
基于改进的YOLO v3车辆检测方法
2021-08-20 10:30:04顾晋罗素云
农业装备与车辆工程 2021年7期
顾晋,罗素云
(201620 上海市 上海工程技术大学 机械与汽车工程学院)
0 引言
车辆检测是目标检测的一种,目标检测的发展经历了传统检测方法、机器学习以及现在热门的深度学习3 类算法阶段。传统的检测方法主要由3 部分构成滑窗区域选择、手工设计特征并提取(一般有HOG[1]、SIFT[2]等算法),分类器分类检测(常用算法有SVM[3]、ADABOOST[4]等)。传统目标检测方法的不足主要有:(1)滑窗区域选择遍历图片效率低下,图片的重要特征所在的部位各不相同,造成时间的浪费严重;(2)手工设计特征受外部条件例如光照、阴影、目标形态多变等影响严重,鲁棒性差;(3)分类器受特征及样本影响大,易产生假阳性,训练时间过长等问题。
基于深度学习的目标检测算法,利用大量的数据完成对模型的训练[5],其算法的泛化能力、鲁棒性更强,更适合目标复杂多变、背景复杂多变的实际应用场景,而不是如传统检测算法一样受限于实际应用中的诸多因素。目前,主流的基于深度神经网络的目标检测方法主要分为TWO-STAGE方法和ONE-STAGE方法[6],即基于Region-proposal[7]的TWO-STAGE 方法:R-CNN,Fast R-CNN,MR-CNN 和基于回归的ONE-STAGE[8]方法:YOLO,SSD。本文提出的改进算法以YOLO v3 为骨架。YOLO 算法于2015年在CVPR2016 上出版,它避免了CNN 算法速度慢的问题,但同时也牺牲了一部分的定位精确度。相对于YOLO-v1,YOLO-9000,YOLO v3 解决了许多前身存在的问题。本文通过简化YOLO v3 的网络结构,引入K-means++[9]处理数据集,用更优秀的GIOU 损失函数代替原有的MSE 函数,提升了YOLO v3 的精确度并兼具识别速度。实验证明,本文提出的改进算法可取得较好的效果,Recall 值达到了88%。
1 YOLO-v3 算法
YOLO 系列是基于卷积神经网络的目标检测算法[10],本文以YOLO v3 算法为改进对象进行车辆检测研究。
YOLO 系列算法的基本原理[11]是在图片输入后将其分成a×a 个栅格,当图片中物体的重心位置的坐标落入某个栅格中,那么该栅格负责检测该物体。每个格子产生多个预测框Bounding boxes 及其置信度object_conf,每个预测框包含5个参数,即(x,y,h,w,置信度)。(x,y)预测边界中心和对应网格边界偏移值,宽度(w,h)是帧的宽度和高度与整个图像的宽度和高度的比值。置信度object_conf 反映是否包含物体以及准确性,如式(1)所示:
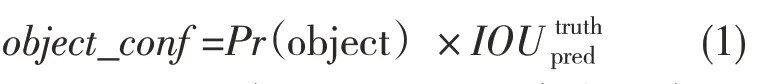
式中:Pr(object)——栅格是否包含真实对象,假若栅格中包含物体则Pr(object)取值为1,若不包含则取值为0;——预测框与真实物体区域的交集区域的面积。YOLO 实现原理的示意图如图1 所示。
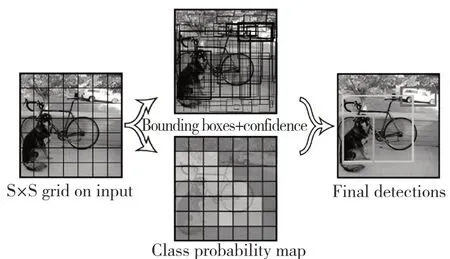
图1 YOLO 实现原理Fig.1 Realization principle of YOLO
YOLO v3采用Darkent-53网络结构。Darknet-53 网络融合了YOLO 9000 的优点以及Darknet-19和新的Residual(残差) 网 络。Darknet-19 网络由19 个卷积层,5 个最大池化层组成[12]。它类似于VGG 模型的传统网络结构,假若YOLO v3 从传统网络模型增加到53 层,模型结构会过于冗长产生梯度消失问题,所以YOLO v3 引入了ResNet 的Residual 残差结构,减少了训练难度。Darknet-19 结构如图2 所示,Darknet-53 网络结构如图3 所示。

图2 Darknet-19 网络结构Fig.2 Network structure of Darknet-19
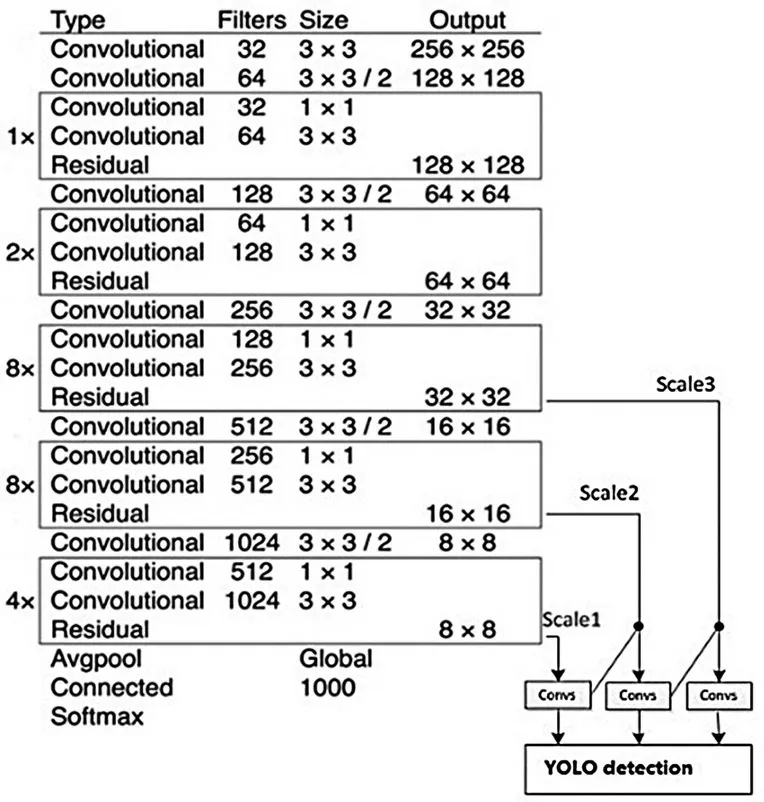
图3 Darknet-53 网络结构Fig.3 Network structure of Darknet-53
YOLO v3 的总体网络结构[13]主要由3 部分组成,分别为(1)输入部分;(2)基础网络部分,YOLO v3 采用的是Darkent-53;(3)特征融合层。
YOLO v3 对图片的输入像素有一定的要求,图中为416×416 像素,假若输入的图片过大,需要将图片Resize 为合适的尺寸,否则算法中的感受野无法完整地感知到图片。虽然Darknet-53中的卷积核带有缩小输出图片尺寸的效果,但是仍然需要输入复核尺寸的图片,才能得到更好的检测效果。
YOLO v3 基础网络部分即Darknet-53,如图4 所示,由DBL 组件与残差结构res(n)组成。DBL 组件如图4 左下角所示,它分别由卷积、BN、激活函数LeakyReLu[14]组成。卷积为1×1与3×3 组成,BN 层的计算公式[15]:
