
一种改进的室内场景语义分割网络
2021-08-19 11:07贺照蒙孔广黔
计算机工程与应用 2021年16期
贺照蒙,孔广黔,吴 云
贵州大学 计算机科学与技术学院,贵阳550025
随着人工智能的不断发展,智能家居机器人逐渐走进了人们的生活。智能家居机器人的主要工作场所就是室内。为了让机器人在室内环境中更好地完成工作,必须使其具备一定的对室内场景的理解能力。而语义分割就是将图像分割成几个具有语义意义的连贯部分,这有助于机器人对场景的理解。因此,越来越多的研究者投入到室内场景语义分割的研究之中。
然而,由于室内场景的物体种类繁多,物体尺寸相差较大且大量物体重叠遮挡,导致室内场景语义分割仍极具挑战。随着深度相机(例如Time-of-Flight(TOF)、Kinect等)的出现和发展,研究者通过深度相机,可以获得更多的几何信息,这些信息对光照、外观和遮挡都具有更高的不变性,融合RGB和深度特征有利于室内场景的语义分割,理论上比只利用RGB信息进行语义分割的分割性能更好。
总而言之,深度图像能为语义分割提供更为丰富的几何信息,有助于网络避免受目标的外观、光照等影响。但是,目前大多数室内场景语义分割网络的融合方式过于单一,不能根据RGB和深度图像的特点进行融合,分割精度欠佳。针对这一问题,本文引入通道注意力机制的思想,设计了特征融合模块,使网络能够学习性地融合RGB和深度信息;同时使用多尺度联合训练指导网络学习各个尺度的特征,加速网络收敛,提高分割精度。
1 网络结构
本文网络主要包括编码器和解码器两部分。其中解码器部分包括:(1)骨干网络-残差网络(Residual Networks,ResNet)[13];(2)特征融合模块(Feature Fusion Module,FFM)。解码器部分包括:(1)反卷积模块;(2)跳过连接;(3)多尺度联合训练模块。具体网络结构如图1所示。

图1 网络总体结构Fig.1 Overall network structure
本文网络首先利用骨干网络ResNet(上下分支)分阶段提取图像的RGB和深度特征,得到(block0~block4)5个阶段的特征图xi∈RH×W×C(i∈[1,5],H×W×C表示特征图的高为H,宽为W,通道数为C);然后通过特征融合模块FFM(粉红色)有选择性地融合同尺度的特征图x;接着使用反卷积(浅蓝色)恢复图像的细节信息,在此过程中,加权融合跳过连接提供的底层特征(黄色);最后使用多尺度联合训练模块,生成outi(i∈[1,4])(深灰色)和最终的finalout(紫色)5个尺度的预测图。
本文网络相较于Locality-Sensitive[10]、DFCN-DCRF[14]等网络的改进之处在于:(1)在编码器部分提出引入注意力机制的特征融合模块,该模块能够根据深度特征图和RGB特征图的特点,学习性地调整网络参数,更有效地对深度特征和RGB特征进行深度融合;(2)在解码器部分则利用多尺度联合训练模块来加权融合图像的底层特征,恢复细节信息,提高预测图像的精确度。
1.1 特征融合模块FFM
在室内场景语义分割中,深度图像和RGB图像提供的信息差异较大。RGB图像提供的是目标类的颜色、形状等各个类别的细节信息;深度图像提供的是图像中各个类的相对位置信息。融合RGB图像和深度图像能够有效提高室内场景语义分割的精度,但如果忽略两者的差异性,使用直接求和的方式对两者进行融合,则无法充分利用两种图像的有效信息,甚至可能因提取到的特征权重占比失衡而导致分类错误。
软土地区选用的地方做法一般采用增加零层板方案。其中,附属用房及办公楼部分柱网大约为7m×8m,柱网间距不大,可仅在柱网间设置零层板即可。而泵房部分为跨度22m的门式刚架结构,因此,还需要对厂区地坪进行处理。地坪活荷载按照30kN/m2进行计算,在钢柱区间内均匀布置地坪桩。北塘热电厂供热管网南干线天碱中继泵站桩承台平面布置图如图1所示,地坪桩及零层板布置图如图2所示。
针对这一问题,本文希望网络能够选择性地关注从深度图像和RGB图像提取到的特征,按照各自特点进行融合,从而产生互补的效果。
因此,本文设计了一个新的特征融合模块,如图2所示(H×W表示特征图的大小,C表示特征图的通道数)。该模块由预处理和通道注意力两部分组成。预处理部分通过卷积操作增强深度特征图和RGB特征图的联系,学习各通道局部特征的相关性,同时使用短连接保留深度特征和RGB特征的特性;通道注意力部分使网络更关注相对重要的特征通道,通过训练寻找各通道的最佳融合方式,实现按照深度特征图和RGB特征图的特点进行融合的目的。

