
融合可变形卷积网络的细粒度图像识别研究
2021-08-03 06:22吴忠粱
电脑知识与技术 2021年17期
吴忠粱

摘要:针对细粒度图像识别领域中识别率不高、难以定位到图像中具有表征性的局部区域的问题,提出一种基于多区域融合的可变形卷积网络算法,该算法采用新型的卷积计算方式,根据越靠近边缘的部位越发包含更多图像上下文信息的原理,对图像给定多个中心并划分权重区域。在主流数据集上的实验结果表明,提出的基于多区域的可变形卷积网络结构在细粒度图像识别上的表现相比其他主流算法都有了一定的提升,并且相比于原始的可变形卷积网络和v2版本的可变形卷积模型也有了性能上的优化。
关键词:细粒度图像识别;局部表征性;多区域可变形卷积网络;图像上下文信息;区域划分
中图分类号:TP301 文献标识码:A
文章编号:1009-3044(2021)17-0193-03
开放科学(资源服务)标识码(OSID):
Fine-grained Image Classification Research Fused with Deformable Convolutional Network
WU Zhong-liang
(School of Information Engineering, East China University of Technology, Nanchang 30013,China)
Abstract: Aiming at the problem that the recognition rate is not high in the field of fine-grained image recognition and it is difficult to locate the characteristic local area in the image, a multi-region-based deformable convolution network algorithm is proposed, which uses a new convolution calculation method. According to the principle that the parts closer to the edge contain more image context information, multiple centers are given to the image and weighted regions are divided. Experimental results on mainstream data sets show that the performance of the proposed multi-region-based deformable convolutional network structure in fine-grained image recognition has a certain improvement compared with other mainstream algorithms, and compared to the original deformable The convolutional network and the v2 version of the deformable convolution model have also been optimized in performance.
Key words: fine-grained image recognition; local representation; multi-region deformable convolutional network; image context information; region partition
1 引言
在计算机视觉领域中,图像分类任务通常分为粗粒度图像分类和细粒度图像分类,其中细粒度图像分类要求识别出某一基类下的数百种子类,包括识别不同种类的鸟[1],车[2],宠物[3],花[4],飞行器[5]等,而粗粒度图像分类只需要识别出图像中目标的基本类别。现如今细粒度图像分类这一任务具有非常迫切的研究需求,并且其應用非常广泛,例如生态多样性的保护、自动驾驶以及癌症检测等。
