
基于机器学习的基坑变形预测研究
2021-08-02 09:53杨建新唐海英
中国科技纵横 2021年9期
杨建新 唐海英
(湖南省核工业地质局三0二大队,湖南郴州 423000)
0.引言
随着城市化建设的高速发展[1],地下空间的开发利用不断深化,基坑的开挖规模日益增长。与此同时,在基坑开挖的过程中,其往往会对其周边环境产生影响,影响周边建筑物及基坑自身安全。而基坑工程在大型工程建设当中,能够保证周围土体稳定性,因此具有重要意义。在进行基坑建设当中,基坑的变形预测及其监测显得至关重要[2]。
一般而言,常见的基坑变形研究方法,主要包括数值模拟[3]、理论计算[4]以及智能算法预测[5]等。在数值模拟方面,Liu Haiming等[6]利用基于有限差分算法的FLAC3D软件,选用2种本构模型,对地面沉降进行了模拟,通过与现场监测数据进行对比,研究了基坑开挖影响范围。刘冰冰[7]采用ABAQUS数值软件,对西安地铁四号线基坑工程沉降进行了模拟分析,研究了基坑开挖降水对相邻建筑物的影响。在理论计算方面,国外学者Peck[8]基于大量的基坑工程数据,提出了基坑地表沉降的计算公式,并得到了广泛应用。此后,段绍伟等[9]根据长沙市地铁开挖的实测数据,采用回归分析方法对Peck沉降计算公式进行了修正。数值模拟及理论计算为现场基坑建设提供了理论指导,但是由于基坑变形的复杂性及随机性,导致现场实际沉降与理论计算具有一定的偏差,而智能算法能够避开基坑变形的内在机理,具有良好的预测能力,目前已经成为基坑变形预测的主要技术手段[10]。
基于此,本文将主要利用随机森林、决策树、支持向量机3种机器学习算法,结合上海某深基坑实测数据,对基坑的变形量进行预测,分析了基坑沉降的影响因素。
1.机器学习算法介绍
1.1 决策树算法
决策树算法是目前最常见的机器学习算法之一,其通过信息熵作为判别标准,将决策树叶节点上的值为输出样本信息,而非叶节点上的值为数据样本中某个属性的划分点,样本数据根据该属性上的不同分割点而被划分为多个子数据集[11]。建立决策树的核心在于非叶节点上属性的选择,即如何选择适当的属性及属性的分割点对样本数据进行划分。
对于回归问题,常用的算法为CART决策树算法。对于给定的训练T={(x1,y1),(x2,y2),...(xn,yn)},根据训练数据集中的几个或者全部特征,按一定的方法对样本数据进行分割,从而建立相应决策树,使得决策树中叶子结点上的值与训练样本中的值相等或接近。决策树建立过程中的核心问题是非子叶节点上特征的选择。假如选择训练集T中的j号特征中的s分量作为分割训练集的阈值,原数据集将分为R1={x|Rj≤s},R2={x|Rj>s}两部分,分割后模型的输出值与实际y值的均方误差可表示为:
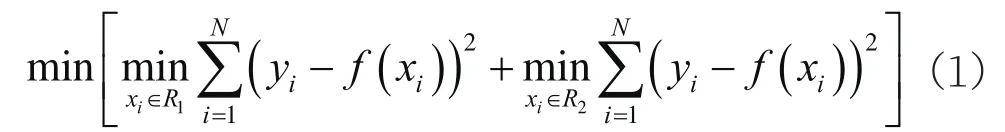
式中,f(xi)代表模型的输出值,其越接近实际值y,说明模型精度越高。
1.2 随机森林算法
随机森林的基本思想是通过Bagging集成,将多个弱决策树求解结果取平均值,从而获得具有较高精确度和泛化性能的算法[12]。模型如图1所示,通过Bootstrap重采样技术,从原始训练数据集D中有放回地重复随机抽取k个样本,生成新的训练数据集,然后基于新生成的k个训练集建立k颗决策树,将这k颗决策树组成随机森林。随机森林的计算结果等于每颗决策树的计算结果求的平均值。

