
3D迁移网络的阿尔茨海默症分类研究
2021-08-19 11:16陆小玲吴海锋孔伶旭罗金玲
计算机工程与应用 2021年16期
陆小玲,吴海锋,曾 玉,孔伶旭,罗金玲
云南民族大学 电气信息工程学院,昆明650504
作为最常见的老年痴呆症,阿尔兹海默症(Alzheimer’s Disease,AD)是一种神经系统功能退化性疾病,病因尚未完全查明。以现在的医疗手段,AD还无法被治愈[1],但若能对其正确诊断,则可采用正确的治疗方式延缓病人病情。目前,AD的主流诊断方式是依靠医师以临床资料综合分析和判断,包括简易精神状态检查表(Minimum Mental State Examination,MMSE)的神经心理学测验[2],脑电图(Electroencephalogram,EEG)的电生理检查[3],核磁共振成像(Magnetic Resonance Imaging,MRI)、正电子发射断层扫描(Positron Emission Tomography,PET)的神经影像学检查[4]以及脑脊液检查[5]等。虽然这些方式均取得不错的诊断效果,但毕竟耗时耗力,且存在一定主观性,仍可能发生误诊。
近年来,随着机器学习技术的快速发展,尤其是在AD定量评估中所展现的优势,人们发现其可作为一种快速的辅助诊断方式,例如多模态分类[6]和支持向量机(Support Vector Machines,SVM)[7]等机器学习算法。MRI作为一种高清晰的成像技术,其成像分辨率高,对比度好,信息量大,可清楚地显示脑结构,反映细微变化,且不会产生对人体有害的电离辐射,目前被广泛地应用于机器学习对AD的辅助诊断上。传统的MRI机器学习分类方法主要可分为结构特征分类和降维特征分类,其中结构特征分类又主要基于海马体和脑灰质特征[8-9],而降维特征分类主要从感兴趣区(Region of Interest,ROI)提取特征[10]。另外,还有MRI纹理特征提取技术[11],其运行速度和分类性能也较好。然而,这些传统的MRI机器学习分类准确率依赖提取特征的准确率,且大多还需手动提取,有时特征提取还较困难。如果提取的特征本身不太正确,那么分类的准确率也不会很高。除此之外,传统机器学习分类更擅长于已知特征数据挖掘,而对于如AD其特征尚未完全明确的图像分类,往往存在一些不确定性。
相比传统的机器学习算法,深度学习针对未明确特征的对象往往具有自学习提取特征特性,其通过非线性模型将原始数据转变成低级特征,再经多个全连接层形成抽象高级特征,使得分类对象具有更具体和有效的特征表达。由于MRI是一个具有脑区空间信息的三维(3D)图像,目前AD分类较好的深度学习是建立在3D卷积神经网络(Convolutional Neural Network,CNN)上[12],该方法能够自动从MRI数据提取特征进行分类,而无需对脑组织和区域进行分割。然而,为了提高分类准确率,深度学习网络往往需要大量的训练数据,而目前公开可使用的AD MRI数据仍然有限。另外,深度学习通常是深度网络,权重数量巨大,再加上巨大的训练数据,导致深度网络的训练时间较为漫长。作为一种针对小型数据训练的分类深度网络,迁移学习已在相关的训练数据集中进行了预训练,因此可缩减在目标数据集的训练时间。较早将迁移学习用在MRI AD诊断上的是采用3D的CNN方法[13-14],其利用SAE提取特征,然后将其作用于网络的较低层中,而较高层则通过全连接层实现。该3D CNN可在(Computer-Aided Diagnosis of Dementia,CADDementia)[15]数据集上进行训练和验证,也可迁移至阿尔茨海默病神经影像学倡议(Alzheimer’s Disease Neuroimaging Initiative,ADNI)[16]数据集。虽然该方法能够得到较高的分类准确率,但毕竟采用3D卷积,权重数量庞大,尽管网络文件可公开下载,预训练权重却未提供下载,这些都致使其训练时间过长,成为其进一步扩大应用的制约因素。