
基于自我监督预处理的食物图像分类
2021-08-09 10:27姚伟盛沈宇帆彭玉波沈炜
智能计算机与应用 2021年3期
姚伟盛 沈宇帆 彭玉波 沈炜


摘 要: 随着社交网络的快速发展,人们通常会上传、分享和记录食物图片,因此食物图像分类的应用价值也越来越大,对食品推荐、营养搭配、烹饪文化等方面都产生了积极的影响。尽管食物图像分类有着巨大的应用潜力,但从图像中识别食物仍然是一项具有挑战性的任务。为了解决食物的细粒度识别问题,本文提出了一种基于自我监督预处理的食物图像分类模型,通过自我监督的学习方式更高程度地学习食物图像特征。该模型在基于密集连接网络的食物图像分类模型DenseFood基础上搭建,采用上下文恢复的自我监督策略,将训练好的网络权重用于初始化DenseFood模型,训练微调完成分类任务。上下文恢复的自我监督策略和密集连接网络都是专注于图像特征的提取,同时结合两者,充分学习食物图像特征,来达到更好的食物图像分类精确度。为了进行性能比较,使用VIREO-172数据集对基于自我监督预处理的食物图像分类模型、未预处理的食物图像分类模型DenseFood以及基于ImageNet数据集训练预处理的DenseNet、ResNet这四个模型进行训练。实验结果表明,本文提出的食物图像分类模型优于其他策略。
关键词: 图像分类; 自监督学习; 卷积神经网络
文章编号: 2095-2163(2021)03-0009-07 中图分类号:TP183 文献标志码:A
【Abstract】With the rapid development of social networks, people usually upload, share and record food images, so the application value of food image classification is also increasing, which has a positive impact on food recommendation, nutrition collocation, cooking culture and so on. Although food image classification has great application potential, it is still a challenging task to recognize food from images. In order to solve the problem of fine-grained food recognition, this paper proposes a food image classification model based on self supervised preprocessing, which can learn food image features to a higher degree through self supervised learning. The model is based on DenseFood, a food image classification model based on dense connected network. The self-monitoring strategy of context recovery is adopted. The trained network weight is used to initialize DenseFood model, and fine-tuned trained to complete the classification task. The self-monitoring strategy of context recovery and dense connection convolution network are both focused on the extraction of image features. The research combines them to fully learn