
集合变换卡尔曼滤波数据同化方法中的协方差局地化
2021-08-02 06:26:50王际朝臧绍东杨俊钢纪艳菊阮宗利
海洋科学 2021年6期
王际朝, 王 玥, 臧绍东, 杨俊钢, 纪艳菊, 阮宗利
(1. 中国石油大学(华东) 理学院, 山东 青岛 266580; 2. 自然资源部第一海洋研究所, 山东 青岛 266061)
数据同化是通过对观测数据与预测值进行分析,寻找一个当前物理状态的最优估计值(分析值), 作为数值预测模型初始条件的方法。作为连接数值模式和观测数据的技术手段, 数据同化在海洋科学领域得到了广泛关注。当前, 集合数据同化方法得以快速发展, 已经成为业务化数值预测的一个可行选择。集 合卡尔 曼 滤波(ensemble Kalman filter, EnKF)[1],可以将卡尔曼滤波应用到强非线性模型, 扩展了卡尔曼滤波的适用性, 是数据同化领域的研究热点之一。EnKF中的预测误差协方差矩阵通过对预测集合成员进行统计计算得到, 预测误差对于集合数据同化方法而言至关重要。然而, 产生足够大的预测集合的计算成本令人望而却步。当使用的集合数目过小时, 则不能在统计意义上充分表示模型的变化, 从而会引起欠采样(under-sampling)。通常, 欠采样会导致滤波发散、预测误差协方差低估和虚假相关等负面问题。由于这些问题的影响, EnKF可能会产生一个次优的分析结果。
在进行数据同化时, 为了克服欠采样带来的负面影响, 有关学者已经提出了很多解决方法。当前基于集合的数据同化研究中, 最著名的解决方法是协方差膨胀(covariance inflation, CI)[2]、协方差局地化(covariance localization, CL)[3-4]和 局 地 化 分 析(local analysis, LA)[5-6]。CI方法通过一个膨胀因子校正预测误差协方差的低估问题, 主要思想是通过膨胀集合均值和集合成员之间的误差来增大预测误差协方差。CI方法用于分析过程之前, 具体表示为:其中“←”表示对于之前状态值的替代,r是所谓的膨胀因子。尽管CI方法克服了预测误差协方差的低估问题, 但是协方差膨胀因子r解决不了虚假相关问题。CL方法在预测误差协方差矩阵和局地化函数之间实施舒尔积运算[7], 通过截断预测误差协方差矩阵中预先指定距离之外的误差相关性以解决虚假相关问题。此外, 舒尔积运算能够提高预测误差协方差矩阵的秩[8]。LA方法以待更新状态变量为中心, 建立一个虚拟的局部窗口, 得到该状态变量预测误差协方差的局部近似值, 在分析更新过程中, 将局部窗口外的集合扰动设定为零。例如, 通常可以以某个状态变量为中心, 仅仅同化与其固定距离为M之内的观测数据, 固定距离的长度决定了同化过程中观测值的数量。显然, 分别对状态变量进行局部同化的特点使LA方法可以利用并行方法进行快速计算。