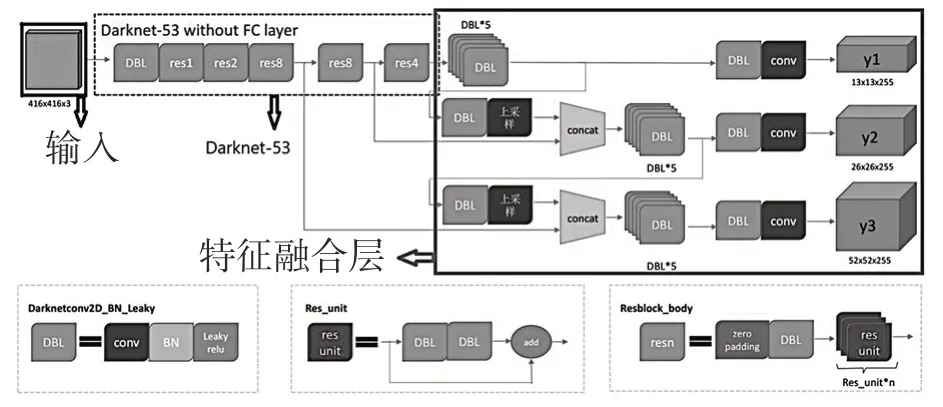
图4 YOLO v3 总体网络结构图Fig.4 Total network structure of YOLO v3

式中:γ——缩放因子;μ——均值;σ2——方差;β——偏置;xconv——卷积计算结果。xconv计算公式如式(3)所示:
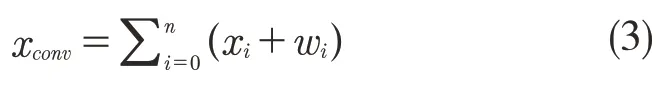
式中:res(n)——YOLO v3 的残差;n——每个残差块中有n 个残差单元。Darknet-53 得益于残差简化了网络结构,避免了梯度问题[16]。
残差模型图如图5 所示。
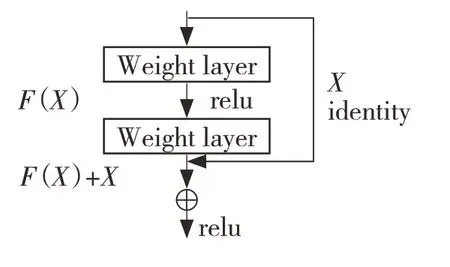
图5 残差模型图Fig.5 Residual model diagram
特征融合层为图4 最右侧所示。由3 个尺度组成[17],分别为(1)最小尺度Y1 层,输入13×13 的特征图,一共1 024 个通道,进行一系列卷积操作,通道数减少为75 个,输出同样为13×13 的特征图,随后进行分类与回归定位;(2)中等尺度Y2 层,对79 层的13×13,512通道的特征图进行卷积操作,进行上采样,生成26×26,256 通道的特征图,然后将其与61 层的26×26,512 通道的中尺度特征图进行合并,最终输出为26×26 大小的特征图,75 个通道,然后在此进行分类和定位回归;(3)最大尺度Y3层,对91 层的26×26,256 通道的特征图进行卷积操作,生成26×26,128 通道的特征图,进行上采样生成52×52,128 通道的特征图,然后将其与36 层的52×52,256 通道的中尺度特征度合并,进行一系列卷积操作,通道数最后减少为75 个。最终输出52×52 大小的特征图,75 个通道,最后在此进行分类和位置回归。
2 基于改进的YOLO-v3 的车辆检测方法
2.1 数据处理
选择K-均值聚类算法处理数据。由于K-means 并不适合车辆检测这类位置变化频繁的场景,于是采用K-means++算法优化候选区域的选取,提高实验结果的精度。
means++[18]的算法步骤分别是:(1)从输入的数据点集合中随机选择一个点作为第一个聚类中心;(2)对于数据集中的每一个点x,计算它与最近聚类中心的距离D(x);(3)重新选择一个D(x)值比较大的数据点作为新的聚类中心,这样被选为聚类中心的概率较大;(4)重复2和3 直到k 个聚类中心被选出来;(5)利用这k个初始的聚类中心来运行标准的K-means 算法。
