。然而,由于该数据普遍存在过拟合现象,因此,姓名消歧框架是在该数据基础上进行二阶段消歧,提高了姓名消歧的准确率。
4.2 效果评估
根据微软知识图谱数据,对学术论文的著者进行初步的ID分配工作,总体来看,作者姓名有91683个,分配了103022个AuthorId,即有11339个学者被初步认为是同名异人的情况。为探究原数据的ID分配情况和二阶段消歧框架的效果,针对部分有歧义的姓名数据进行人工标注。本文的标注策略是根据上述第4.1节所介绍的MAG数据中可利用的字段信息,进行开放网络信息资源的考证,主要在IEEE、Web of Science和Springer等数字学术资源平台上对论文著者进行深度挖掘。
经过评估发现,初步被认为是同名异人的11339个学者中,少部分存在同名异人的情况,大部分是同名同人被误分配不同ID的情况。这表明该分配工作没有经过太多的消歧工作,存在过拟合的情况,即实际上为同一人所著的两篇文章,却被认为是不同的两个人。因此,本文的消歧主要针对这11339个著者所对应的7254个姓名中误分配ID情况,进行同名同人著者的ID“聚类”操作。
由于第二阶段消歧是建立在ORCID数据的基础上,因此,在对消歧框架效果评估之前,对ORCID数据进行了简单评估。在91683个姓名中,从OR‐CID官网抽取到了9821条数据。在数据的召回率上只有12%,这是因为并非所有学者都注册了ORCID号,导致检索不到关于作者的相关信息。另外,有些作者的ORCID只展示了该作者所发表过的论文,并没有添加相关的机构等背景信息。同时,也验证了检索结果的准确性,通过抽样比较爬取到的OR‐CID数据与原始数据,发现爬取到的著者与原数据中的著者确为同一个人。这证明了本文的检索策略是精准的。
在准确的外部数据的支持下,对经过消歧后的ID抽样评估发现,本文所提出的框架在三个方面对姓名歧义问题起到积极的作用,分别是聚类数目、聚类准确率以及同人异名问题解决。
4.2.1 聚类数目效果评估
在所有数据中,本文抽取了30个发文量较多的姓名评估。在表3中,列举了10个姓名下现实社会中对应的人数,以及原始数据、一阶段、二阶段分别对应的类别数,可发现每个姓名对应的真实人数都比原始数据中分配的ID个数(聚类的类别数目)少,这种过拟合现象可能是由于限定了数据集的范围,在小范围下的姓名歧义并不普遍。经过一二阶段消歧之后,聚类数目减少,并且与真实人数更加接近。

表3 聚类数目分析
4.2.2 聚类准确率分析
经过一阶段消歧之后,本文对7254个姓名改动了6779条数据的AuthorId。二阶段在ORCID数据的支持下,消除了203个AuthorId,并将其合并到已知的作者类别中。同样地,在所有姓名中随机抽取15个姓名进行准确率(precision,P)、召回率(re‐call,R)、F1 score计算。这一过程借鉴了Zhang等[22]的验证方法。效果如表4所示。
由表4可知,消歧框架在原始数据的基础上,在经历了第一、二阶段消歧后,各项聚类指标大致呈现递增的趋势。尤其是第二阶段,在经过字段补充,并与外部数据进行关联后,消歧结果的F1 score达到最高点。这表明了本文的消歧框架在MAG数据集上取得了显著的效果。

表4 聚类准确率分析
4.2.3 同人异名问题解决
在评估过程中,本文发现同名异人问题也在一定程度上被解决了。在不同论文中,同一位学者的姓名写法可能不尽相同,会出现诸如简写Middle name甚至省略的情况,故在MAG数据中存在同一人姓名的不同写法被赋予不同AuthorId的现象。然而,恰好ORCID检索策略是根据著者的Familyname和Given-names,再结合关联特征项进行爬取,可发现不同写法的姓名其实指代的是同一名作者。譬如,在MAG数据中,署名为Jin H.Kim和Jin Hyung Kim分别发表了一些论文,且两者在中某些论文中标注的隶属机构都为KAIST(Korea Ad‐vanced Institute of Science and Technology,韩国科学技术院)。经过ORCID的检索发现,两者的ORCID相同,经过验证发现两篇论文也的确为同一人所著。表5列举了同一作者、不同姓名写法经过本文的消歧方法处理之后合并的几个案例。

表5 同人异名合并
4.2.4 Aminer数据验证
除了在固定的研究任务中,本文还验证了该消歧框架在Aminer数据集上的效果,以验证该框架的普适性。Aminer是科技情报分析与挖掘平台,其姓名消歧数据集①Aminer姓名消歧数据集:https://www.aminer.cn/disambiguation提供了110个经过实际标注的学者姓名以及其出版物集合。这些出版物可能来自不同学科的同名学者,根据本文的消歧原则,利用强弱关联项为每篇论文找到相应的著者,最终取得了良好的结果,部分结果如表6所示。

表6 Aminer消歧结果
由表6可知,一阶段利用强关联项取得了较高的准确率,但是召回率普遍较低,拉低了F1的表现。其可能的原因是学术圈的同名著者发文量存在分布极其不均匀的情况,譬如,几位同名的作者只有一篇发表的论文,而有个别学者拥有上百篇论文。因此,在第二阶段,本文通过强弱关联项互相补充的方式与ORCID数据进行关联,最终在牺牲一些准确率的情况下,提高了召回率,在整体F1 score的表现上也有所提升。
5 结语
经过多轮的相互补充,二阶段姓名消歧策略采取内外部数据相结合的方式,进行了本地关系发现、外部数据关联等任务,为学者层面的研究任务提供姓名消歧的简易方法。该消歧框架具有以下优势:首先,本文的消歧算法不需要深入挖掘过多的作者信息,在简化了复杂的图模型基础上,只需要利用公开的作者信息和论文间的关联信息就可以做到相对准确消歧;其次,本文在挖掘消歧特征项方面,将外部作者信息源链接到本地数据中,充分补充本地数据缺失值,扩展消歧依据;最后,本文为相关科研人员集成了简便易行的二阶段消歧框架和代码,为人才流动、人才评价等研究提供高质量的方法支持。
未来,该框架对于科研圈的其他研究任务同样可以发挥实际效用。譬如,学术推荐、科研能力评估和学者社会网络构建等研究对于科学家姓名的准确性要求较高。本文提出的一阶段消歧可以适应于任何形式数据做到关系发现,二阶段则提供了借助异源数据丰富消歧依据的思路。
由于采用了简易化的原则,本方法在特征抽取以及数据的语义信息抽取方面还有提升空间。在未来研究中,对于更顽固的姓名歧义问题,可以尝试使用语义信息与关联语义信息相结合的方式,更准确地表达数据特征。
猜你喜欢
管子学刊(2022年2期)2022-05-10
中北大学学报(自然科学版)(2022年2期)2022-05-05
管子学刊(2022年1期)2022-02-17
新世纪智能(数学备考)(2021年9期)2021-11-24
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
影视与戏剧评论(2016年0期)2016-11-23
漫画月刊·哈版(2015年3期)2015-05-28
小天使·一年级语数英综合(2015年2期)2015-01-14
