
基于近邻成分分析的WebShell特征处理算法研究
2021-08-19 10:57周爱君努尔布力肖中正
计算机工程与应用 2021年16期
周爱君,努尔布力,艾 壮,肖中正
1.新疆大学 信息科学与工程学院,乌鲁木齐830046
2.新疆大学 网络中心,乌鲁木齐830046
随着互联网的快速发展,Web应用系统越来越多,这也进一步滋生了黑色产业。黑客通过入侵网站,在网站植入大量的广告推广页面或者其他链接,这无形中增加了网站性能风险,对用户造成使用隐患。国家互联网应急中心(National Internet Emergency Center,CNCERT)发布的《2019年上半年我国互联网网络安全态势》中指出,CNCERT监测到我国境内有2.6万个网站被恶意植入后门,近4万个网站被篡改。根据Internet Live Status 2018年1月的数据[1],全球每天大概有100 618个网站被攻击。360发布的《2017中国网站安全形势分析报告》指出360网站卫士拦截漏洞攻击中,WebShell排第二位,拦截高达21 615.1万次。由于WebShell能够实现对各种关键功能的远程访问,如执行任意命令查看和修改任意文件、提升访问权限、发送垃圾邮件等,黑客通常会通过在网站植入WebShell,达到植入广告、篡改页面、控制Web服务等目的,因此WebShell的检测及查杀就显得尤为重要。WebShell常常隐藏在正常网站文件下,针对不同的网站编写方法其检测方法存在差异。W3Techs在2020年4月的调查报告中显示,php是网站编写中最常用的语言,使用率高达78.3%。本文考虑对php编写的WebShell展开研究。
常见的WebShell检测方法主要分为静态检测和动态检测。由于动态检测是通过检测代码执行过程中的流量变化、系统指令等敏感行为特征实现WebShell检测的,且该方法系统资源占用大,检测周期长,无法实现大批量检测,甚至会对Web系统性能造成影响,本文考虑从静态检测方法展开研究。目前针对WebShell的静态检测方法主要专注于分类器的优化,而针对WebShell特征指标模型的研究相对较少。WebShell和普通Web页面特征几乎一致,容易逃避传统防火墙和杀毒软件的检测。随着各种反检测特征混淆隐藏技术应用到WebShell上,使得WebShell的检测难度进一步增加。传统基于特征码匹配的检测方式很难及时检测出新的变种。为避免WebShell中的加密、压缩及混淆问题,通常将问题转化为对WebShell编译结果层opcode序列的研究。WebShell的opcode序列特征向量维度非常高,容易出现“维度灾难”问题,因此寻求最具代表性的WebShell特征子空间有助于进一步提高WebShell检测性能。
为了提高检测模型的准确率,需要更好地利用样本之间的联系,本文考虑将近邻成分分析[2]应用到WebShell特征处理过程中,通过样本学习一种有效的距离测度方式,更好表示样本间的相似度。近邻成分分析的目的就是针对特定任务,根据样本学习一种使得分类损失最小的距离测度方式,更好地表示样本间的某种相似度。近年来,基于近邻成分分析的特征处理方法已经在很多领域得到成功应用,包括语音识别、人脸识别等。借鉴其他领域,本文将近邻成分分析应用到WebShell特征处理过程,实验证明,相比传统的WebShell静态检测方法,该算法的检测效率、正确率更高,同时也能以一定概率检测出新型的WebShell。
1 相关工作
互联网中网页恶意代码攻击网络事件给众多的浏览用户带来了极大的危害,Web安全形势变得越来越严峻,基于此种环境,国内外的学者们针对网页恶意代码的检测方法进行了深入的研究。
1.1 WebShell特征处理研究现状
