
基于自适应增强的BP模型的浙江省茶叶产量预测
2021-08-12 12:11陈冬梅韩文炎周贤锋吴开华张竞成
茶叶科学 2021年4期
陈冬梅,韩文炎,周贤锋,吴开华,张竞成*
基于自适应增强的BP模型的浙江省茶叶产量预测
陈冬梅1,韩文炎2,周贤锋1,吴开华1,张竞成1*
1. 杭州电子科技大学自动化学院,浙江 杭州 310018;2. 中国农业科学院茶叶研究所,浙江 杭州 310018
本文采用1999—2018年浙江省59个县市的茶叶产量数据和地面气象要素驱动数据,提出了基于产量等级因子的自适应增强的反向传播(BP)神经网络模型的茶叶产量预测机制。首先分析提取了种植面积、年平均气温、3—7月的平均相对湿度、年平均相对湿度等11个影响因子,然后构建浙江省茶叶产量预测模型。试验结果表明,基于产量等级因子的自适应增强的BP模型算法相关系数达到0.893,相对误差的平均值和方差分别为0.187和0.136。在试验数据选取方面,相较于距离预测年份较远的数据,采用临近预测年份的数据,预测精度较高。根据本研究的茶叶产量预测机制,建立了浙江省茶叶产量预测误差空间分布图,其中1级优势区的平均误差为18.32%,2级次优势区为16.73%,3级一般产区为22.69%。预测模型能够实现浙江省各县市的茶叶产量预测,对茶叶生产的宏观管理具有一定指导意义。
茶叶;产量预测;模型;自适应增强;BP模型
浙江省地处亚热带季风气候区,适宜的气候条件使得茶叶成为了省内的支柱产业之一,成为全省各个县(市)山区、半山区农民收入的主要经济来源[1]。茶叶产量和质量是影响茶叶产值和农民收入的重要因素,受多种因素影响,包括光照、降水、温度、湿度、土壤等自然因素和茶叶采摘面积、城市居民茶叶消费价格指数、技术投入等非自然因素[2-5]。因此,评估各因素对茶叶产量的影响,并提供合理有效的茶叶产量预测分析,具有非常重要的现实意义。
农作物产量预测是国内外学者十分关注的课题,其中涉及茶叶产量的预测一般采用统计模型的分析方法,较常采用回归模型、灰色建模和反向传播(BP)神经网络等。朱秀红等[6]从统计角度对影响茶叶产量的气候因子进行分析,在筛选与日照市产量相关性高的气候因子的基础上,建立了多元回归模型对茶叶产量进行预测;高洁煌[7]根据武夷山市历年茶叶产量数据建立灰色模型,对武夷山市2014—2020年茶叶产量进行预测;吕海侠等[8]利用立残差融合的ARMA-GM(1,1)模型对福建省2013—2015年的茶叶产量进行预测;方孝荣等[9]采用灰色马尔柯夫链模型预测浙江省2011年的名优茶产量;胡克满等[2]提出了一种非自然因素影响茶叶产量的预测模型,使用基于灰色神经网络的茶叶产量需求预测算法。这些产量预测模型都是基于灰色模型,针对某一个地区基于时间序列展开的数据,并利用数据自身的时间规律建模分析。在影响产量的诸多因子中,气象因素直接关系到茶叶各生育期的生长状态,是影响产量的关键因素。刘春涛等[10]利用青岛市崂山区1994—2015年的气象站点数据和产量数据筛选分析得到气温、降水量、日照时数、空气相对湿度等是影响崂山茶产量的关键气象因子。张璠等[4]以陕南8个主要产茶县(区)2007—2016年的气象因子和茶叶产量为对象,运用灰色关联分析法得出年平均相对湿度、极端最高气温和平均气温是影响陕南茶区茶叶产量的主要因素。