因此,二维(2D)迁移网络被提出用在MRI的AD诊断上,AlexNet[17]和VGG16[18]作为可迁移网络,已在AD诊断上展示了良好性能。这两个迁移网络分别采用AlexNet和VGG16作为预训练网络,然后将MRI图像进行切片,按位置和图像熵选择若干张切片图像作为2D卷积神经网络的输入,再将2D神经网络的输出送至一个顶层网络中实现最后的分类。由于该方法将MRI图像进行切片,该切片可以作为2D卷积神经网络的输入,避免了3D图像与2D网络维度不匹配问题。然而,切割不可避免带来信息丢失,致使分类的准确率受到影响。
针对以上问题,本文提出了一种3D迁移学习网络,该迁移学习可实现MRI的AD与正常控制(Normal Control,NC)分类。首先,将一个被试者的MRI图像进行切片,得到若干二维图像,再将这些二维图像输入到预训练的迁移网络中完成瓶颈特征提取,然后对瓶颈特征进行有监督的顶层特征提取,最后将来自每个切片提取的顶层特征合并输入到分类层网络实现分类。相比以往的迁移学习,该3D网络可从MRI图像中提取更多的特征值,因此具有更高的分类正确率。同时,引入了迁移学习,其瓶颈层网络已经过预训练,且顶层网络采用有监督训练,因此减少了训练时间。实验中,本文采用公开的华盛顿大学阿尔茨海默病研究中心的开放成像数据(Open Access Series of Imaging Studies,OASIS)[19]和预训练权重可下载的MobileNet网络,相比传统的2D迁移网络,分类准确率提高了约8个百分点,而分类时间约为传统堆叠自动编码器(Stacked Auto-Encoder,SAE)方法的1/60。
1 维度匹配问题
由于公开的AD MRI数据有限,本文将采用面向小数据集分类的迁移卷积神经网络来实现AD分类。同时,为了减少分类信息的损失,考虑一种3D网络的分类方法。与传统方法相比,本文的分类网络需要保证输入到分类网络的数据应包含丰富的分类信息,同时也要使得分类网络不能太复杂,以免造成较长的训练时间,因此数据如何进入分类网络是将MRI数据应用于迁移学习的AD分类的首要问题。作为一种高清晰的成像技术,MRI信号是一个包含脑区结构像的3D图像,因此是一个NX×NY×NZ的3D数据,其中NX、NY和NZ分别表示脑区的三个空间维度。
一种常用的MRI数据应用于2D迁移学习的方法是将MRI数据进行切割[17-18],得到N1张N2×N3的二维图像,其中Ni,i=1,2,3可以是NX、NY和NZ的任一维,从而可得到冠状、矢状或轴状切面。然后将这N1张二维切面输入到2D迁移网络,最后构建一个顶层网络实现最终的分类。此时,原来的MRI数据经切割后从三维降至二维,因此解决了2D CNN网络的输入维度问题。然而,该方法的性能将取决于N1的值。理论上,N1的取值越大越好,这相当于原3D图像经切割后信息丢失得越少。然而由于深度学习通常是深度网络,输入的图像越多则权重将变得异常庞大。以一个CNN网络为例,假设其共有NC个卷积层,每个卷积层分别由L1,L2,…,LN个特征图组成,特征图的大小分别为F1×F1,F2×F2,…,FN×FN,所使用的卷积核尺寸分别为M1×M1,M2×M2,…,MN×MN,若步长(stride)为1时,那么该网络总共的权重数量为:
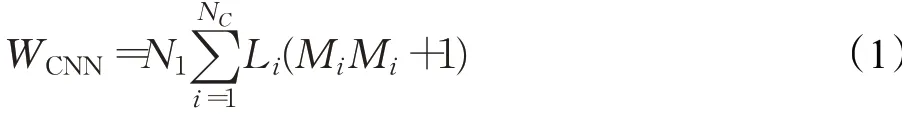
其中偏置数为1。由式(1)可见,网络的权重数与MRI图像切片数N1密切相关,N1越大WCNN也越大。
为减小切片数,也可按照一定规律进行切割。一种方法是按位置排序,越靠脑中部位置的切片将保留,反之则舍弃[17];另外一种方法是按图像熵排序,熵越大的切片将保留下来[18]。然而,不管是以上哪种方法切割,若减少切片数将不可避免带来MRI图像经切割后的信息损失,但增加切片数又将使网络变得复杂,训练时间延长,如图1所示。因此,在MRI信息损失和迁移网络复杂度上寻找平衡,以保证分类网络的分类准确率和减少训练时间将是本文研究的一个重要问题。