2012年胡建康等人[3]提出基于决策树的WebShell检测方法,选取最长单词、加解密函数、字符串操作、文本操作等16个特征作为分类方法,利用决策树算法进行判断,检测的效率及准确率都比较高,但召回率还有提升的空间。Hagen等人利用统计学的方法,使用信息熵、最长单词、重合指数、特征码、文件压缩比五种方法编写了NeoPi[4]这款检测工具,依据以上五个指标能发现可疑文件,但没有给出相应阈值判断文件是否为混淆文件。2014年Truong等人[5]利用统计学方法对WebShell使用的函数,比如恶意函数、命令执行函数等,对这些函数出现的频率进行统计,根据统计分类来判断是否是WebShell。2015年王超[6]通过使用针对WebShell监测的解析引擎,解析WebShell的行为,建立恶意行为库,以此来分析是否为WebShell,但这类检测方式需要大量的资源,部署实施难度较大;同年叶飞等人[7]提出基于支持向量机的WebShell黑盒检测方法,通过分析WebShell的HTML特征,使用支持向量机(Support Vector Machine,SVM)方法进行检测;2015年朱魏魏等人[8]提出基于NN-SVM的WebShell检测方法,该方法是在NeoPi的6个特征的基础上,使用NN-SVM算法进行检测。2016年Thornton[9]开发了WebShell detector,由于其使用了非常多的特征库,对WebShell检测的准确率很高,但对混淆加密的准确率有待提高。2016年胡必伟[10]提出基于贝叶斯理论的WebShell检测方法,该方法通过分析混淆加密的WebShell与正常WebShell的区别,再使用朴素贝叶斯分类进行检测。2017年Tian等人[11]结合行为分析,检测WebShell的通信特征,并测试不同的机器学习算法,最后利用Word2Vec进行文本特征提取,使用卷积神经网络(Convolutional Neural Network,CNN)方法进行训练检测。2018年贾文超等人[12]提出采用随机森林改进算法的WebShell检测方法,该方法通过对比不同类型WebShell的特征构建特征库,根据度量Fisher比对特征进行分类划分,以此来提高决策树的分类强度。
综上所述,基于静态WebShell检测有各自的优点,也存在各自的不足,不难发现关于WebShell的特征研究,大多数停留在统计特征和脚本内容特征层面。随着WebShell检测工具的性能提升,攻击者经常使用混淆加密的方法隐藏WebShell以躲避检测。opcode是php脚本编译后的中间语言,类似Java的ByteCode,机器通过opcode获悉执行指令,处理提供的数据。由于opcode只关心操作指令,不关心函数名、定义等,可以有效地检测一些加密、混淆的代码。本文为解决混淆加密技术导致的检测准确率低的问题,将从WebShell编译结果层opcode序列展开研究。
1.2 近邻成分分析研究现状
特征空间中学习距离度量可以极大地提高分类器的性能,在实际应用中具有重要意义。近邻成分分析就是一种与KNN相关联的距离测度学习算法,通过最大化训练数据中留一法(Leave One Out,LOO)分类精度来搜索线性变换矩阵,利用得到的低秩矩阵,将高维训练数据嵌入低维空间。这种方法已经被应用在许多领域,例如文本分类、语音识别和面部识别。