当前, 越来越多的学者[9-11]关注的是CL方法和LA方法。相比于CL方法, LA方法是一种独立的方法, 它可以用于任何数据同化的框架, 但是它的实际同化效果并不如CL方法。Miyoshi等[12]指出LA方法的同化效果和CL方法类似, 但是LA方法通常会导致弱局地化影响。之后, Janjić等[9]通过对Lorenz96模型进行实验发现: 如果观测误差方差小于初始状态的预测误差方差, CL方法将会导致比较小的估计误差; 如果观测误差方差大于初始状态的预测误差方差, CL方法和LA方法有相同的局地化影响。因此, 从之前的研究和实验可以得出, CL方法可能是相对较好的一个局地化方法。由于CL方法中的舒尔积运算仅仅用于预测误差协方差矩阵,而集合转换卡尔曼滤波(ensemble transform Kalman filter, ETKF)方法中的预测误差协方差矩阵并没有显式计算, 而是传递预测集合扰动矩阵, 这导致ETKF方法中进行舒尔积运算的矩阵维度不一致,所以CL方法不能用于ETKF方法[13]。Janjić等[9]的文章给出了CL方法不适用于ETKF方法的具体讨论。
为了克服CL方法不能用于ETKF方法的限制,在一元模型中, 通过对局地化函数的平方根矩阵和预测集合扰动矩阵进行舒尔积运算, Petrie[14]提出了一种用于ETKF方法的CL近似方法。对于矩阵维度不一致的问题, 通过在预测集合扰动矩阵中添加n-N列零向量(n表示状态变量个数,N表示集合个数), 对矩阵进行扩展来修正。然而, 韩培等[15]对此方法进行探究, 表明这种近似的CL方法是一种弱近似并产生了较差的同化效果。
基于集合样本相关性和矩阵因式分解, 近几年提出了动态计算局地化函数的方法, 使得CL方法可以应用到ETKF方法中。Bishop等[16]提出了一种生成局地化函数的新方法, 该函数能够随真实误差相关函数移动并且还适应真实误差相关函数的宽度。但是此方法的计算代价比较大, 鉴于此, Bishop等[17]提出了一种新的协方差自适应局地化方法(CALECO)的具体实施方案, 成功地将CL方法应用到ETKF方法, 但是此方法仍然具有较高的计算复杂度。基于上述的研究基础, Bishop等[18]在ETKF方法中提出了较为可行的CL方法的实施方案, 并命名为增益集合转换卡尔曼滤波(gain form of ensemble transform Kalman filter, GETKF)。GETKF中使用的是Gaspari等[19]提出的基于距离相关的一个局地裁剪函数作为局地化函数(GC局地化函数), 此方法解决了在一元数值预测模型中CL方法不能用于ETKF方法的问题。
当前, 由于CL方法的实现存在限制, 国内外对于CL方法在ETKF等平方根滤波中的研究较少。本文将基于GETKF方法进行研究, 提出一种局地化效果较好的局地化方法, 并通过数值模拟实验比较本文基于GETKF修改的方法与GETKF方法的同化效果。
1 理论背景与方法改进
Campbell等[20]比较了EnKF方法中分别使用模型空间CL方法和观测空间CL方法的同化效果, 认为模型空间CL方法通常优于观测空间CL方法。因此, 本文以下的研究基于模型空间CL方法。本节首先介绍GETKF方法, 然后对该方法进行改进。
1.1 增益集合转换卡尔曼滤波
在ETKF方法中, 应用CL方法的难点在于预测误差协方差矩阵并没有显式表示, 而是通过预测集合扰动矩阵隐式表达, 因而在预测集合扰动矩阵和局地化函数之间无法进行舒尔积运算, 当前主要的目的是在预测集合扰动矩阵和局地化函数的平方根矩阵中进行舒尔积运算来近似预测误差协方差矩阵和局地化函数之间的舒尔积运算。假定预测集合扰动矩阵表示为
局地化函数ρ的平方根矩阵表示为W, 即

