
基于二级链结构的跨域数据融合溯源框架设计
2021-08-11 08:02祝烈煌
信息安全研究 2021年8期
王 赛 邱 强 王 飞 祝烈煌 冯 吕,4 童 丽
1(中国科学院网络数据科学与技术重点实验室(中国科学院计算技术研究所) 北京 100190) 2(专项技术研究中心(中国科学院计算技术研究所) 北京 100190) 3(北京理工大学 北京 100081) 4(中国科学院大学 北京 100049)
计算系统正从信息空间拓展到包含人类社会、信息空间和物理世界的三元世界,政府数据共享、城市数据治理、海洋态势观测等大数据分析的复杂场景是普遍存在的,在这些场景中往往需要在多层级、跨安全域的环境中完成人在回路的数据融合过程,形成对复杂场景下状态的评估.
区块链是一种去中心化、分布式账本技术[1],具有不可篡改的数据链式结构、多方维护的共识机制、分布式存储的可信透明账本等优点.它的透明可信、防篡改可追溯、隐私安全保障、系统高可靠等特性在信任建立、价值表示和传递方面有不可取代的优势,目前已经在跨行业协作、社会经济发展中展现出其价值和生命力[2],很好地满足了地区、行业、企业间跨域协作的需要.
区块链技术的提出为数据融合的过程控制和结果评估提供了一种透明可信、防篡改可追溯、隐私安全保障的新型技术支撑,但是其作用范围多局限在单个安全域内,难以解决元数据和数据分离存储、跨链的高效率信息协同、多颗粒度融合数据追溯等问题.一方面如何实现跨域数据的充分有效融合,对含有意义的数据进行专业化处理从而实现数据价值倍增;同时如何实现数据和融合产品的全生命周期溯源,对跨域融合过程中涉及的融合任务流程、数据生产过程、用户行为等多层级信息进行安全可靠的溯源分析.
本文基于大数据和区块链技术,研究面向跨域数据融合的二级链构建和溯源方法,为数据安全高效存储和溯源的快速执行提供原理支撑;在此基础上,研究可信接入和存储方式,构建基于二级链的高效存储架构,实现跨域数据的安全高效存储,进一步研究基于二级链的跨域数据可信快速溯源方法,通过证据链和加密搜索,实现对跨域数据融合过程完整信息的快速回溯;最后通过情报溯源场景验证了该方法的可行性及高效性,为跨域数据的安全监管和全生命周期溯源提供支撑,从而为政府数据共享、城市数据治理等场景下的数据融合追溯提供了新的思路指导.
1 现状分析
1.1 国内外研究现状
近年来,区块链技术已从技术探索走向了应用落地的阶段[3].区块链在金融、供应链管理、医疗、媒体、能源、物联网等领域都受到广泛关注.由于其分布式安全可信的特性,尤其在有数据安全存储、分布式记录管理、产品防伪与溯源等需求的场景下得到广泛应用.2017年5月,美国国防高级研究计划局与加密聊天开发商ITAMCO拟合作开发用于军方的安全、不可侵犯的通信平台[4],该平台使用区块链技术来确保消息创建和传输的分离,确保消息不可篡改.马斯达尔科学和技术研究所Aitzhan等人[5]结合传统的区块链技术、多方签名和匿名加密消息流保证电能安全交易与数据安全验证、存储,解决了在分散式智能电网能源交易中提供交易安全性而不依赖于可信赖的第三方的问题.麻省理工学院Azaria等人[6]提出一种使用区块链技术处理电子医疗数据的分布式记录管理系统,可以为患者提供全面的、不可篡改的日志,并能够更快捷访问提供者和治疗部位的医疗信息.世界知名的葡萄酒专家Maureen Downey与Everledger公司[7]一起,利用区块链技术建立了一个名叫Chai Wine Vault的葡萄酒防伪和打假系统,以改善葡萄酒行业的原产地跟踪等问题.
国内,目前利用区块链实现分布式安全存储、溯源,已经进入了医疗、智能电网、供应链溯源、城市数据治理等研究与应用阶段.祝烈煌研究员等人[8]对基于区块链技术实现隐私保护展开研究.张亚娇等人[9]构建基于区块链的医疗数据安全存储模型,通过分布式存储及传播机制,创建了一种大规模、安全的端对端信息交互方式.Gai等人[10-11]提出了一种适用于智能电网的模型许可区块链边缘模型PBEM-SGN,通过结合区块链和边缘计算技术来解决智能电网中的隐私保护和能源安全问题.Zheng等人[12]研究基于区块链的可信数据共享方案,通过使用区块链技术来防止共享数据被篡改,并使用Paillier密码系统来实现共享数据的机密性.周艺华等人[13]基于区块链将访问控制和链外存储结合实现用户数据的管理授权,减少通信和存储开销.赵剑等人[14]提出了一种双区块链模型,将用户信息与交易记录分开存储在2条链上,提高数据安全性,将交易链数据单独处理提高医疗数据共享性.张朝栋等人[15]开发出了一种基于侧链技术的供应链溯源系统.通过以太坊智能合约实现供应链中的货物管理、信息共享与产品溯源,利用侧链技术对以太坊进行扩容,使其满足实际应用的需求.