刘丛山等人提出k近邻元分析分类算法k-NCA,通过引入k近邻思想实现文本分类器功能[13]。Nguyen等人提出了一种新的人脸识别距离度量学习方法——间接邻域成分分析(Indirect Neighborhood Component Analysis,INCA)。INCA是一次性相似性学习和近邻成分分析方法的结合,测试发现即使在非常低的维度上也能取得较好的结果[14]。Wang等人为可靠识别嘈杂的人脸图像,引入一种新颖的空间平滑正则化器(Spatially Smooth Regularizer,SSR)改进了快速邻域成分分析(Fast Neighborhood Component Analysis,FNCA)模型,从而建立了具有更高识别精度的FNCA-SSR模型[15]。Ferdinando等人探讨了使用近邻成分分析(Neighborhood Component Analysis,NCA)进行降维处理能增强心电图(Electrocardiogram,ECG)对三种类型的情感识别性能[16]。Singhmiller等人将近邻成分分析方法应用于语音识别器中的声学建模,将高维声学表示投影到低维空间中,提高了最近邻分类器的分类精度[17]。Jin等人提出的具有NCA特征的增强树模型能够有效预测阿尔茨海默氏病不同阶段,优于主成分分析(Principal Component Analysis,PCA)、序列前向选择(Sequential Forward Selection,SFS)等特征选择策略[18]。Malan等人将正则化近邻成分分析的特征选择算法应用于运动图像的脑机接口信号分析中,增强了运动图像信号的分类性能[19]。李雪晴等人提出基于近邻元分析的半监督流行学习算法能够充分利用样本点的标签信息[20]。Wang等人基于NCA提出一种新颖的贝叶斯度量学习算法,该算法在小型数据集或有错误标签的训练集中可学习可靠的度量标准[21]。
本文提出一种静态的基于近邻成分分析的WebShell特征处理方法,以字节码向量库作为样本特征,使用近邻成分分析算法构建opcode向量库的低维测度空间,为样本创造最佳分类距离。为避免NCA过于依赖总体训练样本,使用同样根据距离作为分类标准的ReliefF特征选择方法,从局部邻域相似度的角度进一步优化特征提取性能,提高分类器检测能力。
2 基于近邻成分分析的WebShell特征处理算法流程
不同于其他的WebShell特征处理方法,本文提出一种静态的基于近邻成分分析的WebShell特征处理算法,使用WebShell的opcode序列特征,适合于不同种类的WebShell,且能够有效避免混淆加密对检测的干扰。另外,使用近邻成分分析算法能够在完成最大化分类准确率任务的同时实现特征降维,不仅能解决因opcode序列特征向量维度过高引起的“维度灾难”问题,还能提升分类准确率。ReliefF算法的加入,可以进一步精简特征,确保处理后的特征具有较高的类别区分能力,达到提高WebShell检测结果的准确率的目的。
本文基于近邻成分分析的WebShell特征处理算法的设计思路如图1所示。WebShell特征处理分为两个阶段,php脚本处理和opcode文本向量处理。php脚本处理主要包括php去重,提取opcode操作码,生成opcode文本向量。为避免重复样本对训练模型造成影响,采用MD5对收集到的php文件进行去重,删除冗余文件。opcode是操作码的缩写,一条指令可以包含一个或多个操作码。本文使用插件VLD进行源码和opcode的转换,将去重后得到的每一个php脚本经过词法分析、语法分析、静态编译过程后最终得到一个opcode序列,如图2所示。采用正则表达式的方式对齐opcode所在列,按序将每一个opcode保存下来。分别提取正样本和负样本的opcode序列,将结果分别保存在两个文件下以便后续数据处理。为有效利用opcode序列的上下文关系,突出opcode序列片段的重要性,本文采用N-gram模型生成opcode词袋。N-gram算法将一个语料片段出现的可能性归结于它之前的n个语料片段,将opcode序列库中所有的opcode序列分割成长度为n的语料片段,构成opcode词袋。