其中, 平方根矩阵W通过对局地化函数ρ进行特征值分解得到, 并且按特征值大小降序排列, 取前10个特征值和特征向量对构成, 即

一般情况, CL方法需要进行如下形式舒尔积运算,

由于之前讨论的ETKF方法的局限性, GETKF方法中采用了集合扩展技术定义一个n× (N×L)维度的矩阵f
Z,

定义矩阵f Z表示局地化后的预测误差协方差矩阵的平方根矩阵, 即
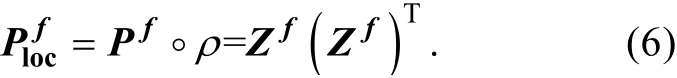
Bishop等[18]已经证明式(6)是成立的。因此成功地在预测集合扰动矩阵实现了CL方法。现在使用代替作为当前的预测集合扰动矩阵, 即局地化后的预测误差协方差矩阵的平方根矩阵, 重新构造集合扩展后的预测集合和预测误差协方差矩阵。
令M=N×L, 则扩展预测集合表示为其中每个列向量如下定义:
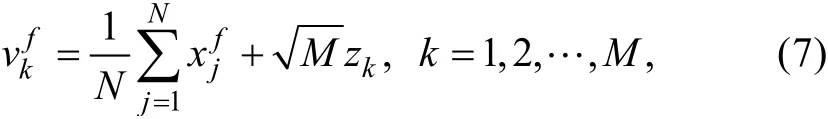
其中,zk表示矩阵的第k列。很显然扩展预测集合的均值与原始预测集合均值相同。扩展预测集合误差协方差矩阵表示为:

GETKF方法的分析过程与标准的ETKF方法的分析过程类似, 区别是GETKF方法使用扩展预测集合以及扩展预测集合扰动矩阵代替原始预测集合和原始预测集合扰动矩阵定义标准化的预测-观测集合扰动矩阵如公式(7)所示:
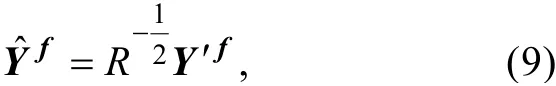
其中,

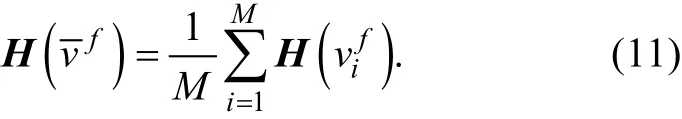
矩阵H表示观测算子。为了提高ETKF方法同化的计算效率, 对标准化的预测-观测集合扰动矩阵进行奇异值分解:

其中, 矩阵U和V是正交矩阵,的奇异值由矩阵∑的对角元素给出。接下来, 分析误差协方差矩阵的平方根矩阵(分析集合扰动矩阵)表示为,
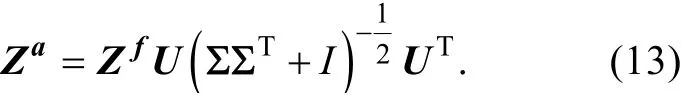

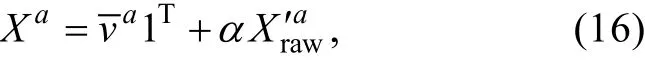
其中,
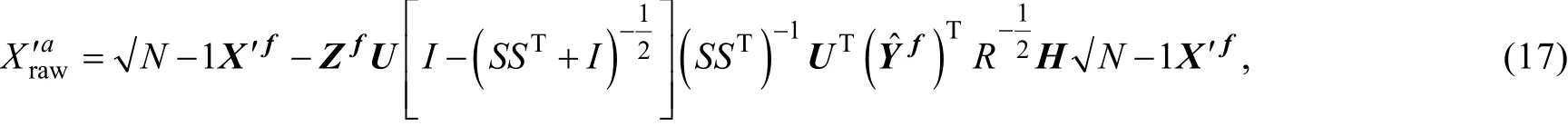

以上展示了GETKF方法的主要计算过程, 可以看出此方法存在改进的空间: 首先, GETKF方法利用集合扩展技术在分析过程中产生M个集合(N<M), 然后使用集合扩展之后的分析误差协方差矩阵计算N个集合的方法较为复杂, 如何更加简便地将M个集合转换为N个集合进行预测过程是值得商榷的; 其次, GETKF方法中计算扩展后的集合误差协方差矩阵采用有偏形式, 本文对此做出了修改,采用无偏形式的矩阵进行计算; 此外, GETKF方法中使用的GC局地化函数是一个基于距离相关的局地裁剪函数, 该函数是一元局地化函数, 所以扩展到多元模型存在限制; 最后, 由于GETKF方法将参数L固定为10, 所以在系统状态变量个数较大的情况下, 扩展后的预测集合扰动矩阵不能很好地表示误差变化。可以看出GETKF方法确实存在的不足之处, 对于GETKF方法的具体改进将在下一节进行说明。
1.2 增益集合转换卡尔曼滤波的改进
基于GETKF方法, 本节从局地化函数平方根矩阵的选取、预测误差协方差的无偏估计、随机子采样方法和GC局地化函数的限制4个方面对原方法进行改进, 以提高同化方法的效果。
1.2.1 局地化函数平方根的选取
对于公式(3)中局地化函数平方根矩阵列数L的选取, GETKF方法按照特征值降序排列, 取前十个特征值和对应的特征向量构成平方根矩阵W,即固定地取L为10。很显然, 在应对状态变量个数n很大时, 前10个特征值和特征向量不能完全表示系统变量的误差变化, 所以本文重新定义了L的选取:

其中,E10%表示前10%的特征值的数量。即给定L的范围, 通过进行多次数值实验选取最优的数值L。
1.2.2 预测误差协方差的无偏估计
通常, 我们假定卡尔曼滤波中的误差协方差矩阵是无偏的。在统计学上, 通过对集合成员与集合均值的偏差除以集合自由度(样本个数减一)来实现。但是GETKF方法中的公式(5)~(7)采用的是有偏形式的误差协方差矩阵, 这导致误差的产生, 造成对误差协方差的低估, 所以本文通过将公式(5)~(7)中的来修正协方差公式, 构造无偏形式的误差协方差矩阵, 从而在进行分析时减少对同化结果的影响。
1.2.3 随机子采样方法
由于扩展后的分析集合数量M大于原始预测集合数量N, 导致集合数量不能在预测模型中进行传递。GETKF方法中利用一个膨胀因子[式(12)]来克服此问题, 该方法需要计算扩展后的分析误差协方差矩阵以及原始预测误差协方差矩阵, 如果变量的个数n很大, 计算难度大大增加。本文使用随机子采样方法进行N列分析集合的选取, 计算简便。随机子采样方法如下:
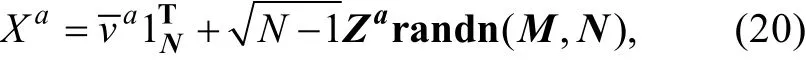
1.2.4 GC局地化函数的限制
GETKF方法中使用GC函数作为局地化函数,但是GC函数仅仅是一个一元变量的局地化函数, 多元模型中不同变量之间的相关性应该是有区别的,GC函数并没有体现这一性质, 所以在多元模型中使用GETKF方法存在限制。本文选用一个基于距离的多元函数Askey函数[21]作为局地化函数, 当前此函数已经用于EnKF方法, 并且在多元模型中进行了实验验证, 得到了较好的同化效果。利用Askey函数将本文修改的方法扩展到多元模型变量中, 探究方法在多元情况下的适用性。
2 实验方案
2.1 模型
2.1.1 KS模型
KS模型的表达式为,

KS模型是一个一元无量纲的非线性偏微分方程模型, 方程中二阶项和四阶项会增加模型的复杂性并导致混沌行为。在本文中, KS模型的偏微分方程通过一个指数时间的四阶龙格库塔数值格式进行离散, 时间步为Δt= 0.25, 终止时间T为250。
2.1.2 浅水模型
浅水模型作为一个多元模型, 在当前的数据同化研究中广泛使用。其忽略摩擦效应、科氏力以及非线性项的方程表示为:

其中,u和v分别表示水平和垂直速度, 水面高度由h表示,g为取值为9.8 m/s2的重力加速度。模型区域选择矩形区域取2 200 km。浅水模型的偏微分方程组使用Lax-Wendroff有限差分方法计算, 时间步为Δt= 0.01, 终止时间T为8。
2.2 局地化函数
对于KS方程等一元模型, 我们可以使用GC函数作为CL方法中的局地化函数ρ, 其表达式如下:

式中,z表示网格点之间或网格点与观测点之间的距离。由于本文使用模型空间CL方法, 所以z表示物理空间中网格点之间的距离。局地化长度尺度c定义为为局地化半径, 是一个可选参数。注意, 因子可以调整局地化函数达到最优[22]。
相反, 多元模型中使用Askey函数的一个多元扩展[21]作为局地化函数ρ, 形式为,

