
加入大数据产业联盟能促进企业的技术创新绩效吗
——基于社会网络视角的分析
2021-08-12 09:12:30张宏斌周先波王雅维
产经评论 2021年3期
张宏斌 周先波 王雅维
一 引 言
在大数据产业高速发展的初期,由于大数据相关技术的新颖性、复杂性以及难点的分散性,很难有一家企业能够拥有充分的资源与能力独自完成关键技术研发与创新(Powell et al.,1996)[1]。企业需要结成大数据产业联盟,以促进成员之间知识和资源的共享,进行研发合作,有效地解决创新中出现的问题。自2012年中国首个大数据产业联盟——中关村大数据产业联盟成立以来,大数据产业联盟获得了快速的发展,2016年后更是呈现出爆发式增长态势。根据本文调研数据,2013-2015年间,每年新增的大数据产业联盟数量分别为4、4、3个。而2016年一年的增长量就高达13个,超过了前三年增量的总和。2017年中国大数据产业联盟新增12个,增长态势依然不减。截至2018年底,我国共创建了41个大数据产业联盟。
大数据产业联盟不同于其他的产业联盟,具有以下特点:(1)资源的独特性。大数据产业联盟涉及的主要资源是大数据,而大数据具有4V特点,即量特别大(Volume)、种类和格式复杂多样(Variety)、产生和增长速度快(Velocity)、价值特别大(Value),这决定了大数据产业联盟与普通产业联盟的异质性。(2)技术迭代速度快。大数据产业联盟所涉及的技术主要为大数据技术,大数据因为产生和增长速度快,给大数据分析和处理技术带来很大的挑战,要求技术不断更新和迭代。例如最近几年就有强化学习、赋能边缘、数字孪生等新技术的出现和发展。(3)成员独特。大数据产业联盟的成员专注大数据收集、存储、分析与处理、应用方面的研发、生产、服务等,在专业领域上具有独特性。(4)探索性。我国大数据产业联盟处于创建初期,联盟的运作机制、成员活动方式等处于探索阶段。
那么,大数据产业联盟是否会影响成员企业的技术创新绩效?特别是,在大数据产业发展初期,企业加入大数据产业联盟能不能促进其技术创新?成员在联盟中的位置和特征是否对此有影响?早期加入比晚期加入是否更为有利?本文实证研究加入大数据产业联盟与企业技术创新绩效之间的关系问题。首先从企业加入大数据产业联盟的社会网络结构特点(如大数据企业的产业联盟加入数量、自我中心网络密度、网络关系强度、结构洞位置等)出发,提出加入大数据产业联盟会影响企业技术创新绩效的理论假设,然后构建多元线性回归模型和Poisson回归模型,从产业联盟网络结构角度,实证研究大数据产业联盟对企业技术创新绩效的影响。
二 文献评述
(一)产业联盟与企业技术创新
国内外学者在产业联盟与技术创新方面有着较为丰富的研究成果。
初始,学者们主要关注的是产业联盟的定义、成因等基本问题。许多学者从跨组织网络、组织学习或组织创新等不同角度界定产业联盟(Teece,1992[2];Gulati,1998[3]),总结出产业联盟的特征:通过正式合同或者协议确立;其组织形式为跨组织网络;有共同目标;成员企业的角色不同。企业发起或加入产业联盟的主要原因有:(1)共同承担技术研发费用和风险(Miyata,1996)[4];(2)技术、资源共享与资源互补(Miyata,1996[4];Dong和Glaister,2006[5];Tsang,1998[6];Miotti和Sachwald,2003[7]);(3)共同开拓市场(Tsang,1998)[6];(4)知识产权保护(Miyata,1996)[4];(5)推动企业自身的技术创新(Miyata,1996[4];Miotti和Sachwald,2003[7])。