金志凤等[11]根据茶叶产量与气象、地形、土壤条件的相关分析,提出了包含气象、土壤、地形因子的茶树栽培综合区划指标体系,并建立了茶树栽培的综合区划评估模型。赵辉等[12]利用河南省119个气象台站1971—2010年气候资料,筛选出影响茶树生长发育和产量形成的关键气候因子,运用层次分析法和加权指数求和法计算出河南省茶树种植综合区划指数,实现了河南省的气候适宜性区划。这些针对产量估测和影响因素的研究大多基于气象站点数据进行分析,目前没有形成在县市尺度上的多个地区产量预测的方法机制,也没有建立行之有效的浙江省内县市级别的茶叶产量预测分析工作。
本研究利用大尺度的中国区域地面气象要素驱动数据和茶叶种植面积数据,基于浙江省59个县市的茶叶产量数据建立了浙江省县市级别茶叶产量预测机制,引入茶叶产量等级因子,并通过产地不同特征的灵敏度分析提取影响茶叶产量的核心因子,选择有效的时间范围进行茶叶产量预测模型研究,为大尺度的茶产业宏观管控提供一定的科学依据。
把生命交给党,始终不渝、毫不动摇地听从党的安排,这是方志敏树立正确的人生价值观的具体体现。胡锦涛指出:“我们纪念和学习方志敏同志,就要像他那样,树立坚定正确的理想和信念,不论在什么样的情况下,都始终不渝、毫不动摇。”[2]方志敏36岁慷慨就义,其生命虽然短暂,但革命经历非常丰富,哪里需要就奔向哪里,一切听从党的安排。按照上级党组织的安排,他在革命斗争中曾担任过多种不同的工作。无论什么工作,什么样的情况下,他都像胡锦涛所指出的“始终不渝、毫不动摇”。这里,我们可以从《我从事革命斗争的略述》中得到印证。
1 数据与方法
1.1 产量数据处理
本研究统计了全省88个县市地区自1999年以来的茶园面积和茶叶产量数据,数据来自浙江省各县市的统计年鉴。选取了历年平均产量大于100 t的59个县市作为研究对象,全省各地区平均茶园面积和平均茶叶产量分布如图1所示。这59个县市的茶叶总产量占1999—2018年全省平均年产量的98%,茶叶种植总面积也占全省茶叶种植面积的98%,基本涵盖了浙江省的茶叶种植地区。
1.2 气象数据处理
1.3 茶叶产量等级因子
BP神经网络是一种应用广泛的多层前馈型神经网络。这种基于输入层、隐含层、输出层的网络结构,在前向逐层传递过程中,如果输出层得不到期望输出,则反向传播转入到隐含层和输入层,根据预测误差调整网络权值和阈值,从而使预测输出不断逼近期望输出[21]。BP神经网络是基于经验风险最小化原则,满足对已有训练数据的最佳拟合,在理论上可以通过增加算法的规模与复杂度,使得经验风险不断降低,直至为0,但是这会导致过拟合增加实际风险,使得预测结果存在较大程度的失真。
数据不平衡性在预测分析中会造成预测插值以一定的比例体现在最终误差上,从而可能造成在数据密集区产生过拟合,稀疏区域欠拟合[16]。针对这种数据不平衡性,一般从数据层面的采样处理和算法层面的模型改进在分类问题上研究较多[17-19],但在预测回归问题上的分析研究较少[20]。有研究指出,在浙江省,茶叶适宜种植在除嘉兴东南部、湖州的东北、南部高山以及海岛以外海拔低于600 m的平原、丘陵和低山区,较不适宜种植在安吉的西南部、临安和淳安的西部,以及海拔较高的高山区域[11]。本研究引入茶叶产量等级因子,将图1中所标选出来的县市按照年产量信息分成3个等级,产量大于4 000 t的县市划定为1级优势区,1 500~4 000 t的划定为2级次优势区,小于1 500 t的划定为3级一般产区,其中,1级优势区14个,2级次优势区15个,3级一般产区30个(图2)。各等级的产量界限既考虑到茶叶种植的区域适宜度分布,也综合了产量按照等级划定后的各等级的县市数量。

