
脸眼协同检测算法在广告推荐系统中的应用
2021-08-02 03:49:08苏彬,梁栋
计算机技术与发展 2021年7期
苏 彬,梁 栋
(1.南京航空航天大学 计算机科学与技术学院 模式分析与机器智能工业和信息化部重点实验室,江苏 南京 210016;2.软件新技术与产业化协同创新中心,江苏 南京 210016)
0 引 言
作为人脸识别、人脸对齐、人脸验证和人脸跟踪等应用程序中的关键步骤,人脸检测的主要任务是确定给定图像或视频中存在的人脸,然后查明脸部的位置和大小[1-3]。在广告推荐场景中,目标是检测当前在广告屏幕前并且正视广告屏幕的用户,识别用户的性别、年龄和身份信息,从而做出准确的广告推荐。广告终端中摄像头的主要目的是检测抓取面向终端屏幕的人脸图像,避免检测抓取到侧脸等其他非正视广告设备的人脸进而导致无效的广告推荐。
人脸姿态估计[4-5]方法有很多,这些方法通常通过二维图像间接获得三维参数[6],以达到人脸姿态估计的目的。然而,非配合式的人脸图像检测[7]在工程应用中由于硬件成本的限制,具有人脸检测功能的智能设备仅适用于简单的人脸检测不具备使用较复杂的人脸姿态检测的算法能力,在该应用中,仅需要检测正对照相机的脸部即可,无需对人脸姿态进行全面的检测评估。因此,需要一种简单有效的检测算法用于检测到关键用户的脸图。
1 算法的选择和优化
1.1 算法比较分析
目标检测算法有两个主要分支:anchor-based的目标检测算法和anchor-free目标检测算法。然而,anchor被越来越多的目标检测算法使用,原因在于预先对要检测的目标可以使用k-means[8]等聚类算法计算出目标可能存在的尺度,这样网络对目标的预测会更加准确。
在PASCAL VOC数据集和COCO数据集[9]上对anchor-based的目标检测算法中的Faster R-CNN[10]、Cascade R-CNN[11]、YOLOv2[12]、YOLOv3[13]、YOLT[14]和SSD网络[15]进行了对比分析。表1是在PASCAL VOC数据集上的对比结果,表2是在COCO数据集上的对比结果。
在表1中,除YOLT之外,其他目标检测算法在PASCAL VOC上的实验结果来自于对应的论文里面的最好的实验结果。

表1 基于anchor的目标检测算法在PASCAL VOC上的检测结果
从表1中可以看到,YOLO、YOLT和SSD的速度要比Faster R-CNN快,这主要是因为YOLO、YOLT和SSD没有生成目标建议区域的步骤,从而大大节省了目标建议区域,进而减少了算法的时间消耗。但是从表2发现,表现最佳的仍然是Cascade R-CNN,与理论结果相同。从理论上讲,Faster R-CNN和Cascade R-CNN比YOLO和SSD更准确,但是检测速度较低。

表2 基于anchor的目标检测算法在COCO数据集上的检测结果
因为该应用场景的困难在于检测作为小目标的眼睛,因此,该文特别关注COCO数据集上的小目标检测结果APs。可以发现最佳结果是Cascade R-CNN,其次是YOLOv3,然后是SSD,最后是YOLOv2。基于以上的比较分析和工程经验,该文选择SSD网络作为基本检测器并根据这种情况对其进行优化。
1.2 SSD介绍
Single Shot MultiBox Detector(SSD)[15]是一种端到端的目标检测算法,该算法也是一种一阶段检测算法,将检测问题直接转化为回归的问题,SSD网络还借鉴了Faster R-CNN中的anchor机制,生成了prior box机制。prior box其实也就是一些目标的候选边界框,之后使用softmax分类和边界框回归得到目标置信度得分和边界框信息。SSD按照如图1方式生成prior box:以特征图上每个网格的中心点为中心,生成一系列同中心的prior box。prior box最小边长为min_size,最大边长定义如下:

图1 prior box
(1)
SSD设置了aspect ratio,利用aspect ratio生成2个长方形,这两个长方形的长和宽分别为:
(2)
(3)
prior box的min_size和max_size由以下公式决定:
(4)
SSD网络最重要的贡献是加入了基于特征金字塔的目标预测方法,该方法使用conv4_3、fc7、conv6_2、conv7_2、conv8_2和conv9_2这些大小不同的特征图来预测不同尺度的目标。SSD在金字塔层次结构的预测特征图上同时添加了分类和边界框回归两个分支网络来进行目标预测。该网络的突出贡献还在于使用高层特征图检测大目标,使用中层特征图预测中等目标,使用低层特征图检测小目标。
该网络采用标准的VGG16作为特征提取器,然后添加额外的卷积层到被截断的VGG16网络中。SSD采用特征金字塔层次结构,利用逐层预测的方法来检测目标。该网络通过多尺度的方法来提高mAP。但是,对于人眼这种小目标检测,SSD的检测效果并不是很好,原因主要有两个方面。原因一在于占图像比例过小的目标经过卷积之后,在conv4_3层输出的特征图上目标尺寸大约为1×1,目标细节的信息将会在conv4_3层之后逐渐消失直至完全消失。原因二在于SSD网络低层的特征图尺寸大,但是特征图所包含的语义信息不够,高层的特征图的语义信息丰富了,但经过太多的池化层,特征图太小了。因此,对于小目标检测来讲,增加特征图尺寸是非常重要的,同时语义信息的添加有益于分类特征的提取。
1.3 优化后的SSD
针对小目标检测的特点[16-17],根据经验,特征图尺寸的大小与小目标检测的性能有很大关系。为了增大SSD网络预测特征图的尺寸,将输入图像的尺寸从300×300调整为500×500。同时为了获得更多有益于小目标分类的特征,追加了3个卷积层在SSD网络之后,这也意味着预测层从原来的6个变为9个。
图2表明优化后的SSD与SSD相比主要有三个方面不同:

图2 优化后的SSD 500×500的网络架构
(1)增大了conv7_2、conv8_2和conv9_2层输出的特征图尺寸。
(2)在SSD网络后追加了conv10、conv11和conv12三个卷积层,从而获取更多有益于小目标分类的特征。
(3)预测层从原来的6个变为9个,增大了网络预测目标的可能性。金字塔结构网络低层用来检测小目标,网络高层用来检测大目标。
优化后的深层次SSD算法,损失函数的计算同SSD算法一致,损失函数如下:
(5)
(6)
(7)
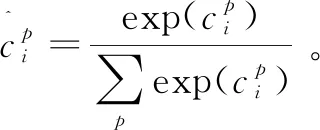
需要分别计算bounding box loss(Loc loss)和classification loss(Conf loss),并最终求和。另外系数α用来平衡两种模型的优化比例,本方法中,它被赋值1;同时在本系统中仅关注人脸、眼睛两个目标,所以检测目标分为2类,即人脸和眼睛,把这种优化后的SSD算法命名为optimized SSD。
1.4 目标脸图的选择和标准化方法
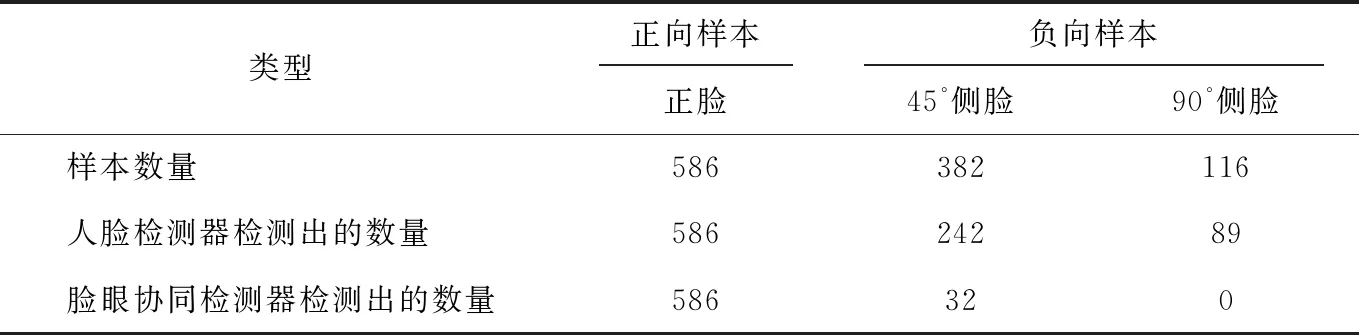
在检测到人脸和眼睛后,首先将人脸按照像素大小进行排序,并从最大的人脸图像中判断在该人脸区域中是否同时有两只眼睛,如果没有,则判断下一张人脸。如果存在,则检查左眼与人脸图像左边缘之间的距离以及右眼与人脸图像右边缘之间的距离差是否超出限制;如果否,则该人脸为目标人脸,即正对广告屏幕的用户,并停止判断;如果不是,将判断下一张脸,直到判断出检测到的最小脸为止。判断左右眼睛和脸边缘的距离差是否超过限制的方法如下:第一步设备脸图的bounding box为Pf(xfyfwfhf),两只眼睛的bounding box分别为Pe1(xe1ye1we1he1)和Pe2(xe2ye2we2he2),如果xe1 |2*[(xe1-xf)-(xf+wf-xe2-we2)]/[(xe1-xf)+(xf+wf-xe2-we2)]|*100% (8) 如果xe1>xe2,则误差率是: |2*[(xe2-xf)-(xf+wf-xe1-we1)]/[(xe2-xf)+(xf+wf-xe1-we1)]|*100% (9) 如果误差率大于等于30%,将认为误差率超限,这种检测器定义为脸眼协同检测器。 相比于眼睛检测,人脸检测属于大目标检测,所以在数据选择和设计阶段更关注眼睛的检测,而且适合工程场景的人脸及眼睛数据采集与标注是进行实验的基础。这些图像的采集主要有三个方面,一个是自己收集的场景应用中的正样本图像2 680张,负样本图像896张,另外是使用了FDDB和CAS-PEAL[18]中的数据集。训练集、验证集和测试集的详细信息如表3所示。数据集中的负样本图像是非目标对象(例如侧面,头部等),由于人眼的尺寸在图片中所占比例太小,因此,眼睛检测定位是一项重要的任务。 表3 训练数据集 分析了数据集中眼睛占整个画面比例大小的分布情况,眼睛尺寸占画面的比例定义如下: ∂=object_size/image_size (10) 根据∂值的范围,将单只眼睛尺寸从小到大(S,M,L,XL)进行了排序,其中S对应∂≤0.5%,M对应0.5%<∂≤1.5%,L对应1.5%<∂≤5%,XL对应5%<∂。 训练数据集经过分类后小尺寸眼睛图片S占整个数据集的35.62%,中尺寸眼睛图片M占整个数据集的56.44%,大尺寸眼睛图片L占整个数据集的7.78%,因此该数据集更加关注小尺眼睛目标,同时也考虑到了不同尺度眼睛目标。 文中使用小尺寸眼睛数据集S和整个数据集W的训练集来训练网络。在Caffe框架下,使用一块P4的NVIDIA GPU进行实验。实验中使用训练好的SSD 500×500网络模型作为预训练模型来训练Optimized SSD和它的变种网络,然后在训练集S和W上微调网络模型。为了定量和定性地分析比较网络,所有网络的基本参数设置如下:迭代次数为120 k,动量大小为0.8,权重衰减大小为0.000 5,批处理大小为6。网络训练的初始学习率为10-3。