
高分影像场景分类的半监督深度卷积神经网络学习方法
2021-08-14 02:27杨秋莲刘艳飞丁乐乐孟凡效
测绘学报 2021年7期
杨秋莲,刘艳飞,丁乐乐,孟凡效
天津市勘察设计院集团有限公司,天津 300000
随着IKONOS、Worldview系列、高分系列、高景一号等高分辨率遥感卫星的成功发射,高分辨率遥感数据已经成为对地精细观测的重要数据来源[1-3]。相较于中低分辨率遥感影像,高分影像呈现出了更丰富的空间细节信息,使得地物目标的精确解译成为可能。目前高分影像的分类基本实现了从基于像素的分类到面向对象的分类转变,极大地提高了分类精度[4-6]。遥感场景是由语义目标以某种空间分布构成的具有高层语义的复杂影像区域。因此即使获得如建筑、道路等精细地物目标识别结果,在获取如工业区、居民区等高层语义方面仍无能为力。为获取高层场景语义信息,如何跨越底层特征与高层场景语义之间存在的“语义鸿沟”,实现高分影像到高层场景语义之间的映射,是当前高分影像分类的一个热点问题[7-10]。
为克服“语义鸿沟”问题,国内外研究学者相继展开了面向高分辨率遥感影像场景分类的方法的研究,目前已经发展出了基于语义目标的场景分类方法[11-12],基于中层特征的场景分类方法[13-15]和基于深度特征的场景分类方法[16-20]。基于语义目标的场景分类方法构建了一种“自底向上”的场景分类框架,首先对遥感影像进行语义目标提取,然后对语义目标的空间关系进行建模获得最终的场景表达特征,如文献[11]利用弹力直方图统计目标之间的位置关系作为场景表达特征用于分类。然而这种方法依赖于语义目标的提取精度和空间关系构建。不同于基于语义目标的场景分类方法,基于中层特征的方法不需要场景中目标的先验信息,直接对场景表达特征进行建模,典型的方法包括词袋模型[21-22]、主题模型[13-14]等。
然而以上两类方法都需要手工设计特征,依赖专家先验。深度学习作为一种数据驱动的学习框架,可以自动地从数据中学习本质特征,已经被成功应用于目标检测、人脸识别等领域,由于其强大的特征学习能力,已经被应用于高分影像场景分类。其中按照网络类型主要可以分为自编码模型[23-24]和深度卷积神经网络模型[25-27]。在基于自编码模型的场景分类方法中,采用编码—解码的3层结构逐层对深度网络每一层进行预训练以获得良好的参数初始化。然而这类方法由于编码—解码结构的存在,训练深度网络时往往需要大量时间。相较于基于自编码的场景分类方法,基于卷积神经网络的方法不需要编码—解码结构,直接对整个网络模型进行训练,获得广泛研究。如文献[28]为了提高深度卷积网络特征的辨别性,通过构建正负样本对并引入度量学习使得正样本对在特征空间彼此接近,负样本对彼此远离。文献[29]提出LPCNN,从数据中进行切片来增加训练数据的个数和多样性,提高场景分类精度。
