
音视频大数据样本库入库规范
2021-07-29 07:32:56韩志峰白雪冰蒋龙泉黄云刚冯瑞
微型电脑应用 2021年7期
韩志峰,白雪冰,蒋龙泉,黄云刚,冯瑞
(1.复旦大学 软件学院,上海 200438;2.复旦大学 工程与应用技术研究院,上海 200438;3.复旦大学 计算机科学技术学院,上海 200438;4.上海海潮新技术研究所,上海 200438)
0 引言
随着互联网、物联网的迅速普及,以音视频为代表的非结构数据呈现爆发式增长趋势,不仅包含了结构化数据,还包含了大量非结构化数据,如视频、图像和语音等。当前互联网上的视频有数十亿,并仍然在实时急剧增长,例如流媒体视频领域巨头,Netflix网站视频数量增长惊人,其中原创视频数量平均每年在以185%的速度增长,如图1所示。

图1 Netflix网站平均日增原创视频数量图
如何对如此巨大的数据进行有效分类管理,并实现灵活调用的问题日益突出。
现在已经有很多公开的大型图片数据集,并在目标检测领域产生了不错的效果,例如ImageNet就有超过1 400万张图片[1]。目前,图片数据集较为成熟,但在音视频数据领域并没有一种完善的数据集标准。这种典型非结构化数据面临分析理解困难、结构化难度大、数据标准不统一和智能分析模型训练样本不足等问题,急需形成音视频大数据样本库标准,有序地组织大量的音视频数据,提升调用效率。
1 音频数据入库规范
1.1 音频样本库概况
大量的音频数据来源于不同的环境,例如监控录音、在线音频等,包含不同的声音类别,具有不同的文件格式和音频长度。考虑到音频数据使用的普适性,也为了确保读入的音频数据格式统一,对不同格式保存的音频数据都会统一转化为wav音频格式。为保证数据的平衡性,要保证每段音频长度介于2秒—10秒之间,过长的音频样本数据被切割成合适大小的多个音频样本,每个片段应明显属于某一声音类别[2]。
大量的音频样本经过切割后,样本数据文件数量会大幅增加,为减小系统查找文件的负担,需要将音频样本文件分别放在不同的文件夹下面。
音频样本库中,除了音频本身,同样包含用于描述音频样本相关信息的文件,需要包含音频类别、声音级别等信息。为减少数据冗余,消除数据的修改异常、入库异常和读取异常,音频数据样本相关信息统一放入csv文件,以行为单位,每行包含一个样本的相关信息。
1.2 编码设计
根据音频的信息类别,需要对6类信息进行编码:
(1)原始文件名:使用正整数作为ID表示,能够唯一标识一个样本,不能为空,从1开始每个文件增加1。具有后缀‘.wav’。
(2)声音类别:使用正整数作为ID表示,从1开始每类增加1。每种类别应具有唯一ID。
(3)声音来源环境:使用正整数作为ID表示,从1开始每类增加1。每种类别应具有唯一ID。
(4)声音分级:0表示背景音,1表示前景音。
(5)切割后文件名:[原始文件ID]-[声音类别ID]-[声音分级]-[声音片段序号]。具有后缀‘.wav’。其中声音片段序号使用正整数作为ID表示,从1开始每条增加1。来自不同原始文件的切割文件声音片段序号互不相关,都重新计数。
(6)存放文件夹名:使用字符化正整数作为ID表示,从1开始每个文件夹增加1。
1.3 概念结构设计
每个样本(指切割后的音频文件)的相关信息应该包含文件名、文件夹名、原始文件ID、在原始文件中起始时间、在原始文件中结束时间、声音分级、声音类别ID和声音来源环境ID。将所有样本的信息依照顺序保存到一个csv文件中。
为尽量减少数据冗余,将一个csv文件当作声音类别对照表保存声音类别与ID的对应关系。同样也使用一个csv文件当作声音来源环境与ID的对应关系。
1.4 信息设计规范
(1)数据文件
• 样本文件名称
切割后的样本的文件名。‘[原始文件ID]-[声音类别ID]-[声音分级]-[声音片段序号].wav’
示例:100-20-0-5.wav
上述文件名表述了是第100个原始文件切割所得,声音类别是第20种,0表示是背景音,5说明是这个原始文件切割出的第5个片段。