图1 浙江省1999—2018年茶叶平均种植面积和平均产量分布示意图
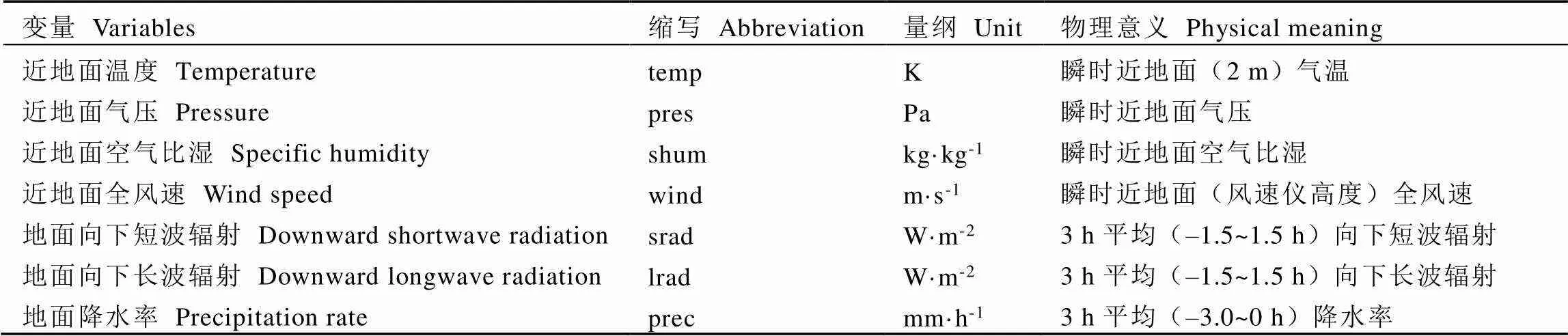
表1 中国区域地面气象要素驱动数据集要素介绍
1.4 基于各县市的灵敏度分析流程
采用近20年的气象月值数据研究与产量相关的潜在影响因子,在气象数据中筛选与产量相关度高的因子。在衡量相关因子过程中,由于各地区的产量分布差异较大,因此提出基于各县市的产量线性相关度分析。首先将各县市的产量信息分别与对应地区的气象信息等因子计算相关系数矩阵,然后将各地区的分析结果组成地区对应变量的产量灵敏度分析矩阵,从每一列中剔除相关度小于0.5的因子对,再统计矩阵中出现次数较多的因子作为核心影响因子,其基本流程如图3所示。
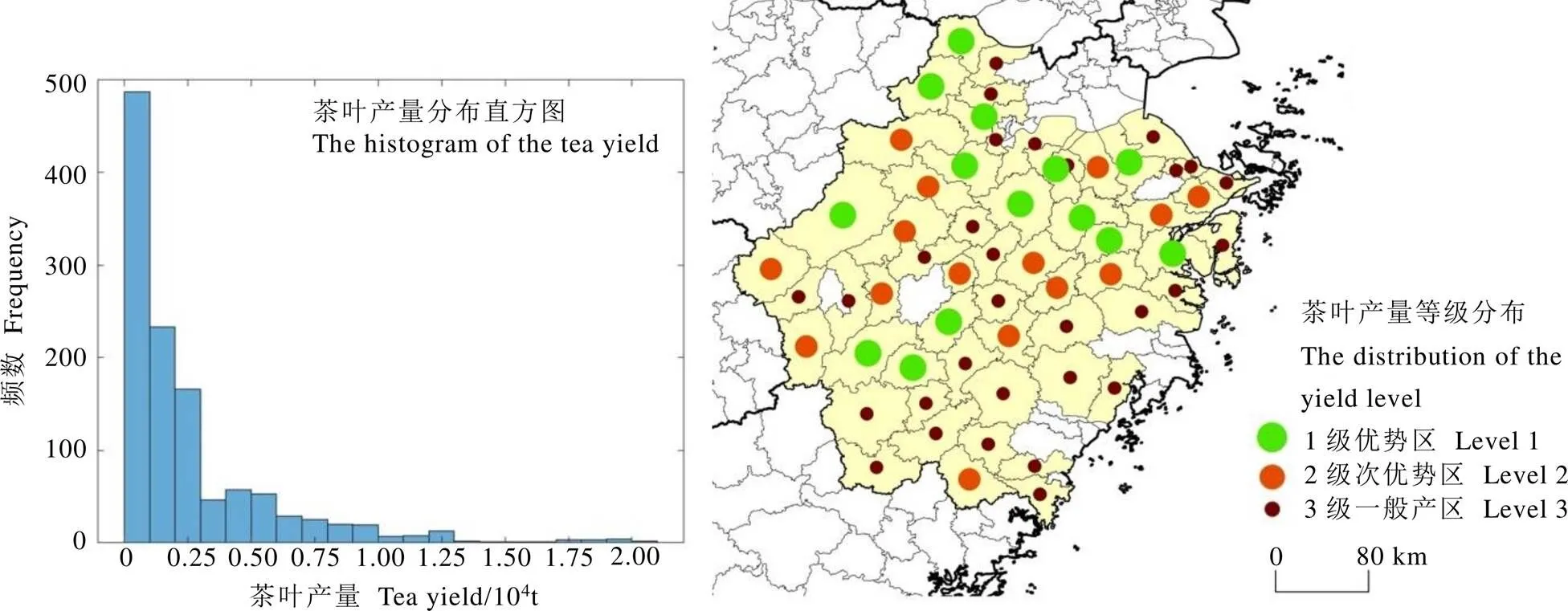
图2 茶叶产量分布的直方图和产量等级分布结果示意图
1.5 自适应增强的反向传播(Adaboost BP)算法
由图1可知,茶叶分布的地域特点会受到土地资源、茶叶种植适宜程度、当地政策等因素影响,尤其是茶叶产量在量级上会有较大变化,其分布范围跨度很大,局部地区年产量仅100多吨,而一些茶叶种植大县年产量高达上万吨。浙江省20年内的各县市茶叶年产量数据分布如图2所示,大部分地区年产量集中在2 500 t以内,极少数地区年产量过万吨,产量在浙江省内地域分布上具有较大的差异性。
Adaboost算法的思想由Freund和Schapire提出[22],源于Valiant提出的PCA学习模型,其核心思想是将多个弱分类器进行组合得到一个联合分类器以产生有效分类,其中BP神经网络被看作是弱分类器[23]。通过训练BP神经网络预测样本数据的输出,再使用Adaboost算法把多个BP神经网络弱分类器构建成强分类器。
图4为本研究对于浙江省茶叶产量的预测回归算法基本流程图,假设样本中有个训练样本{1,2,…,x},f()(=1,2,…,)表示个弱预测器在样本上的输出预测函数,其中训练样本包括各县市的茶叶种植面积和经过灵敏度分析得到的气象因子以及茶叶产量等级因子,通过Adaboost BP算法构建个预测器并进行决策的步骤如下:
在进行实际产量预测时,需要利用历史的产量数据预测未来几年的茶叶产量,而随着时间推移,各县市的茶叶生产种植条件会随之发生变化,距离预测年份时间差越大,条件变化越大,因此在上述试验基础上,需进一步探究足够支撑未来几年数据预测分析的历史数据。本研究使用2016—2018年的产量数据作为测试集合,分别使用表2中的年份组合进行训练。
(1)初始化训练样本{1,2,…,x}的权重w,使得w=1/,=1, 2, …,;
(2)使用BP神经网络弱训练器训练样本得到预测数据f();
预习结束,娟儿问:“什么是力呢?”学生说不清楚具体什么是“力”,他们一脸迷茫地问娟儿:“是推物体,拉物体,压物体吗?”

