
旋转目标检测算法在卫星影像中的应用
2021-08-19 10:58戴朝霞张向东沈沛意
计算机工程与应用 2021年16期
李 巍,戴朝霞,张向东,张 亮,沈沛意
1.西安电子科技大学 通信工程学院,西安710126
2.中国电子科技网络信息安全有限公司,成都610041
3.西安电子科技大学 计算机科学与技术学院,西安710126
卫星遥感目标检测在军事侦察、船舶管理、灾害监测、无人驾驶等领域有着十分重要的应用。随着人工智能技术的蓬勃发展,深度学习在目标检测领域不断突破现有瓶颈,相比于传统方法,其在图像的目标检测、分类分割上更加具有性能优势。深度学习技术所具备的高效通用、灵活易学性,使其成为卫星数据处理领域一个热门研究方向。深度学习在目标检测领域可以分为“two-stage detection”和“one-stage detection”两种检测方法,两者的不同之处在于,前者是一个从粗到细的两阶段处理过程,后者则是一步完成[1]。两阶段检测模型主要包括R-CNN[2]、Fast R-CNN[3]、Faster R-CNN[4]、R-FCN[5]等,检测过程的第一阶段提供大量候选区域,第二阶段则进行具体判定并筛选分数最高的区域。虽然两阶段方法的检测准确率较高,但是不能应用于实时检测。单阶段检测模型主要包括YOLOv1[6]、YOLOv2[7]、YOLOv3[8]、SSD[9]等系列方法。单阶段检测模型拥有更快的速度,可以直接完成端到端的预测,抛弃了两阶段粗检测和精检测的过程,但一定程度上降低了物体检测的精度。
在卫星影像目标检测领域中,检测算法需要维持检测速度和精度之间的平衡。Benjdira等[10]对一阶段检测和两阶段检测模型在卫星影像数据集上进行了细致对比,在精度相当的情况下,一阶段检测算法的灵敏度和处理时间均优于两阶段检测算法。Li等[11]设计了一个端到端的网络用于检测像素级标注的卫星船舶数据,可以将不同级别的特征图进行融合并提取多尺度特征,虽然其可以准确定位,但是标注成本过高且检测速度慢。Adam[12]在YOLOv1上进行改进,解决卫星影像的高图像分辨率问题和小目标物体问题,但无法解决多尺度问题。戴伟聪等[13]将密集相连模块加入到YOLOv3中去检测卫星遥感图像的目标物体,提高了目标的检测精度和召回率。魏玮等[14]对YOLOv3的网络结构和锚点进行改进,提高了YOLOv3在航拍目标检测中的准确性,但是在物体密集的情况下,会存在预测框遮挡问题,视觉效果较差。
针对于如何精确定位,本文设计了基于旋转矩形空间的YOLOv3改进网络用于卫星影像的实时检测,使用旋转矩形框对带有角度的目标物体进行精确定位。主要有以下几点改进:针对于实例角度会随图像缩放而改变的现象,提出了角度转换算法,计算图像缩放后实例的角度;提出了两种旋转框坐标用于回归网络的设计,可以更好地定位带有角度的物体;添加角度锚点到先验框中,帮助网络稳定角度的预测;使用逐边裁剪算法和Green-Riemann定理计算旋转矩形的IOU值;提出了基于旋转矩形空间的非极大值抑制算法,可以有效去除多余的旋转预测框,使算法的检测精度得到较大提升。
1 模型总体设计
网络结构如图1,主要包括预处理部分和三个主体子模块:53层卷积层构成基础骨干网络、特征金字塔网络、用于提取旋转矩形框的预测模块。