考虑到opcode序列片段在单个php脚本及整个php数据集中的重要程度,采用TF-IDF为opcode词袋构建所需文本向量库。TF-IDF算法通过词频(Term Frequency,TF)和逆向文件频率(Inverse Document Frequency,IDF),即某一个opcode序列片段在给定某一php脚本对应的opcode序列中出现的次数,和该序列片段在所有php脚本对应的opcode序列中出现的频率,来衡量一个opcode序列片段的重要性。

图1 算法流程图Fig.1 Algorithm flow chart
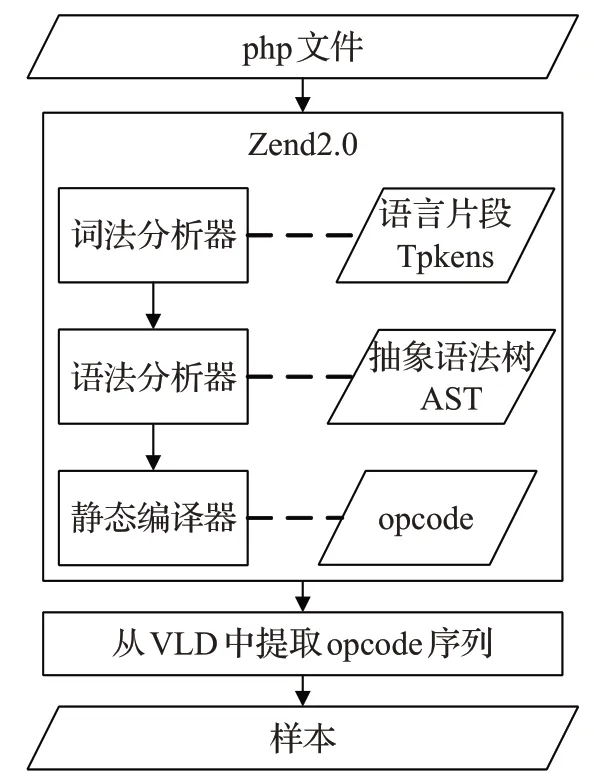
图2 opcode提取过程Fig.2 opcode extraction process
opcode文本向量处理阶段,主要解决opcode文本向量出现的“维数灾难”问题。本文为避免样本不均衡问题采用smote上采样增强训练样本。近邻成分分析是2005年Hinton等人提出的一种度量学习方法[2],目的是采用自适应的方法学习一个使KNN分类正确率尽可能高的距离度量,在距离学习过程中完成高维向低维的转化。本文利用NCA可以获得一个使得分类正确率高的低维空间。为进一步加强低维空间下特征的分类能力,缓解NCA过于依赖总体训练样本,忽略局部信息带来的问题,本文借鉴了ReliefF计算近邻距离评估特征分类价值的方法。对低维空间下的特征按照权重大小排序,找出最具类别区分能力的特征作为KNN分类器的输入,预测模型分类结果。基于使用近邻成分分析算法完成opcode文本向量处理这一过程在文中简称为NCA_ReliefF。NCA_ReliefF主要分为两部分:构建低维空间和特征选择。NCA_ReliefF通过最大化训练集的留一法识别精度期望来学习变换矩阵,以完成低维空间的构建,通过比较特征权重完成特征选择。
2.1 NCA_ReliefF算法流程描述
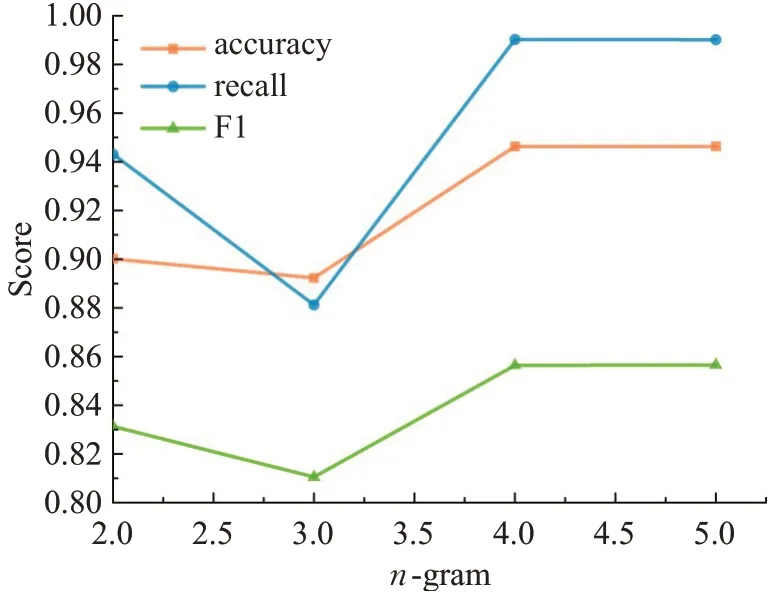
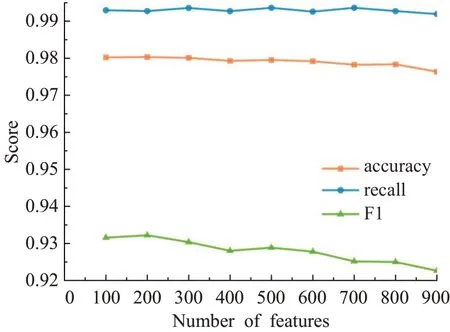
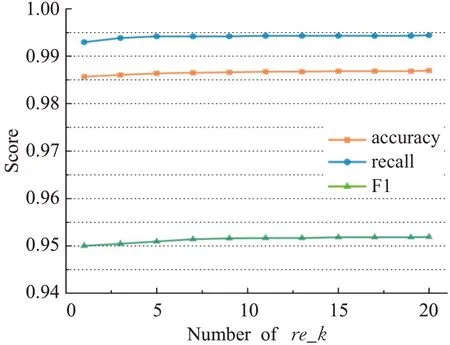
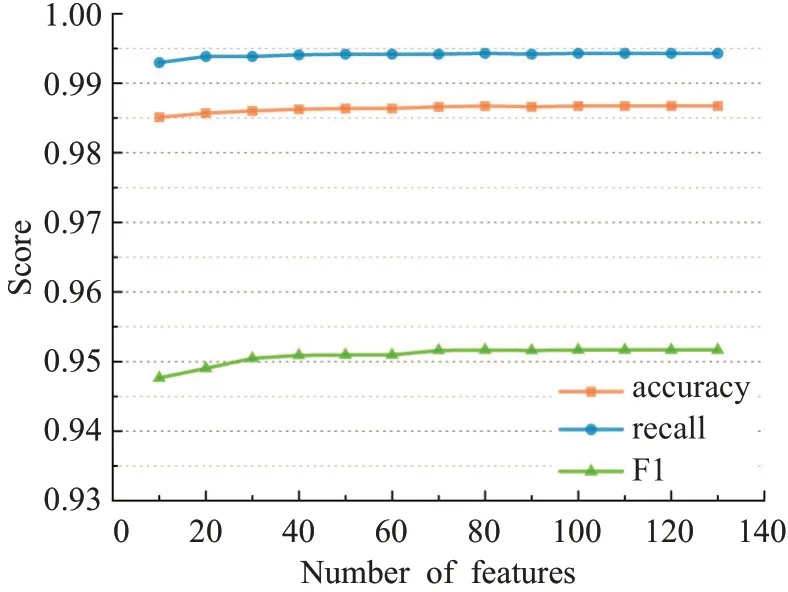
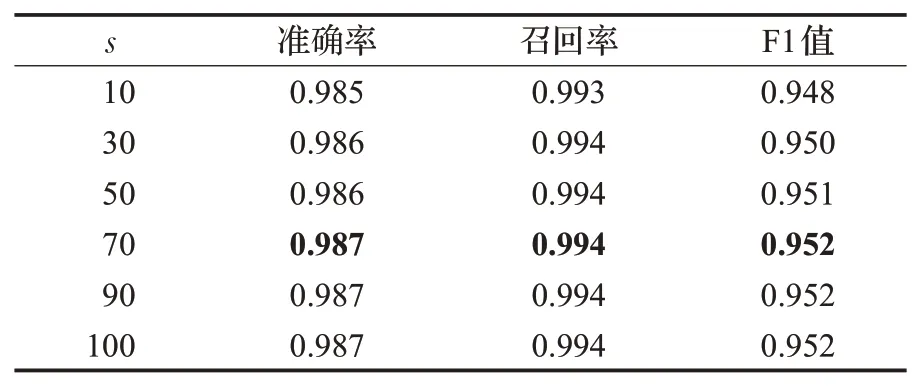
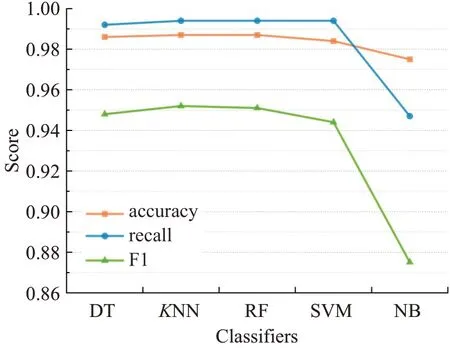
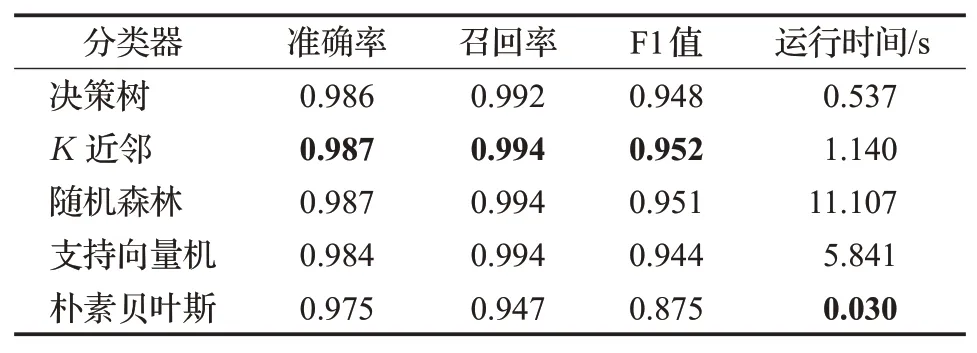
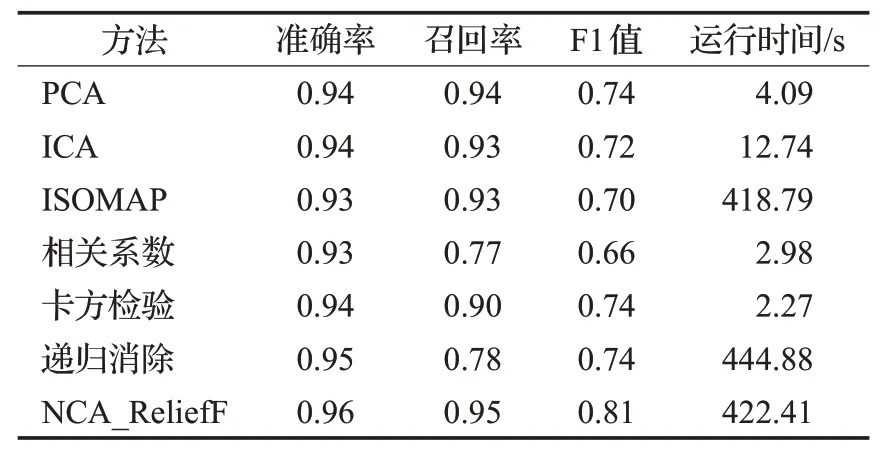
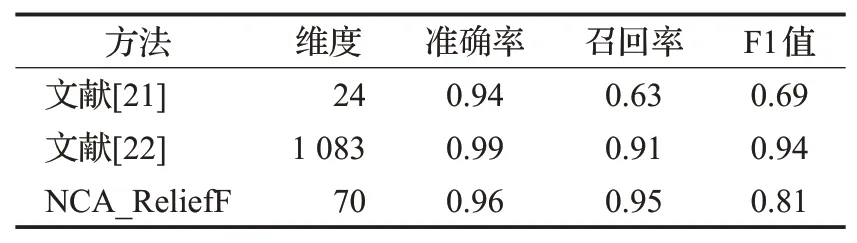
输入:训练数据集Xn×D,NCA特征提取保留的特征数量d(目标维数),ReliefF抽样次数m,邻居个数re_k,最终特征保留数量s,s 步骤1对训练数据集Xn×D进行NCA特征提取,迭代次数选择默认值100,返回低维矩阵Ad×D; 步骤2将训练数据集Xn×D嵌入低维空间中,返回数据集 步骤3从Xn×d中随机选择一个样本,找出re_k个同类近邻样本和re_k个不同类近邻样本; 步骤4更新每一个特征α的权值Wα; 步骤5重复步骤3~步骤4过程m次,返回特征权重向量W; 步骤6根据特征权值对特征进行从大到小排序。 