随着产业联盟的不断发展,相关研究不再局限于解析联盟这一组织形态,学者们开始研究以下问题:(1)产业联盟的知识转移(Jensen和Szulanski,2007[8];Szulanski,2000[9];Ario,2003[10])。一方面联盟成员之间的信息、理念和实践的交流与共享促进了知识在联盟成员之间的传递,另一方面产业联盟的组织活动会促进新知识的创造。(2)技术创新(Ario,2003[10];Funk,2009[11])。一些产业联盟的创建目标就是促进产业技术创新,另外联盟成员之间的信息、知识交流和共享也会促进成员企业的技术创新。(3)技术标准(Funk,2009)[11]。一些产业联盟会致力于产业关键技术标准的研制和推广,从而使行业产品遵循统一的技术标准。(4)成员选择和管理标准(Holmberg和Cummings,2009[12];Kale et al.,2002[13])。产业联盟的成员、治理架构和运作机制对于联盟的产出具有重要意义,制定成员选择和管理标准能够保障优质的成员加入联盟,为联盟健康持续发展奠定基础。
国内学者主要关注产业联盟的定义与特征(陈小洪等,2007)[14]、联盟动因(张毅等,2005)[15]、联盟绩效(王蔷,2000[16];郑胜华等,2007[17])、技术创新以及知识管理(曹兴等,2010)[18]等方面。虽然许多研究采用国内的数据进行分析,但其研究结论和国外学者基本一致,曹兴等(2010)[18]的案例研究表明网络异质性不利于联盟的知识转移。
现有研究通常选择产业联盟中企业的专利和新产品作为产业联盟技术创新绩效的衡量指标(Kim和Song,2007[19];潘东华和孙晨,2013[20])。一些学者用专利、新产品、版权、著作权等的数量度量企业创新绩效,研究表明加入产业联盟能够促进企业的技术创新(Gulati,1998[3];Miyata,1996[4];Miotti和Sachwald,2003[7];陈小洪等,2007[14];Rydehell et al.,2019[21];Yu et al.,2019[22]),究其原因在于产业联盟中知识转移与共享、协同合作、资源互补与共享机制。同时,企业在产业联盟中的网络位置会影响企业的创新绩效(Kok et al.,2020[23];Tsai,2001[24];郑向杰和赵炎,2013[25];李琳和吴越,2014[26];魏轩和陈伟,2019[27]),但是也有学者认为这种影响并不是绝对的(Liao和Phan,2016[28];Tan et al.,2015[29]),与企业自身特点以及产业联盟网络特点相关。
(二)创新网络与企业技术创新
关于创新网络对其中企业创新绩效的影响,许多研究得出具有促进作用的结论(池仁勇,2007[30];李奉书和黄婧涵,2018[31];杨博旭等,2019[32];Kim et al.,2020[33];Khraisha和Mantegna,2020[34])。创新网络的概念由Freeman(1991)[35]提出,其范围非常广泛,包括与企业产生任何联系的组织,如供应链关系、投资关系、协作关系、行业协会等。创新网络虽然也是一种跨组织网络,但是其范畴和产业联盟有较大差异,主要表现为以下几点:(1)产业联盟一般由同一产业中的企业或组织所组成,而创新网络中的成员则可能属于不同的产业;(2)产业联盟通常通过正式的合同或协议确立,而创新网络不一定是正式确立的;(3)产业联盟具有稳定的结构和运作机制,成员在联盟中的角色具有差异性,创新网络则不一定明确,成员之间也是平等关系;(4)产业联盟的概念和内核比较明确,而创新网络的概念非常宽泛,几乎所有的组织间关系都可以归属于创新网络。
(三)大数据产业联盟相关研究
全球大数据产业尚处于高速发展初期,到目前为止,有关国内外大数据产业联盟的研究非常少,主要集中在理论框架探索方面。翟丽丽等(2017)[36]、沃强等(2018)[37]针对大数据产业联盟背景下数据资源利用和需求匹配问题,提出了提高大数据产业联盟数据资源利用效率的策略。邢海龙等(2017)[38]构建大数据产业联盟稳定性系统动力学模型探究了对大数据产业联盟稳定性影响较大的几个因素,结论表明数据资源势差和价值量、成果转化、信任等对联盟稳定性的影响比较大。胡艳玲等(2018)[39]探究了大数据产业联盟成员之间资源共享的影响因素和促进大数据产业联盟数据资源共享的策略。