图1 模型网络结构图Fig.1 Model network structure diagram
1.1 预处理模块
预处理模块对输入的数据进行调整及增强,使数据能够适应当前网络,得到更为精良的模型。主要具有两个功能:(1)图像缩放,因为本文网络结构的输入大小固定,所以需要将图像缩放到合适的大小,对应于网络结构输入层的大小;(2)数据调整,图像中的物体经过图像缩放后,目标物体的角度信息相较于整个图像会发生变化,需要对角度进行计算变换。图2给出了目标物体角度变化的示意图,以及角度坐标变换公式要用到的参数。坐标(x1,y1)和(x2,y2)为图(a)目标物体上的两点,物体的角度θ0为两点直线与x轴正向所形成的夹角,(w0,h0)为图(a)的宽高。将图(a)缩放为图(b),坐标(x3,y3)和(x4,y4)为图(b)目标物体上的两点,对应于图(a)的(x1,y1)和(x2,y2),物体的角度θ1为两点直线与x轴正向所形成的夹角,(w1,h1)为图(b)的宽高。图(b)目标物体的角度与图(a)目标物体的角度之间的换算公式为式(1):

图2 物体角度变化的示意图Fig.2 Schematic diagram of object angle change

1.2 特征提取
目标检测任务首先需要对输入的图形进行基础特征提取工作,针对如何将图形分解成基础特征,再将分解的基础特征逐渐抽象成更为高级的语义进行概念上表达这一问题,本文采用残差网络DarkNet-53和特征金字塔网络相结合的方式进行提取特征。残差网络ResNet在2015年的ImageNet大规模视觉识别竞赛中取得了图像分类和物体识别的优胜,跳跃式连接这一概念首次被应用在深度学习中[15]。残差结构主要解决的是随网络层数增加带来的网络退化问题。Facebook在2017年CVPR论文中提出了特征金字塔网络思想,用于提取特征[16]。卫星影像上的目标物体比自然图像具有更大的尺寸比,通过特征金字塔结构可以在速度上和准确性上兼顾,并获得更加鲁棒的多维度特征。
1.3 预测模块
本文预测模块将每层特征金字塔网络的输出作为输入,两个1×1的卷积层分别对输入进行特征提取,得到两种不同的旋转框坐标预测以及它们各自的置信度和分类预测,如图3所示。本文使用双坐标参与网络训练可以改善网络性能,优化目标检测的结果,其原理是通过网络结构上的改变将两种坐标信息加入到网络回归中,优化最终的目标函数。其中坐标表示1(图4(a))只在网络训练的过程中用于回归,改善网络性能。坐标表示2(图4(b))用于网络训练时的回归,并在测试阶段输出最终的结果。

图3 预测模块示意图Fig.3 Schematic diagram of prediction module
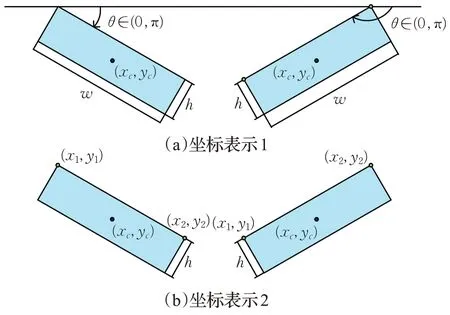
图4 两种旋转坐标示意图Fig.4 Schematic diagram of two rotating coordinates
1.4 角度锚点提出与设计