图1 MRI迁移学习的AD分类问题Fig.1 AD classification for MRI transfer learning
2 算法
2.1 分类基本过程
本文使用MRI数据以及采用迁移学习的CNN网络来对AD进行诊断,方法的基本过程如图2所示。把一个被试者的MRI数据经I个切片后输入到已预训练完的迁移瓶颈(Bottleneck)网络中,以此获得每个切片的瓶颈特征,再将每个切片的瓶颈特征经一顶层以获得顶层特征,然后该被试者所有切片的顶层特征输入到分类层中得到最后分类结果,完成疾病诊断。在该训练网络中,无论是瓶颈层还是顶层的权重对于每一个切片均为共享,不需要对每个切片都采用不同的权重,因此,即使增加切片数量,权重数量也没有得到增加。在本文方法中,迁移的瓶颈网络是用一个2D网络来对2D切片的特征进行提取,因此只要对3D图像产生足够的切片数就可实现对3D图像的分类。同时,虽然对每个切片都提取了瓶颈层特征,然而分类网络中又添加了顶层来进一步降维来提取特征,因此特征值维度将变小,分类网络的复杂度也将降低。

图2 分类方法基本框架Fig.2 Basic framework for classification
2.2 迁移学习的3D特征提取
一个MRI信号往往是一个具有脑区空间的三维数据,不能直接作为一个2D图像分类器的输入。由上所述,为实现3D图像的特征提取,利用一个2D的迁移网络来提取图像切片的特征。设xS和DS分别是一源数据集中任意一张2D图像矢量和其对应标签,将一CNN网络在该源数据集中进行预训练,使其满足

预训练完成后,将在目标MRI训练数据集中训练网络以完成迁移学习的特征提取。首先,完成顶层网络训练。把训练集中任意一个被试者的MRI中第i个切片图像作为迁移网络fbtneck(⋅)的输入,使得该被试者及其所对应标签DT满足

其次,完成分类层网络训练。把训练集中任意一个被试者的MRI 3D图像张量作为迁移网络fbtneck(⋅)的输入,使得该被试者XT及其所对应标签DT均满足

则目标网络分类层fclass(⋅)训练完成,其中wc是分类层权重矢量,F为图像张量XT经I个切片后由式(3)得到的顶层特征矢量,表示为
图3 给出了迁移学习AD特征提取的训练过程,整个过程包含预训练和目标训练两部分。其中预训练部分通常无需在本地端完成,即使瓶颈层的权重wb非常庞大,但可由第三方预先完成而获得,因此可大幅减少提取特征的训练时间。更重要的是,为保证提取瓶颈特征的有效性,训练和获取瓶颈层权重wb往往在一个非常巨大的源数据集中完成,如ImageNet数据集,因此相比单纯无迁移的CNN,迁移网络可以解决目标数据集不足的情形,而目前获取大规模ADMRI数据仍存在一定困难。图3中的AD目标训练中又包含顶层训练和分类层训练两部分,其中顶层训练的输入是由被试者的每张切片所提取的瓶颈层特征,瓶颈层的权重则来自于预训练后得到的结果。顶层网络的输出为从每张切片中提取的特征值,而每张切片的标签将对应所属被试者的标签。训练完毕的顶层权重将可用于分类层训练,分类层训练的输入是以被试者为单位的3D切片张量图像,而该切片张量经过顶层得到该被试者的MRI图像特征,然后进入分类层以完成最终分类层的训练。值得注意的是,图3分类层训练中分类层的权重wc对每一个切片都为共享,因此即使每个被试者的切片数量I非常庞大,相比非共享的方式,权重数也仅为其1/I。另外,提取特征值的顶层训练和分类层训练均为有监督训练,由于无监督SAE训练不仅需要编码层还有解码层[15],本目标训练的层数可减少1/2。