其中,m表示不同的状态变量的总数。例如本文使用的浅水方程中m取3, 则Askey函数表示为:
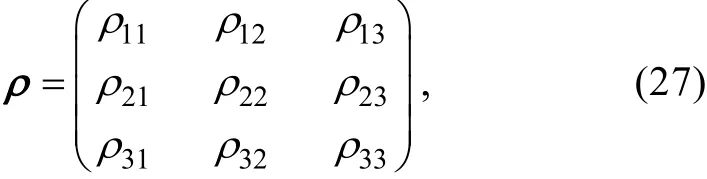
即ρ的每个元素ijρ对应于第i个变量和第j个变量的局地化函数矩阵。由于多元模型引入了一些不同变量之间的联系, 增加了数据同化的复杂度与计算量, 因此多元局地化函数的构造需要考虑这些不同变量之间的联系以及联系的强弱。uij表示第i个和第j个变量之间的局地化影响参数,

Askey函数中的参数z和c与GC函数中定义相同, 分别表示网格点之间的距离和局地化长度尺度。B是一个Beta函数,s表示状态变量所在的欧式空间的维度, 而且要满足条件v≥(s+ 1)/2。
2.3 实验设计
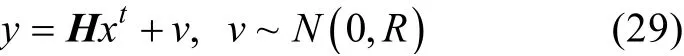
其中, 矩阵H是观测算子, 将真实状态变量映射到观测空间。假定观测误差之间不相关, 则矩阵R为对角观测误差协方差矩阵, 且对角元素取值为1。初始集合通过对真实值t x添加N次随机误差构造。详细的实验参数设置如下。
KS模型具有一维周期性, 设定状态向量u的维度n为256, 初始真实值可以通过定义在周期域0≤x≤32π上的函数给出。实验中分别取集合数N为5或N为10, 观测数p是256或p是235。数值实验的观测频率(同化间隔)不同, 假定每5或10个时间步长存在可用的观测值。
对于多元浅水模型, 假定模型定义在矩形网格区域, 每个网格点定义3个变量: 水面高度h, 水平速度u和垂直速度v。假定水平速度u和垂直速度v的初始真实状态为零, 即u=v= 0, 水面高度h的初始真实状态由如下方式构造,

类似于KS模型中的参数设置, 在浅水方程中,集合数分别取N是5或N是10, 观测数p为300或p为240, 每5或10个时间步长存在可用的观测值。表1中给出了上述具体实验参数的配置, 分别在两

表1 不同实验条件的参数Tab. 1 Parameters for different experimental conditions
个模型中进行8组不同的实验, 其中对于KS方程全观测p为256, 部分观测p为235; 对于浅水模型全观测p为300, 部分观测p是240。
3 实验结果与分析
首先, 分析GETKF方法和本文修改的方法(简称GCL方法)在一元KS模型中的实验结果。为了研究两种方法对预测误差协方差矩阵的影响, 以实验1为例, 取前两个同化时刻(存在观测数据的时刻),比较同化过程中两种方法对于预测误差协方差矩阵的影响。在图1至图4的每一幅图中, 从左到右,从上到下, 依次展示了GC局地化函数、预测误差协方差矩阵、局地化函数和预测误差协方差矩阵做舒尔积运算得到的矩阵、使用局地化函数平方根矩阵与预测集合扰动矩阵做舒尔积运算得到的预测误差协方差矩阵。
图1 实验1中, 第一个同化时刻GCL对预测误差协方差矩阵的影响Fig. 1 Effect of GCL on the forecast error covariance matrix at the first assimilation time in experiment 1

图3 实验1中, 第一个同化时刻GETKF对预测误差协方差矩阵的影响Fig. 3 Effect of GETKF on the forecast error covariance matrix at the first assimilation time in experiment 1
图4 实验1中, 第二个同化时刻GETKF对预测误差协方差矩阵的影响Fig. 4 Effect of GETKF on the forecast error covariance matrix at the second assimilation time in experiment 1
由于KS模型具有一维周期性, 所以GC局地化函数ρ是一个对称矩阵, 且仅在主对角线附近和矩阵边缘存在较强的相关性。很显然, 对于GETKF和GCL这两种方法, 图1至图4中的第4幅子图均显示了使用局地化函数之后协方差矩阵远距离的伪相关得到消除, 并且和第3幅子图相比效果类似, 说明两种方法对于虚假相关性的消除是有效果的。但是,比较图2和图4, 可以看出第2个时刻两种方法的局地化效果是存在偏差的(图例中数值区间不同), 这可能是源于两种方法的具体实施不同。但是总体上两者对于处理伪相关的效果较好, 即截断距离以外的相关性被消除, 邻近状态变量和边界上的相关性得到了保留。