本文将角度锚点加入到了RPN网络中,不仅在每个格子中设置长宽比例不同的anchor box,而且还在每个长宽比上设置不同的旋转角度,具有不同旋转角度和长宽比的anchor box可以尽可能地覆盖图像上不同角度、不同位置、不同尺度的物体。一些大物体可能会占据图像的中心,本文将最后一层特征图的大小设置成奇数,这样会有一个物体位置预测占据图像中心。因此在本文网络结构中,特征金字塔有3层,其特征层大小对应不同大小的RPN网络格子,分别为13×13、26×26、52×52,每层的每个格子有3种不同长宽比的anchor box以及每个长宽比有3种角度的预设,这样每个网格将产生9个anchor box,这些anchor box将作为神经网络的候选区域并预测其中是否有物体,同时调整预测框的位置。图5为本文加入角度锚点后RPN的示意图。

图5 角度锚点示意图Fig.5 Angle anchor point diagram
1.5 旋转矩形的交并比计算
目标之间的交并比(IOU)计算是现在主流目标检测算法中的关键步骤,主要应用于后处理阶段,是目标检测算法中测量指标mAP计算的重要参数。本文设计了一个简单且能够处理旋转矩形框的IOU算法。将要计算的两个旋转矩形的坐标按顺时针排列,然后使用由Sutherland和Hodgman提出的逐边裁剪算法找到两个旋转矩形相交的点[17]。其基本思想是将两个多边形中的一个当作窗口,将多边形关于窗口的裁剪分解为多边形关于窗口各边所在直线的裁剪。裁剪算法中的裁剪线由窗口的每条边及其延长线构成,裁剪线将平面分为可见与不可见两部分。另一个多边形每条边有两个端点s、p,按顺时针顺序排列,经过裁剪线裁剪后有四种输出情况,如图6所示。图(a)中s、p端点同位于外侧,没有输出;图(b)中s端点位于内侧,p端点位于外侧,输出sp与边界交点I;图(c)中s、p端点同位于内侧,输出p;图(d)中s端点位于外侧,p端点位于内侧,输出sp与边界交点I以及p。
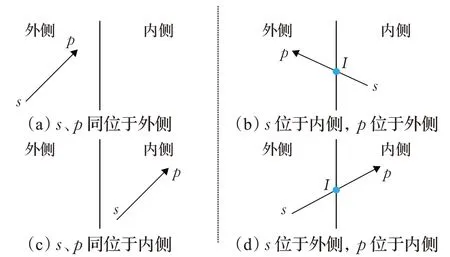
图6 多边形与裁剪线的位置关系Fig.6 Position relationship between polygon and cutting line
图7 为两个旋转矩形使用逐边裁剪算法进行裁剪过程的示意图,按照从左到右、从上到下的顺序进行裁剪。通过逐边裁剪算法得到两个旋转矩形按顺时针旋转的交点,然后对交点使用Green-Riemann定理简单高效地计算两个旋转矩形的交叉面积[18],如式(2)所示:
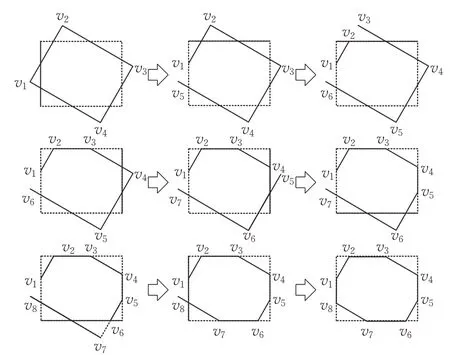
图7 逐边裁剪算法裁剪过程的示意图Fig.7 Schematic diagram of Sutherland-Hodgman cutting process
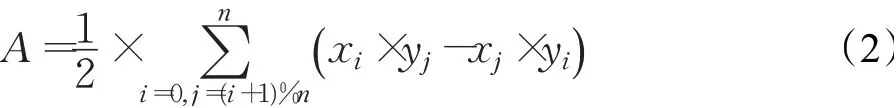
式(2)中A为两个旋转矩形的交叉面积,(xi,yi)为两个旋转矩形的交点,n为两个旋转矩形交点的数量(注:两个旋转矩形的交点按照顺时针排序)。
1.6 基于旋转矩形的非极大值抑制
本文的后处理阶段主要为非极大值抑制处理,主要针对卫星影像这种带有角度的目标物体。假设有两个同心且形状相同的旋转矩形框,保持两个旋转矩形框的角度差不变,逐渐加大两者的长宽比,两者IOU的计算值会随着长宽比的变化急剧减小;保持两个旋转矩形框的长宽比不变,逐渐加大两者的角度差,两者IOU的计算值会随着角度差的变化急剧减小。图8展示了上述两种情况。

图8 物体的角度和长宽比与IOU关系示意图Fig.8 Schematic diagram of relationship between angle and aspect ratio of object and IOU