综上研究,产业联盟与企业技术创新、创新网络与企业技术创新方面已有较为丰富和成熟的研究成果,但是创新网络的概念过于宽泛,几乎所有的企业之间的关系都被冠以“创新网络”之名。社会网络理论是研究创新网络的主流理论,而国内外关于大数据产业联盟的研究成果屈指可数,相关实证研究更是空白。本文以大数据产业联盟为研究对象,与创新网络有较大差异,边际贡献主要在于:(1)如引言所述,大数据产业联盟有别于其他组织,具有其独特性;(2)大数据产业联盟创立仅有几年时间,处于初创期,以往文献较少研究初创产业联盟对成员企业技术创新的影响,本文尝试从这一方面切入进行更细致的研究;(3)进一步,本文研究加入产业联盟时期(早加入、晚加入)对企业技术创新的影响,以及企业规模异质性对加入大数据联盟后创新绩效的影响,拓展现有研究。
三 理论基础与研究假设
根据资源基础观理论,企业发起或加入产业联盟能够促进其技术创新(Yasuda,2005)[40]。主要原因在于:(1)技术创新本身就是某些产业联盟创立的主要目标。一些重大技术创新成本高、风险大、需要的资源庞大,单靠一家企业,很难完成。因此,一些企业和其他社会组织组成产业联盟,共同进行该领域的重大技术研发,如美国和日本的半导体技术产业联盟。(2)联盟成员企业在相互共享信息、资源的过程中,可以获得重要的行业知识和信息,激发创新理念,改善创新方法和技巧,促进企业的技术创新。(3)成员企业可以从联盟中获得关键资源,例如从高校或其他研发机构获得研发力量,从核心企业、投资机构获得研发资金,促进企业的技术创新。(4)成员企业可以与联盟中的上下游企业合作,共同促进技术研发和创新。如技术研发企业与拥有市场的成员企业合作,从其获得技术创新的理念和市场方向,并为新研发产品的市场推广布局好渠道。
企业技术创新可以理解为企业综合现有的知识,进一步创造新知识、新产品的过程(Mardani,2018[41];Chuluun et al.,2017[42]),所以知识是技术创新的基础。根据知识管理理论,大数据产业联盟的成立能够促进各联盟成员之间分享各自的组织知识,形成联盟中的知识流动。流动的形式包括人员交流、技术合作、专业知识培训、知识产权转让和授权等等(陈良民,2009)[43]。大数据产业联盟促进成员技术创新的路径可以用Nonaka et al.(2000)[44]提出的SECI模型解释为:首先,联盟成员代表通过参加联盟活动,理解和消化其他成员共享的经验与知识,并转化为自己的知识(Socialisation);其次,代表回到自己的企业,将知识在自己的企业中进行传递(Externalisation);再次,企业内部将显性知识转换为更复杂和系统化的显性知识集合(Combination),这一步就是技术创新,会形成新的技术和产品;最后,所创造的显性知识在企业内部共享,被转换为个体的隐性知识,并表现在其工作中,从而产生企业绩效(Internalisation)。
如前文所述,学术界一般用社会网络理论来剖析产业联盟。社会网络最早由Barnes于1954年提出(孙立新,2012)[45],用于研究人与人之间结成的小群体以及群体之间的关系,随后逐渐扩展至家庭、企业、组织等广义上的个体。本文运用的社会网络理论主要为嵌入性理论和结构洞理论。
网络嵌入性理论由Granovetter(1985)[46]提出,主要包括结构嵌入性与关系嵌入性,它强调个体行为受到其所处社会网络的影响。
结构嵌入性指的是个体在网络中占据一个什么样的位置,网络的规模和密度等。它一方面强调网络整体的结构与功能对网络中个体的影响,另一方面也关注网络中个体所处的位置。根据结构嵌入性理论,网络规模越大,网络的价值越高。这方面最著名的应用是Metcalfe定律(Zhang et al.,2015)[47]——当网络的规模以线性形式增长时,网络的价值将以平方形式增长。
