
高效运算网络在作物叶部病害识别中的研究*
2021-08-13 09:47孙圆龙徐晓辉宋涛崔迎港司玉龙
中国农机化学报 2021年7期
孙圆龙,徐晓辉,宋涛,崔迎港,司玉龙
(河北工业大学电子信息工程学院,天津市,300401)
0 引言
作物病害是导致作物产量下降的主要原因,实时有效的作物病害识别技术是防治的关键。基于机器视觉的病害识别技术可以检测作物相似的特征,成为病害识别的有效途径。
传统机器学习,其往往是在可见光波段提取特定作物的纹理、颜色和形状等特征[1],然后进行模式识别,但传统机器视觉一般局限于某一作物。深度学习的发展不断催生新的网络模型,这些模型也不断的迁移到果蔬的病害识别上,在其叶部病害识别中[2],迁移的网络模型参数量巨大,VGG16参数内存为526 MB,AlexNet参数内存为127 MB。Durmus等使用AlexNet和SqueezeNet分别对番茄进行病害识别,发现AlexNet识别准确率高于SqueezeNet,但模型内存和运行时间消耗翻倍。
为减小参数量,Geetharamani等[3]将深度CNN模型简化为9个层,对plantvillage提供的数据集进行识别,最高准确率达到96.46%。刘洋等[4]在移动端使用轻量级网络MobileNet进行叶部病害二分类识别,识别率在95%左右,参数内存17.1 MB,计算量消耗为575 M。王冠等[5]对轻量化网络MobileNet进行优化,多作物病害识别准确率为96.23%。蒲秀夫等[6]提出二值化网络将信息压缩以加快叶部病害的识别效率。郭小清等[7]以多个感受野优化AlexNet模型,对番茄早中晚三类疫病进行识别,识别准确率为92.7%,模型的内存消耗为29 MB。谭文军[8]将残差网络中的普通卷积替换为深度卷积可分离,并引入全局池化和批归一化得到DW-ResNe模型,在对作物多病害识别中实现98.59%的准确率,在病害严重程度识别实现89.16%的准确率,参数内存仅2.1 MB,但对硬件计算力(Floating point operations,FLOPs)的要求为481.415 M。
当前很多模型过于复杂,消耗大量的计算资源,只能部署在服务器端,导致普及性和实时性差;轻量化的模型存在模型复杂度高,对优化方式依赖性大,调参复杂。复杂背景下,大量病斑和背景分割耗费时力,且仅提取人工标定的有限特征,会忽略了图像中的全局和上下文信息。为将神经网络用在实际生产中,必须解决效率问题,考虑到模型会占用巨大的内存空间和硬件的计算资源,试验设计了高效残差模块和恒等残差模块,减小参数内存,采用模块化的残差结构搭建高效运算网络,提升网络对整体信息的感知能力,在保证网络识别精度的同时,加快网络的收敛速度,提升网络抗干扰能力,减小模型对硬件资源的消耗,降低硬件开发的成本。