传统区块链架构并未考虑跨链需求,导致不同技术底层的区块链间存在较强的封闭性,缺乏统一的互联互通的机制,链上数据/价值难以在不同行业、不同场景之间流动,极大限制了区块链技术和应用生态的健康发展,文献[16]对近年跨链技术领域的成果进行了系统总结,分析了跨链技术的需求及面临的技术难点.经过几年的发展,现有的跨链交易技术可以分为公证人技术、中继技术和分布式私钥控制技术.
基于公证人技术,BitXHub[17]平台基于链间互操作的需求提出了一种通用的链间消息传输协议, 基于该协议实现了同时支持同构及异构区块链间交易的跨链技术示范平台BitXHub,允许异构的资产交换、信息互通及服务互补.中继技术最初来源于“侧链”技术,侧链技术的主要缺陷是扩展能力.Btc-Market[18]通过以太坊上的智能合约,实现了“运用比特币购买以太币”的功能.以太坊内的智能合约[19]将接收交易所在区块的区块头以及必要的验证消息,在验证比特币交易有效性后,将以太币转入购买方的以太坊账户.Fusion[20]提出了一种新的跨链技术——分布式私钥控制技术.Fusion的目标是创建一个所有区块链之上的管理层,允许这些区块链的互操作.
1.2 问题与挑战
区块链技术经过十几年的发展,已经在城市公共服务、政府大数据治理、情报溯源等场景下得到广泛应用,但伴随以下诸多问题,例如:1)数据安全问题.来自不同安全域的数据包含各自敏感信息,且可能安全等级要求不同,需要采取不同密级保护措施,以防敏感数据泄露.2)数据的可信问题.需要保证数据的完整性、正确性,防止被篡改删除导致数据不可信.3)数据的溯源,保证跨域数据融合过程中各环节按时序、处理逻辑、数据使用者等进行追溯过程等层层关联.
2 跨域多级数据融合模型
在大数据系统构建中,数据来源众多、量级巨大、层次混杂、模态多变,数据和融合产品往往需要经过人在回路的跨域、多层级融合过程,该过程中,原始信息、过程信息、应用信息等都停留在各分域、分层级的系统中,在融合上报之后,数据和融合产品的监控、加工和消费人员难以对融合任务流程、数据生产过程、用户行为等进行全生命周期溯源分析,给融合产品的质量评估和数据融合过程中的问题辅助诊断带来了极大的挑战.
数据溯源是解决数据和产品全生命周期溯源分析的关键:第一,能够将生成的数据标签进行分布式的存储,保证数据和产品溯源信息的高效取用;第二,能够保证溯源信息在分域、分级处理过程中不被篡改、可靠取信;第三,能够针对数据和产品按照时间顺序、处理逻辑、应用部位等进行追溯过程的层层关联;第四,既可为产品提供量化的使用依据和辅助诊断融合过程中产生的问题,也可基于用户反馈反向判断产品的真实应用价值.
基于上述跨域数据融合溯源的场景,构建下列跨域数据多级融合模型:
1) 包括中心、一级分域、二级分域;
2) 数据素材从各级分域加入,各级分域会监控、加工、消费、审核、上报等等;
3) 一方面,当融合数据产品产生效果,需要对提供贡献的人或者数据素材追溯,另一方面,当融合数据产品产生问题,需要对问题环节进行诊断;
4) 需要围绕某一主题、某一级别的素材或者数据进行双向多次追溯的交互式可视化,以透视信息流程.
3 基于二级链结构的跨域数据融合溯源框架设计
基于二级链结构的跨域数据融合溯源框架,主要包括跨域数据统一编码设计、跨域溯源协议设计、跨域数据上链机制设计、跨域数据快速溯源设计、跨域数据融合溯源应用流程设计.框架采用主链和副链结构,副链存储各个部门对数据生产过程中所有副本的溯源记录,主链中存储数据产品和素材所有溯源信息的哈希以完成对数据溯源信息的校验功能.主链可以是不同数据域共同创建和维护的联盟链.副链为数据域自身创建并维护.不同数据域可将数据产品生产的中间环节的数据存储在副链中,并将数据产品存储在主链中.
