
基于深度学习的临床心电图分类算法
2021-08-20 09:17:08刘守华王小松
计算机与现代化 2021年8期
刘守华,王小松,刘 昱
(1.中国科学院大学,北京 100049; 2.中国科学院微电子研究所,北京 100029;3.新一代通信射频芯片技术北京市重点实验室,北京 100029)
0 引 言
心电图(Electrocardiogram, ECG)是记录人体心脏活动的可视时间序列,已经在临床上广泛用于心血管类疾病的诊断[1-2]。由于ECG容易受到各种干扰信号的影响,临床医生往往要忽略受严重干扰的心电波形再进行判断。这种基于人工分析的心电图容易导致诊断结果误判。而心电图的自动分类能高效地为临床医生诊断心血管类疾病提供重要信息。在人工智能技术迅速发展的背景下,目前计算机辅助ECG分析方法[3]越来越受到大家的关注,成为了心电图领域的研究热点之一。
ECG自动分类方法主要有2种,一种是基于数理特征例如小波特征、高阶统计量、功率谱特征[4-10]等。它们配合时域特性以及传统的分析方法例如主成分分析[11]、独立成分分析等用于ECG分类识别。另一种是基于人工智能的[12-14],Rajpurkar等[15]和Hannun等[16]采用34层卷积神经网络,利用来自超过5万位病人的91,232条记录组成的大型数据集,将心电信号分为包括窦性心律在内的11种心律。Jun等[17]提出了具有11层二维卷积的CNN算法;金林鹏等[18]提出了导联卷积神经网络的概念,使用了4层一维卷积的CNN算法;Acharya等[19]利用数据增强来解决数据不平衡问题,并采用9层CNN实现ECG分类。
但无论是使用哪种分类法,现有的不少文献只是在标准数据库或其中某个子集上得出结论(整个MIT-BIH数据集也只有47个病人),算法的泛化能力很难得到保证。还有一个很显著的心搏分类结论是,病人内的正异常分类效果要远高于病人间的,而病人间的某种疾病识别率要介于病人内和病人间的正异常识别率[20]。同时,只针对单导联的分类算法将会丢失很多重要的信息,限制了算法的分类能力;其次,很多算法都是针对少数心率类型实现分类算法,且只能将ECG信号与单一心率类型匹配,或者只做正异常二分类任务。但是临床上心率类型种类众多,且每个心电图同时属于多种心率类型。所以这种分类算法虽然具有较好的实验结果,但是局限性也很大,很难在临床上推广应用。针对以上问题,本文基于多导联二维结构,采用一维卷积ResNet网络的方法,对包括窦性心律在内的共计34种心率类型实现自动识别。