the food image features to achieve better classification accuracy of food image. In order to compare the performance, VIREO-172 data set is used to train four food image classification models: self supervised preprocessing based food image classification model, non preprocessed food image classification model densefood, and ImageNet data set based training preprocessing DenseNet and ResNet. The experimental results show that the proposed food image classification model is superior to other strategies.
【Key words】 image classification; self supervised learning; convolution neural network
0 引 言
食物是人類生活的必需品,关系到人民群众的身体健康和生命安全。随着社交网络的快速发展,人们通常会记录、上传和分享食物图片,因此食物图像分类的应用价值也越来越大,对营养搭配、食品推荐、餐饮、社交等方面都产生了积极的影响,受到了广泛的关注。在营养搭配方面,营养习惯被认为是导致糖尿病和肥胖症等健康问题的主要原因。因此,食物摄入评估是肥胖管理的一个重要方法[1],可以帮助人们了解和保持良好的饮食习惯,在跟踪卡路里消耗量的日常健身中进行使用[2]。在食品推荐方面,可以帮助社交媒体平台为餐馆和饮料公司针对其用户提供食品推荐方案。在餐饮方面,通过客户提供的图像样本帮助餐厅和食堂识别食物,并通过识别托盘中的食物帮助出纳自动计费。使用自动计费可以在保证减少错误的前提下提高工作效率[3]。在社交方面,可以通过社交媒体与朋友分享食物照片,根据其食物偏好对使用者进行聚类。此外,还可以帮助人们使用图像搜索食物。
尽管食物图像分类有着巨大的应用潜力,但从图像中识别食物仍然是一项具有挑战性的任务,挑战来自3个方面:
(1)缺乏用于食物识别的大规模数据集。现有的工作主要集中在利用较小的数据集进行食物识别,如ETH-food-101[4]和Vireo-food-172[5]。例如,Bossard等人[4]发布了一个来自西餐的食物数据集ETH food-101,包含101个食物类别和101 000张图片。Chen等人[5]介绍了来自172个中国食品类别的Vireo Food-172数据集。这些数据集缺乏食品类别的多样性和覆盖面,没有包括广泛的食品图像。因此,可能并不足以构建更复杂的食物识别深度学习模型。
(2)不同种类的食物可能从外观上看极其相似,但是类间相似性非常高,如图1所示。由图1可知,麻婆豆腐和红烧豆腐从外观上看基本上无法分辨。虽然已经有许多方法用于解决食物识别问题,但这些方法大多侧重于提取特定类型或某些类型的特征,而忽略了其他方面。例如,研究[6]的工作主要是提取颜色特征,而Martinel等人[7]设计了一个用于食物识别的网络来捕获特定的垂直结构。
(3)一种特定的食物可能有数千种不同的外观,但其本质上是相同的食物,如图2所示。由图2可知,烤鱼以不同形式的外观表现出来。因为相同食物的配方可以根据位置、食材成分以及最后但并非最不重要的个人口味而有所不同。食物图像中有细微的辨别细节,在很多情况下很难捕捉到。食物识别属于细粒度识别,其中有很多细微差别的细节,现有的图像分类技术还无法很好地获取并区分图像细节特征[8]。
由于有监督学习需要大量的手动数据注释,这一要求耗时耗力,因此无监督学习越来越受到了关注,尤其是在自我监督学习方面。自我监督学习是一种特殊的无监督学习,其目标是监督特征学习,其中监督任务是从数据本身生成的。模型必须充分学习图像特征,才能有效完成这类监督任务,所以基于自我监督的卷积神经网络预训练会产生有用的权重,有助于后续的学习任务[9]。