图4 算法基本流程图
本研究气象数据采用中国区域地面气象要素驱动数据集[12],包括近地面气温、近地面气压、近地面空气比湿、近地面全风速、地面向下短波辐射、地面向下长波辐射、地面降水率等7个要素(表1)。该数据集是以国际上现有的Princeton再分析资料、GLDAS资料、GEWEX-SRB辐射资料,以及TRMM降水资料为背景场,融合中国气象局常规气象观测数据,采用ANU-Spline统计插值而成。该数据时间分辨率为3 h,水平空间分辨率为0.1°,其精度介于气象局观测数据和卫星遥感数据之间,优于国际上已有再分析数据的精度[13-15]。该数据经处理后可以得到多时相的全国范围的气象数据,再根据各县市的边界文件进行分区统计得到各县市的相关要素的月值统计数据,提取出近地面气温、近地面气压、近地面空气比湿、近地面全风速、地面向下短波辐射、地面向下长波辐射、地面降水率等1999—2018年的月值信息。
(6)重复步骤(2)—(5)训练次得到个弱预测器结果f(),将其组合成强预测器;
盐碱地改良是一项紧迫的任务。一方面,耕地高强度、超负荷利用,使耕地质量退化问题突出,像东北黑土层变薄、华北平原耕层变浅、西北地区耕地盐渍化、南方土壤酸化等。我国耕地退化面积已占到耕地面积的40%以上。另一方面,耕地污染问题突出。面对耕地质量的严峻形势,守住18亿亩耕地红线任务艰巨。盐碱地改良将是对我国耕地资源的有益补充。盐碱地利用潜力巨大,已成为我国重要的后备耕地战略资源。
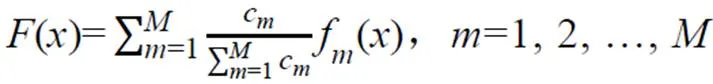
2 结果与分析
2.1 灵敏度分析
经过灵敏度分析后得到的各地区产量对应气象因子的灵敏度矩阵如图5所示。通过灵敏度矩阵剔除相关度小于0.5的影响因子,统计相关度大于0.5因子出现的次数,得到种植面积、年平均地面气温、3—7月的平均空气比湿、年平均空气比湿、7—8月的近地面气压、5—6月的地面向下长波辐射和3—5月的近地面全风速等11个与产量相关的气象因子。这些因子与刘春涛等[10]研究结果有一定的重合度,均包含了年平均气温,茶树生长期的平均相对湿度等。但是本研究中气象数据是使用降水率来反映降雨情况,因此在灵敏度分析中由于相关系数低于其他影响因子被过滤掉。同时,本研究也得到了在茶树生长期的近地面气压、地面向下长波辐射和近地面全风速等其他未在相关文献中提及的气象因子。

注:A为茶叶产量,B为茶叶种植面积,C、D、E、F、G、H、I分别为1—12月的地面气温、地面降水率、近地面空气比湿、近地面气压、地面向下波长辐射、近地面全风速、地面向下短波辐射以及各自的年平均值
2.2 预测方法的有效性分析
经过灵敏度分析筛选,选取11个关键因子并提取各地区的产量数据进行预测模型的有效性分析。在产量数据中随机选取70%的数据作为训练集,其余30%作为测试集,分别使用传统的BP方法和adaboost BP方法进行试验,其中adaboost BP方法中设置了20层、30层、40层和50层4个BP弱分类器进行训练,使用决定系数(2)、预测集合的相对误差的平均值(aveRE)、预测集合的相对误差的方差(stdRE)3个误差指标,得到图6的试验结果。横坐标轴的“标准化的实际产量”是指将所有产量标准化后的值,纵坐标轴“预测结果”指采用不同回归方法得到的预估产量值。为了更加精准的研究气象因素的影响,尽量避免其他因素对茶叶产量的影响,本研究使用气象因子直接与茶叶产量建立关系,结果如图6-A和图6-B所示。由于产量数据在不同地区分布差别很大,导致数据存在一定的不平衡性。针对这种不平衡性,通过引入产量等级因子对数据进行训练和测试,分别得到图6-E和图6-F的结果。结果表明,两种方法中大部分样本都聚集在1∶1线周围,相关系数均达到0.7以上,说明气象因子与茶叶产量之间相关度较高,使用所选的产量相关因子能够有效实现产量预测。同时将图6-A和图6-B与其他结果比较发现,增加茶叶种植面积后2、aveRE和stdRE均得到了改善,说明茶叶种植面积对茶叶产量的预测分析也起到了一定作用。比较图6-A、6-C、6-E和图6-B、6-D、6-F可以发现,不论使用哪种影响因子组合,adaboost BP方法预测结果的2、aveRE和stdRE都优于BP方法。比较图6-E、6-F和图6-C、6-D可以发现,融入了产量等级因子得到的预测精度均比仅包含气象因子的方法好。比较图6-F和图6-D发现,添加产量等级因子后,adaboost BP方法的结果相关度保持一致,但aveRE和stdRE均有所降低,说明基于融合产量等级因子的adaboost BP方法能够更好地克服产量数据分布差异较大的影响,得到较好的预测结果,后续试验均采用这种特征组合进行研究。
2.3 不同年份组合的预测分析
一些旅游网站因为不能满足消费者随时随地的获取最新相关准确信息而使一大批新兴游客更青睐于旅游攻略APP,方便简易,还可以随时随地获取最新相关信息,并可以与其中的一些驴友做一些互动和分享[2]。现有的旅游APP软件存在一些问题,包含内容多而不精,一般单独集中在线路,饮食,住宿领域,对游客而言,我们想去一个景点就是想集合这个景点的所有知识,包括:景点介绍,文化底蕴,去的线路,景点内部导航,游玩攻略,周边美食、住宿等。
结果如图7所示,使用A1—F1组的数据预测精度,2、aveRE和stdRE表现均劣于使用A2—F2组数据的预测结果,说明靠近预测年份的数据更适用于茶叶产量预测。同时,随着年份数的增加,两种方法的预测结果都在变好,说明数据量的增加有助于该方法的学习和训练。其中使用A2—F2组adaboost BP方法的结果2最高,aveRE和stdRE最低,性能表现最好,并且D2组、E2组和F2组表现相差不大。在应用中,结合2、aveRE和stdRE的综合表现,使用2001—2015年数据进行茶叶产量的预测。
人际情绪管理包括反应依赖和反应独立两种机制[6].反应依赖过程有赖于他人反馈的质量.只有对方给予支持性反应时,有情绪困扰的个体倾诉完后才会感觉好些.反应独立过程也发生在社会交往情境下,但并不需要他人做出特定的反应,倾诉本身就可以达到管理情绪的目的.