1 数据集
Plantvillage提供了很多病害数据,采用其中部分数据集包括健康叶片、玉米叶斑病、叶枯病、桃树疮痂病、甜椒疮痂病、草莓叶枯病,苹果黑星病、灰斑病、雪松锈病等作为基础数据,测试了高效残差网络模型,简单背景下验证了模型的有效性。为验证模型的鲁棒性,在实际生产环境中拍摄和搜集了包含复杂背景、不同角度和光照下的作物图像,制作了800张马铃薯晚疫病、780张黄瓜霜霉病、635张黄瓜白粉病、1 200张马铃薯健康和1 000张黄瓜健康数据集,进行复杂场景下的病害识别测试,部分数据集如图1所示。
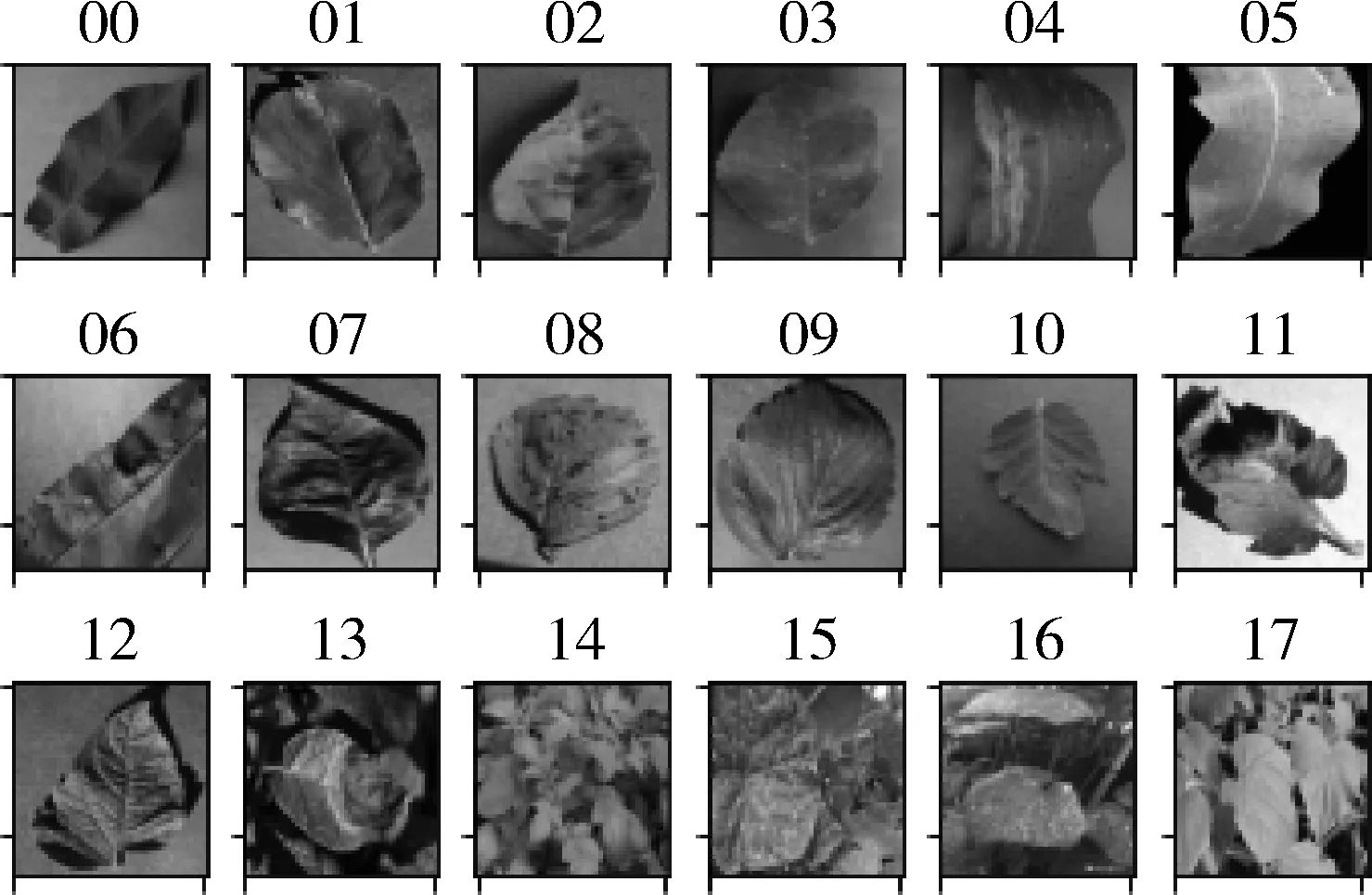
图1 农作物病害随机示例Fig. 1 Random examples of crop diseases
2 病害识别网络模型及损失函数
2.1 卷积神经网络
深度卷积神经网络模型内存占用过大,且对硬件性能要求过高,实时性差且不易在边缘端的设备上布署。二值化网络压缩了信息数量,丢失太多的病害特征。轻量化网络MobileNet在识别精度和效率进行了均衡,但对优化方式依赖性大。
模型的参数数量与卷积核的尺寸大小、通道数量和卷积核的数量有关。大的卷积核可由多个小的卷积核代替,减少参数数量。单通道5×5的卷积核可由两个3×3的卷积核代替[9]。卷积空间可分离将空间位置信息和深度信息分开进行学习,然后进行信息融合[10],但存在信息通畅问题。Lin等提出了1×1的卷积核用来跨通道信息交互。Howard等使用卷积空间可分离和1×1的卷积核实现了MobileNet。轻量级网络ShuffleNet的通道混合和分组卷积结构进一步优化了MobileNet的信息通畅问题和计算量,但是精度有所下降。不同的卷积核有不同的感受野,卷积分解之后可以在不同方向的感受野上来提取图片的特征。Freeman等将卷积分解和池化分解结合起来,搭建了EffNet,提升了识别精度,但浮点数运算量高于MobileNet。
引入卷积分解、池化分解、卷积深度可分离、多个小卷积核替代大卷积核的结构丰富卷积核尺寸,减少模型参数,用残差连接解决信息通畅问题,且防止了梯度消失和网络退化。设计了两个高效模块,通过级联操作形成的高阶残差结构,分别提取细节和全局的信息以提高模型的识别精度,模块化搭建了高效运算网络,减少模型参数和计算量,以解决作物叶部病害识中硬件门槛高的问题。
