
基于迁移学习的无监督跨域人脸表情识别
2021-08-09 06:13:46莫宏伟傅智杰
智能系统学报 2021年3期
莫宏伟,傅智杰
(哈尔滨工程大学 自动化学院,黑龙江 哈尔滨 150001)
人脸表情自动识别是情感计算和计算机视觉领域的研究热点之一[1-5]。近年来,随着人工智能的迅猛发展,人脸表情识别在多媒体娱乐、人机交互、机器智能等领域有着广泛的应用前景。近年来,许多研究者致力于人脸表情识别研究,并提出了许多有效的方法。
Zheng等[6]提出了核典型关联分析(kernel canoncal correlation analysis,KCCA)的人脸表情识别方法,通过对输入图像中人面部34个关键点进行定位,然后将这些关键点通过Gabor小波变换转换成带有标注信息的图向量(labeled graph,LG)来表示人脸特征。另外,针对每个训练人脸表情图像,将6种表情类型的标签转化成一个六维语义表达向量,进而学习LG向量与语义表达向量之间的相关关系,利用这种关系推断出测试图像的语义表达。在不同人脸表情数据库上的实验结果表明了该方法的有效性。与目标检测等计算机视觉任务相比,图像描述不仅需要检测图像中的内容,还需要理解图像中目标物体之间的具体关系,并使用自然语言正确地表达出来。Uddin等[7]提出了一种新的方法来对基于时间序列的视频中的人脸表情进行识别,首先从时间序列人脸中提取局部方向模式特征,然后进行主成分分析和线性判别分析,使特征具有较强的鲁棒性。最后,利用隐马尔可夫模型对不同的面部表情进行局部特征建模和识别,取得了较好的识别效果。Yu[8]提出了一种基于图像的静态面部表情识别方法,该方法包含一个基于3个最先进的人脸检测器集成的人脸检测模块,以及一个基于多层深度卷积神经网络(convolutional neural network, CNN)级联的分类模块。为了自动决定级联CNN的权重分配问题,提出了通过最小化对数似然损失和最小化铰链损失2种自适应训练卷积神经网络权值的优化方案。Baccouche等[9]设计了一种时空卷积稀疏自编码器,在不需要任何监督信息的情况下学习稀疏移位不变表示。
虽然上述人脸表情识别方法取得了较好的识别效果,但需要注意的是,这些方法通常认为训练数据样本和测试数据样本的数据分布相同。而在实际应用中,可能无法满足相同的分布假设。特别是当训练数据和测试数据来自2个不同的数据库,且这2个数据库是在不同的数据收集环境下收集的。对于这样的跨域人脸表情识别问题,传统的人脸表情识别方法可能无法达到很好的识别效果。近年来,迁移学习在图像分类[10-11]和标注[12-13]、目标识别[14-17]和特征学习[18-20]等方面都有很好的应用前景。且在跨域识别问题上展现出较大的优势,越来越受到研究者的关注。
在跨域人脸表情识别问题中,源域和目标域来自不同的数据库,服从不同的数据分布,因此需要解决的主要问题就是如何减小不同域之间的分布差异。近几年,一些研究者通过对源域和目标域数据进行权重的重用来减小域之间的分布差异[21],或者通过找到一个共享的特征表示在保留原始数据属性的同时来减小域之间的分布差异[22-23]。但是大多数存在的方法仅对齐了边缘分布而忽略了条件分布的重要性,且往往需要目标域中有少量标签样本。
因此,为了解决源域和目标域数据来自2个不同的数据集,服从不同的边缘分布和条件分布,且目标域没有标记数据的无监督跨域表情识别问题,本文提出将联合分布对齐的迁移学习方法应用于跨域表情识别。该方法通过找到一个特征变换,将源域和目标域数据映射到一个公共子空间中,在该子空间中联合对齐边缘分布和条件分布来减小域之间的分布差异,然后对变换后的特征进行训练得到一个域适应分类器来预测目标域样本标签,提高跨域人脸表情识别的准确率。
1 提出方法
1.1 问题描述
1.2 核心思想
分布对齐的核心思想是通过找到一个特征变换矩阵,将源域和目标域样本映射到一个公共子空间,即可再生核希尔伯特空间(reproducing kernel Hilbert space, RKHS),通过引入无参数的最大均值差异MMD来度量源域和目标域数据之间边缘分布和条件分布的距离,在该子空间中在最大化投影后源域和目标域数据方差的同时,联合对齐边缘分布和条件分布,最小化域之间的分布距离,即
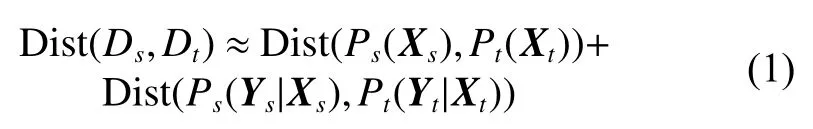
然后对变换后的特征进行训练得到一个域适应分类器,来对目标域中的数据标签进行预测。分布对齐原理示意图如图 1所示。