图3 迁移学习特征提取训练图Fig.3 Train and feature extraction in transfer learning method
其实,图3的迁移学习特征提取只需对一顶层网络和分类网络进行训练,而两者均是一个浅层的神经网络,其权重和wc的数量并不大,因此可保证训练能在短时间内完成。另外,由于顶层特征来源于一个被试者的若干切片图像,只要切片数量足够多,则可以保证MRI图像的信息损失足够小,而由于顶层的权重对所有切片均为共享,并不会使切片数量增大而使权重数量增大,这也可保证较少的网络训练时间。当然,顶层特征来自对瓶颈特征的提取,而瓶颈层fbtneck(⋅)的权重wb虽可由预训练得到,但瓶颈层的特征也需由fbtneck(⋅)得到,因此太复杂的可迁移CNN网络fbtneck(⋅)会增大特征提取的计算量,本文将选用一种轻型的CNN网络来实现迁移学习。
2.3 MobileNet的迁移学习
在迁移学习的目标训练中,将选用MobileNet来作为瓶颈层网络,该网络能够在保持模型性能的前提下降低模型大小,同时提升模型速度。这样可大幅减少计算量和模型参数量,并且它的预训练权重可下载,它采用一种深度可分离卷积代替传统卷积运算,将一个标准的卷积分解成一个深度卷积和一个点卷积,如图4所示,具体计算过程如下。

图4 MobileNet的深度可分离卷积网络Fig.4 Illustration for separable convolution in deep MobileNet
对于一个N1×N2的MRI数据的切片来说,设其输入通道为M,经过一个标准卷积层,则将产生一个No×NT×NA的特征图,No是输出通道数。若经过一个卷积核大小为DK×DK×M×No的标准卷积层,其中DK是卷积核维度,那么该标准卷积的计算成本为
在深度可分离卷积中,先使用深度卷积为每个输入通道应用单个滤波器,深度卷积的计算成本为DK×
然后使用1×1的卷积滤波器来创建深度层的输出的线性组合,其计算成本为M×No×N1×N2。
从而深度可分离卷积的计算成本为DK×DK×M×
因此,深度可分离卷积的计算成本与标准卷积之比为:
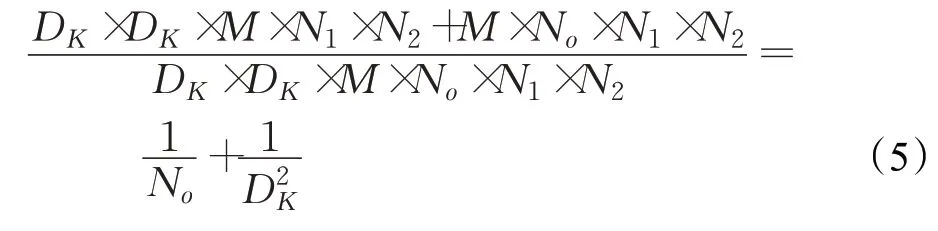
由式(5)可知,MobileNet的瓶颈层所需计算量与相同规模的传统迁移网络比,大大减少。因此从计算量角度,选择MboileNet作为迁移网络是较好的选择。
2.4 顶层与分类层设计
在目标训练中,瓶颈层网络采用迁移的MobileNet网络,无需自行设计,但顶层网络和分类层网络需要设计以保证提取有效的特征。顶层网络的目的是对瓶颈层特征降维,以进一步提取特征,顶层网络设计如图5所示,主要包括全局池化层、全连接层和激活函数输出层。因此,该顶层的权重数量为:

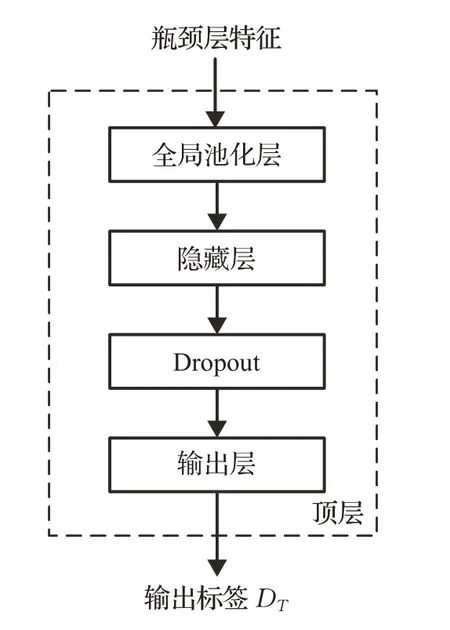
图5 顶层训练设计Fig.5 Top layer in transfer learning
其中,n为全连接层的层数,Ni-1和Ni分别为第i-1层和第i层的神经元个数,di-1为神经元Dropout率,1代表偏置数。在顶层中,经提取和融合后的瓶颈层特征维度已经降至很低,即N0较小,且层数值n较小,因此式(6)的权重数不会很大。分类层网络的目的是对每个被试者的若干张切片的瓶颈特征进行合并,以形成该被试者的特征表示,最后实现分类。分类层网络设计如图6所示,主要包括全局池化层、两个全连接层和输出层,其权重数量类似式(6),若m为分类层的全连接层数,则代入式(6)可得分类层权重数量。