2.2 损失函数的优化
交叉熵是分类中常用的损失函数,试验首先采用交叉熵(Cross entropy)作为损失函数,进行简单背景的病害识别,传统的交叉熵函数如式(1)所示。
(1)
式中:p(xi)——真实概率分布;
q(xi)——模型预测概率分布;
n——样本总数目。
可以看出当预测值为真时,损失值很小,当模型预测值为假时,损失值很大。交叉熵函数对正负样本的预测权重一样,无法应对不均衡样本,为此,He等提出了用于目标检测的二分类任务的focalloss损失函数。
FL(pt)=-αt(1-pt)γlogpt
(2)
(3)
(4)
式中:pt——模型预测概率;
p——真实值为1的模型预测概率;
αt——损失值加权因子;
α——对应类别为1时的损失函数加权因子;
γ——调制因子,取值为2。
focaloss是针对二分类问题,论文将其优化为带权值的多分类muti_focaloss,从而进行数据均衡控制,表达式如式(5)和式(6)所示。
(5)
(6)
式中:yt——当前样本的真实的概率分布;
pt——模型预测概率;
αt——加权因子。
试验首先统计所有的样本总数,然后将每一类样本数目除以样本总数目求得加权因子αt的值,用来平衡权重。
为防止模型训练过程出现过拟合情况,试验在交叉熵损失函数的基础上加上L2正则化用来对损失函数进行限制,衰减权重,从而降低损失函数值,提高模型泛化能力。其表达式如下
(7)
式中:C——新的损失函数;
C0——原来的交叉熵损失函数;

从而得到新的损失函数
(8)
式中:λ——权值衰减的衰减系数。
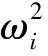
3 高效运算模块结构设计
网络架构在卷积神经网络中起着重要的作用,一般认为不同的卷积核有不同的感受野和识别敏感度,且多个小的卷积核可替代大的卷积核。论文提出的简化运算网络,主要包含两个设计的高效模块:高效残差卷积模块和恒等残差模块。高效残差卷积模块如图2所示模块拥有多种大小的卷积核。首先借助卷积核1×1减少通道数量为N/2,然后进行深度可分离卷积DwConv1×3完成横向卷积;在水平方向进行2×1的最大池化,步长为(2,1);接着完成纵向深度可分离卷积DwConv3×1,此时的张量横向尺寸变为原来的一半,纵向尺寸不变,通道数为原来的一半;接着对以上输出的张量进行普通Conv2×1(N)的卷积,步长为1×2,完成池化分解的纵向效果,此时的输出尺寸为输入尺寸的一半,通道数为N。