图8 (a)、(b)、(c)中两个旋转矩形框之间都具有相同的角度差(角度为45°),但是其长宽比不同,分别为1∶3、1∶6、1∶9,三个IOU的计算值相差巨大,分别为0.308、0.134、0.085。图8(d)、(e)、(f)中两个旋转矩形框长宽比相同(长宽比为1∶6),但是其角度差不同,分别为15°、30°、45°,三个IOU的计算值同样相差巨大,分别为0.444、0.200、0.134。如果按照非极大值抑制算法设定一个阈值I,两个预测框之间的交并比计算超过这个阈值I,则过滤掉预测分数小的预测框,那么遇到图8中类似两个预测框中心离得较近且角度差极大或者长宽比极高的情况就会变得难以处理,因为两个预测框的IOU通常值很小。将阈值下调,一般需要设置一个非常小的值才可以将上述情况去除掉,但是阈值设置小的数值时又会遇到新的问题,因为卫星影像检测中往往会遇到如图9所示的情况。在图9中,红色实线框为真实物体,黑色虚线框为神经网络预测框,浅蓝的颜色区域为两个黑色虚线框交叉的面积。在阈值较小的情况下图中一些有效的检测框会被抑制掉。

图9 卫星影像检测目标预测之间的位置关系Fig.9 Position relationship between satellite image detection target prediction
本文对传统的非极大值抑制算法进行改进,通过在不同的角度差和长宽比下设置不同阈值来抑制多余的预测框,保留有效的预测框。在两个旋转框同心的情况下,保持角度差和长宽比其中一个变量,调整另一个变量,参考两个旋转矩形的交并比值大小来设置不同的阈值,并根据检测的效果不断对每个阈值进行调整。
2 实验与分析
2.1 实验数据集
本文使用3个公开的高分辨率可见光卫星影像数据集来评估模型的性能,分别是中国科学院自动化研究团队建立的High Resolution Ship Collection 2016(HRSC2016)数据集[19]、武大遥感国家重点实验室夏桂松和华科电信学院白翔一起建立的Dota数据集[20]和中科院大学高清航拍目标数据集合UCAS_AOD。
HRSC2016数据集主要由各类舰船图像组成,舰船所在场景有海面和近岸两种。数据集主要来源于Google Earth。数据集的图像从Mumansk、Everett、NewpotRhode Island、Mayport Naval Base、Norfolk Naval Base、San Diego Naval Base这6个著名港口收集。数据集图像一般分辨率为0.4~2.0 m。图像大小在300×300至1 500×900之间,大部分图像分辨率超过了1 000×600。数据使用xml格式保存图像的分辨率层级、港口信息、地理坐标、数据源、标尺信息、图像采集日期等信息。HRSC2016数据集总共有1 061张图像,通过科学的方法将其分为包含436幅图像和1 207个实例样本的训练集,181幅图像和541个实例样本的验证集,444幅图像和1 228个实例样本的测试集。