图2 特征融合模块Fig.2 Feature fusion module
(1)预处理部分如图3所示。通道注意力的全局平均池化(Global Average Pooling,GPA)会对整个通道的全局信息进行压缩,无法实现各通道局部特征相关性的学习,因此加入预处理部分来加强深度和RGB这两种特征图的局部相关性。预处理部分首先串联ResNet分支中同尺度的RGB特征图和深度特征图,得到组合特征图x;考虑卷积核感受野对分割效果的影响,通过实验对比发现使用两个3×3卷积来增强深度特征图和RGB特征图的联系效果最好(使用更大的卷积核或增加卷积层的数量,分割精度几乎没有变化,只是增大了计算量);同时使用短连接将组合得到的特征图x映射到后层,用以保留深度特征和RGB特征的特性,最后得到初步融合的特征图y。计算公式如下:
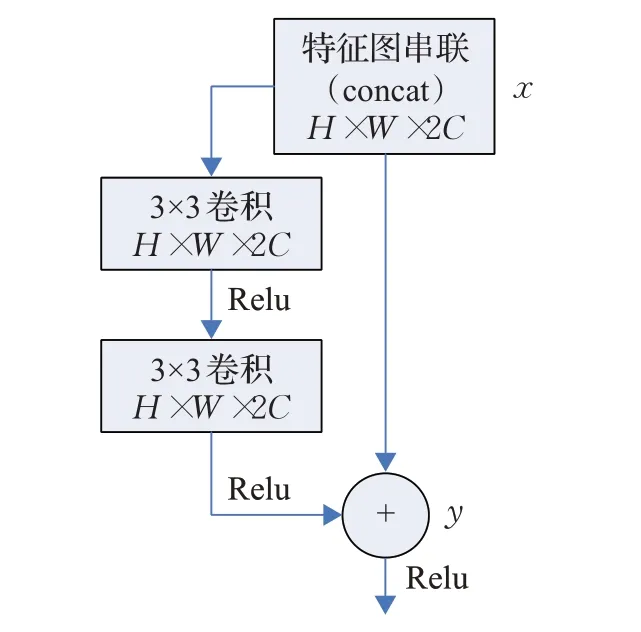
图3 预处理部分Fig.3 Preprocessing part

其中,x为组合后的特征图,f3×3为3×3卷积函数,σ为Relu激活函数。
(2)通道注意力部分如图4所示。该部分通过学习的方式来自动获取每个特征通道的重要程度,然后依此实现深度信息和RGB信息的互补融合。首先使用全局平均池化(GPA)对初步融合的特征图y进行压缩,得到其对应的一维特征yc。此时yc在一定程度上具有全局的感受野,为了便于最后为y分配权重,yc输入和输出的通道数不变,计算公式如下:

图4 通道注意力部分Fig.4 Channel attention part

其中,H为特征图y的高,W为特征图y的宽。
然后通过2个1×1卷积增强通道之间的相关性,并学习得到各通道融合的权重系数组W,目的是通过训练权重系数组W建立各通道之间的联系;为了方便训练,使用Sigmoid函数把学习到的权重W⋅yc映射到0~1之间,将之看作是经过选择后的每个特征通道的重要程度;最后通过点乘的方式给经过初步融合的特征图y进行加权,达到RGB信息和深度信息互补融合的目的,得到深度融合的特征图z,计算公式如下:

1.2 多尺度联合训练
训练数据时,为了加速网络收敛,提高分割精度,本文网络使用5个尺度联合训练以充分利用图像各个尺度的有利于分割的特征。为了恢复图像经过卷积、池化丢失的细节信息,在解码器中,提出一种新的加权融合的方式融合底层特征,具体体现在:特征图每经过一次反卷积,都和跳过连接提供的同尺度的底层特征图加权求和;然后作为输入,进行下一次反卷积。以较小的参数量实现了底层特征和高层语义特征的学习性融合,公式如下:

其中,i∈[1,4],w(wi_0+wi_1=1,且均大于0)为可学习的权重系数,θi为临近上一次反卷积的输出,∂i为跳过连接提供的与θi同尺度的底层特征图,zi为临近下一次反卷积的输入。
为了尽可能少地产生冗余损失,本文对标签进行预处理,用插值的方法把标签处理成与预测图相同的分辨率(对标签进行降采样处理)。使用与预测图相同分辨率的标签指导训练,在一定程度上减少了冗余损失和计算量。损失函数为语义分割任务中最常用的交叉熵损失函数,公式如下:

式中,Lossl表示预测图为outl(l∈[1,5])时的损失,gi∈R表示位置i上的标签语义映射上的类索引,si∈R表示位置i上网络输出的概率,k为数据集中的类数,N表示特定输出的空间分辨率。
本文网络训练数据时的总损失计算公式如下:

2 实验
2.1 实验简介
2.1.1数据集
本文实验在室内场景语义分割主流数据集NYUDV2[15]和SUNRGB-D[16-18]上训练并测试。
NYUDV2数据集是由Microsoft Kinect摄像机记录的各种室内场景的视频序列组成,它含有1 449个分辨率为640×480的像素级标记的RGB和深度图像对,并且包含3个城市的464个场景,具有894个目标类别。本文根据官方设置将该数据集分为795张训练图像和654张测试图像,采用文献中最常用的版本——40类语义标注。
SUNRGB-D数据集是目前最大的室内场景语义分割数据集,它包括10 335个像素级标注的RGB-D图像,具有20个不同的场景和37个类别,其中训练图像5 285张和测试图像5 050张。由于该数据集采集时获取设备不同,图像大小不固定。
2.1.2实验细节
数据预处理。为了降低噪声对数据集的影响,本文对数据集进行了以下预处理:(1)为了降低过拟合,采取了翻转、旋转和像素值归一化等数据增强措施。(2)为了减弱光照对分割效果的影响,采取了颜色和亮度归一化等措施。
参数设置。初始学习率为1E-3,权重衰减为1E-4。使用NVIDIA GeForce RTX 2080 Ti显卡进行训练,batch size为3。在NYUDV2数据集上训练时,每迭代80次,学习率乘以0.8;在SUNRGB-D数据集上训练时,每迭代10次,学习率乘以0.8。
评价指标。本文实验采用像素精度(Pixel Accuracy,PA)、平均准确率(mean Accuracy,mAcc)、平均交并比(mean Intersection over Union,mIoU)、频权交并比(Frequency Weighted Intersection over Union,FWIoU)四种指标衡量分割效果。
2.2 实验结果
2.2.1消融实验
为了验证特征融合模块以及多尺度联合训练对语义分割效果的影响,本文进行了以下五组对比实验。本次实验骨干网络均为ResNet50,实验数据集为SUNRGB-D,实验结果如表1所示。