在数据输入处引入步长为1×1的最大池化Maxpool(2×2)和通道数为N的Conv1×1卷积以统一尺寸和通道数目,并和以上输出相加做到局部和整体信息的融合,从而提升网络对上下文信息的感知能力。丰富的卷积核尺寸,进一步提升了网络的识别准确率。每一次卷积操作之后均加入批归一化(BN)和激活函数以增加网络的稀疏性和收敛速度。
以上结构完成了对3×3×N卷积核的替代,而且丰富的卷积结构模拟了多种不同大小的卷积核,以便提取更多的信息特征。高效残差卷积模块特点是:模型的输出大小变为输入的一半,通道数增多为预设数目;模块将第一层提取的整体信息,与后三次不同大小卷积核提取的局部信息进行相加,不仅精细化了图像信息,做到局部和整体的结合,而且减少了计算消耗,与普通3×3卷积相比,计算量减少到38.9%。
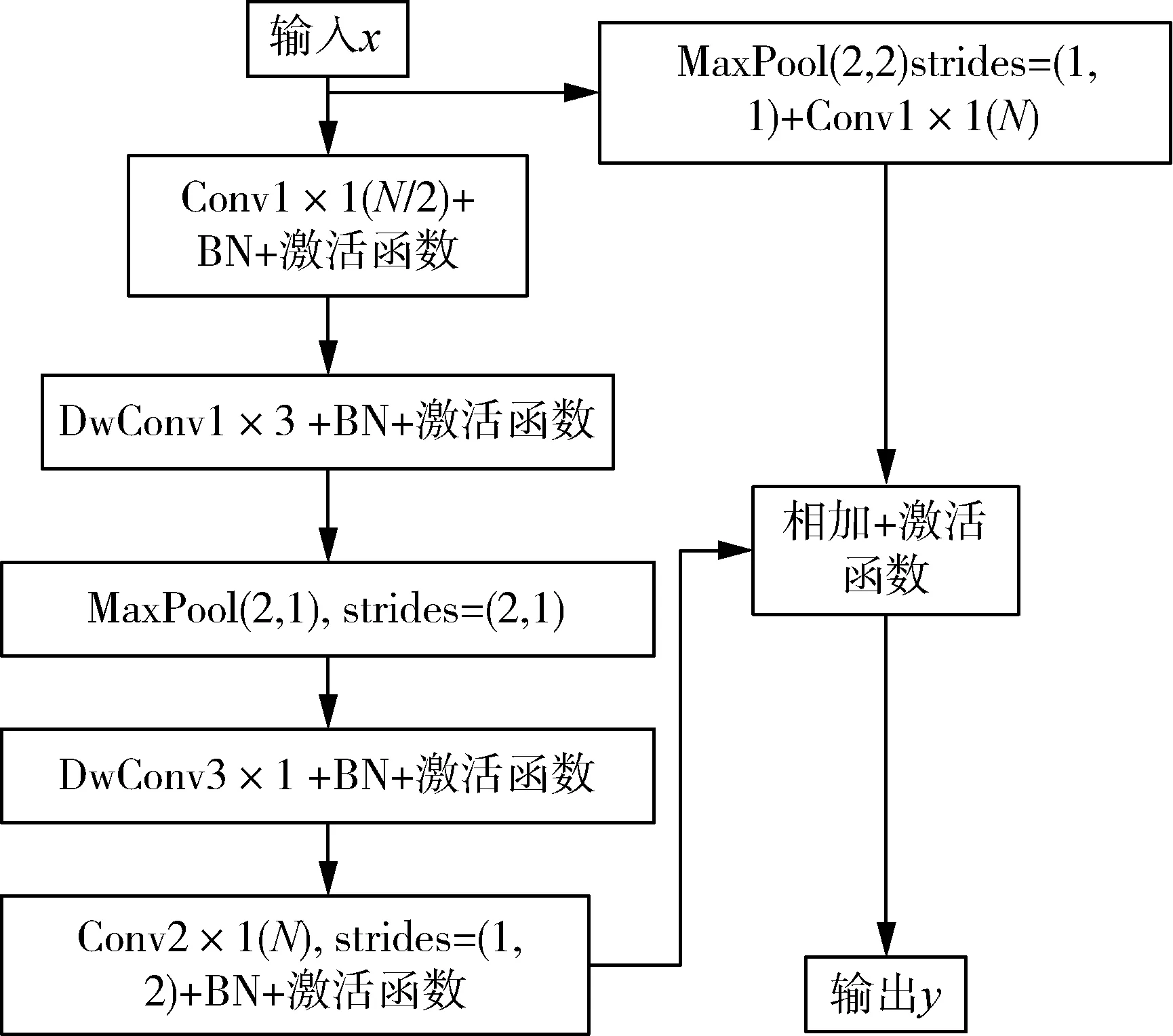
图2 高阶残差卷积模块Fig. 2 Efficient residual convolution module
试验优化了恒等残差模块,如图3所示,通道数变化为原始通道的1/8,试验参数可进一步减少,与普通3×3卷积相比,计算量减少到25%。模块的特点是经过三次卷积之后与输入层相加,实现残差学习以突出细节信息,且输入和输出保持一致,不会改变特征映射的大小,因此可以连续堆叠以加深网络,提升网络的拟合能力,以适应不同要求的识别任务。
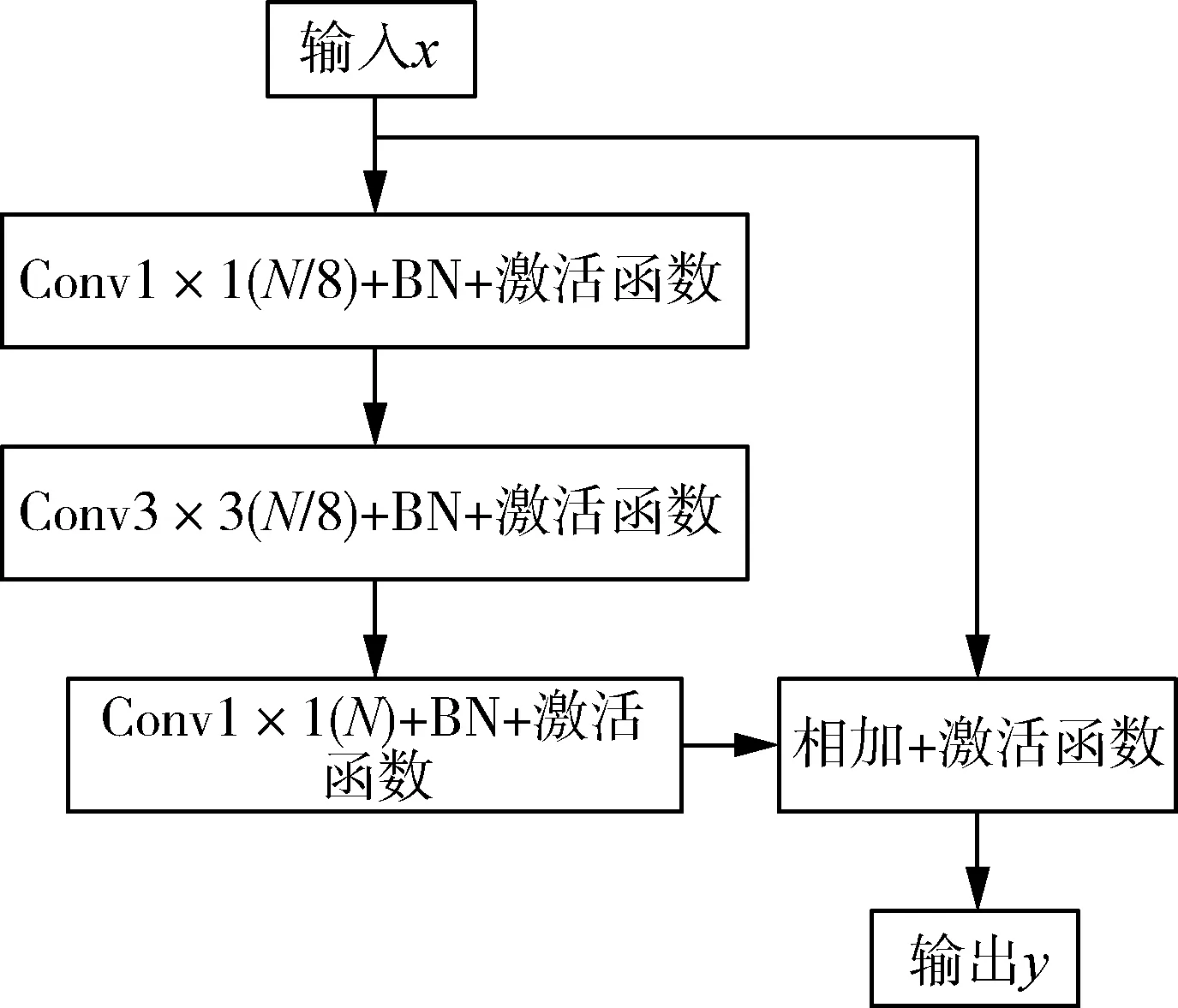
图3 恒等残差模块Fig. 3 Identical residual module
优秀的模型一般包含很多可以重复利用的模块,以上设计的两个模块具有高的性能和低的复杂度。表1为高效运算网络的结构组成,高效运算网络的高阶残差卷积模块Effres_block(a,b)×n和恒等残差模块Idenres_block(a,b)×n组成,其中a代表输入的通道数,b代表输出的通道数,n代表连续堆叠的层数。基于两个模块的特点,可以将多个恒等残差模块堆叠在高效残差卷积模块后边形成高阶残差效果,充分提取各层的特征,做到精细化过滤,并且与输入的全局特征相加融合,充分利用底层特征的细节描述和高层特征的抽象表达,优化了网络的信息感知能力和抗干扰能力,提升网络的识别精度。
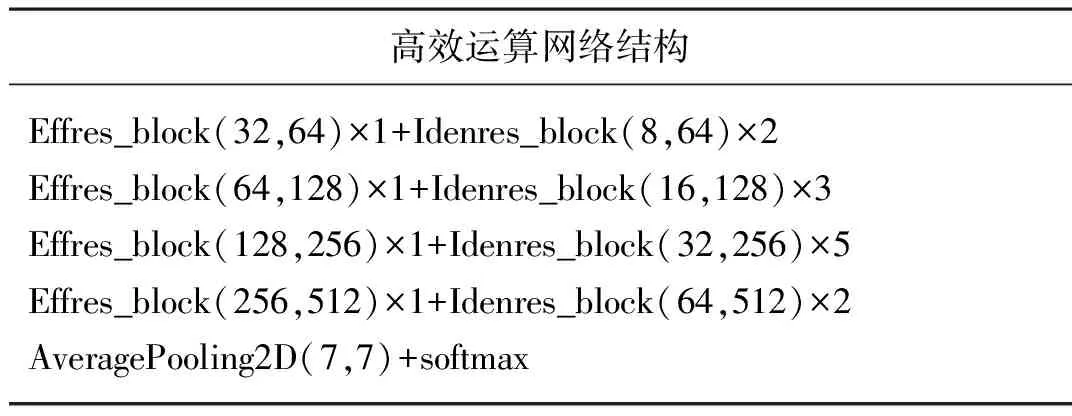
表1 高效运算网络模块化结构Tab. 1 Modular structure of Efficient computing network