1 模型描述
标准的心电信号每个样本有12个导联,其中8个导联正交,其余4个导联可从已有的8个导联导出,现有的CNN主要应用于二维图像。虽然多导联ECG与二维图像类似,但是导联间的相关性与导联内数据的相关程度相差很大。为此本文基于多导联ECG这种特殊的二维结构,使用一维卷积的方法,采用深度卷积神经网络来完成这种端对端的学习任务。网络结构采用的是34层的ResNet[21],将原始的ResNet中二维卷积改为一维卷积,以及设置第一层卷积核尺寸为15×1,步长为2,以适应2048×1的输入尺寸,另外设置全连接层输出长度为34×1,对应于34种心率类型。图1展示了模型结构。
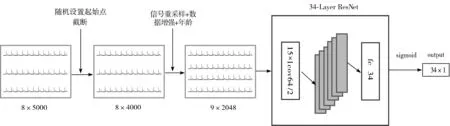
图1 模型结构图
ResNet由微软研究院的何恺明等4名华人提出,通过使用Residual Unit成功训练152层深的神经网络,错误率为3.57%,同时参数量却比VGGNet低,效果非常突出。ResNet的结构可以极快地加速超深神经网络的训练,模型的准确率也有非常大的提升。
ResNet最初的灵感出自这个问题:在不断增加神经网络的深度时,会出现一个Degradation(退化)的问题,即准确率会先上升然后达到饱和,再持续增加深度,准确率反而会下降。这并不是过拟合的问题,因为不光在测试集上误差增大,训练集本身误差也会增大。同时由于Bacth Normalization的应用,梯度消失(或者梯度爆炸)现象理应很早就被解决了。对此何恺明等人在文献[21]中也有提及:假设有一个比较浅的网络达到了饱和的准确率,若后面再加上几个全等的映射层,误差不会增加,即更深的网络也不会造成训练集上的误差增加。因此理论上越深的神经网络其效果应该越好,而这种全等映射恰好是当前网络难以实现的东西。文献[22]也提到过类似的现象,由于非线性激活函数Relu的存在,每次从输入到输出的过程都几乎是不可逆的(信息损失)。人们很难从输出反推回完整的输入。而这里使用全等映射将前一层输出直接传到下一层的思想,就是ResNet的灵感来源。假定某段神经网络的输入是x,期望输出是H(x),如果直接把输入x传到输出作为初始结果,那么此时需要学习的目标就是F(x)=H(x)-x。图2是一个ResNet的残差学习单元(Residual Unit),ResNet相当于将学习目标改变了,不再是学习一个完整的输出H(x),只是输出和输入的差别H(x)-x,即残差。