HRSC2016数据集主要数据类别为舰船,并将其分为3个等级的识别任务:(1)L1级任务,舰船检测任务,种类只有船舶一种,任务是将目标物体从背景中分离。(2)L2级任务,根据舰船用途进行划分的识别任务,将船舶分为4大类,包括军舰、潜艇、航母以及商船。(3)L3级任务,根据舰船型号进行划分的识别任务,在L2任务的基础上,将军舰和航母按照大小型号进行细致的分类,比如军舰具体细分为阿利伯克驱逐舰(Arleigh Burke)、佩里级护卫舰(Perry)、奥斯汀级船坞登陆舰(Austen)等,航母具体细分为企业级航母(Enterprise)、小鹰级航母(Kitty Hawk)以及尼米兹级航母(Nimitz)等,商船则按照用途划分为运输汽车船、气垫船以及游艇等。其位置标注信息包括矩形框:左上点(x1,y1)、右下点(x2,y2);带有角度的矩形框:中心点(xc,yc),宽w,高h,角度θ以及像素级别的分割掩膜。
Dota数据集总共有2 806张卫星图像,分为16个类别,包括飞机、集装箱起重机、船只、游泳池、储蓄罐、环形路线、棒球内场、网球场、英式足球场、直升飞机、大型车辆、桥、篮球场、小型车辆、田径场、海港,共计188 282个实例。大部分图像分辨率约为4 000×4 000,需要进行裁剪才能使用神经网络训练。其数据主要来源为卫星JL-1、卫星GF-2、中国资源卫星数据和应用中心以及Google Earth。Dota数据集中每个实例的位置采用标注4个顶点坐标的方式,可以定位不同方向和形状的四边形,4个点按顺时针方向依次排序,标注形式为(x1,y1,x2,y2,x3,y3,x4,y4)。同时每个实例还被分配类别和是否难以检测的标签。数据集使用txt格式进行保存。在数据划分上,随机将原始数据集划分为1/2、1/6、1/3作为训练集、验证集和测试集。Dota数据集的实例在各种角度方向上表现得非常平衡,通过数据集去观察实例物体时可以进一步接近真实场景,这对神经网络模型的学习训练有着至关重要的作用。在最新的Dota数据集标注还包含10像素以下的小目标实例。
UCAS数据集总共有1 510张卫星图像,包含飞机和汽车两个类别,共计14 596个实例。所有图像分辨率都为1 280×659、1 372×941、1 280×685这三种。数据集中每个实例的标注形式为(x1,y1,x2,y2,x3,y3,x4,y4,θ,x,y,width,height),带角标的(xi,yi)为旋转矩形的4个顶点坐标,θ为目标的旋转角度,(x,y)为水平边界框的左上点,(width,height)为水平边界框宽高。数据主要来源为Google Earth。数据集使用txt格式进行保存。因为原数据没有将数据集进行划分,本文将按照两个类别的实例数量1/2、1/6、1/3作为训练集、验证集和测试集。同样数据集实例的角度分布均衡。
2.2 实验结果及分析
(1)检测结果定量分析
本文通过在HRSC2016数据集、Dota数据集和UCAS_AOD数据集使用均值平均精度(mean Average Precision,mAP)来评估本文算法。表1展示了模型在HRSC2016数据集3个等级任务下每个类别的召回率、精确度和平均精度等指标,gts表示每个类别下测试数据中真实目标的数量,dets表示每个类别下模型预测此类目标的数量。模型从L1任务到L3任务mAP不断下降。先从模型预测目标的数量分析,模型在3个任务下的预测总数量为2 948、3 027、5 942。由于HRSC2016数据集上L1、L2、L3是不同等级的分类任务,三者在训练集训练的实例总数并没有改变,只是单个种类实例的数量随着种类的细分而下降,模型预测数量却急剧上升,保持了高召回率的同时却精确度快速下降,导致在L3任务上mAP大幅下降。