标准K-means 的算法过程为:(1)随机生成初始位置;(2)将所有数据点分类到最近的欧氏质心;(3)计算一个类中所有数据点的位置,并计算出新的质心;(4)重复上述步骤,直到重心位置不再改变。
K-means 的聚类过程如图6 所示。

图6 K-means 的聚类过程图Fig.6 Clustering procedure of K-means
K-means++可以根据实际应用场景选择合适的聚类中心,尽可能采集数据集中的数据点,将数据集进行分类,使其更加适合YOLO v3 对数据尺寸敏感的特点,从而提升算法的精确度与效率。
2.2 YOLO v3 模型剪枝
YOLO-v3 网络模型采用Darknet-53,相较于YOLO2 的Darknet-19 引入了残差,成功简化了模型结构。简化模型结构的意义在于更少的参数参与算法计算,减少冗余的通道,减少内存的浪费。此外,训练过程中结点划分过程不断地重复,会造成算法将训练集自身的特点当作所有的数据都具有的一般性质,从而导致过拟合[19],剪枝处理也可以有效地降低这种风险,降低模型的大小,加快训练速度。
剪枝算法主要是基于BN 层的γ参数并针对Darknet-53 中的卷积层进行剪枝,γ参数公式如下:
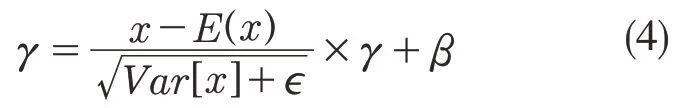
原理为BN 层对通道进行归一化处理。
模型剪枝是为了减少卷积层中特征性较弱的神经元,进而达到减少不必要的计算、加快速度的目的。主要针对粗粒度剪枝中的通道剪枝。采用BN 层的参数γ[20]作为通道剪枝因子。
剪枝算法的步骤简单分为以下3 步[21]:(1)对模型进行稀疏化训练,提取稀疏化后的BN 权重,统计得出的γ并排列,根据一定的比例制定临界值s;(2)将小于s 的γ减掉,得到剪枝后的模型;(3)对剪枝得到的模型进行通道调整。卷积层剪枝前后部分通道数变化如图7 所示。
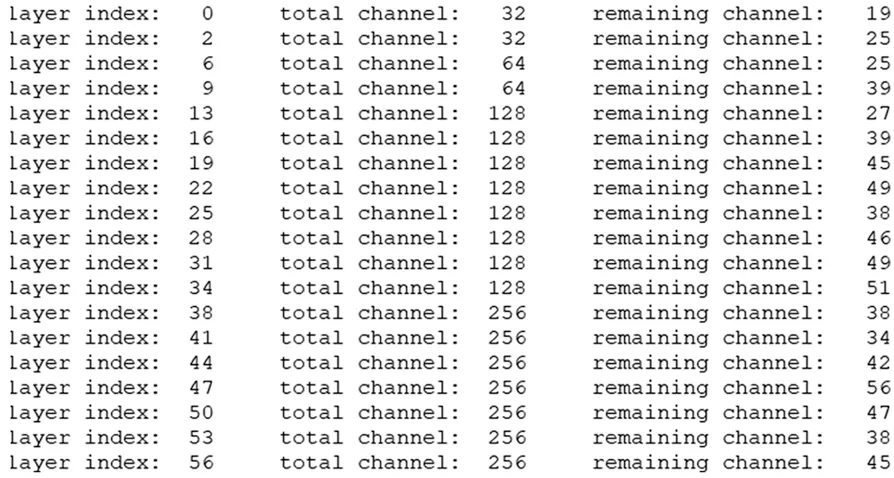
图7 卷积层剪枝前后部分通道数变化Fig.7 Change of channel's number of convolution layer
如上文所述,在YOLO 层中存在减少通道数的操作,我们进一步减少特征通道数量,更加精简了模型,加快了模型效率。
2.3 GIOU 回归策略
YOLO-v3 的损失函数采取的是MSE 回归策略。YOLO-v3 目标检测算法的缺陷是对输入图像的尺寸非常敏感,原因就在于MSE 函数作为YOLO-v3 的损失函数对目标的尺度非常敏感[22]。MSE 损失函数的模型图如图8 所示。