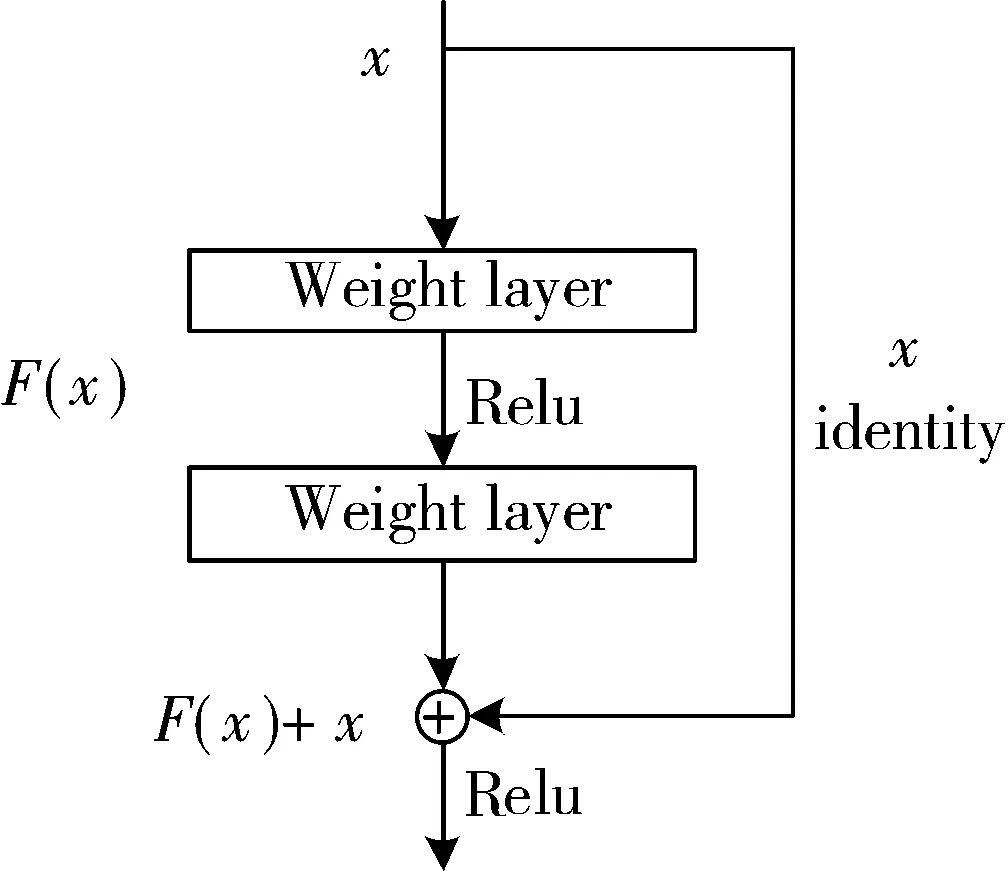
图2 残差单元
这个残差单元通过Identity mapping的引入在输入和输出之间建立一条关联通道,可以将学习单元的输入和输出进行一个element-wise的叠加,这个简单的加法不会增加网络额外的参数和计算量,但可以大大增加模型的训练速度,提高训练效果,并且当模型的层数加深时,这个简单的结构能够很好地解决退化问题。
2 数据分析与处理
2.1 数据分布
本文使用的数据为杭州师范大学移动健康管理系统教育部工程研究中心提供的20,036个样本,数据经过脱敏处理,只保留波形数据和心电异常事件名称以及部分患者年龄性别信息。每个样本采样频率为500 Hz,长度为10 s,单位电压为4.88 μV。
每条样本对应多种心率类型。超过2万条样本,包括QRS低电压、电轴右偏、起搏心律、T波改变等在内共计34种心率类型。
温柔的树袋熊,女(PS:不要问女生年龄),明清史硕士(其实最稀罕魏晋士人来着),喜欢旅游(尤其是不用自己掏荷包那种)。长卷发、天秤座、爱吃辣椒,喜欢传统君子士人:“谦谦君子,温润如玉”,可惜现代社会很难遇见,所以有了这篇文章。
数据集每种心率包含样本数分别为:3、1124、16、3479、1124、120、64、52、16、286、142、25、551、25、35、32、23、414、5264、22、9501、7、299、16、29、34、543、314、901、418、4895、126、35、60。将其中80%划分为训练集,20%划分为验证集,训练集和验证集各类别占比保持一致。
2.2 数据预处理
针对数据集的类别分布可以看到样本中各个类别心率分布极度不平衡,正常的窦性心律样本数含有9501条,最少的QRS低电压样本只有3条。对类别失衡的处理办法通常有2种:1)处理数据,也就是通过对数据重新抽样改变数据类别的分布;2)优化算法,增加小样本的权重,从而使得模型在训练的时候更加专注类别小的样本以获得较好的学习效果。
2.2.1 数据增强
Mateusz等[23]针对神经网络中类别失衡做过系统性研究,在深度学习中针对类别失衡对少量类别进行过采样,效果总是会好于原数据集,并且适当的过采样不会造成模型的严重过拟合。
在图1中,将8导联ECG看作二维图像,原始数据的维度是8×5000;随机设置起始点,截断导联数据之后,输入维度是8×4000;对导联信号重新采样,并增加年龄数值,此时网络的输入维度是9×2048。