图6 分类层训练设计Fig.6 Classification layer in transfer learning
需要注意的是,顶层和分类层中的一些参数设定会影响最后的分类结果,如全连接层层数、全连接层的神经元数、Dropout的权重丢弃率等,如何选择合适的参数值可以通过实验来测试,这部分的讨论将在实验部分做详细介绍。
2.5 分类算法步骤
本文迁移学习AD分类算法的训练步骤如下所示。
输入:
输出:
已知条件:
瓶颈层网络fbtneck(⋅)及其权重wb;
分类层网络fclass(⋅)。
初始条件:
步骤:
1.预处理:对原始图像进行预处理得到XT,然后分成训练集和测试集,再进行切片
4.分类层训练:由式(4)得到分类层权重wc;
5.验证:由验证集,通过式(4)得到分类结果,并计算分类准确率;
6.重复执行步骤3~5直至获得较高分类准确率。
3 实验
3.1 实验设置
在本实验中,所采用的MRI数据均来源于华盛顿大学阿尔茨海默病研究中心的OASIS数据库,其网址为http://www.oasis-brains.org/,所下载的数据为OASIS-1数据组。该数据包含了416名年龄在18岁至96岁的男性和女性被试者,所有被试者均是右撇子,其中AD被试者100人,NC被试者316人,其数据采集参数详见表1。除此之外,所下载的每个被试者数据均包含源数据和预处理后数据,本文选择预处理后数据作为研究对象,该数据已经过去面部特征、平滑、校正、标准化和配准等预处理[19]。最终,本实验选取了100个AD和100个NC数据,其中AD组包含了70个非常轻度、28个轻度和2个中度AD的被试者数据,NC组数据则从数据库中随机选取。