当网络迭代到6万次,9万次和12万次时,学习率变为10-4,10-5和10-6。所有新的添加层初始化模式是“xavier”。训练阶段的每次迭代过程,网络模型会预测目标的边界框和类别,然后去更新网络参数来最小化分类和定位损失。 2.2.1 Optimized SSD与SSD的比较 实验中,使用了SSD网络在小尺寸数据集S和整个数据集W训练集上训练SSD和Optimized SSD网络,然后在对应的验证集上评估它们,实验结果如表4所示。 表4 Optimized SSD和SSD网络在验证集S和W上的实验结果 Optimized SSD方法在验证集S和W上都取得了更好的性能。在验证集S上,Optimized SSD网络将SSD网络的检测精度从87.61%提升到了89.81%。同时,在验证集W上,Optimized SSD网络将检测结果从92.03%提高到了93.16%。虽然Optimized SSD 500×500的检测速度略低于SSD 500×500,但仍然能满足实时检测的要求。 2.2.2 基于Optimized SSD 的Face detector和Face-eyes Co-detector对比实验 为了评估Face-eyes Co-detector在检测目标人脸中的性能,使用Optimized SSD训练了仅检测人脸的检测器,和同时检测人脸和双眼的Face-eyes Co-detector,两种检测器使用相同的训练数据和参数,比较并分析了上述两个检测器的实际效果。使用了两种方法,第一种方法是使用CAS-PEAL数据集中的1 084个样本图像,包括586个正脸图像、382个45°侧脸图和116个90°侧脸图。 验证负样本检测率,比较结果如表5所示。 表5 使用方法一的比较结果 第二种方法用来验证在相同应用环境中的实际检测效果。这种方法分别使用Face detector的设备收集了3 005张脸图和使用Face-eyes Co-detector收集了2 982张图像,然后使用基于三维模型和仿射对应原理的人脸姿态估计方法将采集的图像分类为正脸(小于15°的),15°至45°的人脸和大于45°的人脸三个类别。实验比较结果如表6所示。 表6 方法二对比结果 定义错检率为非目标人脸数量占总检出人脸总数的比例,非目标人脸包含了yaw大于15°的侧脸,其中细分为15°≤yaw<45°侧脸和yaw>45°的侧脸。从图3可以看出,使用Face-eyes Co-detector在广告推荐场景中错检率远低于非脸眼协同检测器,尤其是大角度的侧脸,两种方法使用脸眼协同检测器检出率均为0。 图3 错检率 针对广告推荐场景,提出了眼脸协同检测器(Face-eyes detector)和Optimized SSD网络,Optimized SSD算法可提高检测眼睛等小目标的准确性。同时,设计的协同检测器,能够快速筛选出注视广告屏幕的人脸,避免捕获无效的人脸进行进一步的检测分析,减少对资源的消耗,并有效提升广告推荐的精准度。此外该算法避免使用复杂的脸部关键点检测和姿态评估算法,减少了对硬件资源的消耗,提高了检测效率。2 实 验
2.1 实验数据和训练

2.2 实验结果



3 结束语
猜你喜欢
智族GQ(2022年12期)2022-12-20 07:01:18
China’s foreign Trade(2021年6期)2021-12-26 06:22:58
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
动漫星空(2018年9期)2018-10-26 01:17:14
汽车与新动力(2017年3期)2017-06-29 12:00:21
幼儿教育·父母孩子版(2016年5期)2016-10-08 16:30:28
学苑创造·A版(2016年5期)2016-06-21 01:58:27
儿童故事画报·智力大王(2015年12期)2016-01-23 01:18:11
爆笑show(2015年5期)2015-07-09 19:27:38
中华奇石(2015年5期)2015-07-09 18:31:07