相比一般的图像识别,细粒度图像识别难度较大。一方面,由于部分目标在外观上只存在细微的差异,例如鸟类在形状,背部颜色和纹理特征上的细微差异,而这种细微的局部的差异恰恰是细粒度图像分类的关键所在。另一方面,这些细微且局部的差异常常存在于一些具有区分性的目标和部位上。因此,本文从聚焦于图像中具有明显表征性的部位出发,通过改进现有的较为流行的神经网络算法的采样计算方式,使得算法能进一步捕获到图像的局部细微特征,从而提升细粒度图像识别的准确率。
2融合可变形卷积的细粒度图像识别
2.1 可变形卷积网络
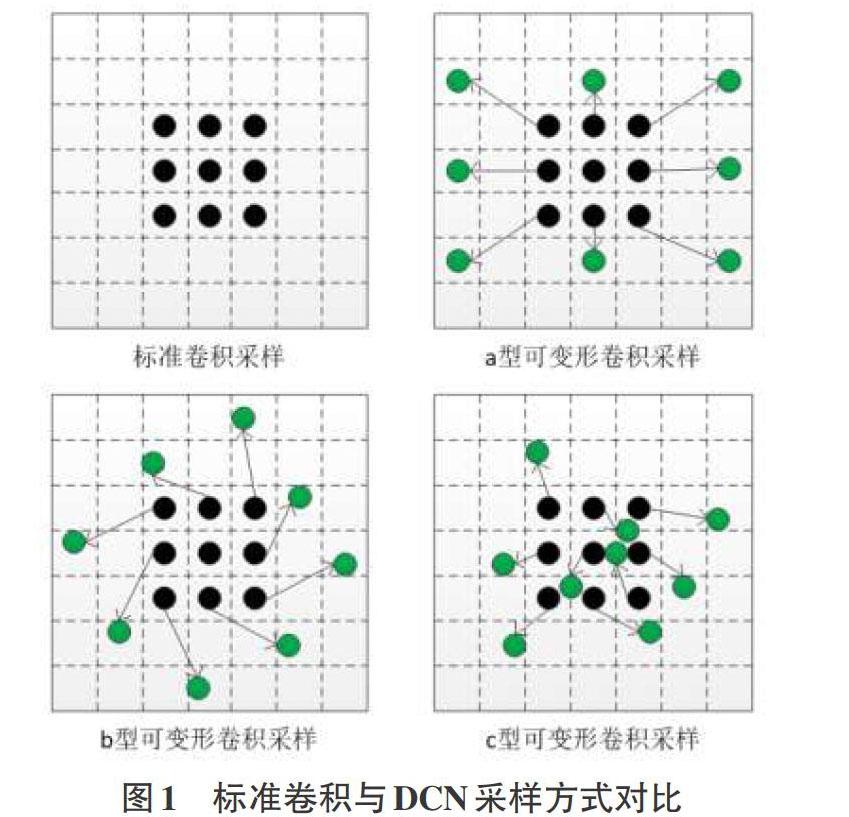
传统的卷积操作一般使用固定尺寸的卷积核对输入图像进行特征提取,其感受野范围固定,而可变形卷积网络[6](Deformable Convolutional Network,DCN)通过引入偏移量使感受野更加汇聚于表征性区域,提升了网络对图像纹理变化的适应能力,但DCN的一大问题是不太适用于图像表征性区域以外的部分,导致捕获的特征掺杂部分冗余信息。然而随后的v2版本可变形卷积网络[7](Deformable Convolutional Networkv2,DCNv2)则在原DCN的基础上对每个采样点引入偏移量以及不同的权重,使得对于图像的特征提取更加全面准确。图1给出了表示标准卷积与各种DCN采样方式的对比(以3×3模板为例),其中的DCN包含了尺度变化、伸缩及旋转等变形方式。
然而DCNv2仅仅通过引入权重带来的效果提升比较有限,这是由于现有的损失函数难以监督模型对无关紧要的区域设置较小的权重。尽管DCNv2相比DCN更加聚焦于表征性区域,但依然有小部分有效区域被忽略,这对于细粒度图像分类任务来说至关重要,可能导致最具区分性的部位特征的丢失,从而无法准确完成分类任务。
2.2 基于多区域融合的可变形卷积网络
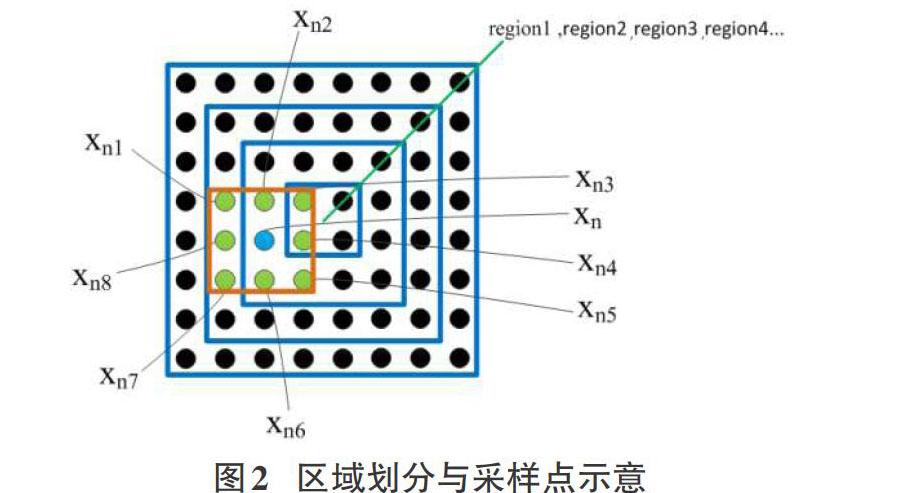
基于上述对DCN缺陷的阐述,本文提出一种基于多区域融合的DCN,同时设定一种新的卷积计算方式,既适用标准卷积网络也适用DCN类网络模型。首先,由于各采样点及其周围的点之间都有一定的关联性,应当保留采样点邻域内像素信息,便于充分发挥图像上下文信息的价值。如图2所示,若输入图像尺寸为8?8,卷积模板尺寸为3?3,某一采样点为Xn,其周围8邻域内各像素点一次为Xn1, Xn2, Xn3, Xn4, Xn5, Xn6, Xn7, Xn8,整幅图像从里至外依次划分区域分别为region1,region2,region3,region4…,新的卷积采样点计算方式为:在采样点的8邻域内选择与采样点梯度最大(即像素值相差最大)的4个点,然后对四个点根据其各自与采样点的梯度值作为对应的权重,并将该权重与原先邻域点的值对应作乘加运算,得到的值作为更新后的采样点的值,再将其输入至下一步的卷积运算过程。计算方式用式(1)表示如下,其中updated_SampleValue表示更新后的采样值,gradienti表示梯度值最大的几个邻域点,N表示变量i的取值范围,Xnj表示某采样点的8邻域内的像素值。
[updated_SampleValue=i=14gradientiNXnj j∈[1,8]] (1)
在图像中,区域划分如图2所示,经过以上区域划分后,图像被分成了具有不同权值不同中心的小区域,各区域对应不同的权值。由于图像中目标的边界区域包含了部分背景区域的信息,因此为了更凸显目标主体,需要降低图像背景干扰信息的影响,类似于DCNv2给每个采样点赋予不同权值,将整幅图像中除主目标以外的区域也相对目标主体加入相应的权重划分,图片中的不同区域在参与计算时也应该具有不同的权重。然而由于输入图像时目标位置不确定,因此本文方法在特征图上设定多个中心,将整幅特征图分为4个区域层次,为了更好地融合不同块的边界信息,每个区域之间有重叠,在每一个区域中,越靠近中心的部分权值越大,越靠近边缘的权值越小。最终在进行卷积计算时,每个采样点的权值为当前采样点所在块的权值以及每个采样位置的权值之乘积。由于在较深的卷积层中,已经学习到了主要目标的特征,大部分背景区域已经被摒弃了,因此该权值设置同时也会应用在region1、region3以及region4区域层次上的卷积层,计算方式依旧同式(1)所示。