本文主要研究食物图像的自我监督,提出了一种基于自我监督预处理的食物图像分类网络模型。文中的方法是将上下文恢复作为一项自我监督任务,上下文恢复策略训练的卷积神经网络专注于学习有用的语义特征,学习的卷积神经网络特征对后续分类任务有用[10]。同时由于基于密集连接网络的食物图像分类模型DenseFood在食物识别应用中表现出的优异性能[11],研究中选择其作为后续的分类任务。建立自我监督预处理模型,训练好的网络权重初始化DenseFood网络,训练微调完成分类任务。通过使用VIREO-172数据集,对基于自我监督预处理的食物图像分类网络、无预处理的DenseFood网络模型以及基于ImageNet数据集训练预处理的DenseNet、ResNet这四个模型进行评估,实验结果表明,所提出的基于自我监督预处理的食物图像分类网络模型优于其他策略。
1 相关研究
自我监督学习的关键挑战是确定一个合适的自我监督任务,即通过数据生成模型输入输出对。Chen等人[10](2019)提出了一种医学图像自监督学习策略。具体来说,给定一幅图像,随机选择并交换2个补丁。多次重复此操作会产生一个新的图像,该图像的强度分布被保留,但其空间信息被改变,然后通过训练卷积神经网络将改变后的图像恢复到原来的版本。所提出的上下文恢复策略有3个优点:在该任务中训练的卷积神经网络专注于学习有用的语义特征;在该任务中学习的卷积神经网络特征对后续不同类型的任务(包括分类、定位和分割)有用;实现简单明了。
针对医学图像分析中的3个常见问题,即:分类、定位和分割,对该自监督学习策略进行了评估。评估使用了不同类型的医学图像:对二维胎儿超声(US)图像进行图像分类;对腹部计算机断层扫描(CT)图像进行器官定位;对脑磁共振(MR)图像进行分割。在这三个任务中,基于上下文恢复策略的预训练都优于其他的自监督学习策略,也优于没有自监督训练的学习策略。
食物图像分类方面,卷积神经网络取得了广泛的成功,其性能优于其他方法。卷积神经网络有许多不同的架构,如AlexNet[12]、VGG[13]、GoogleNet[14]、ResNet[15]、DenseNet[16]等,其中DenseNet的性能表現优异。密集连接网络DenseNet在2017年的ImageNet大规模视觉识别大赛(ILSVRC)上表现出出众的效果。DenseNet专注于图像特征的提取与复用,加强了图像特征的传递,一定程度上减轻了梯度消失的问题,通过对图像特征的极致利用达到了更少的参数和更好的效果。Metwalli等人[11](2020)提出了基于DenseNet的食物图像识别模型DenseFood,使用了softmax损失函数和中心损失函数相结合的方法,该模型从头开始训练就达到了81.23%的准确率,仅次于基于大规模ImageNet数据集训练的ResNet和DenseNet。
基于此,本次研究中针对食物图像分类,提出了一种基于自我监督预处理的网络模型,使用基于上下文恢复的自我监督预处理方法,训练好的权重用于初始化食物分类网络模型DenseFood,再进一步训练微调完成分类任务,来达到更好的分类效果。
2 本文方法
研究中基于自我监督预处理的食物图像分类网络模型由2部分组成,分别是:基于上下文恢复的自我监督预处理模型和食物图像分类模型。对此拟展开研究论述如下。
2.1 基于上下文恢复的自我监督预处理模型
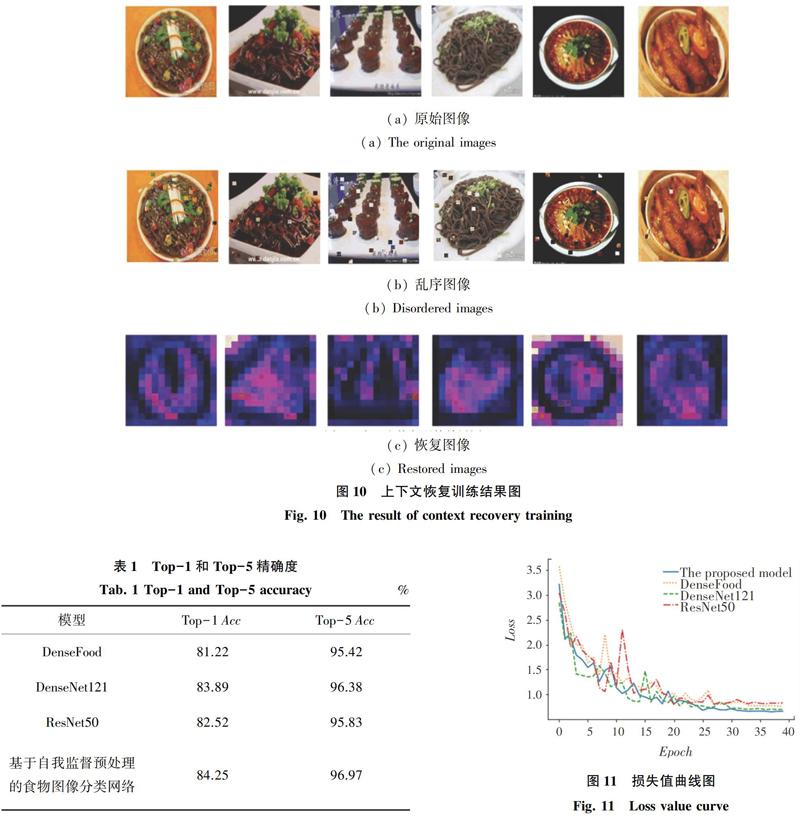
基于上下文恢复的自我监督预处理是将原始的图像进行打乱,再利用卷积网络将其上下文训练恢复为原始图片[10]。打乱的方式是选取图像中随机的2个小块进行交换,迭代多次,保证所有小块不会出现重叠,防止图片打乱过于复杂,最终将会生成一个乱序的图片。乱序算法的伪代码如图3所示,其中,x为原图,取小块大小为10×10,迭代次数N为10。乱序图像生成过程如图4所示。通过上下文恢复的自我监督学习,卷积神经网络可以更加专注地学习食物图像的语义特征。如图5所示,基于上下文恢复的自我监督预处理模型由2部分组成,即:预处理部分和恢复部分。