图1 随机森林示意图
1.3 随机森林算法
支持向量机是将实际问题通过非线性变换Φ(x)转换到高维的特征空间,再利用各种优化算法求得最大分类间隔,以使样本点能够线性可分地转换到所得到的高维空间。在这些样本点中,有一部分位于最大分类间隔的超平面之上,即支持向量点[13]。
支持向量机原理如图2所示,设待求解的数据集为(x1,y1),(x2,y2)…(xn,yn),x∈R,y∈R,i=1…N。xn为输入数据,y为输出数据,通过使所有的样本点离超平面的总偏差最小,此时可建立如下关系式:


图2 支持向量机示意图
式中,C、ε为惩罚因子和不敏感损失参数,w,b最优决策函数的函数系数,其映射关系为y=wTΦ(x)+b,K(xi,xj)为核函数,常见的核函数包括线性核函数、多项式核函数、径向基核函数等。通过KKT对线性规划进行求解,其中ai、ain为拉格朗日乘子,系数ai-ain不为0,因此映射关系可以转换为:

2.基于机器学习的基坑沉降变形预测
2.1 工程分析
基坑开挖对于周边地面变形的影响不可忽视,其往往是多因素的共同作用的结果。主要包括:施工工况、岩土层参数、支护结构刚度以及支撑形式等,每种因素对于周边地面变形的影响程度及方式不同,应用传统的理论计算方法,难以考虑多种因素建立准确的基坑沉降预测模型,机器学习方法为此提供了可靠途径。
以上海某基坑工程为例,在现场施工过程中,通过记录基坑开挖深度、开挖面以上地层内摩擦角值、土体粘聚力值、土体重度、地层渗透系数、监测点距离及监测点沉降的实测值。图3为选取的输入变量与基坑变形量的Pearson相关系数图,可以衡量变量之间的线性相关,数值的取值范围为[-1,1]。其中,-1表示为负相关,1表示为正相关。当数值越接近1或-1时,表示相关度越强,越接近0时,则表示相关度越弱。可以看出,输入变量与输出变量之前存在一定的相关性。

图3 输入变量与输出变量相关系数图
基于此,本文选取100组监测数据作为训练样本和测试样本建立预测模型,选取的监测数据涵括开挖前、开挖中及基坑施工后全周期,随机抽取80%的数据作为训练集,剩下20%的数据作为测试集,分别基于决策树算法、随机森林算法及支持向量机算法进行模型预测。
2.2 机器学习超参数调整及其评价指标定义
通过调整模型超参数,以获得最优化模型,提高机器学习模型的预测准确性。本文基于网格搜索交叉验证方法(GridSearchCV)进行超参数调整[14]。如图4所示为5折交叉验证示意图,其原理为通过将超参数数据集分为n个子集,以一个子集作为验证集,其余n-1个子集作为训练集,得到模型的结果,并通过循环变换验证集,重复上述过程,选取模型表现最优的超参数数据集作为模型的超参数。