3.1 跨域数据统一编码设计
设计数据统一编码,统一管理并维护各类数据信息的各类编码资源,为所有数据标记唯一码,为溯源提供支撑.唯一码编码规范如表1所示:
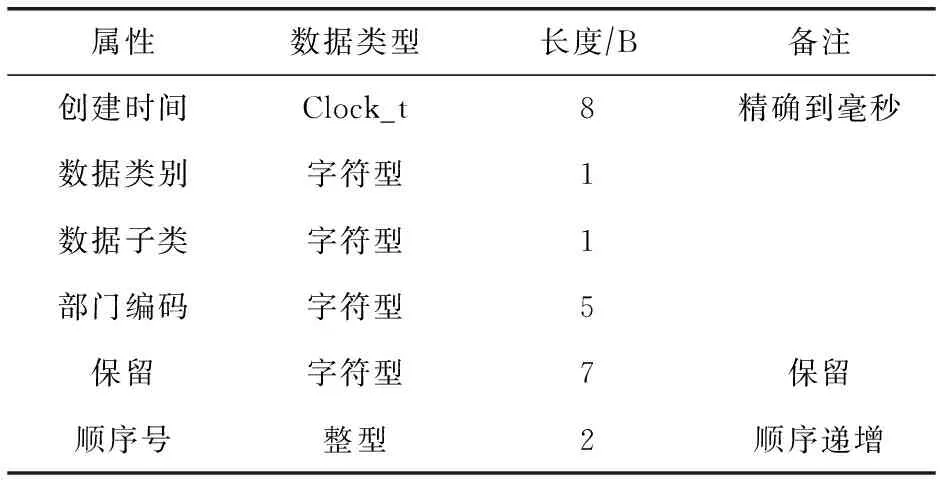
表1 唯一码编码规范
3.2 基于二级链结构的跨域溯源协议设计
设计基于二级链结构的跨域数据可信溯源协议,按照跨域数据产品的生产流程,所有环节可分为任务下发、生产加工、数据上报,每个环节中的参与部门的数字签名、哈希生成的标签信息等都标注到数据中,保证数据的处理环节都有迹可循,为数据溯源提供支撑,防止非法修改,提高系统的安全性.
对于某数据,任务部门Ti将向副链加入的生产计划信息包括:
1) 数据的任务信息T;
2) 数据的ID(唯一标识符);
3) 相关负责人的数字签名STi;
4) 任务T通过哈希运算生成的标签信息,如图 1所示:

IDTSTiH(T)
生产部门(可包括创建、修改、审核等过程)将向副链中加入该部门负责的溯源信息,该信息包括:
1) 生产过程中各生产流程产生的信息Pi(包括数据元数据);
2) 数据的ID(唯一标识符);
3) 该部门相关负责人数字签名SPi(为了能够追溯数据质量问题的相关责任人,需要添加相关分域签名);
4) 数据生产信息通过哈希运算生成标签信息H(P),如图2所示:

IDPiSPiH(Pi)
如图3所示,上报部门加入的溯源信息包括:
1) 副链中该数据生产过程中所产生的所有标签值作哈希运算,生成该数据的标签;
2) 数据的ID(唯一标识符);
3) 数据产品的信息(产品元数据)R;
4) 上报部门的数字签名.

IDSRiH(R)H(H(T, STi),H(P1, SP1),…,H(Pn, SPn),H(R))
在生产流程的最后一个部门完成对副链的存储操作时,上报部门X将副链中该数据生产过程中所产生的所有标签值(溯源信息的哈希值以及各个部门的哈希作哈希运算生成该数据的标签H(R)=H(H(T,STi),H(P1,SP1),…,H(Pn,Pn),H(R))并将其存储到主链中.对每一件数据产品,上报部门X都会生成一个该数据的ID,并将上报部门的数字签名发送给主链.若数字签名合法,主链将该ID存储在主链中.对每一件数据,上报部门会为其生成一个链接T,该链接用于在副链及主链中查询数据溯源信息.
在上报数据时,上报节点将上报信息S及该节点的数字签名发送给主链,主链判定数字签名是否合法,若合法则将上报信息存储在主链系统中.上报信息包括上报时间、上报地点、上报人等信息.