图1 分布对齐原理示意Fig.1 Schematic diagram of the distribution alignment
1.3 特征变换


1.4 边缘分布对齐
在进行分布对齐之前,需要解决的主要问题就是找到一个合适的度量准则来计算2个域之间的分布差异。而在机器学习中存在很多度量准则可以度量不同分布之间的差异, 例如欧氏距离、余弦相似度、KL散度等。但这些方法通常计算起来比较复杂。因此为了对齐边缘分布,减小边缘分布P(Xs) 和P(Xt) 之间的差异,采用无参数的最大均值差异MMD来度量不同分布之间的距离。
MMD的主要目标就是在RKHS中计算经过变换后的源域样本和目标域样本均值之间的距离。因此,边缘分布对齐的目标函数可以写成:

式中:xi、xj分别为源域和目标域中的第i个样本和第j个样本;H表示可再生核希尔伯特空间。
通过矩阵技巧和迹优化,式(3)可以被改写为

其中L是MMD矩阵,计算如下:

因此,通过式(4)使得域之间的边缘分布P(Xs) 和P(Xt) 尽可能地接近,减小了域之间的边缘分布差异。
1.5 条件分布对齐
减小边缘分布的差异通常并不能保证域之间的条件分布差异也随之减小。实际上最小化条件分布Ps(Ys|Xs) 和Pt(Yt|Xt) 之间的差异对于跨域识别问题来说也是至关重要的。然而,对齐条件分布并不是很容易,在目标域没有标签数据,对条件分布Pt(Yt|Xt) 直接进行求解是行不通的。因此可以使用类条件分布的充分统计量Pt(Xt|Yt) 来近似Pt(Yt|Xt)。近来的一些工作开始通过内核映射空间中的样本选择、联合训练[24]、循环验证[25]、核密度估计[26]等进行条件分布对齐。但是这些方法往往都需要在目标域中有一些标签数据,所以这些方法并不能解决我们的问题。
为了解决这一问题,提出利用目标域数据的伪标签,即通过将在有标签的源域数据上训练的基分类器应用于无标签的目标域数据,可以很容易地预测目标域数据的伪标签。由于不同域之间的分布差异,这些伪标签可能不是太准确,需要在实验中进行迭代优化。在源域带标签数据上训练的基分类器可以是标准的学习器,例如支持向量机(SVM)、NN等。
有了真实标签的源域数据和带有伪标签的目标域数据之后,就可以在标签空间Y的每个类中匹配类条件分布Ps(xs|ys=c) 和Pt(xt|yt=c),c={1,2,···,C} 。为了测量类条件分布Ps(xs|ys=c)和Pt(xt|yt=c) 之间的距离,本文对MMD进行了修改。因此,条件分布对齐的目标函数可以写成:

因此,通过式(7)减小了域之间的条件分布差异。但是在本文要解决的问题中,目标同时是最小化域间的边缘分布和条件分布的差异。因此将式(4)、(7)与式(2)合并到一起得到DaL的优化问题,即表示转换矩阵W的Frobenius范数。

1.6 模型优化
φ=diag(φ1,φ2,···,φk)∈Rk×k
令 为拉格朗日乘子,根据约束优化理论,可以推导出式(9)的拉格朗日函数,即

令式(10)对变换矩阵W求偏导数,并令其等于零可得到其广义特征分解:

最后,选择式(11)的前k个最小特征值对应的特征向量作为变换矩阵W的解。算法的伪代码如算法1所示。
算法1 分布对齐算法(DaL)
输入 数据矩阵X,标签矩阵ys,子空间维度k,以及正则化参数 λ;
输出 变换矩阵W,域适应分类器f。

2)通过对式(11)进行特征分解选择最小的k个特征向量构建变换矩阵W;
4)重复步骤2)、3)直至收敛;

图2 CK+数据库部分表情样本Fig.2 Partial expression samples of CK + Database
2)Oulu-CASIA NIR & VIS Database数据库[29]
该数据库主要由Oulu-CASIA NIR(近红外相机)和Oulu-CASIA VIS(可见光相机)两部分组成,如图3、4所示,均通过对年龄范围为25~58岁的80位测试者进行表情采集,其中男性和女性的比例分别为73.8%和26.2%。在80位测试者中,50位芬兰测试者由奥卢大学进行采集,剩余的测试者由中国科学院模式识别实验室完成采集整理。整个数据库包含的面部表情为高兴、生气、厌恶、惊讶、恐惧和悲伤,所有这些表情都是在3种不同光源条件(正常、强光、黑暗)下,分别通过一个可见光摄像机和一个近红外摄像机获得的。

图3 Oulu-CASIA VIS分别在黑暗、正常、强光条件下数据库中表情样本Fig.3 Expression samples of Oulu-CASIA VIS under dark, normal and strong light conditions respectively
2 实验与分析
2.1 数据库介绍
1)CK+数据库
CK+(the extended cohn-kanda dataset)数据库[27]是美国的匹兹堡大学团队和卡内基梅隆大学团队合作在CK(cohn–kanade)数据库[28]上进行扩充
2.2 实验设置
为了比较,本文选择了近年来在跨域人脸表情识别中常使用的迁移学习算法,包括核均值匹配(kernel mean matching, KMM)[30]、Kullback-Leibler重要性估计过程(kullback-leibler importance estimation process, KLIEP)[31]、选择性迁移机(selective transfer machine, STM)[5]等与本文提出的分布对齐(DaL)进行对比,这些方法的参数设置将在后面进行介绍。此外,使用线性支持向量机(SVM)作为这4种基准对比方法的分类器,即KLIEP+SVM、KMM+SVM、STM+SVM和DaL+SVM,同时将无迁移的SVM作为基准方法与这4种算法进行对比。

在实验过程中,每次选取这3个数据库中的任意2个分别作为源域(训练集)和目标域(测试集),因此可以得到6组对比实验,即
1) CK+作为源域,Oulu-CASIA NIR作为目标域,用C&N表示;
2) Oulu-CASIA NIR作为源域,CK+作为目标域,用N&C表示;
3) CK+作为源域,Oulu-CASIA VIS作为目标域,用C&V表示;
4) Oulu-CASIA VIS作为源域,CK+作为目标域,用V&C表示;
5) Oulu-CASIA NIR作为源域,Oulu-CASIA VIS作为目标域,用N&V表示;
6) Oulu-CASIA VIS作为源域,Oulu-CASIA NIR作为目标域,用V&N表示。
在本文实验中所用到的3个数据库中的表情样本构成如表1所示。实验中所有方法采用的参数设置及评价指标如下:在实验中,线性支持向量机(SVM)以固定的C=0.2,且在实验过程中,为了公平对比,所有方法均采用线性核函数。对于KMM来说主要有2个参数B和 ε,分别设置为