表2 不同年份组合的训练数据列表

注:A、B分别为不含有茶叶种植面积的BP、adaboost BP方法结果;C、D分别为不包含产量等级因子的BP、adaboost BP方法结果;E、F分别为含有产量等级因子的BP、adaboost BP方法结果。虚线表示1∶1线

图7 使用不同年份信息的预测结果
2.4 误差分布图
基于前述试验结果,采用灵敏度分析后的关键特征组合,利用2001—2015年的产量数据基于adaboost BP方法预测2016—2018年的产量,并计算预测误差的平均相对误差空间(图8)。由图8可以发现,产量较小的地区,误差变大,产量较大的地区误差持续增大。根据浙江省茶叶生长气候分析[11,24],茶树喜温、喜湿、喜阴,对气温、降水和湿度都有一定要求,而浙江省茶叶适宜生长在包括杭州、嘉兴、湖州、宁波、绍兴的平原地带、东南沿海的滨海地区以及金衢丘陵地区,这些地区湿度和海拔适宜、热量充足、土壤肥沃。其中浙江省茶叶的1级优势区的平均误差为18.32%。而安吉的西南部、临安和淳安的西部以及海拔较高的地区热量条件不足,是大部分茶叶产量较低的区域,即3级一般产区的平均误差为22.69%。较适宜茶叶种植的2级次优势区的平均误差为16.73%。在数据集合上,我们根据浙江省各县市茶叶产量的年平均值将59个县市划分为1级优势区14个,2级次优势区15个和3级一般产区30个,由于部分年份茶叶产量的统计缺失,最终得到的数据中1级优势区、2级次优势区和3级一般产区的数据个数分别为273、284和578,3级一般产区数据占比达51%。3个产区的茶叶产量的直方图分布如图9所示,相较于1级优势区和2级次优势区,3级一般产区数据的不平衡性更为显著,茶叶年产量小于1 000 t的数据有424个,占3级一般产区的70%以上。最终的误差分析发现3级一般产区的平均误差为22.69%,说明这种不平衡性会导致3级产区中的预测产量会往数据占比较大的部分靠拢,回归模型的归一化处理和茶叶产量敏感因子尽管能够适当克服数据分布有偏差问题,但是仍然会造成一般产区的数据拟合误差放大,使模型不稳定性增加,产生预测误差。
3 讨论与结论
本研究根据浙江省1999—2018年的各县市茶叶产量,基于气象数据和产量等级因子利用adaboost BP方法进行了预测试验,基于各县市的气象因子灵敏度分析进行了产量影响因子提取,并对结果的空间分布进行了分析,其中通过灵敏度分析得到了种植面积、年平均气温、3—7月的平均相对湿度、年平均相对湿度等11个影响因子。本研究所提的adaboost BP预测方法结合产量等级因子的结果相关度达到0.893,平均相对误差低至0.187;然后通过比较不同年份的组合数据预测2016—2018年产量数据发现,使用临近预测年份数据的预测精度较好,综合误差指标,选择2001—2015年的数据使用adaboost BP方法进行全省茶叶产量预测;通过计算分析全省误差的空间分布,产量较小的地区,误差变大,产量较大的地区误差持续增大,其中1级优势区的平均误差为18.32%,2级次优势区为16.73%,3级一般产区为22.69%,所提出的预测模型能够实现浙江省各县市的茶叶产量预测。
茶叶产量估测是受到多种因素影响的复杂问题[2-7],目前关于茶叶产量预测的工作大多基于灰色模型且针对某一个地区基于时间序列展开。在估测模型中,影响因子如气象因子大多基于气象站点的数据进行分析,尚未形成统一的方法模型能够实现县市尺度的不同产量、多地区的茶叶产量预测分析。
located on 位于……之上,on表示意思是“上面”,on table在桌子上,on roof在屋顶上。
本研究使用了adaboost BP方法,在学习过程中集成了多个BP弱分类器,不仅能够克服BP算法的过拟合问题,也对产量分析这一复杂问题有较好的泛化能力,但是目前中国区域地面气象要素驱动数据集存在持续更新的问题,且分辨率有限,影响这一研究的后续进展。同时,浙江省内各县市产量数据的不均衡性也导致模型训练的不稳定性,需要在后续收集和积累更多年份数据信息的基础上进一步扩充完善样本量,提高模型精度。