图2 实验1中, 第二个同化时刻GCL对预测误差协方差矩阵的影响Fig. 2 Effect of GCL on the forecast error covariance matrix at the second assimilation time in experiment 1
以实验3和实验7为例, 分别对GETKF方法和GCL两种方法的同化效果进行评估。如图5和图6中不同方法的曲线轨迹所示, 大体上可以看出相比于GETKF方法的同化效果, 本文修改的GCL方法更加接近于真实值的轨迹曲线, 并且减少了滤波发散的发生, 展示了良好的同化效果, 说明在一元数值预测模型下, GCL方法的局地化效果优于GETKF方法。

图5 实验3, KS模型第一个变量的同化效果Fig. 5 Comparison of the assimilation effect of the first variable of the KS model in experiment 3
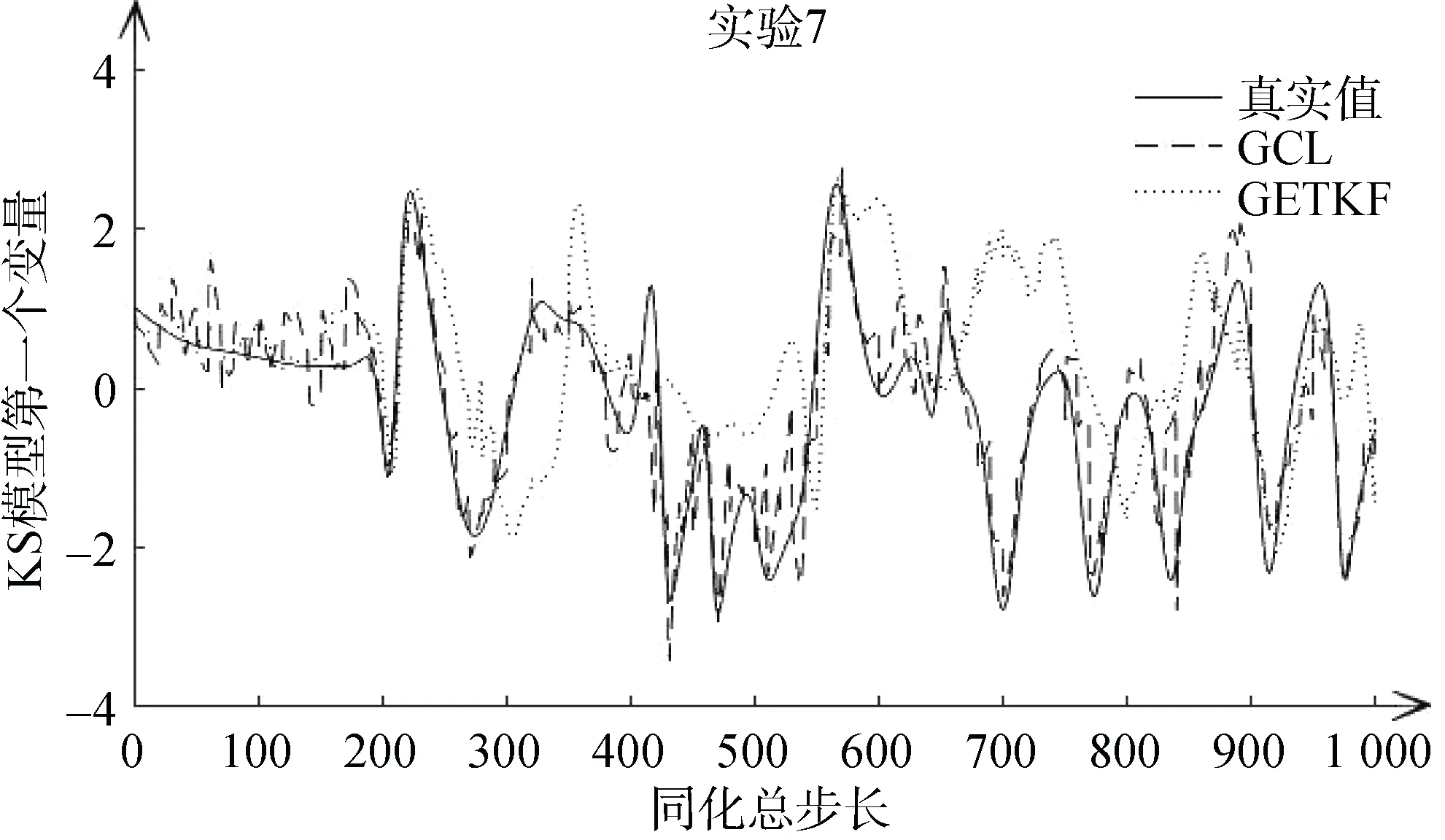
图6 实验7中, KS模型第一个变量的同化效果Fig. 6 Comparison of the assimilation effect of the first variable of the KS model in experiment 7
均方根误差(root mean square error, RMSE)可以量化不同局地化方法的效果, 直观表示不同方法的优劣程度。模型状态变量的整体均方根误差表示为,