2.2.2 更改类别权重
算法层面:对于分类任务一般使用的损失函数都是交叉熵损失,以二分类使用的二值交叉熵损失为例,公式为:

(1)
其中,y∈{±1}表示类别标签,p∈[0,1]表示模型输出的类别为1的概率,为了简便,定义:
(2)
其中Pt为t样本输出类别为1的概率。此时交叉熵就变成了:
CE(p,y)=CE(Pt)=-log(Pt)
(3)
Lin等[24]提出了Focal Loss,通过在交叉熵的基础上增加一个动态缩放因子,以解决类别分类不平衡以及困难的样本难以训练的问题。Focal Loss的缩放因子可以自动降低简单样本的损失权重,帮助模型集中于训练更加困难的样本。Focal Loss的思想与OHEM[25]的思想有点类似,OHEM是仅将损失较大的部分反向传播,直接忽略简单样本的损失,这种直接忽略肯定也会带来一定的影响,所以Focal Loss将简单样本的损失降低,而不是直接忽略,从而得到更好的结果。
Focal Loss的计算公式为:
FL(Pt)=-αt(1-Pt)γlog(pt)
(4)
其中,αt表示样本t中该类别的权重参数,(1-pt)γ表示动态缩放因子,γ是一个可调的参数,控制缩放比例。对于Pt值较大的简单样本,通过动态缩放因子可以下调该类别的权重。该损失函数的缺点是增加了2个超参数(α,γ),想要得到好的效果,需要精细调整。本文采用的αt=1/logN,其中N为原数据集类别样本数。
图3是正常的8导联窦性心律心电信号图;图4展示了不同年龄之间的电轴右偏和起搏心律的分布情况。可以看出,心律分布和年龄的关联性很大,对于起搏心律分布集中在80岁左右,40岁以下没有该心率异常事件;而不属于起搏心率的在20~40岁区间的较多。

图3 8导联ECG

图4 心率年龄分布图
3 实验及结果分析
3.1 实验
实验使用一维卷积神经网络,输入为每个样本前8个导联以及年龄构成的9通道长度为2048的一维向量。年龄的缺失值用0代替,输入不做归一化处理。模型结构如图1所示。
对输入数据使用FFT方法重新采样,采样之后导联长度为2048。数据增强使用的方法包括:随机对导联信号做上下平移、数值翻转以及加随机噪声。这样不仅增加了输入数据的丰富程度,进一步降低样本类别不平衡的影响,并且能增加模型的泛化能力。图5为对样本第一导联进行数据增强的效果,其中每一个子图为对上一个子图进行相关处理之后的效果。