图8 浙江省2016—2018茶叶平均产量分布与误差分布的对比分析示意图
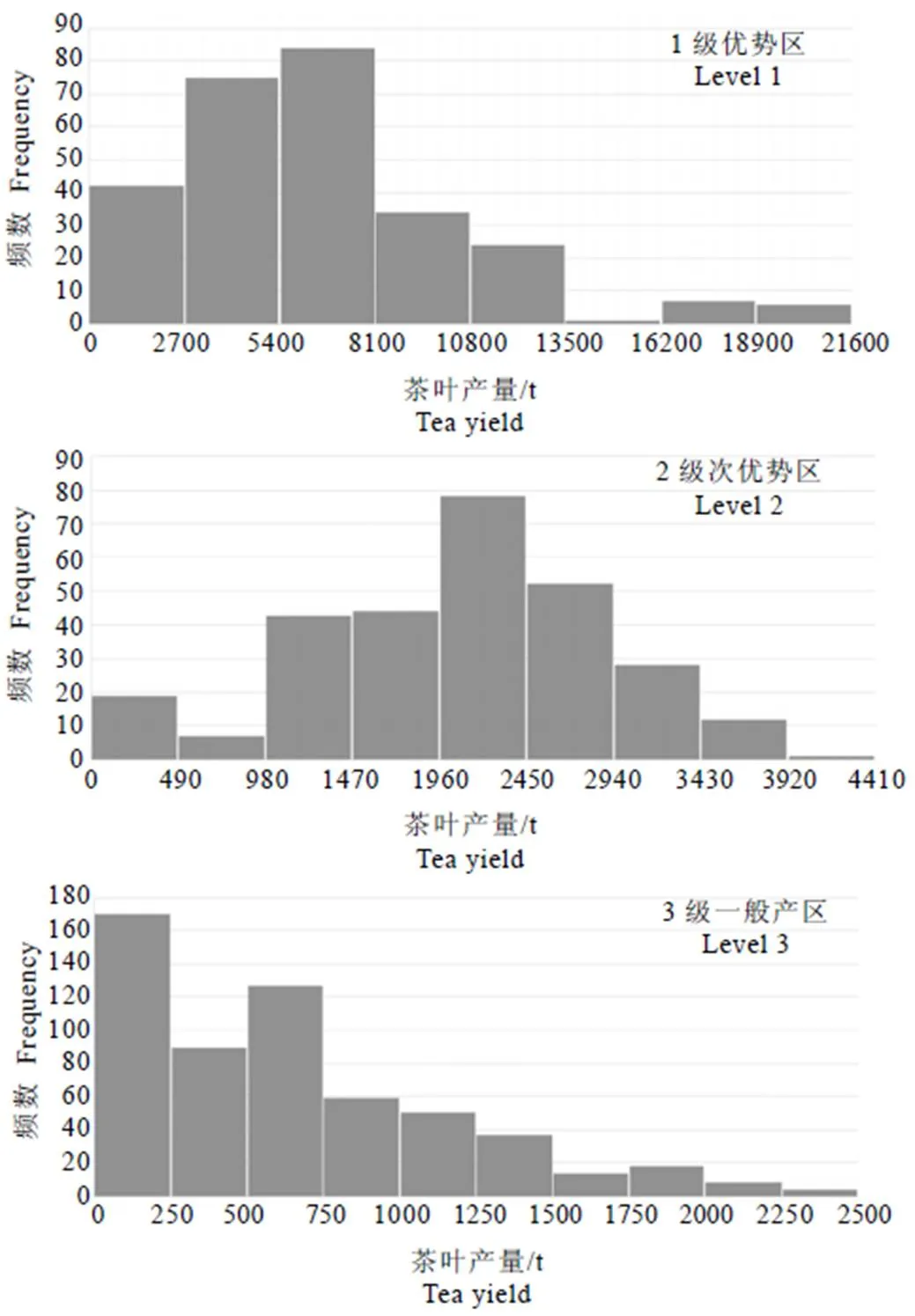
图9 不同产区的茶叶产量的直方图分布
此外,浙江省茶叶从采收季节上主要分为春茶、夏茶和秋茶,其中春茶占较大比重,但统计数据中茶叶种植面积与不同种类的茶叶之间并没有对应关系,并且大部分统计依靠调查获得,只有种植面积而没有采收面积,无法用单产数据来反映茶叶产量。同时,对应的气象数据也需要根据各县市区划边界进行统计计算,这些因素都会对模型精度有所影响。茶园种植受到空间限制,如海拔、经纬度、土壤等因素,这些因素的统计平均值不能反映其对茶叶产量的真实影响。因此,高精度的茶叶面积提取和采摘期的精确分析是提高产量预测精度的必要工作。目前,对于茶园的监测主要是通过人工的野外调绘完成,费时费力,无法持续性监测,目前有不少研究利用遥感技术来监测农作物种植区域[25-26],但是茶树与其他植被容易产生严重的光谱混淆问题[27],增加了提取和分割的难度,关于茶园的精细分割提取研究还有待深入[28-29]。
(2)将种群中的50组解分别带入目标函数,得到全天的列车运行时刻表。计算出列车的全天能耗、变电站负载数据以及列车旅行时间,并将运行结果代入适应度函数,得到每组解的适应值。
有学者在研究自然因素对作物产量的影响时,提出了“气象产量”并建立统计模型[30-31]。茶叶生产种植是一个复杂的经济行为,会受到非自然因素的影响,如收入与支出、国家政策,进出口等。目前,有学者提出将气候因子引进经济学生产函数模型并加以改进,使之符合经济发展规律的模拟结果,从交叉领域角度评价气候、经济等对作物的影响[31-32]。此外,茶叶实际产量除了受气候因子影响外,还受生产茶类结构调整、市场偏好变化、采摘季节的区域性差异等要素影响,在后续预测模型的改进或实践应用中需进一步考虑这些因素的作用。
[1] 毛祖法, 罗列万, 陆德彪, 等. 浙江茶叶产业转型升级基本方略研究[J]. 中国茶叶, 2010, 32(10): 6-9.
Mao Z F, Luo L W, Lu D B, et al. Study on basic strategy of transformation and upgrade of tea industry of Zhejiang Province [J]. China Tea, 2010, 32(10): 6-9.
[2] 胡克满, 胡海燕. 基于灰色神经网络的茶叶产量预测算法[J]. 浙江农业科学, 2019, 60(4): 577-579.
Hu K M, Hu H Y. Yield prediction algorithm of tea based on grey neural network [J]. Journal of Zhejiang Agricultural Sciences, 2019, 60(4): 577-579.
[3] 俞春芳. 中国茶叶生产布局特征及影响因素研究——基于全国408个茶叶生产县的调查[D]. 浙江: 浙江大学, 2018.
Yu C F. Study on the Characteristics and influencing factors of China’s tea production distribution: based on the survey of 408 counties [D]. Zhejiang: Zhejiang University, 2018.
[4] 张璠, 肖斌. 茶叶产量与气象因子的灰色关联度分析——以陕南茶区为例[J]. 西北农业学报, 2018, 27(5): 735-740.