表1 在SUNRGB-D数据集上的对照实验Table 1 Control experiments on SUNRGB-D dataset %
结果显示,在SUNRGB-D数据集上,使用多尺度联合训练,四种评价指标相对于原网络分别提高了5.7个百分点、1.9个百分点、0.8个百分点、2.3个百分点,这是由于多尺度联合训练能够有效利用有利于分割的各个尺度的特征,逐步优化分割结果;在加入特征融合模块中的注意力部分时,四种评价指标相对于原网络分别提高了6.1个百分点、2.5个百分点、1.4个百分点、3.3个百分点,说明注意力部分能够有选择性地融合图像的RGB特征和深度特征,自适应地为其分配权重,在一定程度上避免目标因形状、颜色相似而被错误分类;当加入预处理部分时,四种评价指标均有所提高,这是由于预处理部分完成了深度特征图和RGB特征图的初步融合,在融合过程中能够学习两种特征图的局部相关性,加强两种特征图之间的联系,有助于注意力部分完成深度融合。
2.2.2网络性能对比
为了证明本文网络的有效性,将本文网络和Locality-Sensitive[10]、FCN-32s[19]等主流网络进行对比。实验在SUNRGB-D和NYUDV2数据集上进行,实验结果如表2所示。
由表2可知,本文网络的分割结果优于其他主流分割网络。相比分割精度最高的RefineNet(ResNet152)[20],本文网络在平均交并比(mIoU)上分别提高了0.7个百分点和1.5个百分点,取得了较好的分割精度。值得注意的是,相对于RefineNet(ResNet152),本文网络的骨干网络为ResNet50,参数量更少。

表2 不同网络分割结果对比Table 2 Comparison of different network segmentation results %
2.2.3分割效果
为了更全面地评估本文网络,分析影响分割精度的因素,测试了本文网络在SUNRGB-D数据集上的不同类别物体的交并比(IoU)并与经典网络DFCN-DCRF进行对比。实验结果如表3所示。
结果表明,本文提出的网络无论是在较难分割的类别(如box、bag),还是在较易分割的类别(如wall、floor)上都优于DFCN-DCRF,说明了本文网络对提升各个类别的分割精度都有一定的效果。同时,对比表3可以看出,交并比较高的类别,一般都是在室内占比较大且结构简单的物体(例如wall交并比为79%,floor交并比为90%,bed交并比为72%等);交并比较低的类别,则是在室内占比较小(例如box交并比为30%,bag交并比为18%等)或是结构复杂、不连续且颜色、材料差异较大的物体(例如bslf交并比为36%,stand交并比为20%)。显然,占比较小的物体分割难度较大。因此,研究如何使网络更关注占比较小的物体,有着十分重要的意义。

表3 SUNRGB-D数据集不同类别物体的交并比(IoU)Table 3 Intersection over Union(IoU)of different types of objects in SUNRGB-D dataset %
图5 显示了本文网络与经典网络FCN-32s、DFCNDCRF的分割效果对比。可以看出,本文网络分割效果更好,不但减小了错误分类的概率,而且分割边界也更加清晰、平滑。

图5 分割效果对比Fig.5 Comparison of segmentation effect
3 结论
针对目前大多数室内场景语义分割网络的融合方式过于单一,不能根据RGB和深度图像的特点进行融合的问题,本文提出了一种改进的室内场景语义分割网络。首先,本文网络以RGB和深度图像为输入,利用ResNet分阶段提取RGB和深度图像的特征;然后,通过引入注意力机制的特征融合模块(FFM),根据提取到的RGB和深度特征的特点,逐步融合各个阶段的特征;最后,使用反卷积恢复图像的细节信息,并加权融合跳过连接提供的底层特征,生成预测图像。此外,在训练过程中,使用多尺度联合训练,加速网络收敛,提高分割精度。实验结果表明,本文网络在室内场景语义分割任务中表现良好,能够有选择性地融合图像的RGB特征和深度特征,有效提高了分割精度。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
北京航空航天大学学报(2018年1期)2018-04-20
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