预处理部分主要由初始化层、密集连接块和过渡层组成,训练出的权重用于初始化后续的图像分类网络。初始化层由卷积层和汇聚层组成,在将信息输入密集块层之前从图像中提取出大量的信息,特征映射被下采样以减少参数的数量。密集连接块由批标准化、激活函数和卷积层组成。如图6所示,每一层的输出都作为输入提供给后续层,因此,第k层接受来自先前所有层的特征映射。将X0,X1,...,Xk-1视为输入,即:
为了降低特征映射的维数,将网络结构划分为4个密集连接块,密集连接块之间通过过渡层衔接,过渡层由批处理归一化、ELU、1×1卷积层和2×2最大池化层组成。池化层使用最大池、而不是平均池来减少特征映射的数量,避免过拟合,以使模型更具通用性。值得一提的是,简单模型可能无法很好地拟合数据,因此可能会出现欠拟合,而层数较多的模型可能会产生较高的计算成本,通常需要更大的数据集来避免过度拟合,提高精度,并实现可推广的性能[17]。考虑到本次研究的数据集不够大,无法训练一个复杂的模型,因此分别构造了4个6层、12层、24层和16层的密集连接块,以避免过度拟合和欠[CM(22]拟合。由于密集连接网络较深,导致图像恢复效果[CM)]
较差,研究中就选取了前三个密集连接块作为预处理部分,既加强了图像特征学习,又保证了图像恢复效果。恢复部分主要由upSampling上采样层、过渡层和Min-Max标准化层组成,输出为图片。由于恢复部分不会应用于后续的分类工作,所以相对预处理部分较为简单,upSampling上采样层采用重采样和插值方法,过渡层由批处理归一化、ELU、1×1卷积层组成,Min-Max标准化层将输出进行标准化,Min-Max标准化公式见如下:
其中,x1,x2,...,xn为输入序列,对其进行变换得到标准化序列y1,y2,...,yn。由于该模型训练的数据标签是图片,会占用大量内存,导致可训练的数据集容量较小,因而将网络输出的图片大小以及做比对的原始图片都缩小为原来的1/4(宽和高各缩小为原来的1/2),来保证可以训练更大的数据集,提高训练效率及效果。同时由于恢复部分的网络权重并不会应用到后续的分类工作中,因此缩小输出图片所带来的像素损失对分类结果的影响较小。
2.2 食物图像分类模型
将上下文恢复预处理模型中的预处理部分的网络权重对食物图像分类网络进行初始化,再进一步训练微调。如图7所示,主要由4部分组成,即初始层、密集连接块层、过渡层和完全连接层。前面介绍过,为了避免过度拟合和欠拟合,研究中构造了4个6层、12层、24层和16层的密集连接块,初始层、前三个密集连接块层、过渡层组成了预处理部分,由预处理模型权重进行初始化。最后一部分包括一个密集连接块层、过渡层和2个完全连接层,第一个完全连接层使用全局平均池将特征映射展平成一个包含1 024个节点的数组,然后将其作为分类器输入到第二个完全连接层,该层包含172个神经元,每个神经元代表一个食物类。
2.3 损失函数
对于自我监督预处理模型,文中采用L2损失训练网络来完成上下文恢复任务,L2损失可以预估出图片的恢复程度:
其中,xi和yi分别表示恢复图和原图的像素值;L2损失函数又称为最小平方误差,把目标值和估计值的平方和最小化。尽管上下文恢复的输出可能是模糊的,但是L2损失对于特征学习来说是足够的了。
对于分类网络模型,考虑到食物图像具有类间相似性和类内变化,采用softmax损失和中心损失相结合,并使用λ来平衡2个损失函数[18-19],如下所示:
softmax损失可以最大化类间差异[19]:
2.4 图像预处理
研究中使用的数据集的大小有限,平均每个类641张图像的172个类只包含110 241个图像。为了解决这一问题,防止训练中的过度拟合,通过使用水平翻转、旋转、错切变换、缩放和平移等方法来增加数据,如图8所示。图像的大小总是调整为224×224,以适应模型。
3 实验与结果
3.1 数据集
VIREO-FOOD数据集是一个大型的公共中餐食品数据库,包含172类的110 241张图片,如图9所示,用于训练卷积神经网络有不错的效果。文中将数据集分为2个子集,即:80%用于分类网络训练,20%用于分类网络测试。同时用于训练的子集部分中,80%作为训练集,20%作为校验集。分类网络的训练集的40%用于自我监督预处理的训练,校验集的30%用于自我監督预处理的校验。