表1 OASIS中MRI数据相关参数Table 1 Parameters of MRI data in OASIS
本实验分别用以下几种迁移学习的方法提取特征和分类,具体参数由表2列出,步骤简述如下:
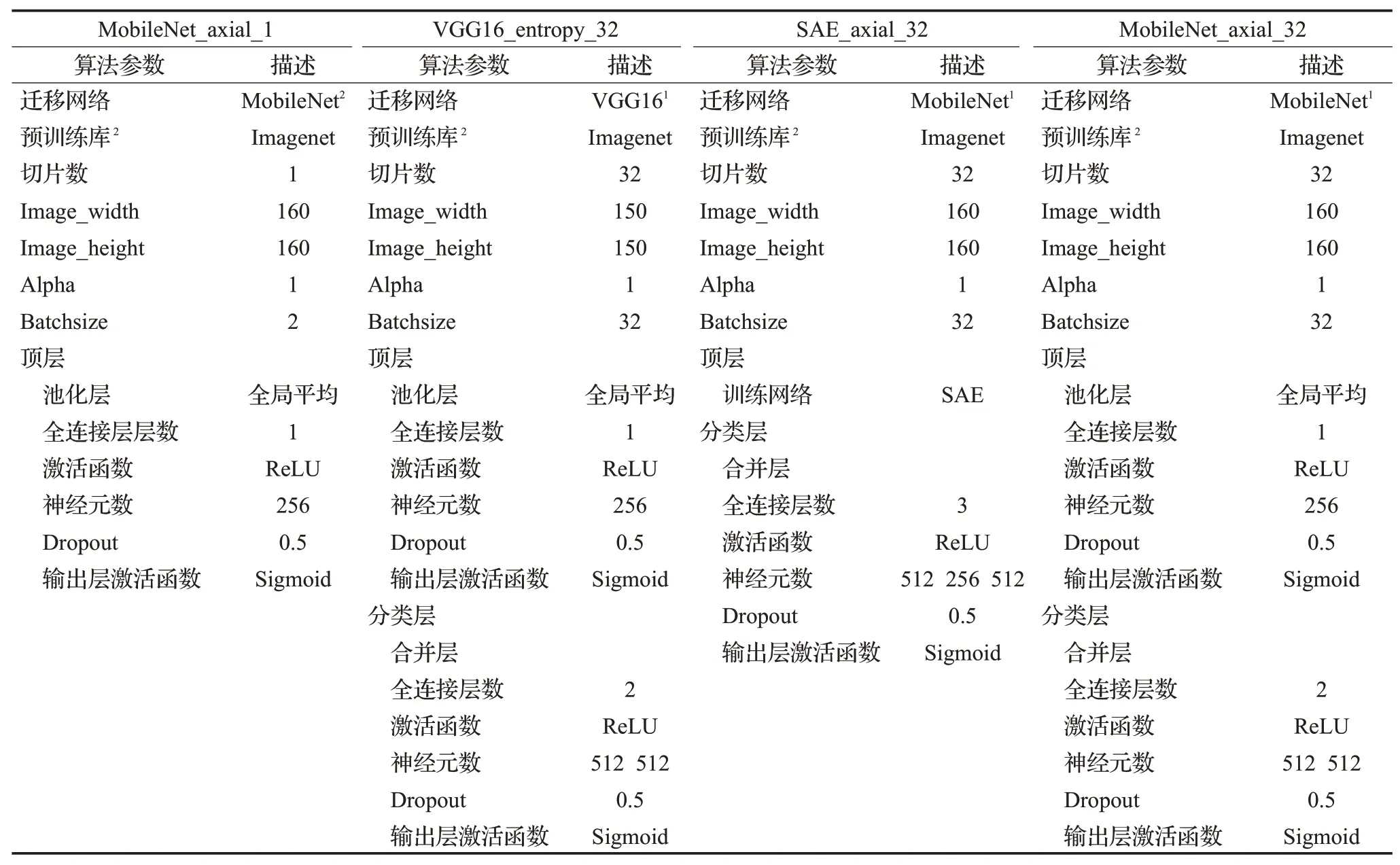
表2 相关分类方法参数Table 2 Parameters in evaluated classification algorithms
(l)MobileNet_axial_1:选取每个被试者最靠近中心的1张轴状切片,用MobileNet提取瓶颈特征后,经顶层网络得到分类。
(2)VGG16_entropy_32:由文献[18]的方法,选取每个被试者信息熵最高的32张MRI切片,其余步骤如第2.5节。需要注意的是,文献[18]中同一被试者的若干张切片被随机地分配到训练集和验证集,而本文方法的训练集和验证集的切片以被试者划分,即同一被试者的切片只能划分至训练集或验证集,以避免验证集中被试者的某些切片已被训练的情况。
(3)SAE_axial_32:由文献[17]按位置切片的方法,选取每个被试者最靠近中心的32张轴状切片,经MoblieNet提取瓶颈特征,提取的瓶颈特征再经SAE提取顶层特征,最后合并被试者的各切片顶层特征送至分类层分类。
(4)MobileNet_axial_32:切片方法与SAE_axial_32相同,其余步骤如第2.5节。
本实验所测试的所有分类方法均采用5折交叉验证,将总数据样本随机分成5份样本,选择其中一份样本作为验证集,其余的样本作为训练集,每个子样本用作测试集1次,交叉验证重复5次。需要注意的是,5折交叉验证是对被试者进行划分,即同一被试者的所有切片是在同一个数据集中,避免被试者的一部分切片在训练集经过训练,其余切片在验证集的情况。根据以上的测试方法,各分类方法的分类准确率为5次分类结果的平均值。
本实验还给出了各迁移方法运行时间的结果,包括了完成一次5折交叉验证时提取瓶颈特征时间、提取顶层特征时间、分类层时间以及总时间。所有方法均在Ubuntu 16.04下Anoconda Python2.7上进行,迁移学习平台为以TensorFlow为后端的Keras,运行硬件为带有Intel®CoreTMi5-5200U(4核)CPU的PC机,未采用任何GPU。
3.2 分类准确率结果
首先,给出各方法的分类准确率,如表3所示。在表3中,MobileNet_axial_1的分类准确率为67.5%,由于该方法仅选取了一张最靠近中心位置的切片,包含的信息不完整,分类准确率较低。表中其余方法的分类结果均对一个被试者的若干切片进行综合得到,其中SAE_axial_32的分类准确率较低,仅有67%,剩余两种方法的准确率均超过了70%,该结果表明利用SAE提取顶层特征的方法分类准确率并不高。分类准确率最高的是MobileNet_axial_32,其分类准确率约75%,与其余的VGG16_entropy_32、MobileNet_axial_1、SAE_axial_32三种方法的分类准确率相比,分别提升了1.5个百分点、7.4个百分点、7.9个百分点。这也表明,利用有监督训练提取顶层特征并在分类层合并的方法的分类准确率要高于仅利用瓶颈特征进行分类的方法。