基于深度卷积神经网络的方法往往需要大量的标注数据用于网络模型的训练,当标注样本有限时,其学习到的特征表达泛化能力有限。针对标注数据有限条件下的遥感场景分类任务,目前已经发展出了基于无监督深度学习方法[23-24,30]、基于领域自适应的方法[31-33]、基于半监督深度学习方法[34-37]。在这3大类方法中,无监督深度学习方法和领域自适应方法往往不需要标记数据,然而这两类方法学习得到特征表达能力有限,场景分类精度较低。相较于基于无监督深度学习方法和领域自适应方法,基于半监督深度学习方法可以同时利用有限标注样本和大量未标记样本训练模型,有效提高模型泛化能力,具有较高分类精度。目前国内外学者已经对基于半监督深度学习场景分类方法开展了系列研究。文献[34]基于度量学习框架将未标记样本纳入到深度网络的训练过程中,根据标记样本在深度特征空间计算类别中心,并利用类别中心有效距离范围内的未标记样本参与类别中心的校正,使得同类样本向其对应类别中心靠拢。文献[35]为提高模型的辨别性,利用标注数据和未标注数据训练对抗网络,并用对抗网络中的辨别网络用于最终的场景分类任务。文献[37]将协同训练引入到半监督卷积神经网络场景分类中,利用标记训练样本分别训练两个不同的网络,同时利用验证集训练一个辨别网络,随后使用3个网络同时对未标记数据做预测,当3个网络对同一样本的预测一致时将其加入到训练集中,用于模型的训练。然而以上方法训练过程较为复杂,涉及多个网络的训练。
针对有限标注数据下模型泛化能力下降问题,本文将自学习半监督算法(self-training)应用到网络模型的训练,提出了一种端到端的半监督深度卷积高分影像场景分类方法(3sCNN)。相较于已有方法,本文提出的方法仅需训练单个网络,训练过程简单,便于实现:首先,利用标记样本对卷积神经网络进行训练;然后,利用得到的网络对未标记样本进行预测得到未标记样本的预测标签和对应的置信度,将置信度高的样本作为真实标签数据加入标记样本数据中进行模型训练。
1 基于卷积神经网络的高分辨率影像场景分类