其中,l表示同化时间的长度,表示第i个时刻第j个变量的分析值,表示第i个时刻第j个变量的真实值。此外, 由预测集合通过统计意义计算得到预测误差协方差矩阵的秩至多为N-1, 该矩阵是一个低秩的矩阵, 这在传递误差时易造成矩阵的病态, 因此需要提升矩阵的秩。理论上CL方法对于矩阵秩的提升是有效果的, 但是由于CL方法应用于ETKF方法的局限性, 使得效果大打折扣, 所以除了计算同化过程中的RMSE外, 也会对比GETKF和GCL方法使用前后预测误差协方差矩阵秩的变化。具体如表2所示, 首先, 两种方法的预测误差协方差矩阵的秩与不使用局地化方法相比, 显然均有了提高。GCL方法对于矩阵秩的提高更为明显。其次, GCL方法的RMSE明显小于GETKF方法的RMSE(实验6有偏差), 说明在一元模型中, GCL方法的同化效果要优于GETKF方法的同化效果。

表2 KS模型中不同实验条件下RMSE和矩阵秩的对比Tab. 2 Comparison of the RMSE and matrix rank under different experimental conditions in the KS model

续表
表3 中展示了主流的数据同化方法(EnKF)的RMSE, 采用实验1中的观测数和同化间隔, 同时使用变化的集合数进行数值实验。EnKF方法在集合数N是5的情况下, RMSE的数值远远大于GCL方法(实验1), 随着集合数N增大到100, RMSE的数值在降低, 与GCL方法(实验1)的RMSE相当, 但是程序的运行时间也在不断增加。当集合数为N取200时,EnKF方法的RMSE数值低于GCL方法(实验1), 表现出了良好的数据同化效果, 但是程序运行时间是GCL方法使用集合数N为5时的数倍(实验1条件下,GCL方法运行时间为4.83 s)。EnKF通过使用大集合数, 牺牲程序计算时间来获取低RMSE, 并不是一种很好的处理方式, 并且在真实的数据同化方法应用中, 选取超过100个集合是不合适的。上述实验结果表明两种数据同化方法各有优劣, 但是可以看出在集合数较小的情况下, 选择GCL方法进行数据同化的效果较好。
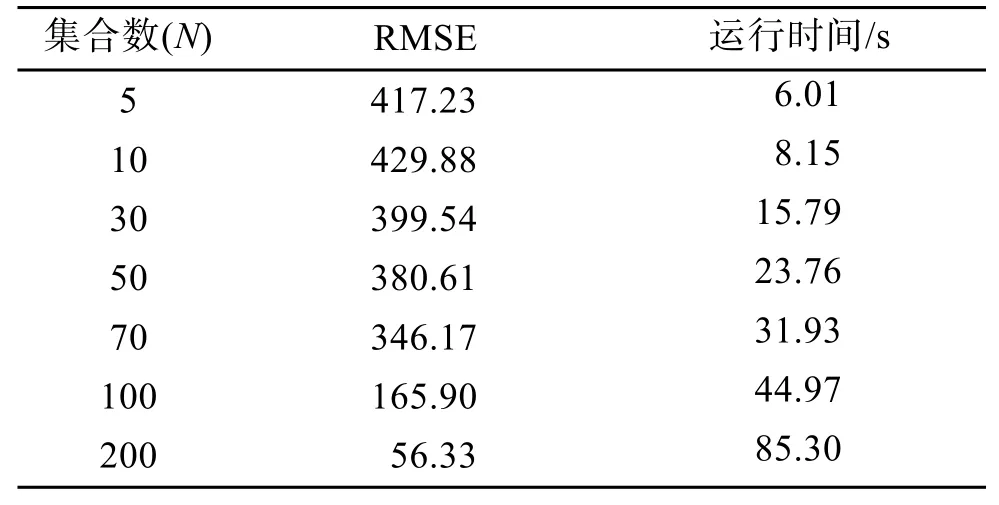
表3 KS模型中EnKF方法的RMSETab. 3 RMSE of the EnKF method in the KS model
最后, 我们将本文提出的GCL方法中的GC函数替换为Askey函数, 扩展方法的适用范围, 在多元浅水模型中检验该方法。表4展示了在不同实验条件下, GCL方法与未使用局地化方法的RMSE以及预测误差协方差矩阵的秩的对比。类似于一元数值模型中的实验结果, 使用GCL方法后的预测误差协方差矩阵的秩与未使用局地化方法相比, 有了明显的提升, 保证了误差矩阵传递的可靠性, 从而GCL方法的RMSE与未使用局地化方法相比也有了明显的降低, 说明利用Askey函数将GCL方法扩展到多元模型是成功的, 克服了GETKF方法只能用于一元模型的局限性。

表4 浅水模型中不同实验条件下RMSE和矩阵秩的对比Tab. 4 Comparison of the RMSE and matrix rank under different experimental conditions in the shallow water model
4 结论
为解决基于集合的卡尔曼滤波中集合数目过少导致的欠采样问题, 以及CL方法对于ETKF等平方根卡尔曼滤波方法的不适用, 本文对GETKF方法进行了改进, 提出GCL方法, 并与GETKF方法在相同实验条件下进行了实验对比。结果表明, GCL方法改善了在一元模型情况中的同化效果, 明显提高了预测误差协方差矩阵的秩, 降低了分析值的均方根误差。此外, 利用一个Askey函数实现局地化方法在多元模型中的扩展, 使得提出的GCL方法可以用于多元模型中, 克服当前多元模型中局地化方法的欠缺。总体来说, 虽然GCL方法在处理欠采样问题以及对于多元模型局地化具有一定的效果, 但是GCL方法应用到多元模型时, 为设计多元变量之间的相互作用关系及相关性, Askey函数需要预先指定的参数较多。在下一步的研究中应找到合适的参数确定依据,使得提出的新方法具有更广泛的适用性。
猜你喜欢
军事文摘(2023年18期)2023-11-03 09:45:42
黑龙江气象(2021年2期)2021-11-05 07:06:54
成都信息工程大学学报(2019年5期)2019-05-21 00:46:34
测绘科学与工程(2017年1期)2017-05-04 03:40:44
太空探索(2016年7期)2016-07-10 12:10:15
自动化学报(2016年8期)2016-04-16 03:38:55
无线电通信技术(2015年3期)2015-12-23 11:37:00
太空探索(2015年8期)2015-07-18 11:04:44
中低纬山地气象(2014年4期)2014-03-11 16:12:59
中国海洋大学学报(自然科学版)(2014年9期)2014-02-28 12:21:33