数字经济时代,网络成员的联系更多地依靠计算机网络、微信、公众号等数字化形式连接,加入更多的大数据产业联盟意味着它能够有机会与更多的企业直接联系,从而获取到更多的市场信息、生产资源、技术知识、创意和创新的机会。同时,在与更多的大数据企业建立联盟关系后,企业还能够获得更广阔的市场渠道来推广自己的产品,也能够从更多的企业伙伴那里获得一些创新成功或失败的间接经验,为自身创新增加成功落地的机率。另外,根据结构性嵌入理论,特别是Metcalfe定律,加入一个规模较大的大数据产业联盟能够产生更多的价值。企业的自我中心网络指的是由企业自身以及与其直接相连的其他企业所组成的网络,而企业自我中心网络的规模就是该网络中的成员数量。自我中心网络的规模越大,说明该企业与越多的企业有直接联系,进而可以接触或掌控更多的信息与资源。企业自我中心网络的密度则是网络中的成员数量与联盟整体网络中的成员数量之比,考虑到中国大数据产业联盟整体网络中的成员数量是逐年增加的,本文认为企业自我中心网络的密度能够更准确地反映企业对联盟整体网络中资源的掌控力度。
因此,本文提出以下假设:
H1:企业加入的大数据产业联盟数量越多,越有利于进行技术创新。
H2:企业在大数据产业联盟中的自我中心网络密度越高,越有利于进行技术创新。
所谓关系嵌入性指的是网络中个体之间社会性关系的方向、强度、频率、对称性等属性。在数字经济时代,信息更为丰富和透明,信任关系显得更为重要。根据关系嵌入性理论,企业在大数据产业联盟中的关系强度越高,更能够理解彼此,同时也更容易分享信息、促进合作,从而更能提高企业的技术创新绩效。本文定义两家企业之间的关系强度为同时包含这两家企业的大数据产业联盟数量,也就是两家企业对应节点之间关系出现的次数。因此,本文提出以下假设:
H3:企业在大数据产业联盟中的关系强度越高,越有利于进行技术创新。
结构洞理论由Burt(1992)[48]提出,他认为与关系强弱比起来,个体在社会网络中的位置显得更为重要,因为位置决定了个体获取信息与资源的能力。在一个社会网络中,如果有两个个体一定要通过某一个第三方才能建立联系,那么这个第三方个体在该社会网络中就占据了一个结构洞的位置。根据结构洞理论,企业在大数据产业联盟中占据的结构洞数量越多,获得的联盟资源(特别是数据和信息)将会越多,从而促进其技术创新绩效。因此,本文提出以下假设:
H4:企业在大数据产业联盟中占据的结构洞位置数量越多,越有利于进行技术创新。
另外,2013-2015年是我国大数据产业联盟创立的初期,在此期间加入联盟的企业规模较大、实力较强,具有强烈的创新意识和敢为天下先的精神,同时早期的大数据产业联盟也具有一定的先发优势。因此,本文提出以下假设:
H5:企业越早加入大数据产业联盟,越有利于进行技术创新。
四 数据收集与研究设计
(一)样本选取
本文利用万得数据库、百度等工具,以“大数据产业联盟”为关键词检索获取中国大数据产业联盟名单,进而通过大数据产业联盟的官方网站、微信公众号以及相关新闻报道获取各联盟的成员名单。从2012开始,以年为单位,将每年中国所有大数据产业联盟中的所有企业组成的网络定义为一个图G,企业的集合记为N={1,2,…,n},n表示图G中不同企业的数量。图G中两个不同的节点i和j表示两家企业,如果i和j同处于一个产业联盟中,则ij表示i和j之间的边。根据各联盟的成员名单,本文利用Python的Networkx库构建了每一年的中国大数据产业联盟整体网络,并编写程序对每年整体网络中每个节点(成员企业)的相关属性进行了计算,包括加入的大数据产业联盟数量、自我中心网络密度、关系强度以及结构洞数量等。
我国大数据产业联盟的成员涵盖了政、产、研、学等多类型组织,其中企业占了绝大多数,且本文研究对象是企业的技术创新,因此在大数据产业联盟的所有成员中仅选取企业进行研究。还需注意到,金融服务机构、医疗服务机构、媒体、数据服务机构等服务型企业的核心竞争力并不在于大数据相关的技术研发。因此,这类服务型企业并不属于本文研究的对象,本文仅仅关注业务范围包含开发大数据相关技术的生产或研发型企业。
(二)数据来源
本文选取2013-2016年共计四年的数据来验证假设。之所以选择2013年作为起点是因为2012年中国成立的仅有中关村大数据产业联盟,数据尚不具备代表性。而选择2016年作为截止点主要是考虑到加入产业联盟对企业技术创新产生的影响具有一定时滞性,2017年或者2018年才加入大数据产业联盟的企业,到目前为止的专利数据不足以充分反映加入产业联盟所带来的影响。