Zhang P, Xiao B. Grey correlation analysis between tea yield and meteorological factors: case study of tea region in southern Shaanxi [J]. Acta Agriculturae Boreali-occidentalis Sinica, 2018, 27(5): 735-740.
[5] 孙智敏. 提高春茶产量的主要技术措施[J]. 福建茶叶, 2003, 25(3): 37.
Sun Z M. Main technical measures to improve the yield of spring tea [J]. Tea in Fujian, 2003, 25(3): 37.
[6] 朱秀红, 郑美琴, 姚文军, 等. 基于SPSS的日照市茶叶产量预测模型的建立[J]. 河南农业科学, 2010(7): 31-33.
Zhu X H, Zheng M Q, Yao W J, et al. The tea yield prediction model based on SPSS statistical software in Rizhao city [J]. Journal of Henan Agricultural Sciences, 2010(7): 31-33.
[7] 高洁煌. 基于GM(1,1)模型的武夷山市茶叶产量预测[J]. 科技视界, 2014(22): 21-22.
Gao J H. Forecast on the tea production of Wuyishan city by GM(1,1) model [J]. Science & Technology Vision, 2014(22): 21-22.
[8] 吕海侠, 赵景惠, 傅霞. 基于残差融合的ARMA-GM(1,1)模型茶叶产量预测[J]. 甘肃科学学报, 2018, 30(5): 24-28.
Lv H X, Zhao J H, Fu X. Tea production prediction under ARMA-GM (1,1) model based on residual fusion [J]. Journal of Gansu Sciences, 2018, 30(5): 24-28.
[9] 方孝荣, 丁希斌, 李晓丽. 基于灰色马尔柯夫链模型的浙江省名优茶产量预测[J]. 农机化研究, 2014, 36(7): 18-21.
Fang X R, Ding X B, Li X L. Yield prediction of famous green tea in Zhejiang Province based on Grey-Markov chain theory [J]. Journal of Agricultural Mechanization Research, 2014, 36(7): 18-21.
[10] 刘春涛, 魏明明, 郭丽娜. 气象要素对青岛崂山茶叶产量影响分析[J]. 中低纬山地气象, 2018, 42(1): 57-60.
Liu C T, Wei M M, Guo L N. The effect of meteorological factors on tea yield in Laoshan [J]. Mid-Low Latitude Mountain Meteorology, 2018, 42(1): 57-60.
[11] 金志凤, 黄敬峰, 李波, 等. 基于GIS及气候-土壤-地形因子的浙江省茶树栽培适宜性评价[J]. 农业工程学报, 2011, 27(3): 231-236.
Jin Z F, Huang J F, Li B, et al. Suitability evaluation of tea trees cultivation based on GIS in Zhejiang Province [J]. Transactions of the Chinese Society of Agricultural Engineering, 2011, 27(3): 231-236.
[12] 赵辉, 米鸿涛, 杜子璇, 等. 河南省茶树适宜种植气候区划研究[J]. 茶叶科学, 2016, 36(3): 330-336.
Zhao H, Mi H T, Du Z X, et al. Study on the climate regionalization of tea plant in Henan Province [J]. Journal of Tea Science, 2016, 36(3): 330-336.
[13] 阳坤, 何杰. 中国区域地面气象要素驱动数据集(1979-2018)[DS]. 国家青藏高原科学数据中心, 2019. doi: 10.11888/AtmosphericPhysics.tpe.249369.file.
Yang K, He J. China meteorological forcing dataset (1979-2018) [DS]. National Tibetan Plateau Data Center, 2019. doi: 10.11888/AtmosphericPhysics.tpe.249369.file.
[14] He J, Yang K, Tang W, et al. The first high-resolution meteorological forcing dataset for land process studies over China [J]. Scientific Data, 2020, 7: 25. doi: 10.1038/s41597-020-0369-y.
[15] Yang K, He J, Tang W, et al. On downward shortwave and longwave radiations over high altitude regions: observation and modeling in the Tibetan Plateau [J]. Agricultural & Forest Meteorology, 2010, 150(1): 38-46.
[16] Moniz N, Branco P, Torgo L. Evaluation of ensemble methods in imbalanced regression tasks [C]//International Workshop on Learning with Imbalanced Domains: Theory and Applications. Proceedings of Machine Learning Research 74, 2017: 129-140.
[17] 孙炜. 基于代价敏感的改进AdaBoost算法在不平衡数据中的应用[D]. 广州: 暨南大学, 2018.
Sun W. The application of improved adaBoost algorithm based on cost sensitive in imbalanced data [D]. Guangzhou: Jinan University, 2018.
[18] Przemysław S, Krawczyk B. Influence of minority class instance types on SMOTE imbalanced data oversampling [C]//International Workshop on Learning with Imbalanced Domains: Theory and Applications. Proceedings of Machine Learning Research 74, 2017: 7-21.
[19] 王来, 樊重俊, 杨云鹏, 等. 面向不平衡数据分类的KFDA-Boosting算法[J]. 计算机应用研究, 2019, 36(3): 807-811.
Wang L, Fan C J, Yang Y P, et al. KFDA-Boosting algorithm oriented to imbalanced data classification [J]. Application Research of Computers, 2019, 36(3): 807-811.
[20] Zhu T, Lin Y, Liu Y, et al. Minority oversampling for imbalanced ordinal regression [J]. Knowledge-Based Systems, 2019, 166: 140-155.
[21] Martin F M. A scaled conjugate gradient algorithm for fast supervised learning [J]. Neural Networks, 1993, 6(4): 525-533.