3.3 基于二级链结构的跨域数据上链机制设计
3.3.1 二级链构造
各溯源节点在获得上一溯源节点提供的溯源信息后,将新的溯源信息及本节点的签名存储到溯源系统中.溯源记录的存储结构如图4所示.

图4 溯源记录的存储结构
数据的溯源信息由数据任务、生产、上报环节的各节点加入,各溯源节点需要添加:溯源信息(溯源信息及ID)、该节点对溯源信息的签名S(为了能够追溯数据质量问题的相关责任人,需要添加相关部门签名)、上一溯源节点所提供信息(包括溯源信息及签名等)的哈希值、溯源信息,该溯源节点对溯源信息的签名一起作哈希运算得到的哈希值.厂商或溯源节点可通过验证各阶段的溯源信息与签名、哈希是否匹配、验证存储信息是否合法.为方便查询完整数据的溯源信息,每一个节点加入的溯源信息还应该包括一个transaction_id,其作用将在副链与链外文件存储系统中描述(若为第1个溯源节点加入的溯源信息,该值为空).溯源节点将溯源信息存储到链外文件存储系统中,并将上述信息的哈希通过交易存储到所述的副链系统中.
各个部门加入溯源信息的过程如图5所示,各个部门需要向副链中加入溯源信息、自己对溯源信息的签名以及上述两者的哈希值.

图5 加入溯源信息流程
溯源记录包括以下步骤:
1) 任务部门提出任务T,计算出任务的哈希H(T)并签名该任务,任务T及其签名和任务的哈希H(T)存入到副链中.
2) 各生产部门将生产过程中产生的信息(如数据原始信息、数据元数据、操作记录、数据标签)构建区块存储于副链中,并对这些数据进行签名,生成哈希存储于副链中.对于每件数据产品和素材,上报节点将数据ID、副链中对应信息的哈希值以及上报节点的签名构建可验证的标签信息并将其存储于主链中.
3) 在溯源协议中,数据使用人员、溯源部门和其他相关人员都能够在副链位置上获得详细的生产信息.溯源人员可以通过主链的哈希值、数据编号等信息与对应的副链的数据进行检查,确认副链数据是否被恶意篡改.若有篡改,则副链对应的哈希值与主链中对应的哈希值不同.
构建一个与链外文件存储系统相结合的副链系统,用于存储数据各个生产阶段及上报阶段的信息.详细溯源信息及相关责任人签名将存储在链外文件存储系统中,而对应的哈希值存储在副链中.与主链相比,副链是一种高效、大容量的信息存储方式.多条溯源信息的哈希值被封装在一个区块内,存储在副链中.溯源系统再通过智能合约将该区块的哈希值存储在主链中.链外文件存储系统中同时存储该区块的备份,可用于副链的数据恢复.溯源过程中,可对副链中各区块数据的哈希与主链中存储的各区块的哈希进行对比检验,确保副链中的数据不被篡改.若本地副链被篡改,可通过主链中相关哈希值在链外文件存储系统中获取被篡改区块的原始信息,实施副链的修复,提高系统安全性与可靠性.
3.3.2 基于安全等级的跨域数据可信接入
链外数据接入区块链存储平台的基本流程如图6所示,将负责用户身份创建的认证中心作为一个可信的密钥管理机构.认证中心负责密钥的生成和分配,并通过基于智能合约的访问控制模块判断申请密钥的用户是否具有足够的权限.产生数据的用户需要将数据的基本信息和自己的账号信息发送给认证中心,认证中心通过调用基于智能合约的访问控制模块验证用户权限,如果验证通过则生成加密密钥返回给用户,并在本地数据库中记录用户的账号信息和密钥信息.
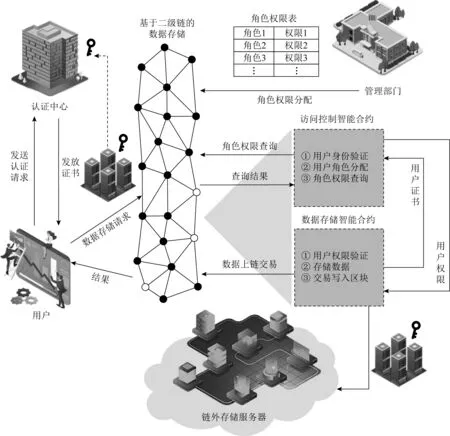
图6 数据存储基本流程示意图
3.3.3 跨域数据的记录存储与校验
链上存储方式通常应用于安全等级较高且规模较小的数据.此类数据将由产生数据的用户写入区块链中.其他有权访问这些数据的用户必须验证权限才能够获取到数据原文.