对于上述的生产或研发型大数据产业联盟企业,用申请成功的专利数量来表示企业的技术创新绩效,这也是国内外学者常用的方法(Kim和Song,2007[19];潘东华和孙晨,2013[20];Chuluun et al.,2017[42])。本文采用万方数据知识服务平台上的专利数据库检索企业的专利数据,仅选择企业专利数据中的大数据相关专利。
考虑到2013-2016年这段时间内,有不少企业先后加入了多个大数据产业联盟。对于一家企业而言,它在不同年份加入不同的大数据产业联盟时,其所处的产业联盟整体网络环境完全不同,从新的联盟中获益的程度也不尽相同。因此,本文将同一企业在不同年份加入大数据产业联盟的情况作为不同的样本分别纳入研究。
(三)变量说明及模型设定
本文研究涉及的主要变量如表1所示。
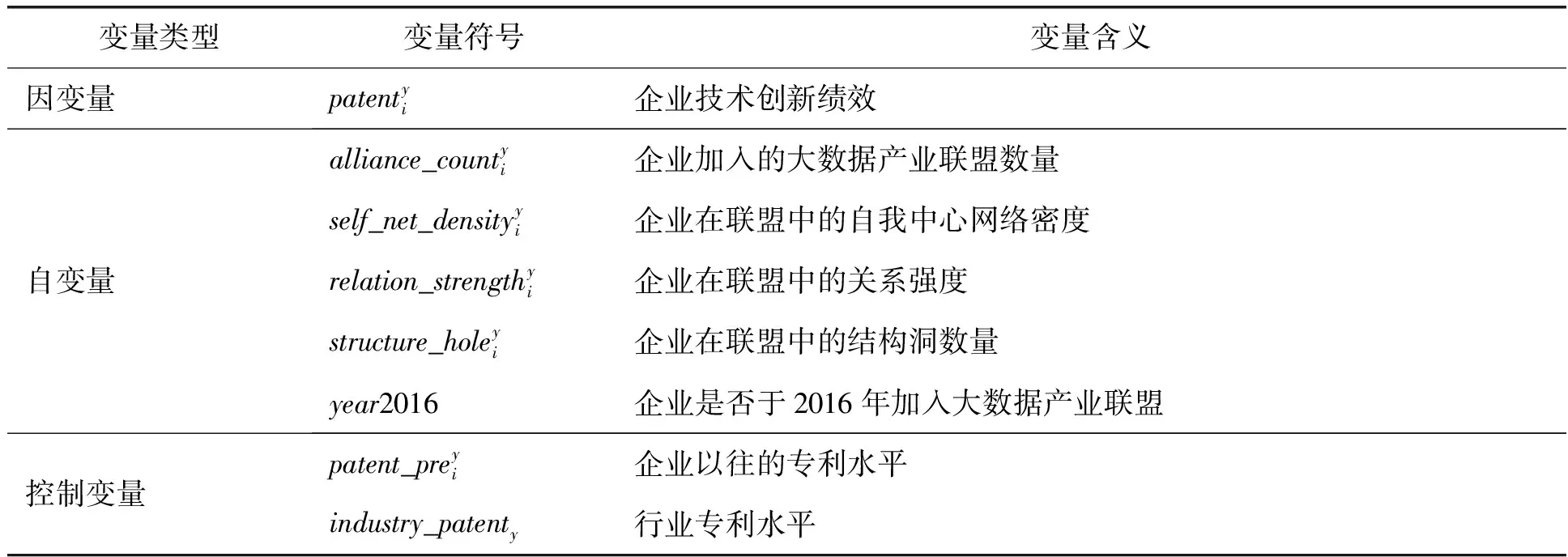
表1 变量定义
各变量的具体度量方法如下:
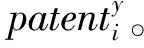
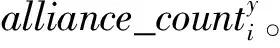
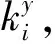
(1)

(2)
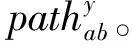
(3)
(6)企业加入大数据产业联盟的时间:本文定义2013-2015年加入的为早期加入,而2016年加入的为相对晚期加入,用虚拟变量year2016表示,若2016年加入产业联盟,则为1,否则为0。
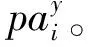
(4)
(8)行业专利水平(控制变量):2013-2016年正是中国大数据产业蓬勃发展的初期,期间行业环境和技术水平发生着日新月异的变化。在万方数据知识服务平台专利数据库上检索发现,2013-2016年这段时间内大数据相关技术专利的数量逐年增长。本文采用从当年起三年内(包含当年)的大数据相关技术专利总数来度量相应年份的行业专利水平,并将它作为控制变量以控制行业整体的发展对企业技术创新绩效的影响,记为industry_patenty。其中三年时间窗的选取是为了与企业技术创新绩效的度量方式保持一致。
基于上述变量,本文构建如下多元线性回归模型,其中i表示企业,y表示企业i加入大数据产业联盟的年份:
(5)
五 实证分析
(一)变量描述性统计
在根据上文阐述的方法得到符合条件的研究数据后,首先对各变量进行初步的统计分析,表2为各变量的描述统计。

表2 变量描述性统计

(续上表)
“企业技术创新绩效”分布在111-1992这个范围的样本量不到10%。这部分专利数量异常高的记录对应的企业大多是一些超大型集团,如:阿里、华为、腾讯、中兴、浪潮等。
截至2016年12月,在中国大数据产业联盟的所有企业成员中,最多有企业加入了13个不同的大数据产业联盟。绝大部分企业(73%)选择加入1-3个不等的大数据产业联盟,仅有少数企业会加入4个甚至更多。
样本中,共有217家企业的自我中心网络密度分布在0.01-0.29这个范围内。而自我中心网络密度高于0.29的企业大多是加入了两个甚至更多的大数据产业联盟,其中自我中心网络密度超过0.70的企业主要是一些大型集团,仅有14家企业。
企业关系强度分布在1.00-1.15这个范围内,其中有约75%的样本关系强度为1。所以,大部分的企业与企业之间的关系仅出现了一次,这与相当一部分企业仅加入1个大数据产业联盟有关,也与一些完全独立存在的联盟有关。
大约有73%样本的结构洞数量为0,这是符合预期的。首先,对于仅加入了1个大数据产业联盟的这部分企业而言,它们只与本联盟中其它企业成员之间存在直接相连的关系,因此没有机会成为两个不同联盟中的不同企业之间不可或缺的桥梁。其次,结构洞位置本身的价值就是来自于它的特殊性和稀少性,即使是加入了两个甚至更多个大数据产业联盟的企业也不一定能在联盟整体网络中占据结构洞位置。
最后,关于控制变量,大数据行业专利水平在2013-2016年这段时间内呈现出逐步上升的趋势,这说明行业整体的发展正推动着大数据相关技术的不断进步。通过将行业专利水平作为控制变量纳入模型,可有效地控制行业整体发展水平对企业技术创新绩效可能带来的影响。