输出:输出权值最大的前s个加权处理过的特征矩阵 步骤1和步骤2的目的是利用NCA算法迭代计算出一个低维矩阵Ad×D,将训练集Xn×D由原本的D维空间转化为d维(D>d),进而避免因“维数灾难”导致的检测准确率不高的问题;步骤3~步骤5的主要工作是利用ReliefF特征选择方法计算出d维空间下各个特征对分类标签的重要程度,最终得到一个长度为d的特征权重向量W;步骤6描述特征再选择过程,先对权重向量W进行排序,再筛选出前s个分类价值最大的特征,以确保特征矩阵的输入对分类结果有积极影响。 近邻成分分析(NCA)算法采用迭代的方式自动化完成距离矩阵的测度学习,也是在这个过程中完成降维。给定n个带标签的样本(x1,x2,…,xn)∈RD,相对应的类标为C1,C2,…,Cn。人们希望获得使最近邻分类效果最优的低维矩阵。由于数据的真实分布情况处于未知状态,将问题转化为求训练数据上的留一化效果最优。限定马氏距离变换矩阵Q是一个对称半正定矩阵,即Q=ATA,那么两个样本之间的马氏距离为: 式中,pij表示样本点xi随机选择另外一个样本点xj为近邻,且最终xi继承xj标签Cj的概率。那么,将样本点xi正确分类的概率为: 其中,Ci={j|Ci=Cj}。目标函数要使得正确分类点的数目最大,因此定义为: f(A)是一个连续可微的矩阵函数,算法就是要最大化目标函数。由于这是一个无约束优化问题,使用收敛速度快,内存消耗小的梯度下降算法LBFGS求出A。其梯度表达式如式(5)所示,其中xij=xi-xj。 最大化目标函数f(A)等同于最小化真实类别分布和随机类别分布之间的L1范数。当A是d×D的非方阵,便可将样本降到Rd空间。从NCA算法理论上看,其计算成本主要取决于最优化过程的梯度计算,即式(5),每一次迭代的计算复杂度为O(dDn2),由此可知,当数据集过大时,该算法的计算效率较低。由于参照样本是随机选择的,在分类时很难体现局部信息的优势,易导致分类结果不理想。 为缓解NCA过于依赖总体训练样本,忽略局部信息带来的问题,使用ReliefF计算各个特征权值。ReliefF算法中特征和类别的相关性是基于特征对近距离样本的区分能力。从训练集中随机选择一个样本xi,从和xi同类的样本中寻找最近邻样本H,从和xi不同类的样本中寻找最近邻样本M,若xi和H在特征∂上的距离小于xi和M上的距离,则说明特征∂对区分同类和不同类起正面作用,则增加特征∂的权重;反之,则降低特征∂的权重。将该过程重复m次,最后得到各个特征的平均权重。ReliefF算法伪代码如下所示。 算法ReliefF 输入:训练集Xn×d,抽样次数m,最近邻样本个数re_k。 输出:d个特征的特征权重W。 步骤1置所有特征权重为0,W为空集。 步骤2fori=1 tom 从Xn×d中随机选择一个样本xi; 从xi的同类样本中找到re_k个最近邻Hj,从不同类样本集中找到re_k个最近邻Mj(C),j=1,2,…,re_k; 步骤3forα=1 tod(all features) End Return当前特征权重向量W 步骤3是ReliefF算法的核心部分,其中diff(∂,xi,Hj)表示计算样本xi和最近邻同类样本Hj在特征∂上的差,如式(6)所示: diff(∂,xi,Mj(C))表示计算样本xi和最近邻非同类样本Mj(C)在特征∂上的差,Mj(C)表示类C∉class(xi)中第j个最近邻样本。p(C)表示出现样本标签为C的概率,p(class(xi))表示出现样本和xi同类的概率。WebShell检测是二分类问题,此时: 将步骤3重复m次,最后输出各个特征的平均权重。特征权重越大表示该特征分类能力越强,特征权重越小表示分类的能力越弱。通过对权重排序可将相关性强的特征保留,去除不相关的特征。 综上,ReliefF能够利用邻域衡量各特征和类别的相关性,有效找出具有类别区分能力的特征。ReliefF算法的运行时间与样本的抽样次数m、特征数量d、样本数量n相关,可得出结论,ReliefF的计算复杂度为Θ(dmn)。 