论文先用简化运算的两个高效模块替代Res50结构,搭建了高效运算网络,表1为其中高效运算网络的结构,经过表1中每一行的模块后,特征尺寸减半。
4 模型训练
4.1 试验平台
采用Ubuntu16.04操作系统,搭载AMD Ryzen 74800U with Radeon Graphic处理器,频率为1.8 GHz。内存为16 G。选用基于tensorflow的keras深度学习框架。以python语言为基础,进行代码编写。
4.2 试验参数设置
试验采用批量训练的方法,将数据集分为多个batch,batch的值设置为64。epochs设置为24,损失函数选取交叉熵,优化器选择Adam,初始学习率lr_start设置为0.000 1,最终学习率lr_end设置为0.000 01,每一个epoch之后,让学习率进行衰减按照(lr_end/lr_start)(1/epochs)逐渐衰减,使得模型参数不断稳定。使用Dropout防止模型发生过拟合,失活率设置为0.2。试验对每一份数据的80%作为训练集,20%作为验证集。
4.3 试验和结果分析
试验以设计的高效结构为基础,降低模型对硬件的需求,用Plantvillage提供的多病害数据,进行简单背景下的病害识别,以优化网络模型,提升识别准确率,加快收敛速度,然后将高效网络模型用于自制的数据集,进行复杂背景下的病害识别,测试了模型的参数内存,并与经典网络进行对比。
4.3.1 简单背景下多种作物病害识别
论文采用高效运算网络对Plantvillage提供的简单背景下的部分健康叶片、玉米叶斑病、叶枯病、桃树疮痂病、甜椒疮痂病、草莓叶枯病,苹果黑星病、灰斑病、雪松锈病等加入高斯噪声后进行分批次识别,交叉熵损失作为损失函数,网络的输入为(256×256×3),采用Relu激活函数得到24个迭代周期的识别结果如图4和图5所示。
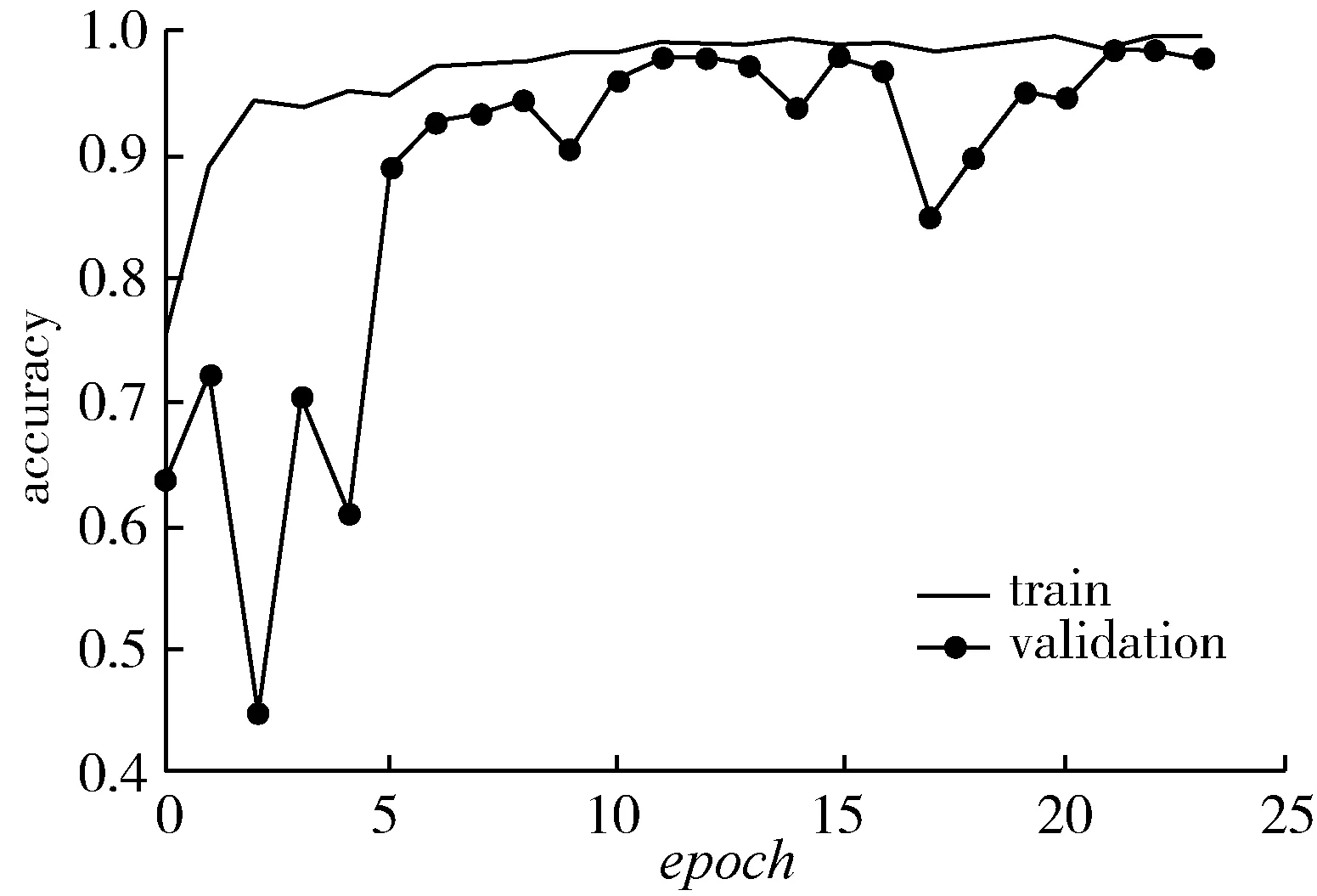
图4 Relu作为激活函数的多病害识别准确率Fig. 4 Recognition accuracy of multiplediseases using Relu as activation function
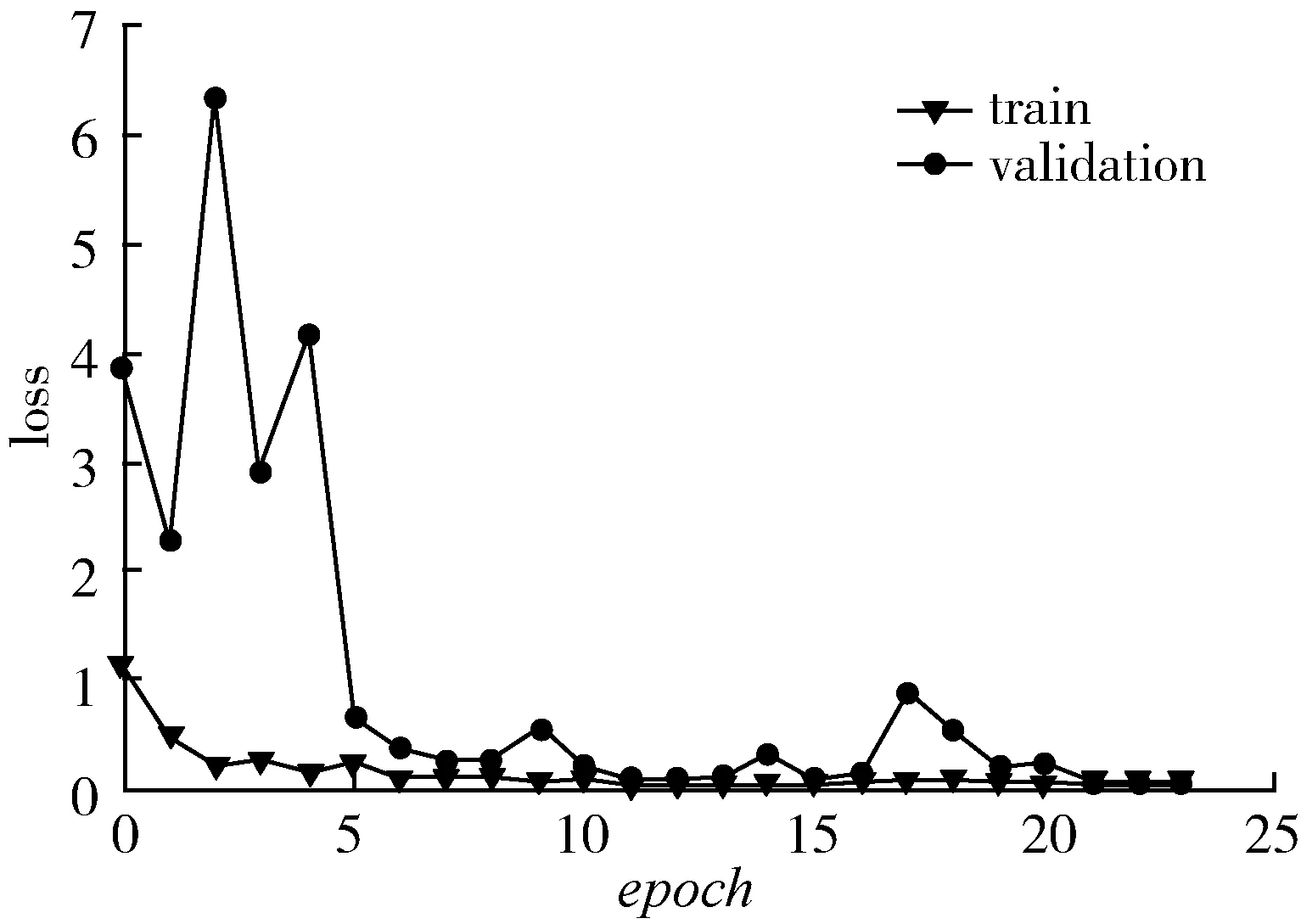
图5 Relu作为激活函数的多病害识别损失值Fig. 5 Loss value of multiple diseasesidentification using Relu as activation function