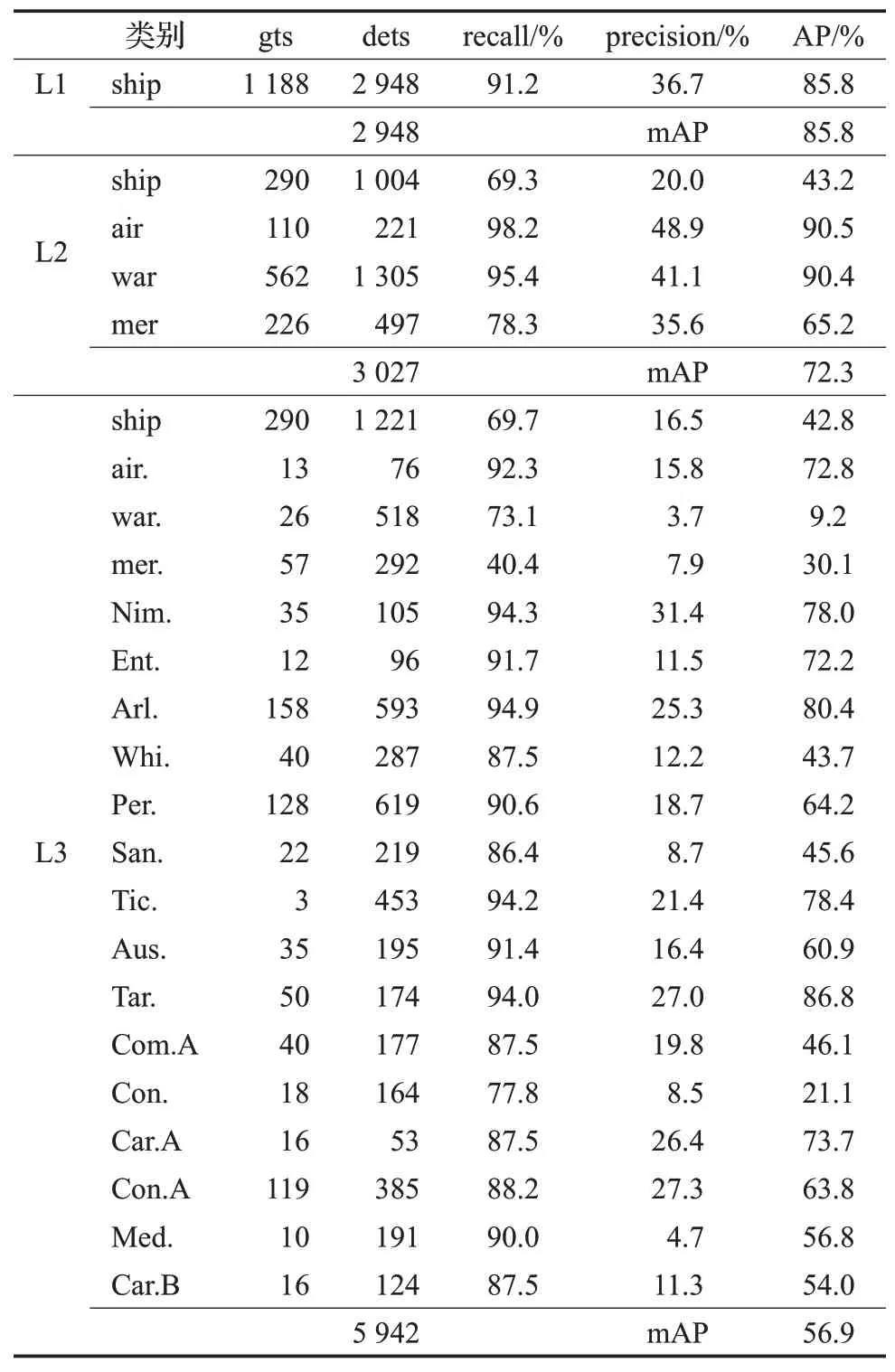
表1 HRSC2016数据集测试实验的详细结果Table 1 Detailed results of HRSC2016 data set test experiment
Dota数据集的测试结果如表2所示。结果相比于HRSC2016数据集测试的结果,其检测准确率下降,模型的mAP为38.2%。模型在Dota数据集上性能整体下降主要有三点原因:(1)Dota数据集具有很多小目标物体,10~50像素的目标占比57%,还包含10像素以下的小目标。(2)Dota数据集包含多种实例密度不同的图像,特别是有很多小目标高度聚集的图像。(3)Dota训练集各个类别的实例数量极端不平衡。

表2 Dota数据集测试实验的详细结果Table 2 Detailed results of Dota data set test experiment
为了验证单阶段网络的准确率会受到类别不平衡的影响,本文还使用类别实例数量较为平衡的UCAS_AOD数据集进行对比验证,表3展示了其详细的实验结果,模型的mAP为92.1%。结合表4中3个训练集每个类别实例数量的统计,发现UCAS_AOD训练集两个类别的实例数量分布平衡,模型检测效果最好,HRSC2016训练集L1任务到L3任务,每个类别实例数量差异变大,检测效果从高到底,Dota训练集中实例数量差异最大,最高类别实例数量与最低类别实例数量之比约1 000∶1,模型检测效果最差。
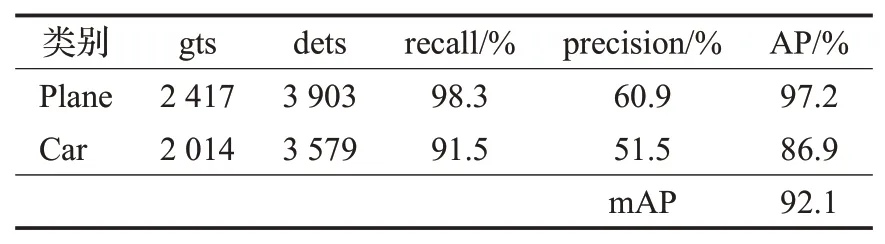
表3 UCAS_AOD数据集测试实验的详细结果Table 3 Detailed results of UCAS_AOD data set test experiment

表4 训练集每个类别的实例数量统计Table 4 Statistics of number of instances of each category in training set
(2)可视化检测结果
图10 和图11展示了算法改进前后使用非旋转矩形候选框和旋转矩形候选框的检测效果。图10为HRSC2016数据集的3个识别任务的检测结果,图11为Dota数据集和UCAS_AOD数据集的检测结果。图10中从左到右3列分别为L1舰船检测任务、L2舰船种类识别任务、L3舰船型号识别任务。

图10 HRSC2016数据集检测结果对比图Fig.10 Comparison chart of HRSC2016 data set test results

图11 Dota和UCAS_AOD数据集检测结果对比图Fig.11 Comparison chart of Dota and UCAS_AOD data set test results