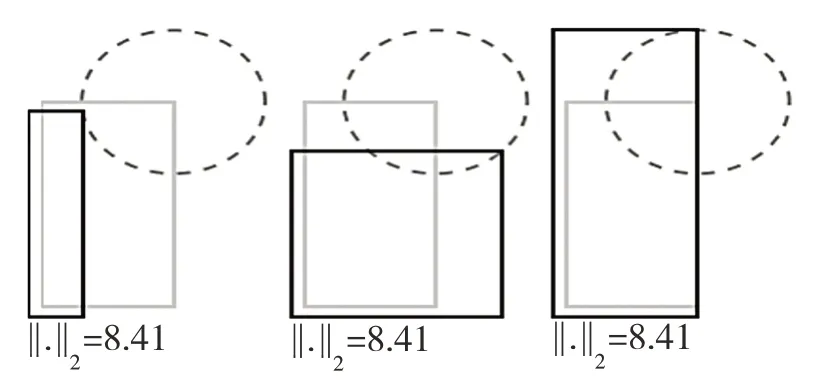
图8 MSE 损失函数的模型图Fig.8 Model diagram of MSE loss function
本文提出用GIOU 回归策略替代MSE 回归策略,GIOU 函数模型图如图9 所示。
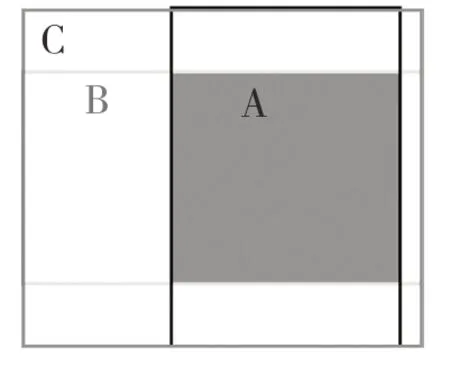
图9 GIOU 函数模型图Fig.9 Diagram of GIOU model
GIOU 函数计算公式如下:
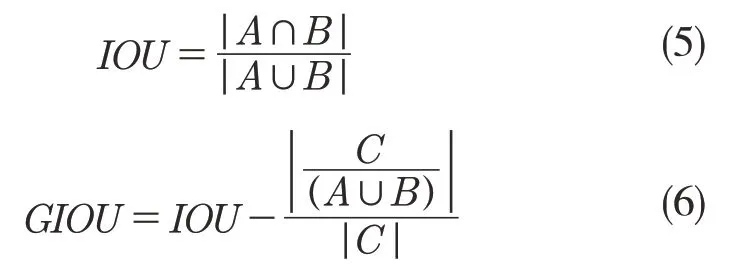
相比于MSE 与现如今使用较多的IOU 回归策略,GIOU 有如下优点:(1)GIOU 具有作为一个度量标准的优良性质;(2)具有尺度不变性;(3)GIOU 的值是小于IOU 的值的;(4)在A,B 没有良好对齐时,会导致C 的面积增大,从而使GIOU 的值变小,在矩形框没有重叠区域时依然可以计算损失函数值,比IOU 函数更加优秀[23]。
采用GIOU 回归策略代替原有MSE 回归策略可以有效解决YOLO-v3 车辆检测算法对输入图形尺寸过于敏感导致精度差的问题。
3 实验
3.1 实验平台
本实验是在Windows 系统下进行的。采用Nvidia GeForce RTX2060 显卡,Intel 酷睿i7-10875H 8 核16 线程CPU处理器,32G内存。深度学习框架为KERAS-YOLO v3。为了提高计算速度,减少训练时间,在NVIDIA 官网上下载CUDA-Enabled GeForce and TITAN Products 调用GPU 进行训练。
3.2 数据集处理
本实验采用COCO 车辆类别数据集,共下载了80 000 张图片。YOLO-v3 训练中不一定需要负样本,我们只需标出需要检测的样本即可。训练集,测试集,验证集按3∶1∶1 划分。随后制作标签覆盖检测图片的正确位置。
Darknet-53 使用COCO2017 车辆类别数据集训练YOLO-v3 的步骤分别为:(1)将COCO 的Instances_val(train)2017.json 标签转为VOC(.xml)的标签;(2)分别得到了训练集的xml 和训练过程中的测试集的xml 之后,我们进一步使用脚本转化xml 为txt,其中分为2 部分。第1 部分将所有xml 的路径取出来放到train_all.txt 中,第2部分将得到的文件一起整理好,生成每个xml 对应的txt 标签;(3)最后将拟生成的txt 标签放到VOC2020 的labels 的train2017 和val2017 下面就可以开始训练darknet 了。