(二)基础回归结果
根据描述性统计分析结果,删除样本中一些异常值对应的记录,进而得到了最后用于进行多元线性回归的样本,共281条观察值。同时,由于各个变量在数量级上差异较大(见表2),对变量进行标准化处理:
(6)
表3报告上述变量的皮尔森(Pearson)相关系数及其显著性。可以看出,因变量企业技术创新绩效与各自变量之间都存在着显著的相关性,将它们纳入模型进行回归分析是合理的。此外,各自变量之间存在不同程度的相关性,基于前文的理论阐述,这样的相关性是合理且符合实际的。由于各自变量之间的相关系数均未超过0.7,自变量之间不存在严重的多重共线性问题。
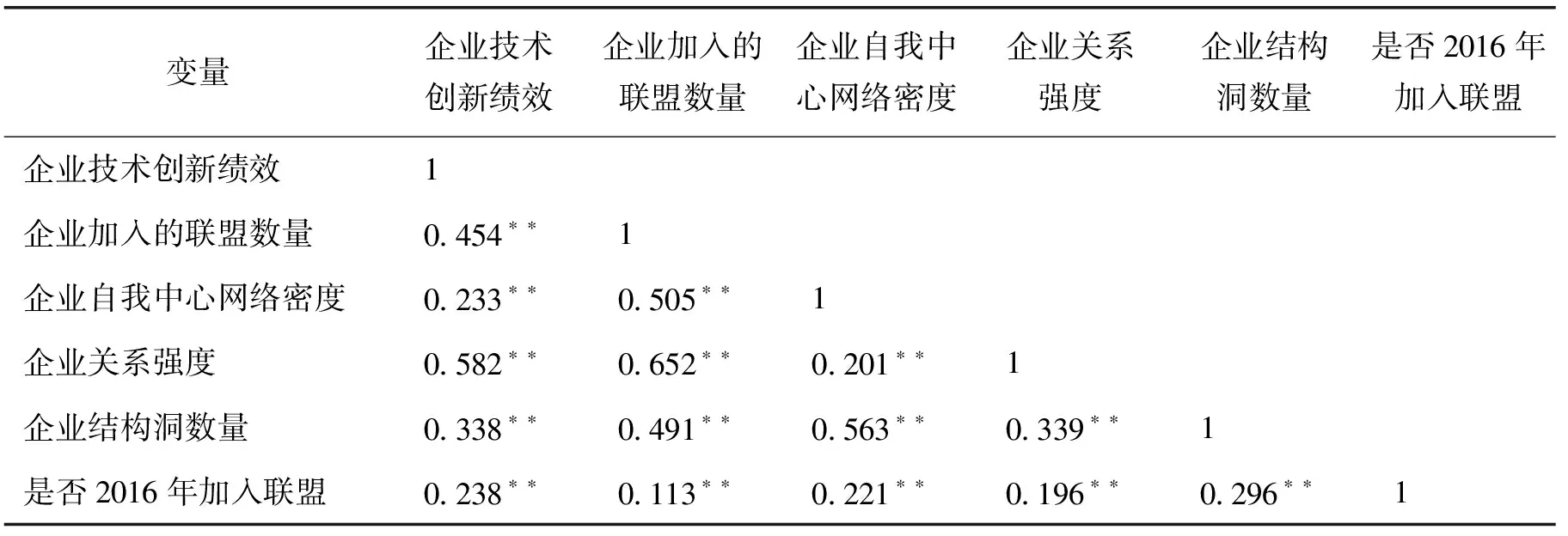
表3 变量的相关性分析
表4为因变量Zscore(企业技术创新绩效)的多元线性回归估计结果。计算各解释变量的方差膨胀因子VIF,发现它们均小于5,故可以认为模型中不存在严重的多重共线性问题。将模型的标准化残差保存下来,通过绘制残差的分位图(1)限于篇幅,此图从略,作者备索。验证了模型的残差基本符合正态分布。由表4的R2可见,各模型拟合比较好,解释变量能够解释因变量中大部分的样本变化(约80%及以上)。各模型整体F检验结果显著,说明各变量联合起来对因变量具有显著的影响,回归方程整体上是有意义的。
由表4结果可见,企业加入的联盟数量、企业自我中心网络密度、企业关系强度、企业结构洞数量的系数估计均在5%水平上显著为正。表明这四个关键变量对因变量均具有显著的边际影响,假设H1-H4得到验证。另外,年份变量year2016的系数估计显著为负,说明较早时期加入大数据产业联盟的企业,其技术创新绩效相对较高,假设H5也得到验证。
从控制变量看,企业以往专利水平对企业技术创新绩效的影响显著为正;行业专利水平的影响虽然也为正,但显著性不高。

表4 线性回归模型估计结果

(续上表)
(三)Poisson回归
上文将企业加入大数据产业联盟后三年的专利数(即企业技术创新绩效)看作连续型变量,运用多元线性回归模型估计结果验证了H1-H5。设定连续型因变量模型式(5)具有一定的合理性,因为在本文研究的样本中,专利数最小为0,最大为973(2)删除6条异常样本后,企业技术创新绩效的最大值由1992变为973。,跨度比较大。不过,专利数毕竟是离散型非负整数变量,从稳健性角度,需用Poisson回归模型作进一步分析。为此,设定专利数patent的Poisson模型如下:
(7)
其中x表示式(5)中的企业加入的联盟数量、企业自我中心网络密度、企业关系强度、结构洞以及控制变量等。用最大似然方法估计得到表5结果。可见,模型m1-模型m4的估计结果同表4一致,四个关键变量的系数均为正,验证了假设H1-H4。不过,与表4结果的区别是,最后一列m5中企业关系强度的系数虽然为正,但变得不显著,即H3虽然得到验证,但其显著性没有得到保证。企业加入大数据产业联盟的年份变量year2016的系数显著为负,同表4,说明较早时期加入大数据产业联盟的企业的技术创新绩效相对较高,假设H5得到验证。控制变量方面,企业以往专利水平对企业技术创新绩效的影响显著为正,这与表4结果一致。行业专利水平的影响显著为负,说明行业总体创新水平的增加会相对降低微观企业的技术创新绩效。
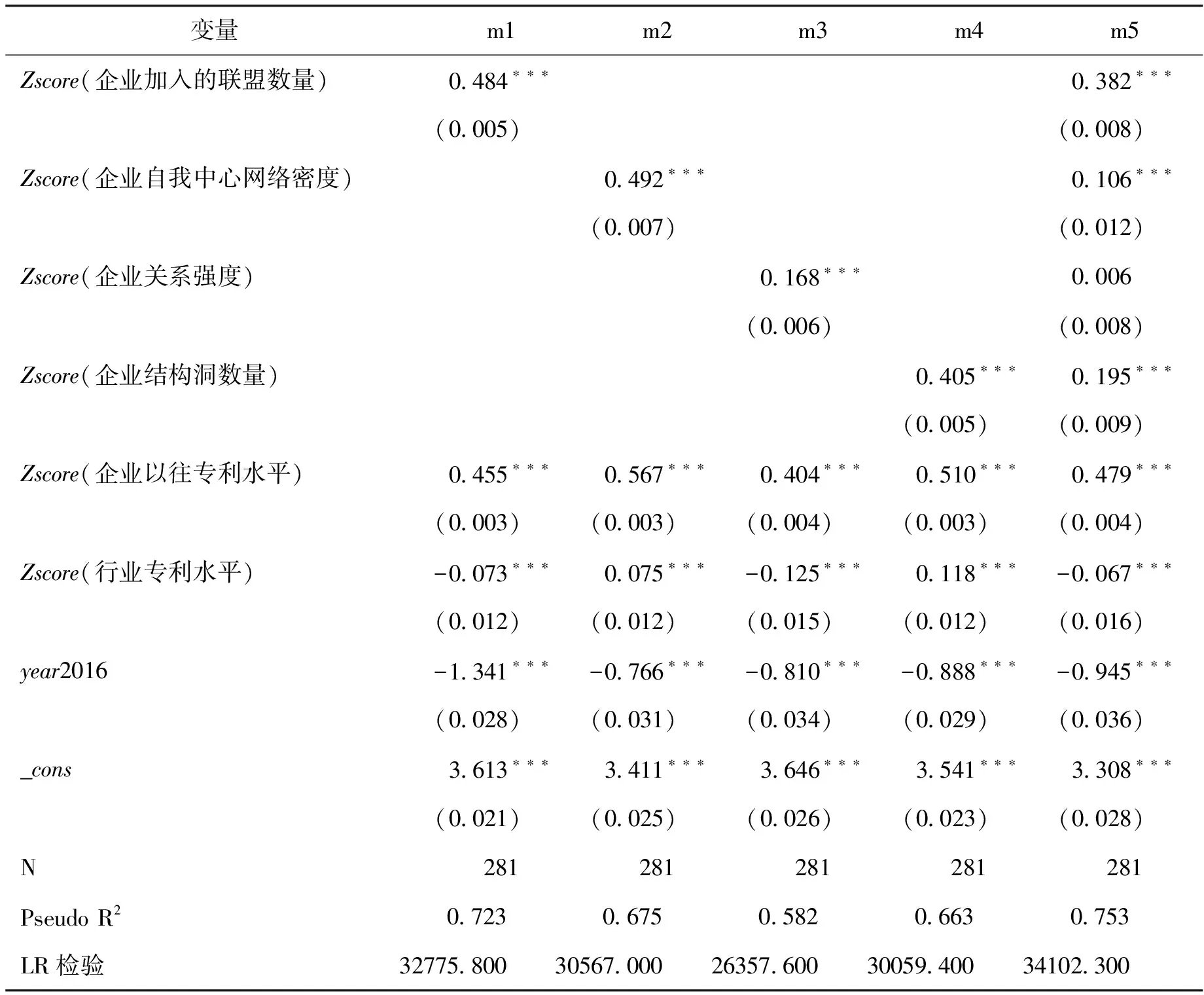
表5 Poisson回归估计结果
表5的系数估计结果与表4中对应的线性回归系数估计结果在数值上具有较大的差异,两者没有可比性。根据表5最后一列计算出Poisson回归的平均边际影响,见表6。可见,四个关键变量对企业加入大数据产业联盟三年内专利数的边际影响均为正,除企业关系强度变量的影响不显著外,其他三个变量的边际影响均显著,同样验证了假设H1-H4,但H3的显著性得不到保证。另外,变量year2016的边际影响显著为负,假设H5得到验证。
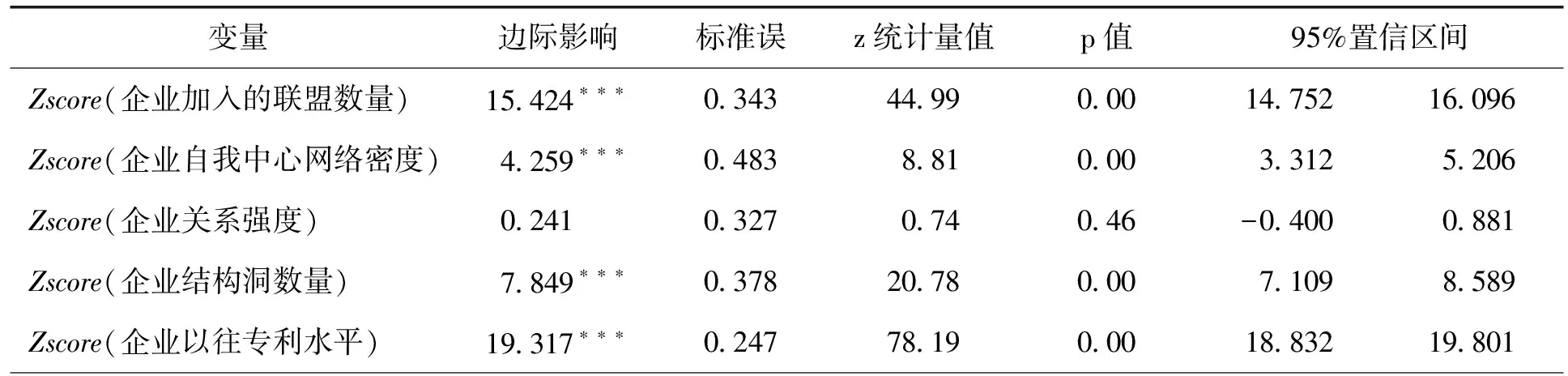
表6 Poisson回归的平均边际影响估计