基于卷积神经网络的高分影像场景分类基本流程包括数据预处理、深度特征提取和特征分类3个部分。
在数据预处理阶段,主要对输入原始影像进行归一化操作,在本文中采用简单的除以255操作,将影像像素值落在[0,1]区间。同时为了增加数据的多样性,在训练阶段随机地对数据进行平移、旋转等操作。
深度特征提取阶段利用卷积神经网络对经过数据预处理的影像逐层的进行特征提取。其中卷积神经网络的主要包含卷积层、池化层、全连接层和分类器层等。在特征提取过程中,对于第i层网络layi,其前一层的输出zi-1作为本层的输入得到本层输出特征zi,随后输出到下一层作为输入,重复特征提取过程
zi=layi(zi-1)
(1)
式中,layi可以是卷积层、池化层或者是全连接层等。
在深度特征提取阶段,利用多元分类器SoftMax对得到的深度特征进行分类,输出待分类样本的类别分布概率。
虽然基于卷积神经网络的场景分类方法已经被成功应用于遥感影像场景分类,并获得广泛关注,然而作为一种数据驱动的监督学习模型,其训练过程往往需要大量的标注数据。当训练样本有限时其深度特征泛化能力衰减,分类精度降低。针对这个问题,本文提出了半监督深度卷积神经网络用于高分辨率遥感影像场景分类。
2 高分影像场景分类的半监督深度卷积神经网络学习方法
本文提出的方法流程如图1所示,其过程主要包括数据预处理、深度特征提取和分类,标记数据集更新。
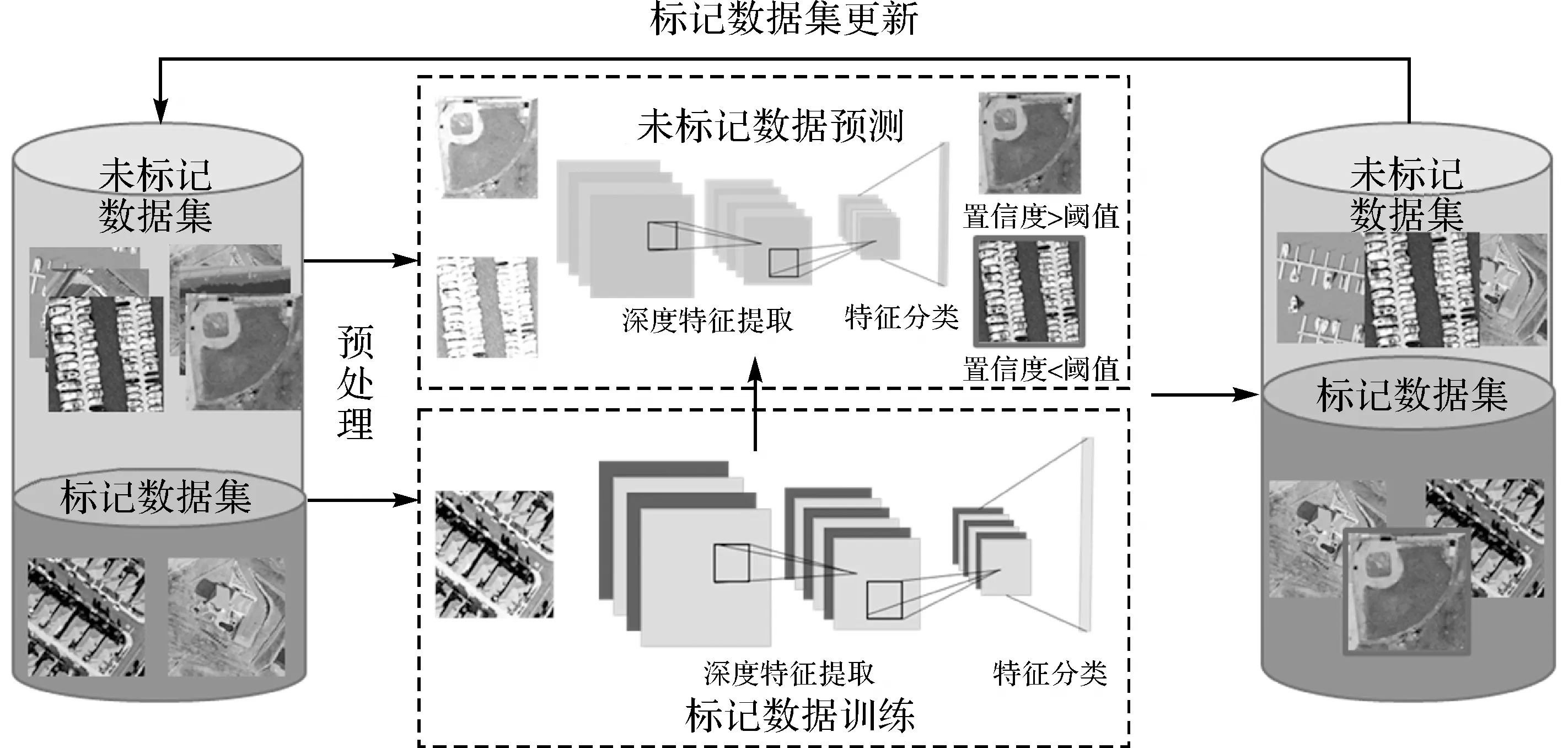
图1 基于自学习半监督深度卷积神经网络的高分影像场景分类流程Fig.1 Framework of high spatial resolution imagery scene classification based on semi-supervised CNNs
为增加数据的多样性,在数据预处理阶段对输入的每一张影像进行随机切块作为样本输入,并且对得到的影像快进行随机旋转。
本文采用残差网ResNet-50[38]用于特征提取和分类。在残差网中,其通过在低层网络和高层网络之间建立跨越连接(skip connection)来保证低层网络向高层网络的信息流通和避免梯度弥散导致的深度网络训练收敛困难问题,如图2(a)所示为含有跨越连接的ResNet Block,构成了残差网络的基本逻辑单元。残差网络通过堆叠多个ResNet Block构建深度网络,如图2(b)所示为ResNet-50的网络结构图,其中nX表示将n个ResNet Block堆叠在一起。