表1 实验所用数据库样本构成Table 1 Composition of database samples used in the experiment


式中:A表示准确率;Dt表示目标域样本;yˆ(x) 表示各对比算法预测的目标域样本标签;y(x) 表示目标域样本的真实标签。
2.3 实验结果与分析
不同对比方法在本文设置的6种实验场景下的平均准确率分别如表2、3所示。从实验结果可以看出:
1)本文提出的DaL在不同场景下的识别效果相对于无迁移学习的传统机器学习算法SVM有大幅提升,且均高于KMM、KLIEP和STM,表明DaL在跨域人脸表情识别的有效性。
2)从表2和表3的1、2和3、4四组实验中可以看出,在源域为CK+而目标域分别为Oul u-CASIA VIS和Oulu-CASIA NIR时的识别准确率均低于在源域分别为Oulu-CASIA VIS和Oulu-CASIA NIR而目标域为CK+时的识别准确率,并结合表1可以看出,出现这种情况的原因:1)可能是因为CK+数据库中的表情样本数量较少;2)可能是因为CK+数据库中样本数量不均衡造成的。
3)通过表2和3中5、6两组实验可以看出,在源域为Oulu-CASIA VIS,目标域为Oulu-CASIA NIR上的识别效果要高于在源域为Oulu-CASIA NIR,目标域为Oulu-CASIA VIS上的识别效果,出现这种现象的原因可能是由于Oul u-CASIA VIS和Oulu-CASIA NIR数据库中表情图像使用的采集设备不同,在Oul u-CASIA VIS和Oul u-CASIA NIR数据库中的表情图像分别是通过可见光相机和近红外相机拍摄的,表明模型从由可见光相机拍摄的表情图像上提取的特征要比近红外图像上提取的质量更高。
4)通过对比表2和表3中6组实验可以看出,通过圆形LBP特征提取方法在R= 2,P=16时提取特征的识别效果均高于R= 1,P=8时的识别效果,这一现象表明,在扩大特征提取半径和增加临近像素点时,LBP提取的特征相对较好。
5)通过对比表2和3中的6组实验可以看出,SVM在5、6两组实验上的识别效果相对于前4组实验来说有了较大提升。这是因为,Oulu-CASIA VIS和Oulu-CASIA NIR数据库中的样本之间的差异,要小于CK+中样本与Oul u-CASIA VIS和Oul u-CASIA NIR之间的差异。在Oul u-CASIA VIS和Oulu-CASIA NIR中样本的采集对象相同,因此样本间的特征差异相对较小。所以,对于无迁移学习的传统机器学习算法SVM来说,在5、6两组上的识别率相对较好。
表 2不同方法在6种不同实验场景下的平均准确率Table 2 Average accuracy of different methods in six different experimental scenarios%

表 2不同方法在6种不同实验场景下的平均准确率Table 2 Average accuracy of different methods in six different experimental scenarios%
?
表 3不同方法在6种不同实验场景下的平均准确率Table 3 Average accuracy of different methods in six different experimental scenarios %