(续上表)
(四)企业规模异质性
企业技术创新绩效、企业自我中心网络密度的极值主要是超大型集团的存在,那么这种超大型集团对上述实证结果是否起决定性作用?因此,有必要对大数据产业联盟成员企业的规模异质性进行分析。基于数据可得性,选用企业注册资金作为企业规模代理变量,将注册资金大于其中位数的企业记为大企业;否则,记为小企业。分大、小企业样本的OLS和Poisson回归估计结果见表7。
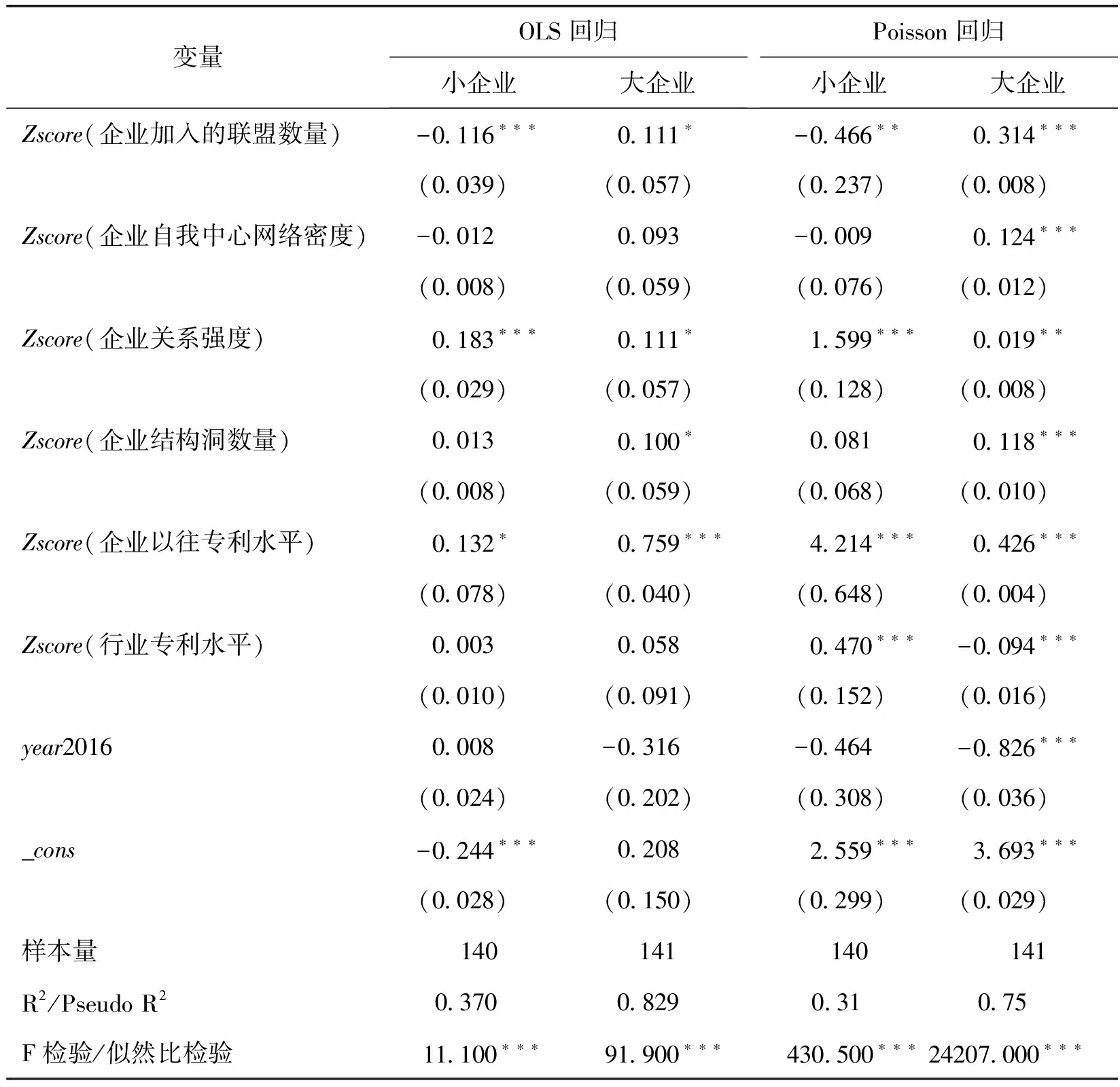
表7 关于企业规模异质性的估计
由表7可见,除企业加入的联盟数量变量对企业技术创新绩效的影响在大、小企业方向相反外,其他变量的影响在方向上基本一致。对于小企业而言,加入的大数据产业联盟数量越多,越不利于其技术创新绩效的提升;对于大企业而言,正好相反。这说明,企业在规模没有足够大时加入多个大数据产业联盟创新效用不突出;只有当规模达到一定水平后,加入多个大数据产业联盟才可增强企业的创新。
(五)内生性分析
研究创新绩效常常会产生内生性问题,与本研究相关的内生性来源有两种。一是遗漏变量,可能是其他因素影响了企业的创新绩效,在模型中没有考虑;二是因果互换,创新绩效越强的大数据企业,其在大数据产业联盟中越可能处于比较有利的位置,模型可能产生因果互换关系的情形。

最后,为进一步验证企业加入大数据产业联盟的效应,利用重复横截面数据的双重差分(DID)模型(Wooldridge, 2017)[50]进行分析。因为样本中企业加入大数据产业联盟的年份有先后,将样本分为两组,2013、2014年加入大数据产业联盟的样本作为处理组,而2016年加入联盟的作为对照组。将2012、2013两年的平均专利数量作为第一阶段的企业技术创新绩效(2013年加入联盟的样本用2011、2012两年的平均值),而将2014、2015两年的平均专利数量作为第二阶段的企业技术创新绩效(2013年的样本用2013、2014两年的平均值)。这样在第一阶段,处理组和对照组都没有加入大数据产业联盟;而在第二阶段,处理组加入了大数据产业联盟,对照组没有加入。比较处理组和对照组在两个阶段的技术创新绩效差异,就可以验证企业加入大数据产业联盟对其技术创新绩效的影响。删除了2015年加入大数据产业联盟的样本,因其无法被清晰地分为两个阶段。这样处理组的两个阶段分别为加入大数据产业联盟前和加入后,而对照组的两个阶段都没有加入大数据产业联盟。构建如下双重差分模型:
Yit=β0t+β1Gi×Dt+β2Gi+β3Dt+μit+εit
(8)
其中Yit表示第i个企业在第t阶段的技术创新绩效;Gi表示企业i所在组别,在处理组为1,在对照组为0;Dt表示阶段,第一阶段为0,第二阶段为1;Gi×Dt为Gi和Dt的交叉项;μit表示可能影响企业技术创新绩效的其他因素,为固定效应,不随时间段(是否加入大数据产业联盟)而变化,εit为独立的误差项。
为了避免多个虚拟变量产生的多重共线性,将上面的模型进行差分,变换为如下模型:
ΔYi=β0+β1Gi+ε
(9)
其中ΔYi表示企业i前后两阶段的技术创新绩效之差,β0表示因时间差异而产生的技术创新绩效,β1表示因加入大数据产业联盟而产生的技术创新绩效。
从表8可以看出,回归结果有效,且β1为7.9083,说明加入大数据产业联盟对成员企业的技术创新绩效影响显著。
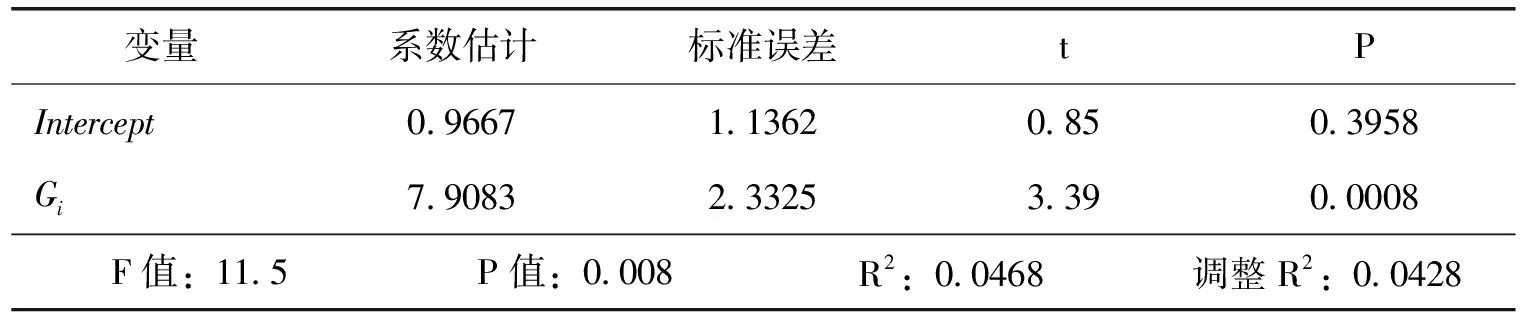
表8 双重差分回归结果
图1表示了双重差分分析结果,直观地说明剔除内生性因素后,加入大数据产业联盟对企业技术创新绩效有着显著的影响,也说明本文模型是合理的。

图1 企业是否加入大数据产业联盟对其技术创新绩效的影响
六 结论与启示