训练集识别准确率不断上升,最终稳定在99%附近,验证集识别准确率在22个epoch后达到99%左右的识别准确率,损失值降到0.073附近,识别准确率最高达到99.37%,可以完成常见病害的识别任务,但模型在8个epoch之后,验证集识别准确率以90%为中心进行波动,幅度较大,收敛性差。
为进一步提升模型的识别效率,加快收敛速度,论文将激活函数变为LeakyRelu,改用加入L2正则化优化的交叉熵作为损失函数,权重衰减系数λ设置为0.000 01,改变网络的稀疏性,再次进行多病害识别,得到24个迭代周期的识别结果如图6和图7所示。
如图6和图7所示,在前8个迭代周期,验证集准确率先波动上升达到90%以上,9个epoch之后识别准确率便在94%之上波动,且波动幅度比较小,收敛速度明显加快,而且验证集损失值与训练集的损失值不断波动下降,最终收敛在0.066以下。训练集最高准确率为99.68%,验证集的准确率最终稳定在99%附近,优化的高效运算网络具有更好的收敛性和稳定性,识别效率更高。
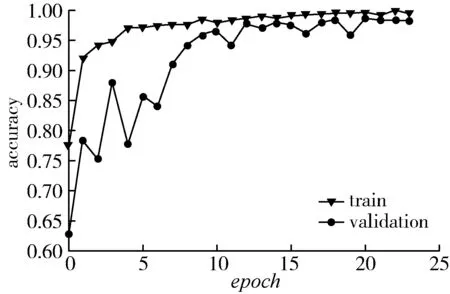
图6 LeakyRelu作为激活函数的多病害识别准确率Fig. 6 Recognition accuracy of multiplediseases using LeakyRelu as activation function
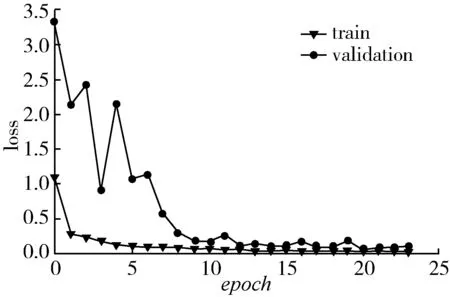
图7 LeakyRelu作为激活函数的多病害识别损失值Fig. 7 Loss value of multiple diseasesidentification using LeakyRelu as activation function
4.3.2 复杂背景下病害识别测试
为进一步测试实际生产环境中高效运算网络的高效性,进行复杂背景下的作物病害识别,实验将优化的muti-focaloss损失函数加入高效运算网络中,形成新高效运算网络,以应对数据不均衡问题。首先计算总的样本数目,然后将每类样本数量除以总样本数量的值,作为优化的muti_focaloss损失函数的加权因子,来解决数据不均衡问题。复杂背景下的加权因子α1、α2、α3、α4、α5分别为0.181、0.177、0.144、0.272、0.273,对应数据集的黄瓜霜霉病、黄瓜白粉病、黄瓜健康、马铃薯晚疫病和马铃薯健康叶片的权重,然后进行病害识别,并与经典网络对比,识别结果如表2所示。