图10 (a)、(b)和(c)分为两行,第一行为使用非旋转矩形候选框的检测结果,第二行为使用旋转矩形候选框的检测结果。图11中左列为使用非旋转矩形候选框的检测结果,右列为使用旋转矩形候选框的检测结果。在目标背景简单以及目标为单个情况下,旋转矩形框和非旋转矩形框在可视化效果方面较为相同,如图10(a)和(b)所示。当物体相邻较近或者相互挨着的情况下,如图10(c)和图11所示,旋转矩形框标定的图像更为清晰,可以帮助工作人员快速定位目标并分析处理数据。非旋转矩形框标定的图像会存在几点问题:大物体预测框囊括相邻小物体预测框的问题,相邻物体间预测框相互覆盖和重叠的问题,以及一个预测框覆盖多个实例的问题,这对快速发现目标物体的位置信息影响较大,特别是当较小物体排布特别紧密时,大量重叠的预测矩形框会遮挡小目标物体。综上所述,在可视化效果方面,基于旋转矩形框检测识别的效果更好,因为旋转矩形框更贴合卫星图像目标,而非旋转矩形框则在预测旋转目标的同时还会覆盖多余的区域,如果遇到目标物体密集度非常高且目标物体处于多角度的场景时,非旋矩形框标定的图像显得特别杂乱。
(3)与其他算法的比较
使 用Faster R-CNN[4]、Cascade R-CNN[21]、SSD[9]、YOLOv3[8]以及本文改进方法进行对比,结果如表5所示。

表5 不同算法的检测结果对比Table 5 Comparison of detection results of different algorithms
由表5、图10和图11可见,改进的YOLOv3算法与原YOLOv3相比,时间上由于引入旋转检测框,导致平均检测时间稍长0.002 6 s,但是在3个数据集的5个任务上平均mAP提高了0.8个百分点,可视化效果更好。两阶段方法Faster R-CNN和Cascade R-CNN检测准确率更高,但是本文改进的方法检测速度是两者检测速度的10倍、25倍。而SSD算法无论在检测精度还是检测速度上都较差。因此,本文改进的YOLOv3算法在实时性及检测精度上达到了较好的平衡,可视化效果更佳。
3 结束语
本文设计了基于旋转矩形空间的单阶段卫星影像目标检测模型,使用多种方法对其进行改进,是本文的主要工作内容。使用残差网络结构和特征金字塔网络结构相结合的方式提取特征。针对实例角度会随着图像缩放而改变的现象,对角度标签在输入网络时进行了预处理,使角度符合缩放后实例的实际情况。提出了两种旋转框坐标用于网络回归的设计,添加角度锚点到先验框中,优化了目标函数。使用逐边裁剪算法和Green-Riemann定理计算旋转矩形的IOU值,并针对卫星影像提出了基于旋转矩形空间的非极大值抑制算法。
但本文工作还存在不足,单阶段检测模型如果遇到种类实例数量不平衡的数据集,检测准确率会降低,接下来还需要克服这方面的影响。本文基于旋转矩形的非极大值抑制算法,虽然效果比传统的非极大值抑制算法可视化效果好,但是需要人工按照不同的情况去精细设置多个不同角度和不同长宽比下的NMS阈值,朝着自适应化的方向改进算法同样是值得研究的重点。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
沈阳理工大学学报(2019年4期)2019-09-13
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
科学与技术(2019年3期)2019-03-05
今日农业(2017年4期)2017-12-22
中学生数理化·八年级数学人教版(2017年4期)2017-07-08
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
通信技术(2011年10期)2011-08-11