3.2 实验平台
文中使用TensorFlow实现了研究中的分类网络模型,TensorFlow是由Google开发的一个端到端开放源代码机器学习平台,具有灵活和全面的工具、库和资源生态系统[20]。训练过程是在Intel CoreTM i7 2.8 GHz CPU、32 GB RAM和一个6 GB的Nvidia GeForce GTX 1060 GPU。训练以平均52.48张图像/s的速度进行。
3.3 卷积神经网络训练
自我监督预处理模型的训练初始学习率设置为0.01,分类网络模型是在预训练基础上训练的,为了避免权重失真,初始学习率改为0.005。此外,在学习速率表中使用余弦衰减来降低学习速率。同时使用中心损失函数和softmax分类交叉熵函数相结合进行分类,其中λ的值设为0.5,以平衡损失函数,因为大多数食品类别的类内变化较小。为了避免过度拟合和提高精度,在训练期间使用了数据扩充,使用随机的水平翻转、旋转、错切变换、缩放和平移。由于计算资源有限,批量大小设为16,训练时长设为40个周期。
3.4 实验结果
研究中,在VIREO-172数据集上评估了上下文恢复模型以及分类网络模型,上下文恢复训练结果如图10所示,还原图较为模糊,但对于预训练分类网络已经足够了。紧接着,训练了无预处理的食物图像分类网络模型DenseFood、基于ImageNet数据集预处理的DenseNet121、ResNet50和基于自我监督预处理的食物图像分类网络四个模型,提供Top-1和Top-5精度,实验结果见表1。由表1可以看出,基于自我监督预处理的食物图像分类网络的Top-1和Top-5精度分别为84.25%和96.97%,准确率高于其他模型,验证了本文的网络模型具有更有效的食物图像特征学习。在此基础上,还绘制了这4个模型的损失曲线和精确度曲线,如图11、图12所示,文中的模型对损失值做到了更好的最小化,其损失值为0.69。
4 結束语
本文提出了一种基于自我监督预处理的食物图像分类网络。研究中构建模型训练食物图片的上下文恢复能力来学习图像特征,将该模型训练出的网络权重在分类网络中进行初始化,再进一步训练微调,使用密集连接卷积网络进一步提取和复用图像特征,充分实现对食物图片细节上的图像特征的学习和提取,来提高食物图像分类的精确度。实验结果也验证了本文的论点,文中研发的模型Top-1和Top-5精确度高达84.25%和96.97%,优于其他模型。
参考文献
[1] HE Hongsheng, KONG Fanyu, TAN Jindong. DietCam: Multiview food recognition using a multikernel SVM[J]. IEEE Journal of Biomedical and Health Informatics, 2015, 20(3):848-855.
[2] PANDEY P, DEEPTHI A, MANDAL B, et al. FoodNet: Recognizing foods using ensemble of Deep Networks[J]. IEEE Signal Processing Letters, 2017, 24(12):1758-1762.
[3] AGUILAR E, REMESEIRO B ,BOLAOS M, et al. Grab, Pay and eat: Semantic food detection for smart restaurants[J]. IEEE Transactions on Multimedia, 2018,20(12):3266-3275.
[4] BOSSARD L, GUILLAUMIN M, GOOL L V. Food-101-Mining discriminative components with Random Forests[C]//European Conference on Computer Vision.Zurich:Springer,2014:446-461.