3 实验
3.1 实验设置与数据集简介
本文的实验配置为:CPU(i7-9700H),内存大小为32G,操作系统版本为Ubuntu 16.04,图形处理器为英伟达公司出品的RTX2070显卡,Python版本为3.6.4,集成开发环境为Anaconda3内置的spyder,深度学习框架tensorflow版本为1.8.1。首先搭建好本文整个的算法框架,随后加载好在ImageNet大型图像识别数据集上训练好的预训练模型,该预训练模型的主干网络采用的是ResNet-101。本文实验选择Adam优化器对算法模型的权重衰减进行优化,设置初始学习率为0.005,每经过10个epoch对学习率进行调整,每个epoch送入模型的训练批量数目为50,同时设置学习率降低的阈值为0.0001。实验时对于各类数据集均取其80%作为训练组,10%作为模型验证组,10%作为测试组。
本文采用细粒度图像识别中常用的数据集CUB-2000-2011[8]、FGVC-aircraft[9]和 Stanford-cars[10]进行实验,其中CUB-200-2011 数据集由200种不同角度、不同姿势、不同背景的鸟类图像组成,每一类所提供的样本数量不同,总共 11788 张图像数据,该数据集给出了样本的标签信息,目标标注框信息以及目标局部不为标注信息,以及多种分类属性信息。FGVC-aircraft 数据集包括由 102 类不同飞机的图像组成,每一类飞机含有不同拍摄角度的100张图像,总共10200个样本数據。提供的标注信息有label和目标边界框,不包含局部定位。Stanford-cars 数据集由 196 类汽车图像组成,每一类提供的样本数据不一,总共16185 张图像,与FGVC-aircraft 数据集一样,数据集只提供了标签和目标标记框信息。同时将本文方法与DCN[6]算法、DCNv2[7]算法以及一般的图像识别中较为流行的Faster RCNN[11]算法及RANet[12]算法分别在三大数据集上进行了比较实验。
3.2 实验结果与分析
表1给出的是本文提出的多区域可变形卷积方式与其他主流的图像识别算法在数据集CUB-200-2011、 FGVC-aircraft以及Stanford-cars上的识别结果比较,可以看出,仅通过改变神经网络卷积采样方式同时不大幅改变整体模型结构的情况下,本文提出的多区域可变形卷积在各大数据集上相比于几大主流的细粒度图像识别算法具有更优的分类性能,譬如本文方法在最具挑战性的鸟类细粒度图像识别数据集上,比Faster RCNN[10]算法识别正确率提高了5%,比RANet[11]算法提高了3%,更重要的是,与原始的可变形卷积网络DCN[6]以及v2版本的可变形卷积模型DCNv2相比同样也有1%、2%的提升,这是由于改进后的可变形卷积网络的每个卷积核都能够提取到大量的邻近的图像上下文信息,这对细粒度图像分类算法来说能够更加精确地捕获到图像的局部特征。另一方面,由于越小的区域内的信息相似度越高,据此算法通过融合多区域权重,并加深每种区域的划分密度,使得识别准确率逐步提升。
图3给出了在本文方法下的图像区域热点图及其权值可视化效果,明确展示了相似度极高类别图像的区分性区域。这更加说明本文提出的多区域可变形卷积获取到更加多的相邻区域信息,并能够准确定位到图像中对目标识别具有重要贡献的部位。
4结论
本文针对细粒度图像识别领域中识别率不高、算法难以定位到图像中具有表征性的局部区域的问题,在分析当前主流的可变形卷积网络DCN的原理与结构的基础上,指出了DCN在对图像感受野的具体范围上尚有缺陷,由此提出一种基于多区域融合的可变形卷积网络的细粒度图像识别算法,该算法采用新型的卷积计算方式,根据越靠近边缘的部位越发包含更多图像上下文信息的原理,通过对图像给定多个中心及区域,并对图像不同区域进行权重划分。在三大主流的数据集上的实验结果表明,本文提出的基于多区域的可变形卷积网络结构在细粒度图像识别上的表现相比其他主流算法都有了一定的提升,并且相比于原始的可变形卷积网络和v2版本的可变形卷积模型也有了性能上的提高,本文算法对于图像目标的感受野范围更加灵活,同时改进后的模型体量相较之前基本无差别,这对于模型的训练益处较大。此外由于本文提出的基于多区域的可变形卷积网络算法在细粒度图像识别问题上表现优良,因此具有一定的研究价值与实用意义。