表 3不同方法在6种不同实验场景下的平均准确率Table 3 Average accuracy of different methods in six different experimental scenarios %
?
为了更加直观地表示各对比算法的识别效果,给出了这5种算法在不同场景下的平均准确率曲线,如图5所示。从图5中可以清晰看出,本文提出的Da L方法在跨域人脸表情识别上的有效性。
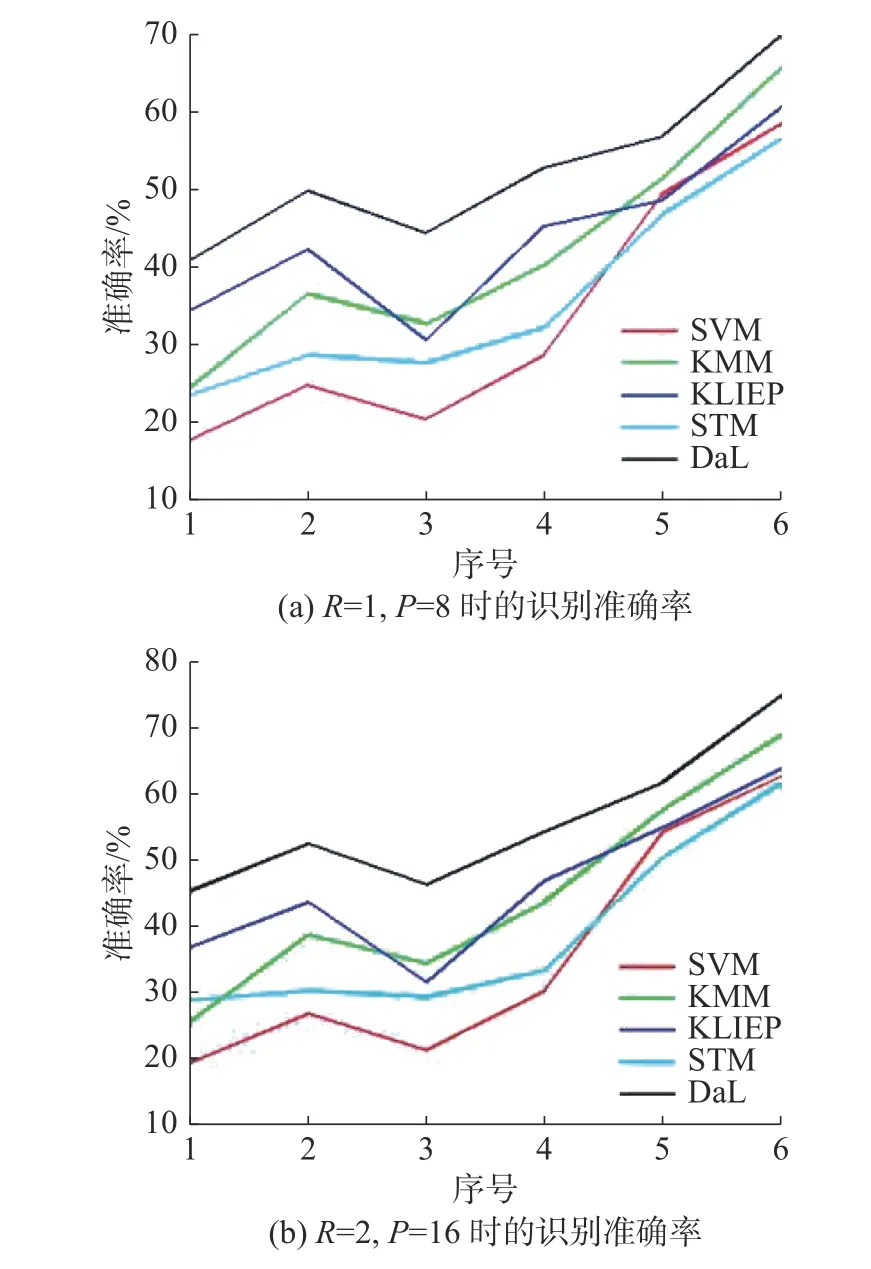
图5 各对比算法在不同实验场景下的平均准确率曲线Fig.5 Average accur acy curve of each compar i son algorithm in different experimental scenarios
为了进一步验证提出方法的有效性,本文选择表3中序号为3和5的这一组对比实验进行分析,并给出了在C&V和N&V两种实验场景下各对比算法在6种表情上的识别率混淆矩阵,分别如图6和图7所示。
通过图6和图7可以看出,在CK+作为源域,Oulu-CASIA VIS作为目标域时,在DaL中各种表情的识别率均高于各基准对比算法,并且不同算法在6种表情上的识别率差异相对较大。例如,在DaL中 “惊讶”、“高兴”这2种表情的识别率相对较高,分别为72%、60%,而“悲伤”和“恐惧”这2种表情的识别率较低,分别为36%、32%。
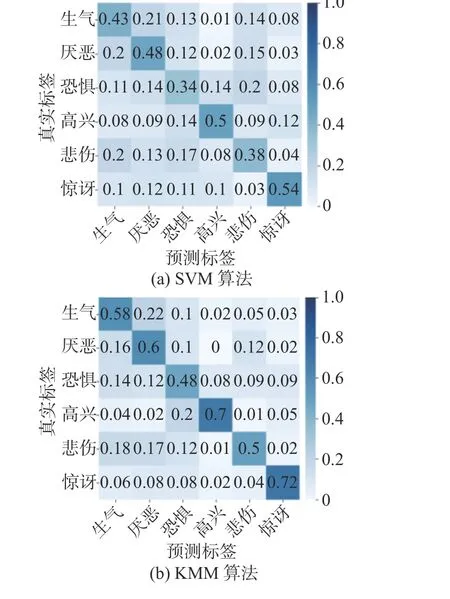