[5] CHEN Jingjing, NGO C W. Deep-based ingredient recognition for cooking recipe retrieval[C]//Proceedings of the 24th ACM on International Conference on Multimedia (MM'16). New York, NY, United States:ACM,2016: 32-41.
[6] BETTADAPURA V, THOMAZ E, PARNAMI A, et al. Leveraging context to support automated food recognition in restaurants[C]// IEEE Winter Conference on Applications of Computer Vision. Waikoloa, HI, USA:IEEE,2015:580-587.
[7] MARTINEL N, FORESTI G L, MICHELONI C. Wide-slice residual networks for food recognition[C]// IEEE Winter Conference on Applications of Computer Vision.Lake Placid,NY,USA: IEEE Computer Society, 2016: 567-576.
[8] MIN Weiqing, LIU Linhu, WANG Zhiling, et al. ISIA Food-500: A dataset for large-scale food recognition via stacked global-local attention network[C]// Proceedings of the 28th ACM International Conference on Multimedia(MM '20).2020:393-401.
[9] GIDARIS S, SINGH P, KOMODAKIS N. Unsupervised representation learning by predicting image rotations[J]. arXiv preprint arXiv:1803.07728,2018.
[10]CHEN L, BENTLEY P, MORI K, et al. Self-supervised learning for medical image analysis using image context restoration[J]. Medical Image Analysis, 2019,58(11):101539.
[11]METWALLI A S, SHEN W, WU C Q. Food image recognition based on densely Connected Convolutional Neural Networks[C]// 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC).Fukuoka, Japan:IEEE, 2020:27-32.
[12]KRIZHEVSKY A, SUTSKEVER I, HINTON G. ImageNet classification with Deep Convolutional Neural Networks[C]// Neural Information Processing Systems(NIPS). USA:Morgan Kaufmann Publishers, Inc., United States of America, 2012,141:1097-1105.
[13]SIMONYAN K, ZIEEERMAN A. Very Deep Convolutional Networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
[14]SZEGEDYC, IOFFE S, VANHOUCKE V, et al. Inception-v4, inceptionresnet and the impact of residual connections on learning[C]// AAAI Conference on Artificial Intelligence (AAAI). San Francisco, California,USA: AAAI, 2017:4278-4284.
[15]SZEGEDY C, LIU W, JIA Y, et al. Going Deeper with Convolutions[C]//Proceedings of The IEEE Conference On Computer Vision and Pattern Recognition, Boston, MA:IEEE, 2015:1-9.
[16]HUANG G, LIU Z, LAURENS V D M, et al. Densely Connected Convolutional Networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR 2017). Washington, DC: IEEE Computer Society,2017:2261-2269.
[17]KABKAB M, HANDS E, CHELLAPPA R. On the size of Convolutional Neural Networks and generalization performance[C]// 2016 23rd International Conference on Pattern Recognition (ICPR). Cancun, Mexico:IEEE, 2016:3572-3577.
[18]WANG F, XIANG X, CHENG J, et al. NormFace: L2 hypersphere embedding for face verification[C]//Proceedings of the 2017 ACM on Multimedia Conference. Mountain View, CA, USA:ACM, 2017: 1041-1049.
[19]ZHANG Tong, WANG Rong, DING Jianwei, et al. Face recognition based on densely Connected Convolutional Networks[C]// IEEE Fourth International Conference on Multimedia Big Data(BigMM). Xi'an, China:IEEE Computer Society, 2018:1-6.
[20]Google. Tensorflow[EB/OL]. [2019]. http://tensorflow.google.cn.
猜你喜欢
现代电子技术(2017年3期)2017-03-04
科技创新与应用(2016年35期)2017-02-21
现代电子技术(2017年1期)2017-02-16
计算机应用(2016年12期)2017-01-13
现代电子技术(2016年22期)2016-12-26
软件导刊(2016年9期)2016-11-07
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
电脑知识与技术(2016年10期)2016-06-16