图5 导联I信号的输入处理
对心电信号进行数据增强之后,结合年龄,将batch size设置为64,此时输入的size为[9×2048],将ResNet第一层卷积核尺寸设置为15×1,步长设置为2,以适应2048的导联长度。模型的输出size为[34×1],将模型的输出经过sigmoid函数,此时输出序列为Y=[y1,y2,…,yn],n为34,yn的值表示预测为第n类心律类型的概率值。当yn大于阈值a时,可以认为该样本属于第n类心律。可以通过实验结果选取合适的a值。
3.2 实验结果
3.2.1 评估方法
对于多分类常用的评价指标为F1,其结果越大越好,计算公式为:
(5)
其中,P为准确率,R为召回率,计算公式为:
(6)
(7)
P、R中涉及的心电异常事件数均是所有样本的累加。
3.2.2 结果分析
当(1-pt)γ的参数γ=1,a=0.5时,模型在验证集取得最好的效果,选用的起始学习率lr=0.02,每经过完整的一轮迭代,学习率衰减因子lr_decay=0.97。为了防止算法过拟合,dropout=0.2,最大迭代轮数为300。最终在验证集上的F1值达到了0.91的分数,准确率为93.96%,召回率为87.89%。
图6、图7为经过300轮迭代的训练集和验证集的损失曲线和F1曲线。
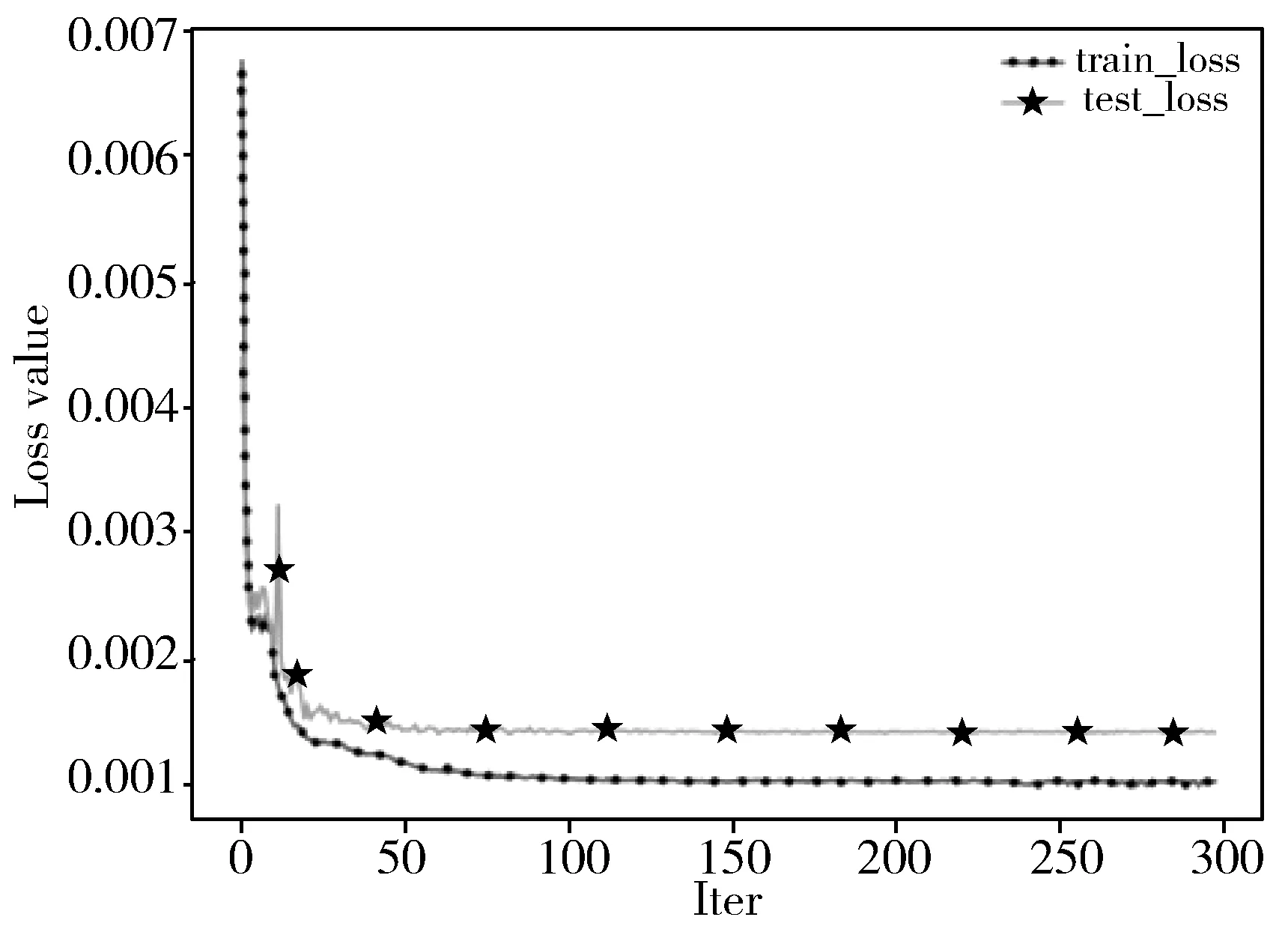
图6 loss曲线
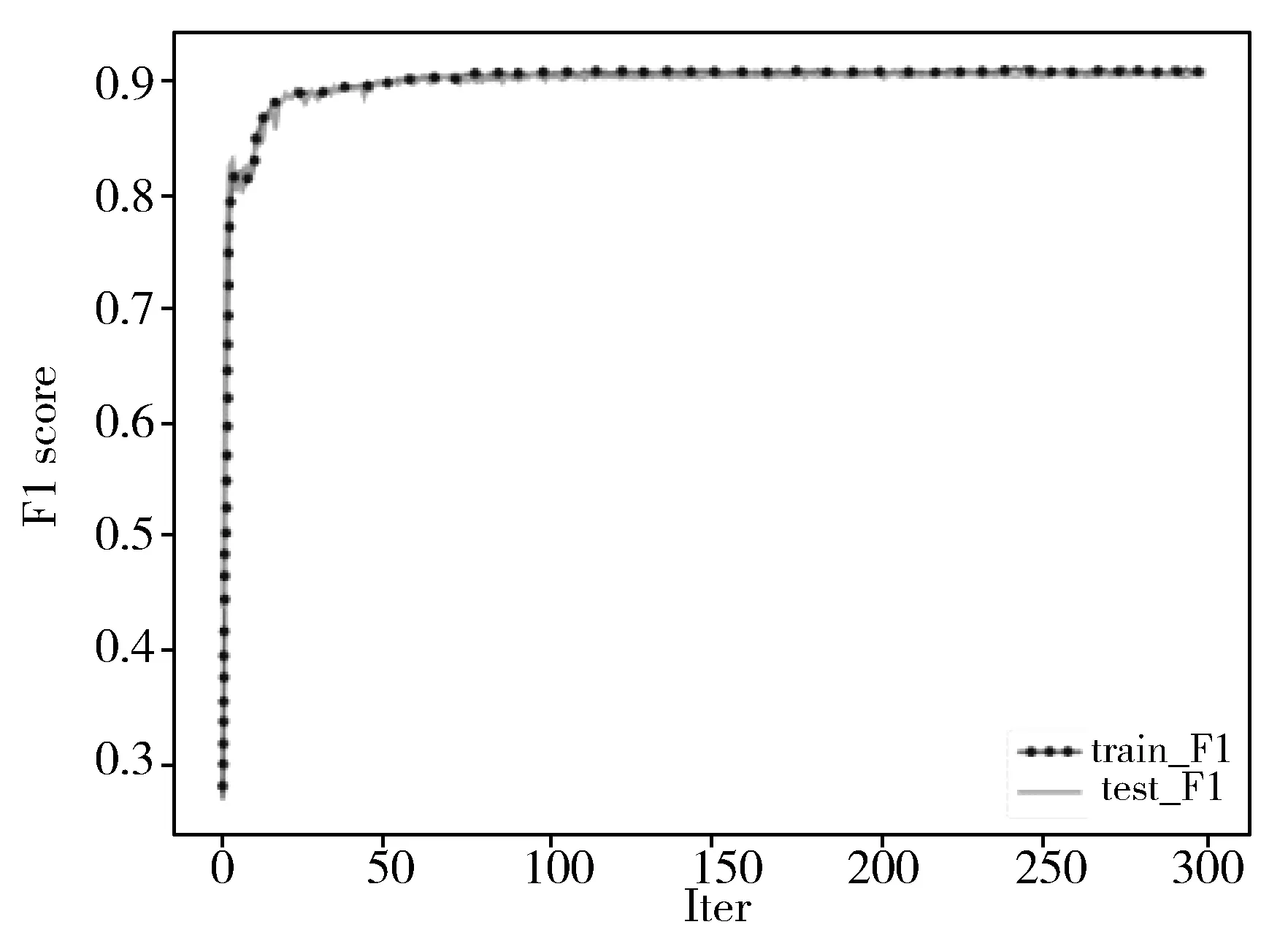
图7 F1 score曲线
由于初始学习率设置为0.2,loss曲线在训练集和验证集上在第80个iter左右已经基本收敛,后200个iter只有轻微下降。虽然在训练集上损失小于验证集,但是其F1值在训练集和验证集上基本一致。因此对训练集进行小规模过抽样并没有使得模型严重过拟合,对于34种心电异常事件预测准确率仍达到94%。
当设置输出阈值a=0.5时,对于训练集样本数超过100的类别在验证集上的预测效果如表1所示。

表1 部分心率类别预测效果
对于训练数据类别样本数大于100的心率类型,在验证集上大部分类别的预测准确率都在90%以上,并且也都取得较高的召回率,但是对于样本数较多的少数心率类型,例如窦性心律不齐以及对于样本数少的ST段改变、不完全性右束支传导阻滞心率类型的学习效果仍不理想。
3.3 与其他研究方法对比