本文研究新创建的大数据产业联盟对成员企业技术创新绩效的影响,通过设定回归模型,对企业加入的大数据产业联盟数量、企业自我中心网络密度、企业关系强度、企业结构洞数量、企业加入大数据产业联盟的时间等影响企业技术创新绩效的因素进行了检验。同时,对大数据产业联盟成员企业规模进行异质性分析。综合得到主要结论为:(1)大规模企业加入越多的大数据产业联盟,越有利于企业进行技术创新。加入多个大数据产业联盟能够使大规模企业与更多的联盟成员形成伙伴关系,进而使企业有机会获取更多的市场信息、市场推广渠道、生产资源、技术知识、创意、创新机会和创新经验,而这些都可以帮助企业进行创新或是增加创新成功的机率。但对于小型企业,加入的大数据产业联盟数量越多,越不利于其技术创新绩效的提升。这说明,企业在规模没有足够大时加入多个大数据产业联盟,反而不利于企业的技术创新。(2)在大数据产业联盟中拥有越高密度的自我中心网络,越有利于企业进行技术创新。企业自我中心网络的密度越高,代表着它与联盟整体网络中更多的其他成员存在伙伴关系,意味着企业能够接触到联盟整体网络中更多的资源。丰富的资源不仅可以帮助企业进行创新,还可以降低风险。(3)在大数据产业联盟中拥有越强的网络关系,越有利于企业进行技术创新。企业与联盟整体网络中其他成员的关系强度越高就意味着双方之间的关系更为紧密、互相更为信任。这样的关系不仅能够降低双方在合作过程中的交易成本,同时也有利于双方进行更为深入的合作以及资源共享,从而促进技术创新。(4)在大数据产业联盟中占据越多的结构洞位置,越有利于企业进行技术创新。对于占据结构洞的企业而言,其他成员对该企业的依赖性可以被视为企业对其他成员的资源拥有了一定的控制力,联盟整体网络中更多的其他成员会积极与该企业维持稳定的关系,使得企业在资源获取、创新合作网络构建、知识共享等方面具有一定优势,有利于企业进行技术创新。(5)越早加入创立初期的大数据产业联盟,越有利于企业进行技术创新。所谓“早起的鸟儿有虫吃”,早期加入联盟的企业具有先发优势,也更具有创新意识,其技术创新绩效会优于晚期加入的企业。
由此得到以下五点启示与建议:
第一,企业和政府应重视大数据产业联盟对企业技术创新的重要作用。大数据企业,尤其是生产或研发型的头部企业,可以通过加入大数据产业联盟获得研发优势。各级政府则可通过制定大数据产业联盟的相关政策,鼓励和促进联盟的设立和发展,以促进大数据产业健康、可持续发展。
第二,企业应合理选择并着力加入大数据产业联盟。规模企业加入大数据产业联盟越多,越有利于自身技术创新。第一次加入大数据产业联盟的企业在条件允许的情况下宜尽可能加入规模更大的联盟,以使企业获得密度更大的自我中心网络,获取更多的信息和资源。企业在考虑加入更大的产业联盟的同时,要考虑新产业联盟的成员中有多少处于自己的中心网络中。只有当新的大数据产业联盟能够为企业自我中心网络带来新成员时,加入其中才能真正为企业带来更丰富的信息和资源。
第三,企业应积极维持与大数据产业联盟伙伴之间的关系。在大数据产业联盟整体网络中企业拥有更强的关系有利于其技术创新。大数据产业联盟企业应与自己深入交流合作的企业保持紧密、稳定、互信的关系。另外,政府可鼓励区域内的大数据企业抱团加入某些大数据产业联盟,共同推动当地大数据产业的发展。
第四,符合条件的大数据企业应尽可能早地加入大数据产业联盟。早加入不仅有利于提升企业技术创新绩效,而且有利于推动大数据产业的发展。
第五,企业应从自身建设出发,在提升规模后再加入多个大数据产业联盟。在规模没有足够大时盲目加入多个大数据产业联盟,会损害企业的技术创新。
猜你喜欢
城市建设理论研究(电子版)(2022年27期)2022-09-30 08:42:22
水运工程(2022年7期)2022-07-29 08:37:38
城市建设理论研究(电子版)(2022年10期)2022-06-08 07:11:48
城市建设理论研究(电子版)(2022年4期)2022-06-08 01:25:34
城市建设理论研究(电子版)(2022年9期)2022-06-07 08:29:06
小学生学习指导(高年级)(2021年4期)2021-04-29 02:17:10
河北理科教学研究(2020年2期)2020-09-11 06:15:48
传感器世界(2019年4期)2019-06-26 09:58:44
数学年刊A辑(中文版)(2015年2期)2015-10-30 01:56:14
新高考·高二数学(2014年7期)2014-09-18 00:42:02