如表2所示,与Res50相比,MobileNet极大降了参数冗余,参数内存由90 MB降到12.4 MB,但准确率有所下降。高效运算网络的高阶残差结构和丰富的卷积核尺寸提供了更加全面的病害特征,不仅解决了广义识别模型对细粒度特征提取弱的问题,将识别准确率从MobileNet的86.3%和Res50的87%提升到88.6%,当采用优化的muti_focaloss损失函数后,识别准确率提升到92.6%,可以满足实际生产的识别要求,且将参数内存降低到3.15 MB,从而提升网络的识别效率。
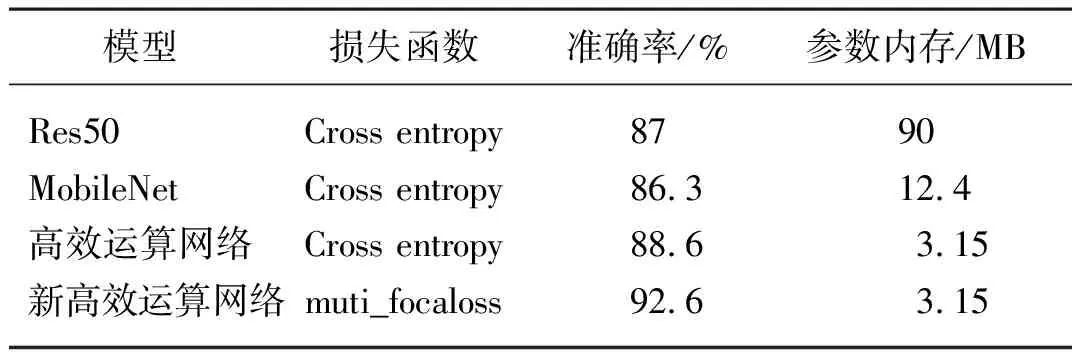
表2 复杂背景下作物病害识别结果Tab. 2 Recognition results of crop diseases incomplex background
4.4 模型性能分析讨论
卷积神经网络参数内存冗余太大,对硬件计算力(FLOPs)的要求过高,导致普及性差,一般只能用于服务器端。卷积神经网络要想广泛用于实际的生产场景,提升识别效率,必须降低对硬件的门槛要求,适用于大多数的嵌入式设备,且模型参数内存越小,相同硬件资源下,推理速度就越快,为了更加全面评价高效运算网络模型,论文从模型的识别准确率、参数量、激活函数、对硬件计算力要求(Floating point operations,FLOPs)和参数内存几个方面进行了分析,识别准确率为简单背景下多种混合作物的病害识别准确率。
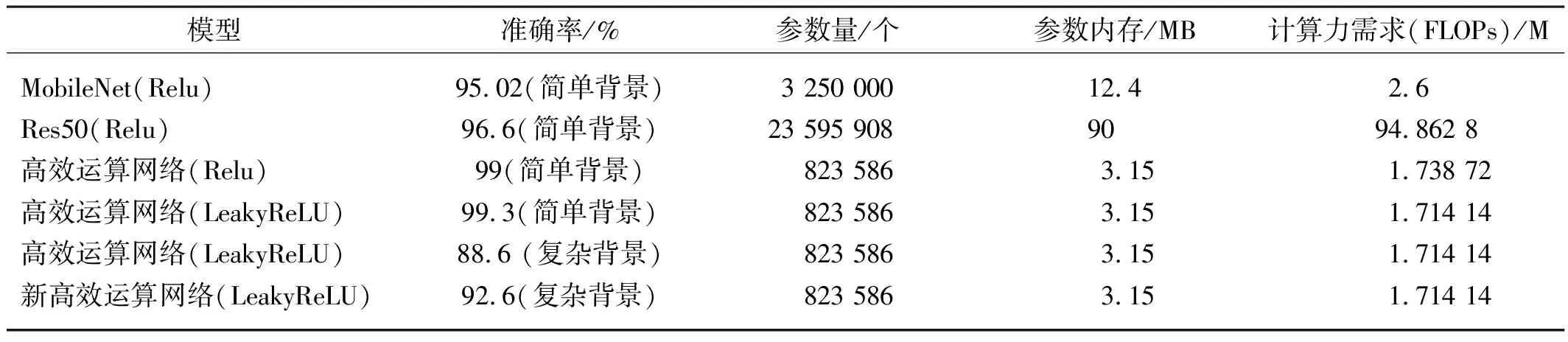
表3 多病害识别模型的性能Tab. 3 Performance of multi disease recognition model
由表3可知,以Relu为激活函数的Res50(Relu)在简单背景下多病害识别中的准确率为95.02%,硬件计算力需求为94.862 8 M,参数内存要求超过90 MB,占用过多的硬件资源,在硬件计算力资源相同的情况下,内存占用越大,识别消耗时间就越长。MobileNet (Relu),以Relu为激活函数,在保持95.02%的识别精度的同时,将参数内存降低到12.4 MB,对硬件计算力的要求降到2.6 M左右,使得网络识别模型可以布署在边缘侧的移动设备上,很大程度上提升了神经网络的普适性。高效运算网络(Relu)在进一步降低参数内存到3.15 MB的情况下,相比MobileNet(Relu),把简单背景下作物病害识别准确率提升到99%以上,将对硬件计算力的要求降低到1.714 M左右,改用激活函数为LeakyRelu后,高效运算网络(LeakyRelu)将简单背景下作物病害识别准确率提升到99.3%。