图4 交叉验证示意图
本文采用拟合优度R2和均方根误差RMSE统计指标作为本文机器学习预测模型精确度的评价指标,其定义如下式所示:
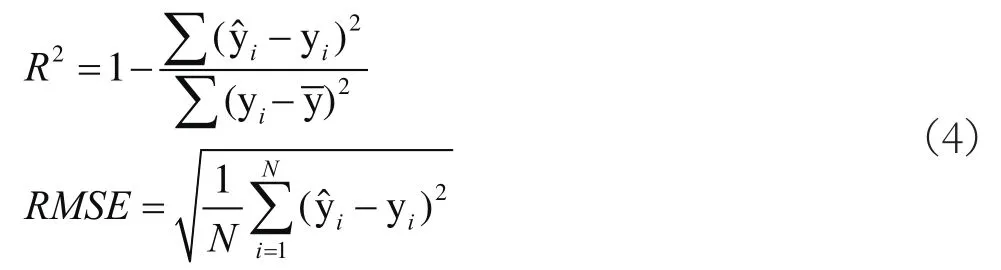
2.3 预测结果及分析
在机器学习中,使用网格搜索交叉验证获得的最佳超参数组合进行建模,各模型在测试集上的性能表现见表1所示。可以看出,支持向量机具有较差的预测效果,随机森林和决策树算法具有较高的预测精度,其拟优度都超过了0.9,且均方根误差在2以下。其中随机森林算法预测能力最好,这主要是由于输入数据与输出数据具有高度非线性,因此集成算法能够具有较高的表现能力。
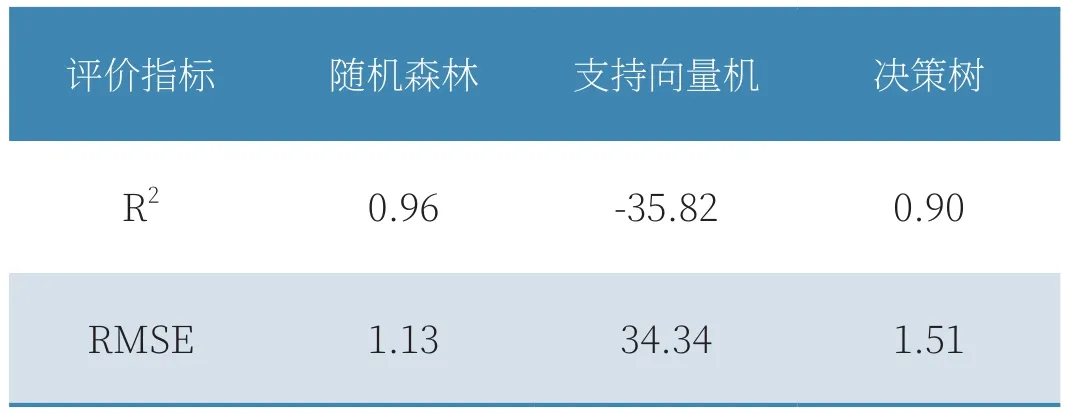
表1 机器学习预测结果对比
通过上述分析,利用3种机器学习模型对整个数据集进行建模分析,最终的结果如图5所示。可以看出,基于随机森林模型和决策树模型的预测值均较好地分布在理想拟合线附近,其最大相对误差为0.35%,具有较高的稳定性。而基于支持向量机模型的预测值则表现较差,其最大相对误差为10.34%,难以满足工程实际要求。总的来说,不同机器学习算法,由于其内核计算方法的差别,在同一工程数据的预测应用中表现出精度差异。

图5 随机森林预测结果
基坑周边沉降实测值和基于随机森林模型的预测值如表2所示,可以看出,对于本文所研究的基坑,基于随机森林模型的预测结果虽有一定的波动,但仍在可接受的范围之内,其相对误差范围为0.13%~2.01%,平均相对误差为0.97%,对于基坑变形预测来说其精度满足要求[15]。
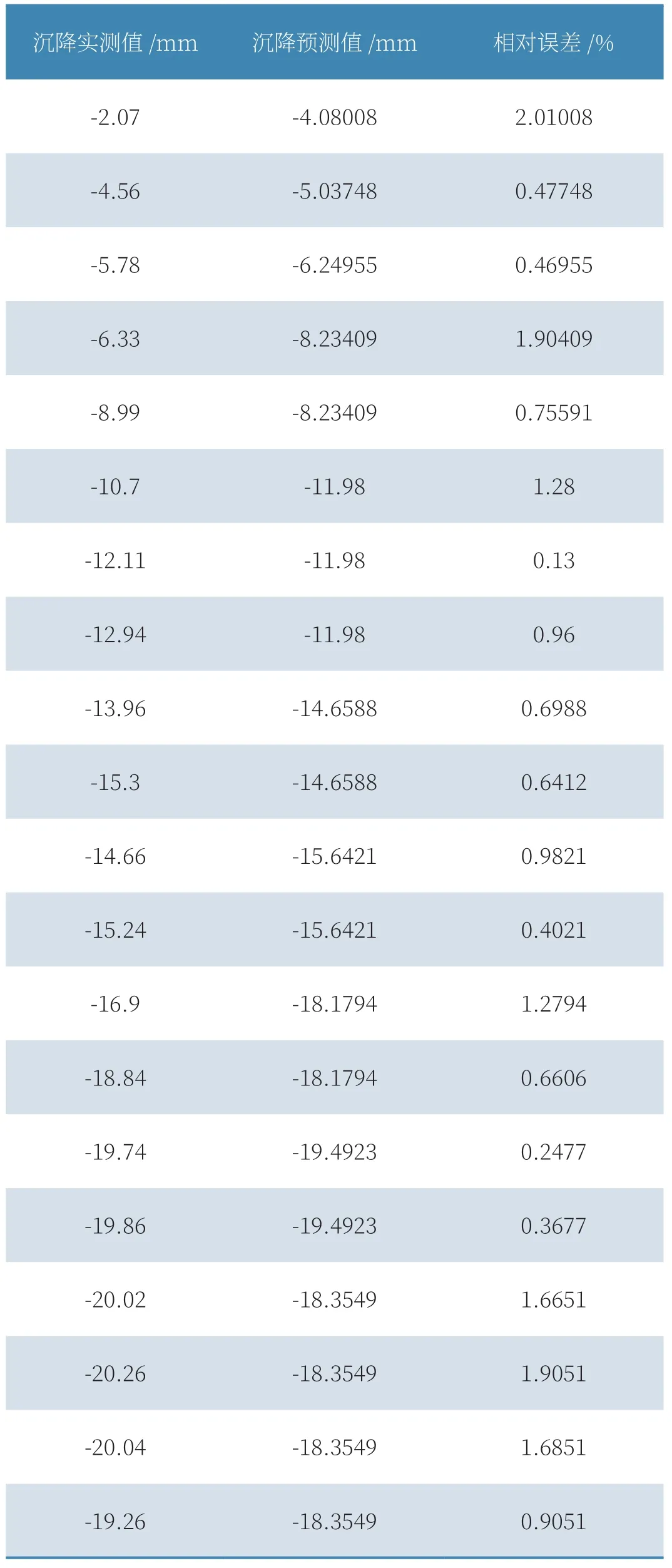
表2 位移实测值与预测值的比较
2.4 影响因素分析
影响基坑沉降的因素很多,但是不同的因素对沉降的影响程度不一样。在机器学习算法中,函数“feature_importance_”对各影响因素的重要性给出了定量解释,具体数学过程如下[16]:
(1)对每一颗决策树,建立决策树前将数据集分为训练集和预测集,选择没有参与建立决策树的预测集数据进行预测,计算出预测值与试验值的误差,记为err1。(2)随机对预测集数据中样本的影响因素(因变量)X加入噪声干扰(即随机改变样本在特征X的值),再次计算预测值与试验值之间的误差,记为err2。(3)假设森林中有N棵树,则影响因素(因变量)X的重要性为:

当加入随机噪声后,模型的精度会发生变化(即err2改变),err2改变的幅度即反映出输出结果对X变量的敏感性,假如X变量对结果无影响,则err2与err1相等,即是ERRX等于0,ERRX越大,说明X变量对于样本的预测结果有很大影响,进而说明该特征的重要程度比较高。进一步基于随机森林模型分析了各影响因素对于基坑沉降的敏感性影响如图6所示。图6中所有的重要性系数总和为1,从中可以看出内摩擦角、粘聚力和检测点距离的相对重要性系数分别为0.245、0.231和0.22,为所有影响因素中较高的3个得分值。在随机森林模型中,影响因素的重要性排名为内摩擦角>粘聚力>监测点距离>土体重度>基坑开挖深度>土体渗透系数,证明了土层本身性质对于基坑的沉降影响至关重要。
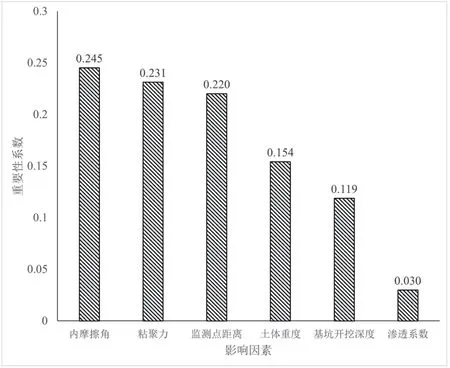
图6 随机森林模型生成的特征重要性
3.结论
本文基于机器学习中的决策树、随机森林和支持向量机算法对基坑沉降进行预测,得出主要结论如下:
(1)传统的模型一般难以考虑基坑的复杂性,本文基于基坑实测数据,建立了基坑沉降预测的机器学习模型,并通过与实测数据进行对比分析,结果表明基于随机森林的预测模型表现优于其他2种模型,其最大相对误差为2.01%。(2)影响因素分析结果表明,众多影响因素中,内摩擦角对基坑沉降的影响最显著,但土层力学性质等特征的影响较为平均,而土层渗透系数对于基坑沉降的影响较小。本文研究结果为基坑工程建设提供有益参考。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电影(2018年8期)2018-09-21
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