对于给定的输入影像,ResNet-50通过逐层特征提取得到对应的特征向量,并将特征输入到分类器SoftMax进行深度特征分类,得到一个样本的类别概率分布

(2)
式中,p(y=i|x)代表输入图像x属于类别i的预测概率;c代表场景分类中类别个数。在训练阶段,通过最大化样本被正确分类的概率来为网络参数更新提供监督信息,目标损失函数为式(3)
(3)
式中,n为参与训练的样本个数;yt,i为样本t的类别编码,当且仅当样本t属于类别i时yt,i取1,否则取0。
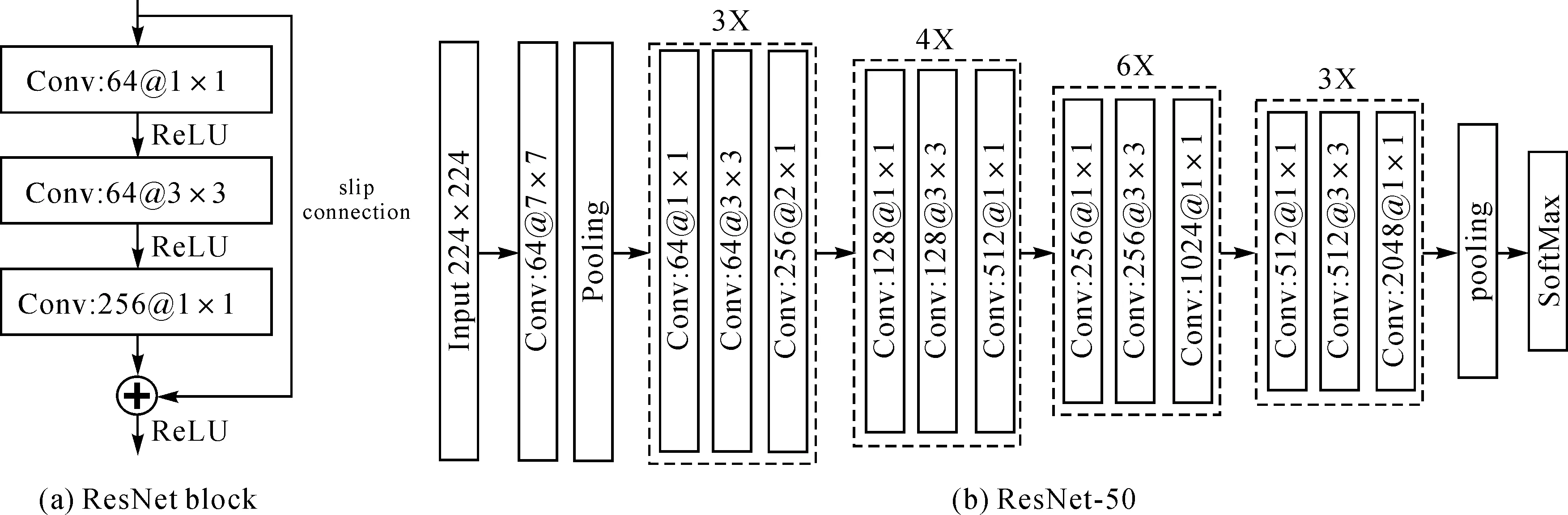
图2 ResNet-50Fig.2 ResNet-50
传统卷积神经网络通过最小化式(3)来训练网络参数,然而当高分辨率遥感标记数据有限时,模型的泛化能力受到限制。针对这一问题,本文采用自学习机制在卷积神经网络训练过程中加入标记数据集更新操作,增加可用于训练的标记图像数量。
首先在有限标注数据集上进行iter_thrd次迭代预训练,使得深度网络具有初步的场景识别能力。在标记数据更新阶段,利用预训练的网络对未标记数据集进行推断预测,得到每一个未标记样本属于某一类的最大概率,并将其作为置信度。对于未标记数据,如果其置信度大于阈值con_thrd,则将其加入到训练集中作为标记数据集进行网络参数的训练。对于未标记数据,将其用于模型训练时,其对应得目标函数为
(4)
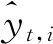
Lsum=Lcls+λ(t)Lsemi
(5)
式中,Lsum为总的目标函数;λ(t)为未标记数据样本参与训练的权重,其定义如式(6)

(6)
在本文方法具体实现中,在每一次网络参数更新迭代时,从标记数据和未标记数据同时随机采样一批数据输入卷积神经网络,计算标记数据和未标记数据的类别概率分布,然后根据式(3)、式(4)、式(5)计算目标函数。具体的伪代码如下。
算法1 3sCNN算法
输入:卷积网络Net,学习率lr,未标记数据集Ud,标记数据集Ld,最大迭代次数iter
输出:训练得到的网络net
fori=1:iter do:
sample batch of labeled dataL_batch fromLd
sample batch of unlabeled dataU_batch fromUd
FeedL_batch andU_batch to net