链外密文存储通常应用于安全等级高且规模较大的数据.鉴于区块链并不适用于大规模的数据存储,采用链上存储与链外存储相结合的方式处理此类数据.具体地,数据的源地址、数据哈希等信息将保存在区块链中,原始数据则保存在数据产生单位的服务器中.拥有访问权限的用户首先从区块链上获得相关数据的源地址和数据哈希等信息,用户向链外存储服务器发出数据请求.链外存储服务器接收到请求后,将通过基于智能合约的访问控制模块验证用户是否具有足够的权限,若验证通过则将数据返回给用户.
3.4 基于二级链的跨域数据快速溯源方法设计
采用链式结构对跨域数据全生命周期进行监管,可利用保存的不可篡改的数据进行溯源.需解决以下问题:
1) 如何快速地从存储在链式存储结构上的大量数据中找到指定数据或者数据产品的相关数据;
2) 数据和融合产品的监控、加工和消费人员难以对融合任务流程、数据生产过程、用户行为等进行全生命周期溯源分析.
针对上述问题,设计二级链结构,利用哈希指针将指定数据的所有数据链接起来,从而使用户能够便捷且快速地获取指定数据在整个生命周期中的全部数据资料.同时,利用数据签名和数据哈希来保证溯源结果具有不可伪造、不可抵赖的特性.
为了能够在大量链式结构事务中快速定位特定数据的相关数据资料,设计链式结构存储数据.存储在链式结构上的数据以事务记录为基本单元.事务记录中不仅包括数据资料,还包括该数据的前序数据的哈希指针.依据哈希指针依次查找前序数据,用户可找到一个数据在链式结构上的所有资料.例如,当数据出现质量问题时,管理机构可首先利用数据编号在链式结构中找到包含该数据使用信息的链式结构事务.然后,根据该链式结构事务中的前序哈希指针,找到该数据在生产阶段的相关数据资料.基于这种链式数据结构,管理机构能够找到该数据的所有制作记录、使用记录、分发记录和共享记录.此外,由于跨域数据在上链时会附上数据提供者的数字签名和数据哈希,基于链式结构数据得到的溯源结果是可靠的,相关人员也无法抵赖.
溯源系统中的各个节点将溯源信息添加到副链及链外文件存储系统中.生产单位对每一件数据生成标签信息,通过数据唯一码可以查询标签信息,标签信息包括tid以及address.tid为指向副链中记录数据溯源信息最后一个交易的transaction_id的链接;address为链外文件存储系统与数据关联的副链中的账户.为方便查询数据的完整溯源信息,每一个溯源节点加入的溯源信息必须包括一个交易号transaction_id(若为第1个溯源节点该值为空)用于匹配对应的交易.如图7所示,图中的transaction_id为副链中的某次交易的交易号,该交易存储了上一溯源节点所记录溯源信息的哈希.因此,可以根据该哈希值从链外文件存储系统获得上一溯源信息.
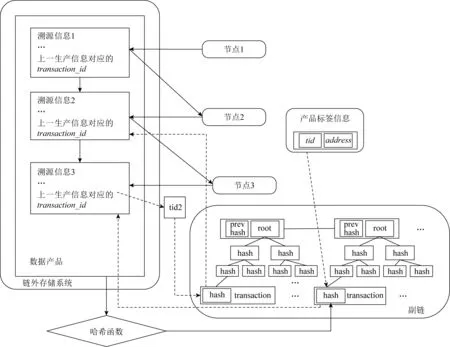
图7 利用transaction_id查找上一溯源信息
3.5 基于二级链的跨域数据融合溯源应用流程设计
当数据出现质量问题时,管理单位可结合数据的实际问题和链式结构上的编制、修改、审核、上报、引用等过程数据,快速定位问题原因,帮助优化数据处理过程中的环节.
如图8所示,链式结构上数据追溯的基本流程如下:
1) 管理单位获得问题数据的唯一标识符;
2) 根据唯一标识符,管理单位在主链式结构中查询该标识的事务记录;
3) 根据跨域主链中事务记录中的链接关系,构建该数据的全生命周期数据流转视图,流转视图包含该数据跨三级整个生命周期的所有引用素材和上报产品.
通过流转视图,管理单位可以逐一检查在副链域内中数据产品生产各个环节的资料,审核相应的素材、半成品、数据产品.
由于链式结构中的数据不可篡改、不可伪造,管理单位能够获得全面的、具有高公信力的过程数据,避免传统追责机制中数据丢失、数据伪造、推卸责任等问题,从而可有效缩短定位问题原因的时间.