为了验证本文提出的模型的有效性和泛化能力,将本文的模型与先前ECG心率分类工作的性能进行比较。由于这些工作具有不同的数据集和心率失常类型,因此直接比较是不合理的。故针对公共数据集MIT-BIH心电数据库使用本文的模型进行验证。
使用美国医疗仪器促进协会制定的AAMI标准对MIT-BIH数据进行类型划分,得到6类心率类型,训练样本数M=12000,其中各个类型包含2000个样本,采样点为统一为512个,80%的样本用于训练模型,20%用于验证。为了便于与其他文献算法相比较,测试集总体的分类效果用整体精度(OA)表示,定义为:
(8)
其中:N、L、R、V、A、P分别为测试集中正常信号(N)、左束支传导阻滞(LBBB)、右束支传导阻滞(RBBB)、房性期前收缩(APC)、室性期前收缩(PVC)、融合性心拍(P)正样本预测为正样本数目;M为总样本数目。
从表2可以看出,本文方法在公共数据库上的识别精确度高于表2中的其他方法。在心率类别数目上多于其他方法的同时识别精度远高于其他方法。验证了本模型具备较好的泛化能力。
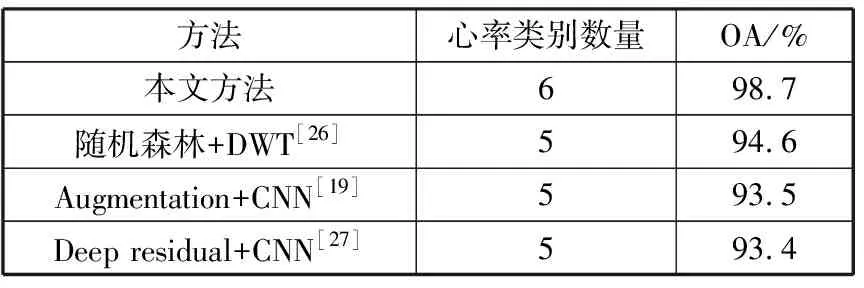
表2 本文与其他方法比较
4 结束语
本文对面向临床的ECG分类进行了研究。针对多导联ECG分类问题引入了一维卷积神经网络。使用的数据增强和Focal loss损失函数对类别失衡有较优的效果。经过1.8万条训练样本,最终在2千多条的验证集上取得了0.91的F1值,93.96%的准确率,召回率为87.89%的结果。
网络结构参数的进一步优化、起始点范围的选择以及分类器融合途径等都有待进一步研究。今后将不断以既有思想和方法为基础,吸纳新的理论和技术,为计算机辅助ECG分析方法的广泛应用进行不断的探索和努力。
猜你喜欢
实用心电学杂志(2023年4期)2023-03-08 06:11:55
保健医苑(2022年4期)2022-05-05 06:11:10
求学·理科版(2020年4期)2020-05-13 14:03:12
新世纪智能(数学备考)(2020年12期)2020-03-29 02:15:42
广东教育·高中(2017年11期)2017-12-04 17:09:16
实用心电学杂志(2016年5期)2016-11-11 00:54:45
实用心电学杂志(2016年5期)2016-11-11 00:53:27
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