参考文献:
[1] Wah C,Branson S,Welinder P,et al.The caltech-UCSD birds200-2011 dataset[EB/OL].2011.
[2] Krause J,Stark M,Jia D,et al.3D object representations for fine-grained categorization[C]//2013 IEEE International Conference on Computer Vision Workshops.December 2-8,2013,Sydney,NSW,Australia.IEEE,2013:554-561.
[3] Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar.Cats and dogs. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012:3498-3505.
[4] Maria Elena Nilsback and Andrew Zisserman. Automated ?ower classi?cation over a large number of classes. Sixth Indian Conference on Computer Vision, Graphics & Image Processing, 2008:722-729.
[5] Maji S,Rahtu E,Kannala J,et al.Fine-grained visual classification of aircraft[EB/OL].2013.
[6] Dai J F,Qi H Z,Xiong Y W,et al.Deformable convolutional networks[EB/OL].2017:arXiv:1703.06211[cs.CV].https://arxiv.org/abs/1703.06211.
[7] Zhu X Z,Hu H,Lin S,et al.Deformable ConvNets V2:more deformable,better results[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).June 15-20,2019,Long Beach,CA,USA.IEEE,2019:9300-9308.
[8] Catherine W, Steve B, Peter W,et.al. The Caltech-UCSD Birds-200-2011 Dataset. Technical Report,2011.
[9] Maji S,Rahtu E,Kannala J,et al.Fine-grained visual classification of aircraft[EB/OL].2013.
[10] Krause J,Stark M,Jia D,et al.3D object representations for fine-grained categorization[C]//2013 IEEE International Conference on Computer Vision Workshops.December 2-8,2013,Sydney,NSW,Australia.IEEE,2013:554-561.
[11] Ren S Q,He K M,Girshick R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[12] Fu J L,Zheng H L,Mei T.Look closer to see better:recurrent attention convolutional neural network for fine-grained image recognition[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).July 21-26,2017,Honolulu,HI,USA.IEEE,2017:4476-4484.
【通聯编辑:唐一东】