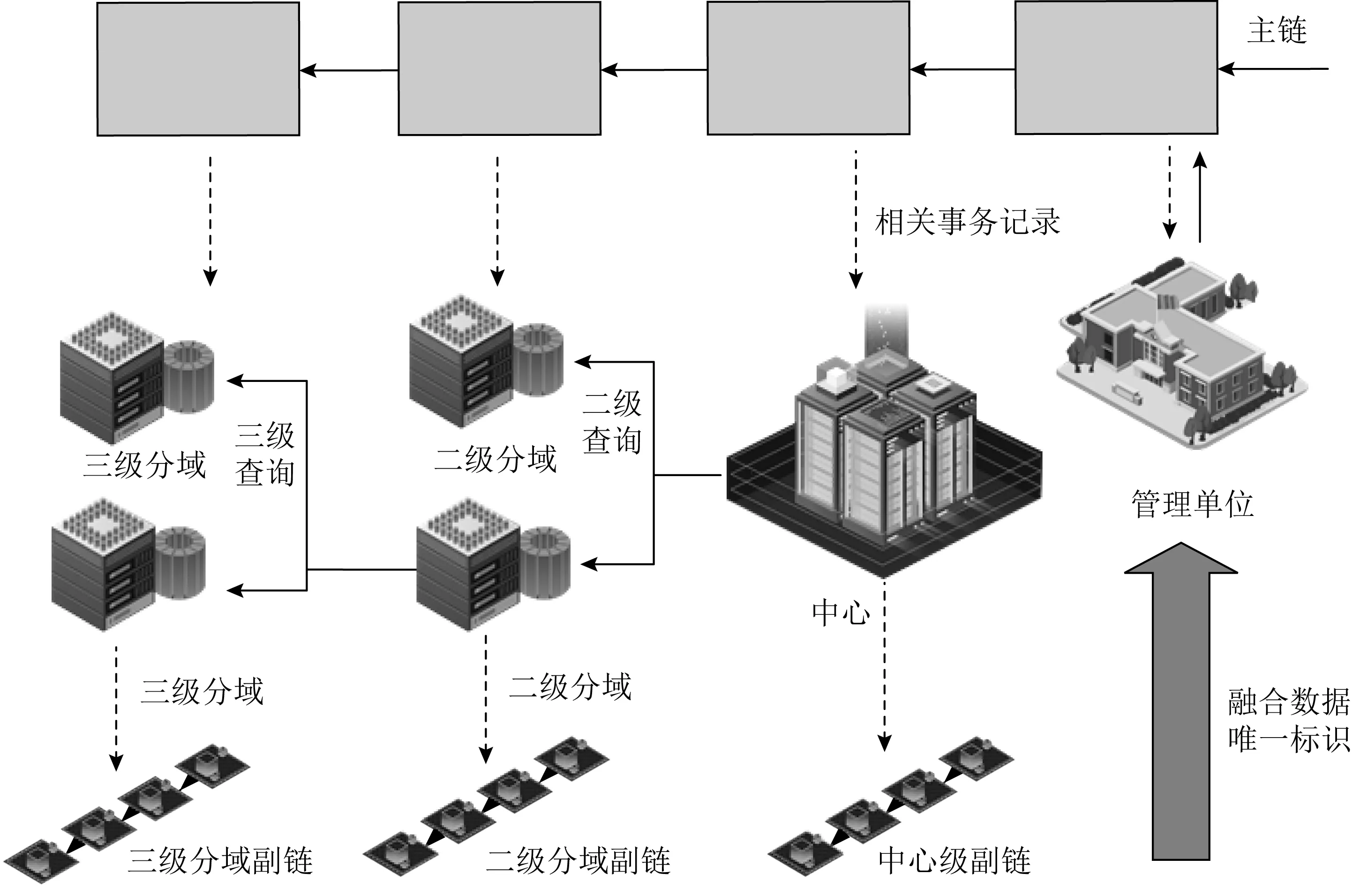
图8 基于二级链结构的跨域数据溯源
4 实现和验证
4.1 原型系统的实现
构建基于二级链结构的高效存储架构,实现跨域数据的安全高效存储;通过二级链和加密搜索,实现跨域数据可信快速溯源.跨域数据溯源逻辑关系如图9所示.
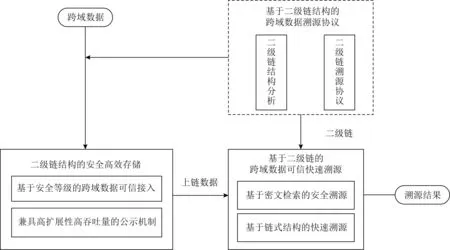
图9 跨域数据溯源逻辑关系图
基于上述设计构建基于二级链结构的跨域数据溯源系统,系统框架如图10所示.