Compute the loss according to the equation (3)—(5)
Update the parameters of net
end
本文方法相较于传统卷积神经网络训练过程,仅是增加了一个未标记数据读取分支和一个阈值筛选步骤。相较于已有的半监督卷积神经网络场景分类方法,本文算法是一个端到端的半监督训练过程,简单易行,便于实现。
3 试验与分析
3.1 试验设置
为验证本文算法的有效性,本文采用UCM[39]、Google of SIRI-WHU[14]和NWPU-RESISC45[19]3个场景分类数据集进行试验测试。其中UCM数据集包含21个场景类别,每个类别具有100张场景影像,每张影像大小为256×256,空间分辨率为0.304 8 m(1 ft)。Google of SIRI-WHU数据集包含12个场景类别,每个类别具有200张影像,每张影像大小200×200,空间分辨率为2 m。NWPU-RESISC45具有45个场景类别,每类具有700张影像,大小为256×256,空间分辨率为30~0.2 m。图3、图4、图5分别给出了3个数据集的代表样本。为验证本文方法在标记样本有限的情况下的提升卷积神经网络泛化能力的有效性,在每一个数据集试验中,仅从该数据集抽取3%的影像数据作为标记数据集,抽取70%的影像数据作为未标记数据集,剩余的数据作为测试样本。每次试验重复5次,记录5次试验的平均分类精度作为最终的分类精度。试验中利用经过在ImageNet数据集上经过预训练的ResNet-50进行网络的初始化并在3个数据集上微调,其中不采用本文提出的半监督训练方法进行微调的ResNet-50作为对比方法,记为Baseline-ResNet50。在本文试验中,训练迭代次数设置为2000,学习率为0.000 1。

图3 UCM数据集Fig.3 UCM data set

图4 Google of SIRI-WHU数据集Fig.4 Google of SIRI-WHU data set
3.2 试验结果与分析
表1给出了在置信度阈值con_thrd为0.2,迭代训练阈值iter_thrd为300的条件下,本文提出的半监督算法3sCNN与对比方法在3个数据集上的分类结果。从表1可以看出,本文半监督算法可以有效地提高高分辨率场景分类精度,在3%标记数据集和70%未标记数据集参与训练的情况下,相比于Baseline-ResNet50,提出的3sCNN在3个数据集上的分类精度分别提高了7.4%、4.7%和3.2%,有效地证明了所提算法的有效性。

