
基于深度残差网络的驾驶行为识别
2021-08-19 08:15武文博
数字技术与应用 2021年7期
武文博
(广西科技大学电气与信息工程学院,广西柳州 545616)
0 引言
约束和规范司机驾驶行为作为提高驾驶安全性的必经之路,是道路交通安全和车辆驾驶安全的关键所在。随着我国经济水平和生产力的高速发展,国民生活水平得到较大提升,民用车辆保有量逐年上升。国家统计局发布的统计数据显示2020年全国民用汽车保有量比上年末增加1937万辆,其中私人轿车增长比率为6.63%[1]。如此数量的汽车保有量下,如何保障交通安全成为不可忽视的问题。当前,最新升级的交通探头可以识别驾驶员的安全带佩戴情况,但这单一的功能不能满足日益复杂的路况条件。通过交通警察来约束司机的分心驾驶行为效果有限,造成极大的人力浪费。随着深度学习的技术迭代与发展,学者看到了通过计算机视觉技术来识别驾驶行为的可能性。通过实时采集驾驶员的图像,借助行车电脑部署的模型,可以实现低成本、高效率的驾驶行为识别。因此,开展驾驶行为识别算法的研究,具有较强的现实意义与应用价值。
1 相关工作
在计算机视觉研究初期,学者通过机器学习的算法来完成识别和分类任务[2-4],这要通过手动计算和提取图像特征如HOG特征等,并需要结合相应分类器如SVM、随机森林算法等完成。文献[5]通过扩展图像数据的方向梯度直方图的描述符,建立一种基于姿态基础元的行为识别算法。由于依赖人工特征提取的算法处理方式繁琐,识别响应较慢,无法达到实时性和稳定性的要求。随着卷积神经网络的提出,深度学习由于其能够自发学习特征的能力,被广泛使用在图像识别领域。在之后的研究中,Inception Net[6]、VGG Net[7]等高效的深度网络被提出,它们大幅提高了图像识别和分类的精度。文献[8]提出一种基于级联卷积网络的疲劳驾驶检测模型,通过构建多级卷积神经网络来学习人眼的图像特征,连续监测多张眼部图像数据,结合其特征点定位判断驾驶员是否疲劳。文献[9]结合遗传算法和卷积神经网络,通过定位人脸和手部来对驾驶员行为进行分类,达到84.64%的准确率。现有的驾驶行为识别算法能够识别的驾驶种类较少,多数研究关注于司机使用电话的情况。本文提出一种基于深度残差网络的识别方法,提高了模型在更多类别的行为识别任务的正确率。
2 算法设计
2.1 深度网络
在深度卷积神经网络的研究初期,学者通过不断加深网络层次来强化模型的特征提取与学习能力。文献[10]所设计的LeNet是卷积神经网络里程碑式的成果,使用卷积层、池化层和全连接层级联构建模型,网络层次较浅且结构简单,故而对于较为复杂的分类任务力不从心。LeNet未能得到广泛应用的原因是当时的计算机性能不足,而数据量在机器学习如随机向量机的承受能力之下,卷积神经网络的表现并不出色。该模型的结构如图1所示。

图1 LeNet结构图Fig.1 LeNet structure diagram
20世纪初,计算机性能爆炸式的提升对深度学习的研究进展提供了强有力的支持。2012年,Alex Krizhevsky凭借其设计的深层卷积网络模型[11]取得了ILSVRC(ImageNet Scale Visual Recognition Challenge)大赛的冠军。文中使用随机丢弃法(Dropout)将上层神经元提取的特征随机置0来阻止过拟合,同时还提出局部归一化技术LRN(Local Response Normalization)来强化网络对于特征的拟合能力。与LeNet不同的,AlexNet还将激活函数更换为ReLU函数,并且验证其性能优于sigmoid激活函数,间接地解决了深层卷积时出现的梯度消失问题。
在前期的诸多研究中,学者通过不断加深网络层数和提高网络复杂程度以达到提升模型对特征的提取能力,但这也导致梯度爆炸和消失的问题,网络虽然能够更好的提取数据特征但是却不能很好的自发学习这些特征。为了解决这一问题,文献[12]提出一种新颖的网络结构并且将运用这种结构的深度卷积网络模型命名为ResNet模型,残差模块结构如图2所示。卷积网络在训练时,每层都会产生新的特征图,而训练的目的就是让模型自发地去学习不同特征图之间的权重。通常地,一个输入a经过卷积层,形成新的输出,这就是普通映射H(a)。而对于残差模块,经过卷积后的映射就成为。相较于使用多层卷积去近似接近H(a),其效果不如去近似接近残差,如式1所示:
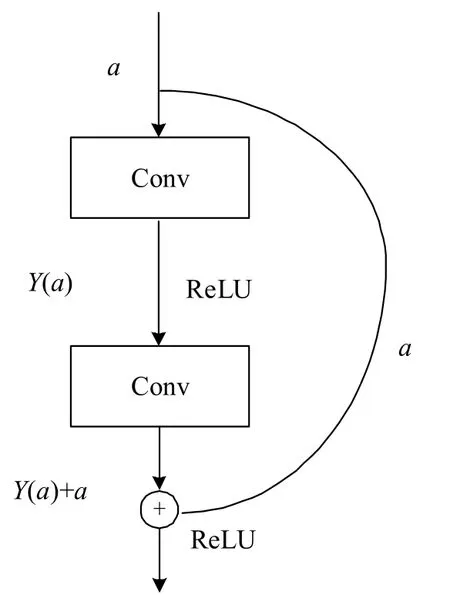
图2 残差模块结构图Fig.2 Structure diagram of residual module