本文将经过NCA特征提取得到的矩阵Ad×D作为变换矩阵,通过计算样本Xn×D在空间Ad×D中的投影,得到一个d维空间的样本Xn×D。将Xn×D作为ReliefF的输入,此时ReliefF计算Xn×D中d个特征的权值,得到权重向量W。为增加局部信息的效能,对特征进行重新筛选,最终可得到一个s维的样本,至此便完成了对整个数据集的预处理。为验证特征处理的有效性,提高模型对WebShell的检测性能,选择准确率、召回率作为评价指标。 本实验所用的计算机配置如下Intel®CoreTMi3-3227U CPU@1.9 GHz,8.00 GB内存,软件开发环境为Windows10,编程语言是Python3,主要调用机器学习库Sklearn。本文所使用的数据集,由Github收集项目经过MD5去重筛选后得到,由566个恶意WebShell和5 378个正常php脚本构成,如表1所示。随机选取样本集中80%样本作为训练集,用于生成检测模型,剩余数据作为测试集,用于检测模型的测试。 表1 WebShell样本Table 1 WebShell sample 将去重后得到的php文件进行opcode编码,每一个php文件经过编码后得到一个opcode编码串。用TFIDF构建词向量模型,计算该词组TF-IDF值,得到编译结果层基于opcode序列的词频矩阵,将其作为特征向量。为提高整个模型的运行效率,选取出现频数最高的1 000个片段生成词袋模型,通过五折交叉验证发现opcode序列片段长度n∈[]2,4时,分类准确率和召回率均超过95%,如图3所示。 图3 语法模型参数选择Fig.3 Syntax model parameter selection 实验中,将WebShell标记为1,正常样本标记为0。分类结果混淆矩阵如表2所示。本文采用准确率、召回率、F1值3个指标评估特征选择方法性能。 表2 分类结果混淆矩阵Table 2 Confusion matrix of classification results (1)准确率(acc):所有被正确判断类别的测试样本数量与测试样本数量的比值。 (2)召回率(rec):所有被正确判断为正常事件数量与所有正常事件数量的比值。 (3)F1值:分类问题的一个衡量指标,是精确率和召回率的调和平均数,能够反映检测的综合效果。 实验参数一共有4个,NCA降维空间维度d、ReliefF迭代次数m、ReliefF邻居个数re_k和ReliefF的特征保留数量s。 NCA与ReliefF在计算过程中都采用了距离度量,在参数选择过程中,本文选择KNN分类器来衡量模型的检测效果。近邻计算中若k值选择过小,得到的近邻数过少,不仅会降低分类精度,也会放大噪声数据的干扰;而如果k值选择过大,对于训练集中数据量较少的异常样本在选择k个近邻的时候,容易将并不相似的数据包含进来,造成噪声增加,导致分类效果的降低。本文采用五折交叉验证选取恰当的k值,选择k=5,在此情况下,KNN分类的召回率较高。 NCA降维过程中,提取的特征数量对最终分类结果有很大影响,模型仅需少量的样本就可以得到较高的预测准确率。理想状态下,期望选择尽可能少的子特征,同时保证模型的效果不会显著下降,类别分布尽可能地接近真实的类别分布。实验对比了保留100维,200维,…,900维情况下的分类性能,如图4所示。实验表明,当提取特征为200时,分类准确率、召回率均超过98%,F1值超过93%。在此基础上增加提取数量时,F1值明显下降。为保证模型效果的前提下,最终选择提取200个特征,d=200。 