图6 C&V实验场景下各对比方法在6种表情上的识别率混淆矩阵Fig.6 Confusion matrix of the recognition rate of each comparison method on six expressions in the C&V experimental scene


图7 N&V实验场景下各对比方法在6种表情上的识别率混淆矩阵Fig.7 Confusion matrix of the recognition rate of each comparison method on six expressions in the N&V experimental scene
结合表2可知,出现这种现象主要是因为在CK+数据库中 “吃惊”表情的样本数量最多,有85张表情图像,而“恐惧”仅有25张表情图像。另外,还可以看到,“愤怒”、“厌恶”和“悲伤”这3种表情比较容易误判,结合图4中各表情样本,出现这种情况原因可能是因为受试者在表达这3种表情时的面部运动变化不大,因此提取的特征较为相似,不易于区分。此外,当源域为Oulu-CASIA NIR,目标域为Oulu-CASIA VIS时,“悲伤”和“恐惧”这2种表情的识别准确率有了大幅提升,平均提高了22%左右,且其他4种表情的识别率也有较大提升。这进一步说明了,数据库中样本数量的多少对跨域人脸表情识别的效果具有一定的影响。但无论CK+和Oulu-CASIA NIR哪个数据库作为源域,DaL的识别准确率均高于各基准对比算法,验证了该算法在跨域人脸表情识别上的有效性。
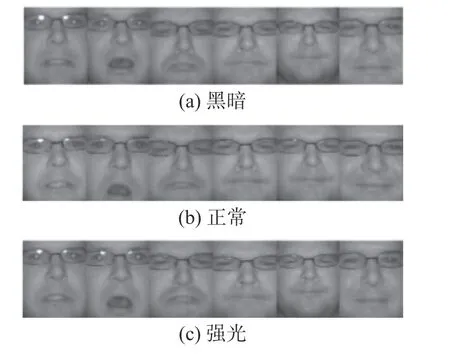
图4 Oulu-CASIA NIR分别在黑暗、正常、强光条件下数据库中表情样本Fig.4 Expression samples of Oulu CASIA NIR under dark, normal and strong light conditions respectively
3 结束语
本文提出将一种基于分布对齐的迁移学习方法应用到跨域人脸表情识别中,通过找到一个特征变换矩阵,将源域和目标域样本映射到一个公共子空间,引入无参数的最大均值差异MMD来度量源域和目标域数据之间边缘分布和条件分布的距离,在该子空间中最大化投影后源域和目标域数据方差的同时,联合对齐边缘分布和条件分布,最小化域之间的分布距离,然后对迁移后的特征进行训练得到一个域适应分类器,来对目标域中的数据标签进行预测,与4种基准方法在不同实验场景下的实验结果表明,本文提出的算法在跨域人脸表情识别上具有优势。但是还有一些不足之处,需要进一步的研究:1)对于跨域人脸表情识别来说,实验中的数据集样本数量的多少对于实验效果会产生很大的影响。因此,对于如何建立大样本人脸表情数据库将会是下一步需要进行的工作。2)在本文中对条件分布进行对齐时,由于目标域数据中没有标签数据,因此在实验中通过目标域数据的伪标签来进行对齐。但由于域之间的分布差异问题,这种方法预测的伪标签可能不是很准确。因此,对于在条件分布对齐时目标域中无标签数据的问题,需要进一步探索新方法来解决。
猜你喜欢
计算机技术与发展(2024年3期)2024-03-25 02:10:02
系统仿真技术(2022年4期)2023-01-17 13:01:44
北京航空航天大学学报(2022年8期)2022-08-31 08:59:18
读报参考(2022年1期)2022-04-25 00:01:16
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
科学家(2021年24期)2021-04-25 13:25:34
计算机技术与发展(2020年11期)2020-12-04 07:50:46
动漫星空(2018年9期)2018-10-26 01:17:14
电子与信息学报(2015年12期)2015-08-17 11:14:42
发明与创新(2015年33期)2015-02-27 10:40:09