2.2 基于深度残差网络的识别模型
基于上述技术背景,使用残差模块构建不同的深度残差网络模型,对比其性能以确定哪种结构的深度残差网络模型对司机行为识别这一任务的完成度较好。按照搭建的网络结构层数,分别称其为Res-34、Res-50和Res-101,其中,34和50层结构的深度残差网络使用双层残差模块而101层的深度残差网络使用三层残差模块。其网络结构描述如下:三个模型都在卷积层使用7×7的卷积核,通道数为64;其中Res-34在后续模块中的残差块数为[2,2,2,2],通道数分别为64×2,128×2,256×2,512×2;Res-50在后续模块中的残差块数为[3,4,6,3],通道数分别为64×2,128×2,256×2,512×2;Res-101在后续模块中的残差块数为[3,4,6,3],通道数分别为64×2,256,128×2,256×2,1024,512×2,2048。
构建的基于深度残差网络的驾驶行为识别模型结构如图3所示,先将图像数据输入模型,对其进行数据预处理操作,将处理后的图像数据送入模型进行特征提取,并且训练模型使其与数据拟合,最后将预测的数据经过分类概率函数进行分类,输出识别到的行为类别。

图3 基于深度残差网络的识别模型结构图Fig.3 Structure diagram of recognition model based on deep residual network
3 实验与分析
3.1 数据集介绍
本文采用凯格勒平台公开的驾驶行为识别竞赛数据集[13]进行实验,该数据集包含10种驾驶行为:安全驾驶、右手玩手机、右手通话、左手玩手机、左手通话、调节面板、喝水、向后伸手、整理头发和与乘客交谈。10个类别共计23500张图像数据,图片大小为640×480。为验证模型训练后真实的驾驶行为识别能力,将数据集的20%单独划分为验证集和测试集。
3.2 实验环境
本文所使用的实验环境如表1所示,使用英伟达公司的GTX Titan XP计算卡,配合spyder编译器搭建基于Python的深度学习运行环境。同时使用Pytorch深度学习框架,它具有使用GPU加速张量计算的强大功能,还可以对梯度进行自动求导,提供多种深度学习工具的API接口。

表1 实验环境配置表Tab.1 Experimental environment configuration table
3.3 模型训练与测试
驾驶行为数据集的初始图像尺寸在经过数据增强处理后会出现大小不一致的情况,为满足模型输入通道的需求,将图像统一进行resize操作使其大小都为224×224,这在一定程度上还可以降低模型的计算量,提升模型运行速度。
训练深度卷积神经网络模型时,网络参数的初始化对于模型的训练速度和最后的收敛效果有较大影响,对于本文所设计较为深层的卷积神经网络而言,理想化的初始化模型参数可以使其梯度求导较为迅速,而较差的初始化参数会使模型陷入局部收敛无法优化或者最终收敛效果不好。因此在训练模型时本文使用何凯明博士在2015年ICCV大会提出的Kaiming初始化方法,文献[14]中其表现优于其他初始化方法。
训练深度卷积神经网络时,学习率是另一个重要的超参数,学习率设置的过大会导致模型不断跳过最优点无法收敛,而学习率设置过小会导致模型迭代过慢,训练过程漫长无比。因此本文在实验中使用自我衰减的学习率
设置策略,配合Adam优化器,每10代进行一次衰减,衰减系数为0.5。
此外,考虑到内存大小和显卡性能的限制,模型每次载入的小批量数据为64。完成训练后,载入测试集对模型性能进行测试,模型的acc曲线如图4所示,将模型Loss和Acc结果整理于表2。对比实验结果可以确定Res-101模型的识别正确率最高,为83.18%。

表2 实验结果Tab.2 Experimental results
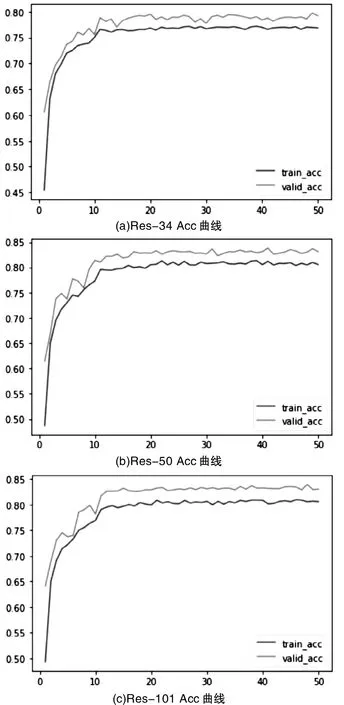
图4 模型Acc曲线Fig.4 Model Acc curve
4 结语
针对私家车保有量越来越高而人力和无力较为不足的情况,设计出一种可以快速识别驾驶员分心行为的模型,根据识别模型的提醒,可以有效约束驾驶员,进而提高驾驶安全性和避免交通事故的发生。通过实验验证文中设计的模型高效且准确,为后续研究做出铺垫。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
电子制作(2019年19期)2019-11-23
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
河南科技(2015年8期)2015-03-11