[22] Freund Y, Schapire R E. A decision-theoretic generalization of on-line learning and an application to boosting [J]. Journal of Computer and System Sciences, 1997, 55(1): 119-139.
[23] Michael K, Leslie G V. Cryptographic limitation on learning Boolean formulae and finite automata [C]//Johnson D S. STOC'89: Proceedings of the twenty-first annual ACM symposium on Theory of computing. New York: Association for Computing Machinery, 1989: 433-444.
[24] 金志凤, 封秀燕. 基于GIS的浙江省茶树栽培气候区划[J]. 茶叶, 2006, 32(1): 7-10.
Jin Z F, Feng X Y. Tea plant climate division in Zhejiang Province base on GIS technology [J]. Journal of Tea, 2006, 32(1): 7-10.
[25] Waldner F, Canto G S, Defourny P. Automated annual cropland mapping using knowledge-based temporal features [J]. Isprs Journal of Photogrammetry & Remote Sensing, 2015, 110: 1-13.
[26] Zhou Y, Xiao X, Qin Y, et al. Mapping paddy rice planting area in rice-wetland coexistent areas through analysis of Landsat 8 OLI and MODIS images [J]. International Journal of Applied Earth Observation and Geoinformation, 2016, 46: 1-12.
[27] Rajapakse R M S S, Tripathi N K, Honda K. Spectral characterization and LAI modelling for the tea ((L.) O. Kuntze) canopy [J]. International Journal of Remote Sensing, 2002, 23(18): 3569-3577.
[28] 杨艳魁, 陈芸芝, 吴波, 等. 基于高分二号影像结合纹理信息的茶园提取[J]. 江苏农业科学, 2019, 47(2): 210-214.
Yang Y K, Chen Y Z, Wu B, et al. Tea garden extraction based on gaofen-2 image with texture information [J]. Jiangsu Agricultural Sciences, 2019, 47(2): 210-214.
[29] 朱泽润. 基于高分辨率遥感影像的茶园场景提取方法[D]. 武汉: 武汉大学, 2018.
Zhu Z R. Tea garden scene extraction method based on high resolution remote sensing image [D]. Wuhan: Wuhan University, 2018.
[30] 刘峻明, 和晓彤, 王鹏新, 等. 长时间序列气象数据结合随机森林法早期预测冬小麦产量[J]. 农业工程学报, 2019, 35(6): 158-166.
Liu J M, He X T, Wang P X, et al. Early prediction of winter wheat yield with long time series meteorological data and random forest method [J]. Transactions of the Chinese Society of Agricultural Engineering, 2019, 35(6): 158-166.
[31] 丑洁明, 叶笃正. 构建一个经济-气候新模型评价气候变化对粮食产量的影响[J]. 气候与环境研究, 2006, 11(3): 347-353.
Chou J M, Ye D Z. Assessing the effect of climate changes on grains yields with a new economy-climate model [J]. Climatic and Environmental Research, 2006, 11(3): 347-353.
[32] 齐邦宇, 方成刚, 王群, 等. 基于经济-气候耦合模型的昆明冬小麦产量评估[J]. 西南农业学报, 2013, 26(6): 2241-2246.
Qi B Y, Fang C G, Wang Q, et al. Study on assessing total winter-wheat yield based on an economy-climate coupling model in Kunming city [J]. Southwest China Journal of Agricultural Sciences, 2013, 26(6): 2241-2246.
Tea Yield Prediction in Zhejiang Province Based on Adaboost BP Model
CHEN Dongmei1, HAN Wenyan2, ZHOU Xianfeng1, WU Kaihua1, ZHANG Jingcheng1*
1. Hangzhou Dianzi University School of Artificial Intelligence, Hangzhou 310018, China; 2. Tea Research Institute, Chinese Academy of Agricultural Sciences, Hangzhou 310008, China
The study proposed the tea yield prediction mechanism using the adaboost BP network model with the tea yield level factor and China meteorological forcing dataset in 59 counties of Zhejiang in 1999-2018. We extracted 11 factors including the planting area, the yearly average temperature, the average relative humidity from March to July in the sensitivity analysis. The tea yield prediction model was established then. The result shows that the adaboost BP method with the yield level factor could reach the correlation coefficient as 0.893 and the average of the relative error as 0.187 and the variance of the relative error as 0.316. When selecting history data, the prediction error was lower when the data was closer to the prediction years. Based on the proposed method, the distribution of the prediction error was made. The average relative errors were 18.32%, 16.73% and 22.69% in level 1 high production area, level 2 medium area and level 3 general production area, respectively. The proposed model could realize the tea yield prediction in the counties of Zhejiang Province and could be used in the management of tea production process.
tea, yield prediction, model, adaboost, BP model
S571;S165+.27
A
1000-369X(2021)04-564-13
2020-08-28
2020-11-17
浙江省公益技术应用研究(LGN19F030001)、浙江省自然科学基金(LQ19D010009)、国家自然科学基金(41901268)、浙江省农业重大技术协同推广计划(2020XTTGCY04-02、2020XTTGCY01-05)
陈冬梅,女,副教授,主要从事农业遥感数据分析处理研究,chendongmei@hdu.edu.cn。*通信作者:zhangjc_rs@163.com
(责任编辑:黄晨)
猜你喜欢
茶叶通讯(2022年2期)2022-11-15
中小学校长(2022年7期)2022-08-19
作文周刊·小学一年级版(2022年24期)2022-06-18
观察与思考(2021年6期)2021-07-25
创造(2020年5期)2020-09-10
中等数学(2018年7期)2018-11-10
领导决策信息(2018年46期)2018-04-20
快乐语文(2018年36期)2018-03-12
智慧与创想(2013年10期)2013-11-28