图4 NCA特征提取数量对分类性能影响Fig.4 Influence of number of NCA feature extractions on classification performance 为进一步降低存储空间,提高分类速率,采用ReliefF特征选择方法进一步约减特征空间,获得最优子空间。ReliefF算法的参数m、re_k、s的确定如下: (1)m值的实验测定。s固定为100时,m取值范围[1,1 000],从中均匀取出10个值,统计准确率、召回率、F1值。其中m=100时,准确率、召回率、F1值都超过了95%,召回率高达99%。 (2)re_k值的实验测定。固定已经选择的m值为100,n固定为100时,选取re_k=1,3,…,19等10种情况,如图5所示。re_k对检测结果的影响较小,当近邻数量为9时,分类效果最佳,如表3所示。在此基础上继续增加近邻数量,re_k=11时,检测效率无显著提升。 图5 ReliefF近邻数量对分类的影响Fig.5 Influence of number of ReliefF neighbors on classification performance (3)s的实验测定。固定选择好的m=100,re_k=9时,选取s=10,20,…,130,如图6所示。统计准确率、召回率、F1值,结果如表4所示。分类性能随着特征选择数量的增加逐渐稳定,当s=70时,达到分类性能最佳,如表4所示。 图6 特征数量s对分类的影响Fig.6 Influence of number of features s on classification performance 表4 特征数量s对分类性能的影响Table 4 Influence of number of features s on classification performance 综上,ReliefF参数已确定,迭代次数m=100,邻居数量re_k=9,特征保留数量s=70。在这组参数设置下,可将原本1 000维的空间缩小至70,且达到的分类效果最佳,准确率和召回率均超过95%,将该70维的子空间视为最优子空间。 现从准确率、召回率、F1值、运行时间四方面对基于决策树(DT)、K近邻(KNN)、随机森林(RF)、支持向量机(SVM)、朴素贝叶斯(NB)五种分类器进行比较,结果如图7所示。 图7 不同分类算法对WebShell检测性能的影响Fig.7 Influence of different classification algorithms on WebShell detection performance 在不同的评价标准上,有的分类器在某一方面表现非常优秀。由表5所示,K近邻和随机森林在准确率、召回率和F1值方面表现较佳,但考虑运行效率,基于KNN算法的WebShell检测方法更有优势。 表5 不同分类算法对WebShell检测性能的影响Table 5 Influence of different classification algorithms on WebShell detection performance 本文提出的NCA_ReliefF特征处理方法能有效检测WebShell样本,且在一定程度上解决了NCA特征选择方法易忽略局部信息的问题。实验对比了文本向量特征、单独使用NCA算法、单独使用ReliefF算法和采用NCA_ReliefF算法四种处理特征方法对WebsShell检测模型的影响。由表6可知,NCA_ReliefF综合了NCA和ReliefF两种算法的优点,在保证准确率的同时提高了召回率,准确率达到96%,召回率达到95%。 