图5 NWPU-RESISC45数据集Fig.5 NWPU-RESISC45 data set

表1 场景分类精度对比情况Tab.1 The scene classification accuracy comparison
表2、表3分别给出了提出的3sCNN与已有半监督的方法在UCM和NWPU-RESISC45数据集上的对比情况,其中x%~y%代表参与训练的标记数据的占数据集整体的x%,未标记数据集占比y%。本文按照与对比方法相同的数据配置进行试验,其中在5%~95%和80%~20%的设置中,测试数据也作为未标记数据参与训练。从表2、表3可以看出本文提出的方法在同样配置下可以取得最优的分类结果。相较于文献[37]、文献[35]中的方法需要训练多个网络,本文提出的方法可以获得更优的分类精度,且仅需要训练一个网络,训练简单,便于实现。

表3 与已有方法在NWPU-RESISC45上对比情况Tab.3 Compared with published results with NWPU-RESISC45
为了进一步验证未标记数据集在深度神经网络训练中的作用,本文通过控制参与训练的未标记数据样本个数,对比不同未标记样本个数下3个数据集的场景分类精度,对比情况如表4所示,其中分别对比了当参与训练的未标记个数占总样本数0%(即等价于Baseline-ResNet50)、20%、50%和70%下的场景分类精度。从表4可以看出在未标记数据集的样本个数逐渐从0%升至70%时,场景分类精度也随之逐步提升,证明了提出的半监督场景算法3sCNN可以有效利用未标记样本参与模型训练,提高模型的泛化能力。图6比较了Baseline-ResNet50和3sCNN在Google of SIRI-WHU测试数据集上的混淆矩阵。如图6所示,所提出的3sCNN在7类上取得了最好的分类效果,减少了港口、公园、裸地等类别的误分类。对于池塘这一类别,相比于对比方法Baseline-ResNet50,本文方法的3sCNN精度由0.975衰减至0.775,造成这一现象的原因主要是在提出的半监督方法中,会对未标记数据进行预测,然后将高置信度未标记样本作为标记数据加入到训练集中用于模型的训练,因此未标记数据的预测质量会影响到训练数据的准确度,当有错误的高置信度样本被作为标记数据用于训练网络模型时,会降低网络的预测准确度。如图7所示,本文测试了Baseline-ResNet50和3sCNN在未标记数据集上的分类情况,可以看出Baseline-ResNet50在池塘这一类别上的精度(0.96)高于3sCNN(0.91),这也说明了3sCNN在池塘这一类别上选用了错误的高置信度未标记样本参与模型训练,降低了模型对该类别样本的识别能力。