为解决实际生产中环境多变的问题,将加入muti_focaloss损失函数的新高效运算网络(LeakyRelu)用于复杂背景下的识别,相比高效运算网络(LeakyRelu),将识别精度提升到92.6%。与经典网络相比,新高效运算网络硬件计算力的需求仅1.71 M左右,进一步降低了模型对硬件计算力要求的门槛,节约了开发硬件开发成本,且参数内存小,具有更好的实时性,适合布署在边缘侧的设备上进行边缘计算。
5 结论
论文以设计的高效运算模块为基础,用于减少参数冗余和计算量,结合优化的损失函数搭建了高效运算网络,在提升了识别精度的同时,加快了网络收敛速度,降低了硬件资源消耗,从而解决了边缘端作物病害识别适用性差的问题,具体结论如下。
1) 高效运算网络对简单背景下多种作物进行病害识别,准确率在99%附近;优化损失函数后,病害识准确率达到99%以上,具有很好的细粒度特征提取能力;为进一步验证模型的鲁棒性,再次将模型用于复杂背景下的作物病害识别,采用改进的损失函数的新高效运算网络应对实际生产中的数据不均衡问题,准确率达到92.6%,试验证明模型具有很好的抗干扰能力,可以用于实际生产场景的病害识别。
2) 在简单背景下多病害识别中,交叉熵作为损失函数,8个epoch后验证集准确率以90%为中心波动,幅度较大,改用加入L2正则化的损失函数后,9个epoch之后验证集准确率便在94%之上,且波动幅度小,验证集的准确率最终稳定在99%附近,收敛速度明显加快。
3) 高效运算网络的参数内存仅占3.15 MB,对硬件性能(FLOPs)的要求仅为1.714 M,不仅识别效率高,而且极大降低了硬件成本,适合用于边缘端实时检测作物病害,便于后续作物病害监测系统的开发和普及。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26
高技术通讯(2021年5期)2021-07-16
北京航空航天大学学报(2020年10期)2020-11-14
数学小灵通(1-2年级)(2020年6期)2020-06-24
当代陕西(2019年13期)2019-08-20
自动化学报(2019年6期)2019-07-23
中学生数理化·八年级数学人教版(2017年2期)2017-03-25
河南科技(2015年8期)2015-03-11
测绘科学与工程(2014年5期)2014-02-27