表3 不同分类方法的分类准确率Table 3 Classification accuracy for evaluated classification algorithms %
图7 给出了预训练网络MobileNet所提取的特征值结果图,其中NC是预训练网络MobileNet提取NC组的顶层特征,AD是预训练网络MobileNet提取AD组的顶层特征。被试者数1~80为训练集,81~100为验证集。从图中可以看出,NC组测试集的顶层特征值大部分集中在0.8~1.0之间,而AD组测试集的顶层特征的一部分值在0.2左右,存在一定的差异性,可确保AD与NC的分类。

图7 顶层提取的特征值Fig.7 Features extracted from top layer
图8 给出了四种分类方法在5次交叉验证中的分类准确率曲线,虽然SAE_axial_32在第1和第5次实验有较高准确率,但是其余实验的分类准确率较低,且曲线波动较大。另外一方面,虽然MobileNet_axial_32和VGG16_entropy_32这两种分类方法并不是每次实验都有较高的分类准确率,但是波动较小,因此平均值相对其他两种方法较高。这也表明,利用迁移学习网络提取特征的方法较SAE的方法更好。

图8 不同分类方法的分类准确率曲线Fig.8 Classification accuracy curves for evaluated classification algorithms
3.3 分类时间
表4 给出了各迁移方法提取瓶颈特征时间、提取顶层特征时间、分类层时间和总时间。从表4中可以看出,当切片数相同时,使用MobileNet提取瓶颈特征的时间少于用VGG16提取瓶颈特征,减少了近80%。这表明MobileNet使用深度可分离卷积,大大减少了计算量。从表中还可以看出,与SAE_axial_32相比,MobileNet_axial_32提取顶层特征的时间减少了近96%,且分类时间也减少了近96%,总时间减少了近97%。这都表明了在相同的环境下,设计一个有监督训练的顶层所提取特征的时间远少于用SAE提取特征的时间。

表4 分类算法运行时间Table 4 Running time for evaluated classification algorithms s
3.4 其他因素对算法的影响
本节给出了其他因素对本文3D迁移学习网络的分类影响。
首先,给出各切片方法对结果的影响,如图9和表5所示,采用的切片方法参照文献[17-18]得到,简述如下:
(l)MobileNet_acs_32:分别沿轴状、矢状和冠状对每个被试者的MRI图像进行切片,选取靠近中心的32张MRI切片,其中包含了11张轴状、11张矢状和10张冠状切片。
(2)MobileNet_entropy_32:对每个被试者的MRI图像切片,选取信息熵最大的32张轴状切片。
(3)MobileNet_axial_32:对每个被试者的MRI图像切片,选取最靠近中心位置的32张轴状切片。
以上方法切片后所采用的步骤均如第2.5节所述。其余参数同MobileNet_axial_32。从图9可以看到,除第4次外,MobileNet_axial_32的分类准确率均较高,与表5的结果一致。该结果表明,按中心位置选取切片的方法优于按信息熵选取切片的方法,且切片选取应在同一状位。

图9 不同切片方法的分类准确率曲线Fig.9 Classification accuracy curves for different slice segment methods

表5 不同切片方法的分类准确率Table 5 Classification accuracy for different slice segment methods %
再次,给出切片的数量对分类算法的影响,分别选取了最靠中心位置的80张、60张、32张、20张和10张轴状切片,分类算法的其余参数同表5和图9中的算法所采用参数,分类结果如图10和表6所示。总体看,各切片数量的分类准确率较为接近,32张切片的结果略高于其余切片数量,然而切片数量太多会导致网络复杂度上升,而切片数量太少,分类准确率会略有下降,因此选用32张切片是一种可行的折衷方案。

图10 不同切片数的分类准确率曲线Fig.10 Classification accuracy curves for different counts of slices

表6 不同切片数的分类准确率Table 6 Classification accuracy for different counts of slices %
最后,给出分类层参数对本文3D迁移网络的分类影响,主要考虑分类层中全连接层的层数。表7给出了全连接层数分别为1、2、3和4时MobileNet_axial_32的平均分类准确率,图11给出了每次交叉验证的分类准确率曲线。从图中可以看到,具有两个全连接层的分类层网络的分类准确率曲线最高,且表中的平均准确率最高的也是两个全连接层的网络,因此,设计具有两个全连接层的分类层网络是一个较好的选择。