表4 不同未标记样本下场景分类精度对比情况Tab.4 Scene classification accuracy with different training sample ratio

图6 Baseline-ResNet50和3sCNN对Google of SIRI-WHU测试数据的混淆矩阵Fig.6 The confusion matrix of Baseline-ResNet50 and 3sCNN with Google of SIRI-WHU
3.3 参数分析
在本文提出的方法中,存在迭代阈值iter_thrd和置信度阈值con_thrd需要指定。为研究迭代阈值iter_thrd和置信度阈值con_thrd对分类精度的影响,本文分别令iter_thrd={0,300,600,900,1200,1500,1800},con_thrd={0,0.2,0.4,0.6,0.8}进行试验,试验结果如图8、图9所示。从图8中可知,对于UCM和NWPU-RESISC45数据,当置信度取值为0.2时获得最优分类精度,对于Google of SIRI-WHU数据集,当置信度阈值取值为0.4时获得最优精度。对于3个数据集来说当置信度阈值大于0时,场景分类精度有所提升,并在0.2和0.4取得最优结果,说明通过设置阈值可以有效控制选入未标记样本的质量,避免预测错误的样本参与到模型的训练中。继续增加置信度阈值精度开始出现下降,造成这一现象的原因可能是置信度非常高的样本其与原本的训练集样本具有较高的相似性,将其加入训练集用于模型训练时,其带来的信息量较为有限。图9给出了迭代阈值iter_thrd对场景分类精度的影响,从图9可以看出,当迭代阈值从0增加至300时,分类精度提升,当该阈值继续增加时,分类精度出现下降,造成这一现象的原因可能是标记数据本身数据量少,过多的迭代次数造成了过拟合现象。当迭代阈值取值300时,本文提出的方法在3个数据集上获得最佳分类精度。
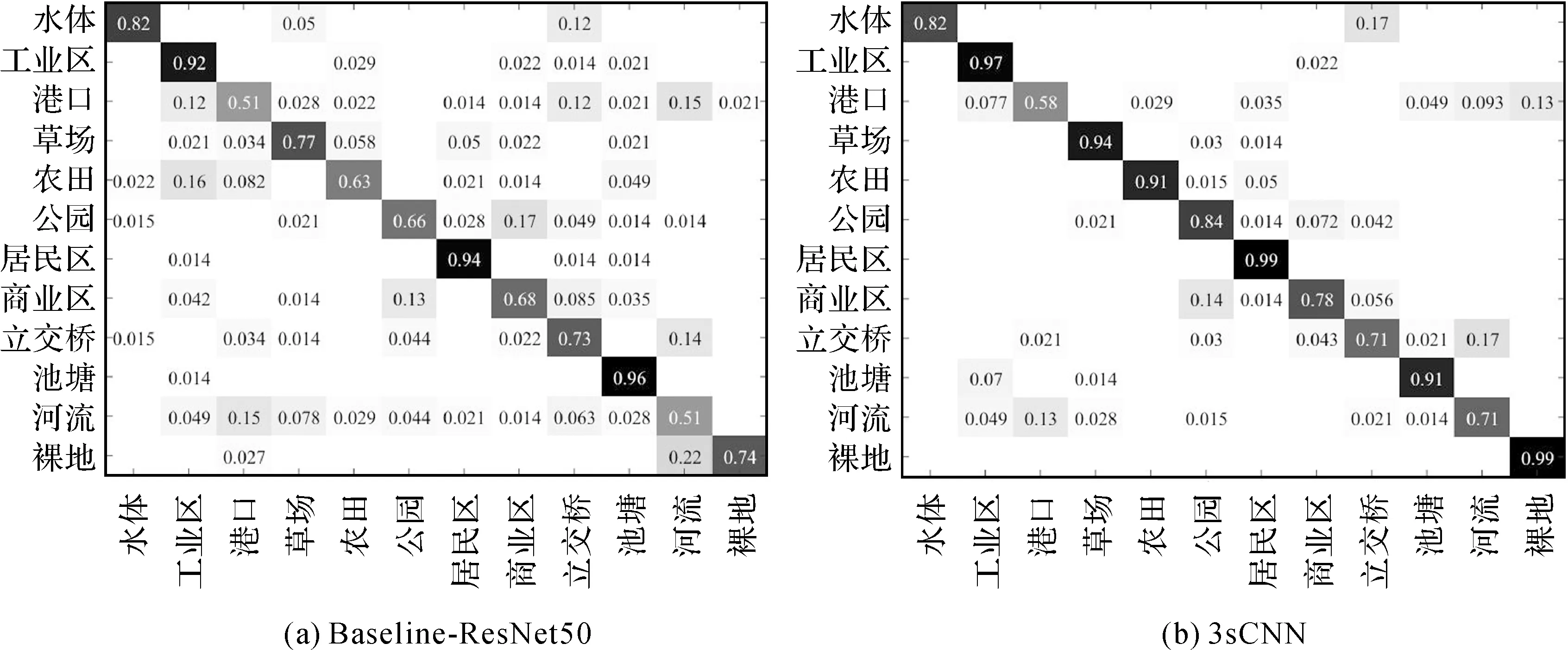