3.3 实验结果
对改进过的YOLO-v3 车辆检测算法指标进行了动态记录。平均损失函数的变化如图10 所示。
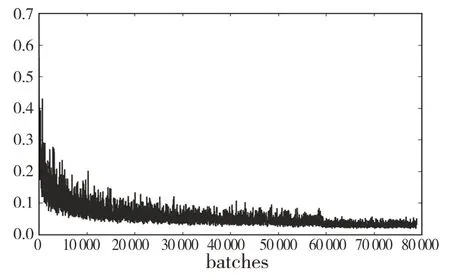
图10 平均损失函数的变化Fig.10 Diagram of Avg_loss
在平均准确度与召回率方面,将原YOLO-v3算法和改进过后的YOLO-v3 算法进行了比较,两者均在COCO 数据集上进行测试。从表1 可以看出,本文提出的改进的YOLO-v3 车辆检测算法Map 值达到81.3%,原算法Map 值为75.5%。召回率改进后的算法可以达到88.18%,原算法只有85.11%。检测帧率也得到了提高,表明改进后的YOLO-v3 车辆检测算法检测效果比原算法更高,更准确。
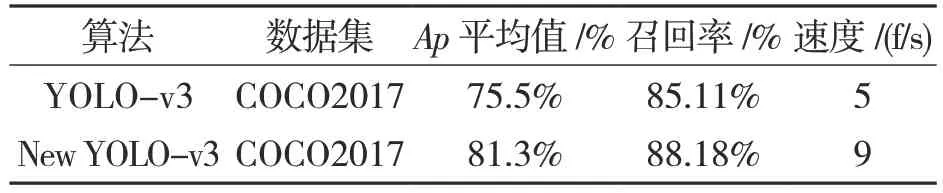
表1 Map 值与召回率比较结果Tab.1 Results of Map and Recall comparison
3.4 测试结果
利用改进的算法对2 个视频进行了测试,分别为高速公路录像视频,以及车辆车载镜头视频,测试结果如图11 所示。
本文提出的基于YOLO-v3 的改进算法的实际测试结果如图11 所示。从图(a),图(b),图(c),图(d),图(e),图(j)中可以看出该算法对密集对象检测效果非常好;从图(h)中可以看出对突然出现的车辆检测效果很好;从图(g),图(i),图(k)中可以看出,改进过后的算法对尺寸较小、较密集的物体检测效果良好。

图11 测试结果Fig.11 Result of test
4 结语
基于YOLO-v3 的车辆检测算法,利用深度学习的特点,有效避免了传统算法需要人工选择特征的弊端。本文首先采用K-means++聚类策略处理数据有效避免了梯度问题,提高了之后的检测效率。随后通过模型剪枝以及采用新的回归策略,进一步提高了YOLO-v3 的检测效率和精准度。实验结果和现实测试结果表明,本文提出的基于改进的YOLO-v3 车辆检测算法比原有算法的效果有所提高。
猜你喜欢
保健医苑(2022年5期)2022-06-10 07:47:22
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
天津诗人(2017年2期)2017-03-16 03:09:39
河南科技(2015年8期)2015-03-11 16:23:52