表7 分类层中不同全连接层数的分类准确率Table 7 Classification accuracy for different full-connect layers in classification layer %

图11 分类层中不同全连接层数的分类准确率曲线Fig.11 Classification accuracy curves for different full-connect layers in a classification layer
4 讨论
针对MRI数据的AD分类问题,本文采用迁移学习MoblieNet网络对切片数据进行特征提取,再进入到顶层提取顶层特征,最后由分类层网络分类。实验结果表明,本文方法较其他方法的分类准确率有所提升,且运行时间也有较大程度的减少,但还有以下几点需要进一步进行讨论。
首先,本文所采用的迁移网络与传统的3DCNN网络[13-14]相比,AD的分类准确率未表现出显著提升。然而,3DCNN将3D的MRI图像数据直接作为深度网络的输入,权重将不可避免地大幅增加,使得训练时间也大幅增加,而本文方法采用2D迁移网络的预训练权重来提取特征,可大幅减少训练时间,且与传统诊断AD的2D迁移网络相比,分类准确率确实得到了提高。因此,作为一种用于AD辅助诊断的机器学习算法,本文的迁移网络在减少计算成本和节约训练时间上具备一定优势。另外,本文仅使用MRI数据进行AD分类,而文献[20-26]的高分类准确率是建立在多模态分类方法上,除使用MRI,还使用了PET和脑脊髓液等数据,因此也可以考虑使用更多种类数据来进一步提高本文的迁移网络分类准确率。
本实验主要从OASIS-1数据库中选取数据,因此实验所得到的分类准确率结果仅局限于该数据库上,严格意义上,要得到更完整的分类准确率结果还应尝试更多的数据库数据。本文所对比的传统迁移网络[18]使用该数据库,因此选用该数据库能得到较为直观的对比结果。在未来的工作中,也可以使用ADNI和CADDementia等数据库。
在选取切片数上,仅给出被试者10、20、32、60、80张切片的实验结果,并未尝试其他切片数量来作为网络的输入。由于离中心位置较远,靠近头颅两边的切片包含的结构信息较少,且切片数越多,冗余信息越多,过多切片反而降低分类准确率,增加网络运行时间,因此没有考虑更多的切片数量。
在分类层参数设置的实验中,仅给出了全连接层数的实验结果,而未对其他参数做进一步讨论,这主要是因为相对于其他参数,全连接层数对分类结果的影响比较大。对于激活函数,也尝试了一些常用的softmax、tanh、sigmoid等函数,但发现这些函数的分类结果并没有较大差别,因此选择了最常见的ReLU。当然,还有一些参数对顶层性能也非常重要,例如全连接层节点数。然而,节点数量可由经验确定,若节点数太小,网络无法适应大尺寸图像,若节点数太大,会增加训练时间且可能产生过拟合,本文的分类层网络的两个全连接层的节点数均设置为512。
5 结论
利用机器学习方法来辅助诊断AD可减少人工诊断的时间和人力,本文提出了一种利用MRI信号来分类AD和NC的迁移网络机器学习方法。在实验中,采用了OASIS-1的MRI数据,将本文方法与其他传统方法进行了对比,结果显示本文方法的分类准确率比仅用VGG16提取瓶颈特征来分类的方法提高了1.5个百分点,总时间减少了约80%;比用SAE提取特征来分类的方法,准确率提高了约8个百分点,总时间减少了约98%。该结果说明,对于MRI数据,从瓶颈特征提取出顶层特征再到分类层合并的方法要优于直接从瓶颈特征进行分类的方法,其分类准确率得到提高,并且使用有监督的顶层特征训练时间要少于无监督的SAE方法。
猜你喜欢
文苑(2019年24期)2020-01-06
共产党员(辽宁)(2019年7期)2019-11-18
共产党员·上(2019年4期)2019-04-26
环球时报(2017-08-18)2017-08-18
电信科学(2016年11期)2016-11-23
奥秘(2016年3期)2016-03-23
中国组织化学与细胞化学杂志(2016年3期)2016-02-27
中国卫生(2015年4期)2015-11-08
中国当代医药(2015年17期)2015-03-01
中国卫生(2014年2期)2014-11-12