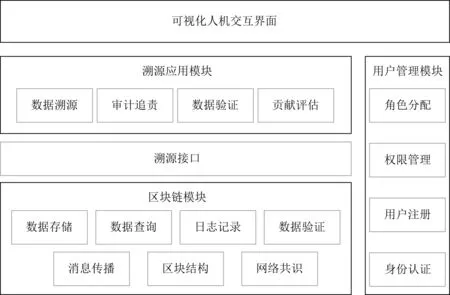
图10 基于二级链的分布式跨域数据可信溯源系统架构图
该系统划分为区块链模块、用户管理模块、数据业务模块和溯源应用模块.
1) 区块链模块
该模块基于开源区块链结构实现,是本系统的基础组件,为数据业务模块和数据溯源模块提供存储和查询接口.
2) 用户管理模块
用户管理模块采用传统的基于角色的访问控制将角色与权限进行绑定,角色分为数据收集者、数据加工者、数据报告者和数据使用者4类,区块链模块将根据其权限决定数据验证的结果.
3) 数据业务模块
数据业务模块是依据提出的框架实现的,用于主链信息上链和副链的信息存储,提供各阶段的数据写入和读取接口.
4) 溯源应用模块
数据溯源模块是依据提出的框架实现的,通过在区块链中构建交易依赖关系的有向无环图,实现跨域数据融合过程的监控,以图形化方式展示融合素材、半成品、产品的依赖关系,提供溯源查询的接口.
4.2 场景验证
通过构建主副链二级溯源架构,将素材和产品在主链进行存储和查询,将用户操作和生产过程的数据融合半成品在副链进行存储和查询.基于这种链式数据结构,管理机构能够找到数据的所有制作、使用、分发和共享记录,且数据上链时会附上数据提供者的数字签名和数据哈希,保证得到的溯源结果是可靠的,相关人员不可抵赖.并且基于主副链结构能将复杂多样的数据信息在域内处理,主链不需要保存具体的过程信息,减轻主链负载,提高系统吞吐量,支持异构信息的分级查询.同时,能够支持产品和素材跨域溯源、半成品域内溯源、双向多级溯源等新型使用模式下的便捷溯源.一方面,当融合数据产品产生效果,可以对提供贡献的人或者数据素材追溯;另一方面,当融合数据产品产生问题,结合数据的实际问题和链式结构上的过程数据,快速定位问题原因,对问题环节进行诊断.
1) 产品、素材、半成品溯源
如图11所示,可以实现产品、素材的跨域溯源、半成品的域内溯源.

图11 产品、素材、半成品溯源
2) 双向多级溯源
二级分域的素材加工产生二级分域产品,一级分域的素材加工产生一级分域产品,一级分域产品作为中心域的素材加工产生最终的产品.围绕某一主题、某一级别的素材或者数据可以进行双向多次追溯的交互式可视化,以透视信息流程.
图12(a)所示为由中心产品进行的1次正向溯源,可以直观展示产生这一中心产品所使用的二级分域素材、一级分域素材.图12(b)所示为由二级分域的素材到产品的反向溯源,可追查到该素材加工、消费、审核、上报等使用情况.图12(c)所示为由二级分域的产品的1次正向溯源,可以追查到形成该产品使用的其他素材情况.