图7 Baseline-ResNet50和3sCNN对Google of SIRI-WHU中未标记数据的混淆矩阵Fig.7 The confusion matrix of Baseline-ResNet50 and 3sCNN computed on the unlabeled dataset from Google of SIRI-WHU

图8 置信度阈值对场景分类的影响Fig.8 The influence of con_thrd on scene classification accuracy
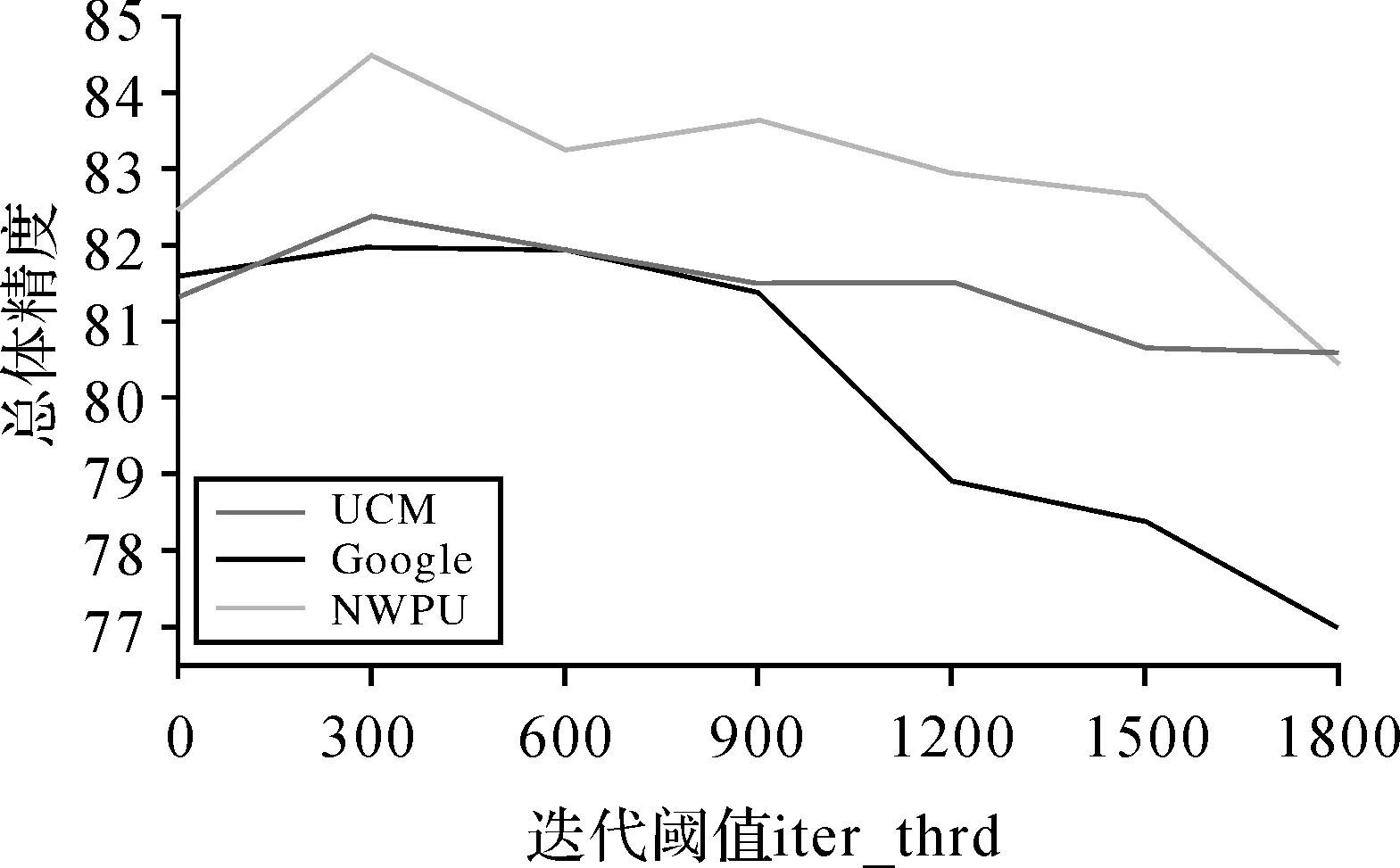
图9 迭代阈值对场景分类的影响Fig.9 The influence of iter_thrd on scene classification accuracy
4 结束语
在基于卷积神经网络用于高分辨率遥感影像场景分类时,针对标记数据有限情况下卷积神经网络训练困难,特征泛化能力衰减问题,本文将自学习半监督算法应用到网络模型的训练,提出了一种端到端的自学习半监督深度卷积高分影像场景分类方法,在利用有限标记数据训练的同时,对未标记数据进行标记预测并将高置信度样本作为标记数据加入到训练集中进行模型的训练。试验表明本文算法可以有效提升分类精度本文方法在训练过程中需要加入高置信度未标记样本参与模型训练,通过设置置信度阈值来保证加入样本预测标签的正确性。然而过高的阈值会导致选用的样本所携带的有效信息较为有限,影响分类精度的进一步提升,在未来的工作中,将在保证未标记样本标签正确率的同时考虑待基于差异性衡量样本信息量,选用携带更多有效信息的高置信度样本参与模型的训练,进一步提升场景分类精度。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·高一版(2021年2期)2021-03-19
电子制作(2019年11期)2019-07-04
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
知识经济·中国直销(2018年8期)2018-08-23
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
北京航空航天大学学报(2018年1期)2018-04-20
初中生世界·七年级(2017年9期)2017-10-13
数学学习与研究(2017年3期)2017-03-09