表6 特征处理方法对比结果统计Table 6 Comparison results statistics of feature processing methods 特征降维方法分为特征选择和特征提取两种,目前常用的特征提取方法有主成分分析(Principal Component Analysis,PCA)、独立成分分析(Independent Component Analysis,ICA)、等距特征映射(Isometric Mapping,ISOMAP)。常用的特征选择方法有互信息、相关系数、卡方检验。表7对比了特征维度保持在70维时,不同特征处理方法的检测效果。由表可知,特征提取的三种方法的召回率和准确率均超过93%,其中PCA耗时最短,仅需4 s。特征选择的三种方法在召回率上表现欠佳,不超过90%。其中卡方检验耗时最短,运行时间不超过3 s。本文提出的NCA_ReliefF特征处理方法在准确率、召回率和F1值上都优于以上特征处理方法,但其运行时间较长。 表7 常见特征处理方法的检测结果统计Table 7 Test results statistics of common feature processing methods 表8 对比了最新提出的WebShell检测模型,即基于多层感知器的检测模型[22]、组合层面基于Fisher特征选择和随机森林的检测模型[23]和本文基于近邻成分分析的检测模型。三种模型都是基于编译结果层完成检测任务。综合对比,基于多层感知器的检测模型能得到一个维度小的子空间,缩短了模型检测时间,但准确率和召回率均低于95%。组合层面基于Fisher特征选择和随机森林的WebShell检测模型整体性能最佳,其准确率和F1值均超过94%,但其特征数量较大,数据存在冗余,增加了模型的计算量。理想的WebShell检测模型是准确找出所有的异常样本,其对召回率的期望值较高。本文提出的基于近邻成分分析的检测模型NCA和ReliefF方法的结合,在保证准确率的同时能有效提高WebShell检测的召回率。 表8 各种模型检测结果统计Table 8 Test results statistics of various models 本文为解决WebShell样本的特征维度过高、检测效果差的问题,提出了一种基于近邻成分分析算法的WebShell特征处理算法。该算法从源码编译结果层出发,通过NCA自动化学习字节码序列特征的投影矩阵,在保留全局信息的同时完成高维特征空间的约减。为避免过于依赖总体训练样本,采用ReliefF特征选择方法从局部信息的角度进一步优化特征处理性能。实验结果表明,该算法能够减少数据维数,且在保证准确率的情况下,有效提高WebShell检测的召回率。由于NCA降维算法采用留一验证法,计算成本较大,如何减少NCA时间复杂度,是下一步的研究重点。2.2 近邻成分分析
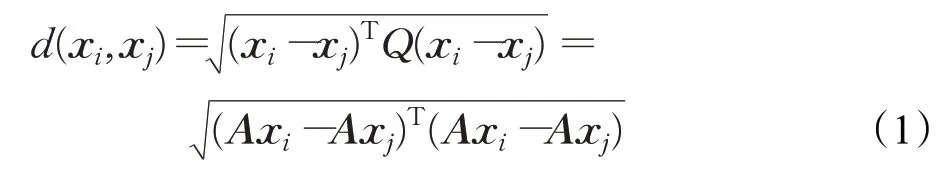
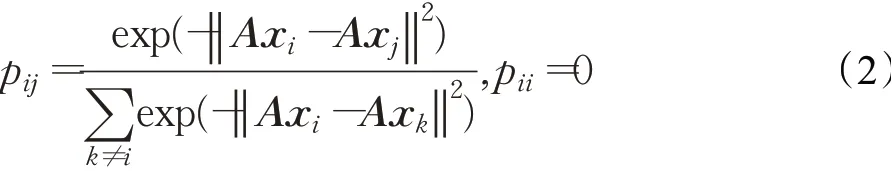

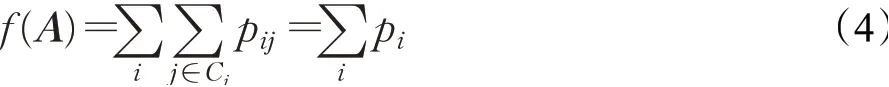

2.3 ReliefF算法

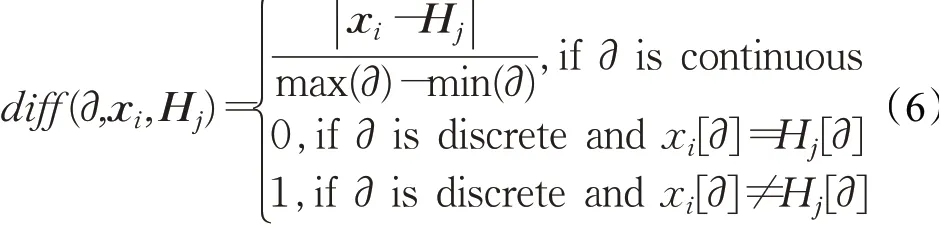
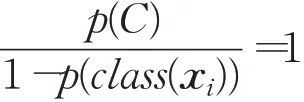
3 实验结果及分析
3.1 实验数据

3.2 评估准则




3.3 参数选择
3.4 实验结果及分析

4 结束语
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中国交通信息化(2018年5期)2018-08-21
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
电子制作(2017年23期)2017-02-02
西北工业大学学报(2015年4期)2016-01-19