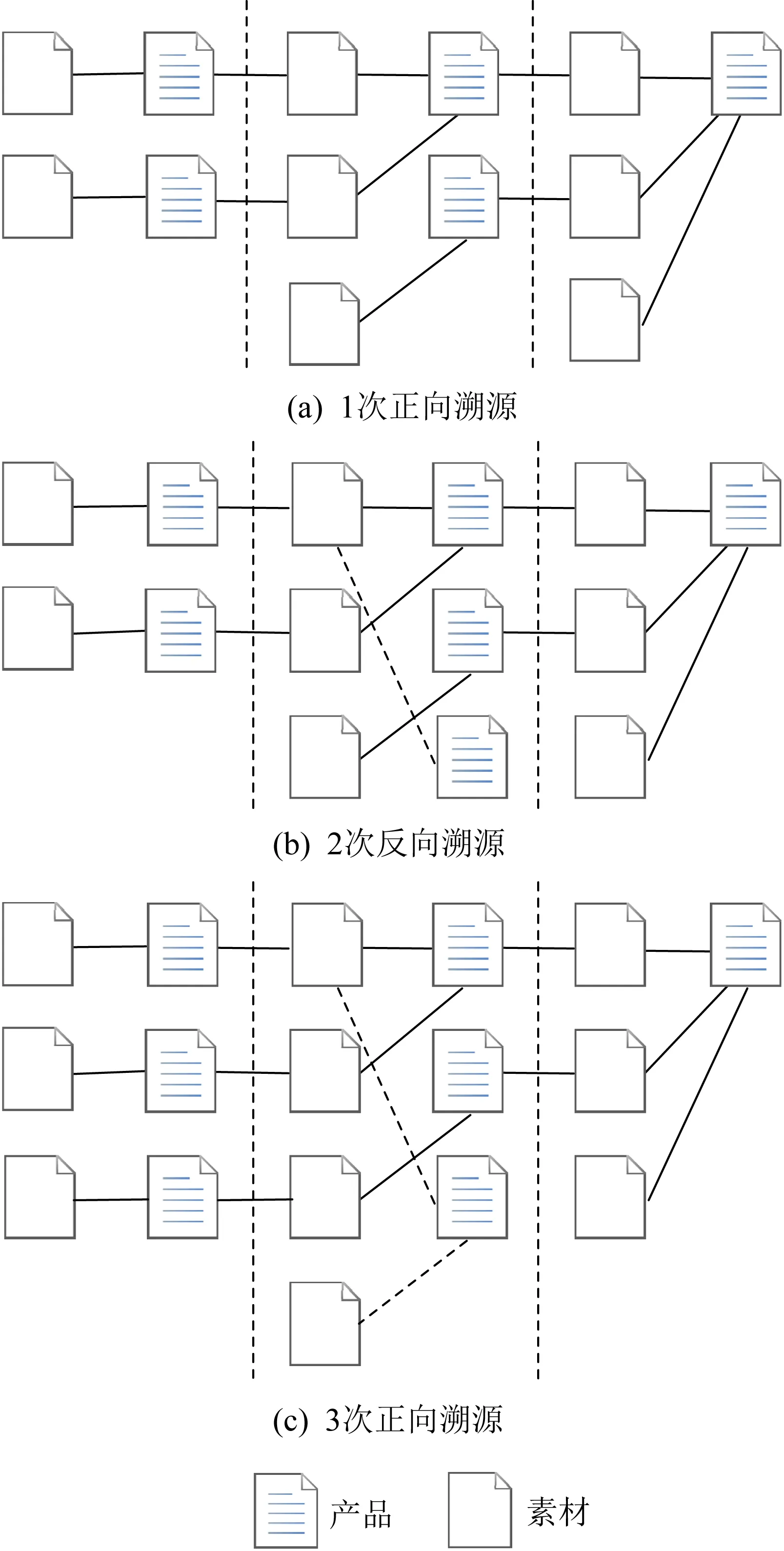
图12 双向多次溯源
5 结 论
针对跨域数据融合过程中存在的数据安全、数据可信和溯源问题,本文提出了一种基于二级链结构的跨域数据融合溯源框架,该框架设计统一编码、溯源协议、上链机制、溯源方法、应用流程等,实现了跨域数据的安全高效存储和融合过程完整信息的快速安全回溯.另外,在本文中通过设定通用性的三级分域数据融合场景,验证了该框架数据编码、上链、溯源等基础功能的可行性,进一步验证了框架在跨域数据融合系统中产品和素材跨域溯源、半成品域内溯源、双向多级溯源等新型使用模式下的便捷性.通过验证,可以看出本框架具备链外数据可信接入和高效存储、存储架构具有高扩展性和高吞吐量、融合数据全生命周期全数据资料回溯,在跨域场景下保证了结果的不可伪造和不可抵赖性.
基于本文的二级链溯源技术框架,在未来工作中我们将进一步研究和解决多层级跨链技术、完善与现有各数据系统接口适配问题、数据的精细化授权等问题,为政府数据共享、城市数据治理、海洋态势观测场景下的大规模数据融合系统的安全监管和全生命周期溯源提供一体化架构解决方案.
猜你喜欢
系统仿真技术(2022年4期)2023-01-17
北京航空航天大学学报(2022年8期)2022-08-31
读报参考(2022年1期)2022-04-25
科学家(2021年24期)2021-04-25
电脑爱好者(2020年20期)2020-10-22
中国计算机报(2019年26期)2019-08-27
中学生数理化·高二版(2017年2期)2017-04-19
中学化学(2016年12期)2017-02-05
工业设计(2016年8期)2016-04-16
电脑爱好者(2015年13期)2015-09-10