• 原始文件ID:
原始文件的ID,可以由此ID找到原始文件。
示例:100
表示这个样本是由100号原始文件切割得来。
• 开始
本样本在原始文件中的开始时间。
示例:12.12
表示样本从原始文件12.12秒开始。
• 结束:
本样本在原始声音中的结束时间。
示例:19.12
表示样本到原始文件19.12秒结束。
• 声音分级:
声音的(主观)显著性等级。0 表示是背景音,1表示是前景音。
• 文件名:
该文件分配到的文件夹编号。
示例:100
表示样本存放在第100个文件夹下。
• 类别ID:
声音类别的数字ID。
• 环境ID:
声音类别的数字ID。
(2)对照表
• 声音类被对照关系:[类别ID] [类别名]
示例:1 boom
表示第一类声音是爆炸声。
• 声音来源环境对照关系:[环境ID] [环境名]
示例:2 street
表示第二类声音是来自与街道。
2 视频数据入库规范
2.1 视频样本库概况
视频监控在现代城市中正发挥着越来越重要的作用,交通要道、景区、商场、超市和楼道等地方都安装有监控摄像机,每时每刻都会产生大量的视频数据,对数据存储的方式方法都有较高要求,不同格式的视频数据处理也会不同,因此需要统一将所有视频转换成wmv格式进行存储[3]。
在利用智能分析算法处理视频时需要逐帧分析处理,1小时的视频数据按标准25 bps测算,需要处理9万帧图像,计算需求极大。为了保证数据的平衡性以及针对性的处理视频,需要对视频数据文件进行切割,将原视频分成5到10分钟不等的视频片段,并对拆分的视频片段进行信息标注。
2.2 编码设计
视频数据文件的编码应包括以下内容。
(1)原始视频文件名:使用字符化正整数作为ID表示,从1开始每个文件增加1。具有后缀‘.wmv’。
(2)视频类别:使用正整数作为ID表示,从1开始每类增加1。每种类别应具有唯一ID。
(3)切割后文件名:[原始文件ID]-[视频类别ID]-[视频片段序号]。具有后缀‘.wmv’。
其中声音片段序号使用正整数作为ID表示,从1开始每条增加1。来自不同原始文件的切割文件声音片段序号互不相关,都重新计数。
(4)存放文件夹名:使用字符化正整数作为ID表示,从1开始每个文件夹增加1。
2.3 概念结构设计
每个原始视频文件应该包含一个csv文件,用于记录文件名、文件夹名、原始时长和所分片段数。
分割后的每个视频的csv文件应在包含原视频信息的基础上,增加分割信息,如视频的起止时间、视频段ID和视频类别。
2.4 信息设计规范
(1)数据文件
样本文件名称
切割后的样本的文件名。‘[原始文件ID]-[视频类别ID]-[视频片段序号].wmv’。
示例:100-2-5.wmv
上述文件名表述了是第100个原始文件切割所得,视频类别是第2种,5说明是这个原始文件切割出的第5个视频片段。
• 原始文件ID:
原始文件的ID,可以由此ID找到原始文件。
示例:100
表示这个样本是由100号原始文件切割得来。
• 开始:
本样本在原始文件中的开始时间。
示例:12
表示样本从原始文件12分钟开始。
• 结束:
本样本在原始声音中的结束时间。
示例:19
表示样本到原始文件19分钟结束。
示例:-1
表示样本到原始文件最后时刻结束。
• 文件名:
该文件分配到的文件夹编号。
示例:100
表示样本存放在第100个文件夹下。
• 类别ID:
声音类别的数字ID。
示例:5
表示样本属于视频类别中的第5类。
(2)类别对照表
对照关系:[类别ID] [类别名]。
示例:1 Abandon
表示第一类视频用于遗留物检测。
3 图片数据入库规范
3.1 图片样本库概况
随着深度学习的快速发展,各种优秀的目标检测算法相继涌现。目标检测的任务就是找出图像中我们所需要的目标,并且确定其位置及其他属性[4],如图2所示。

图2 目标检测效果示例图
图2左侧输入为待检测图片,右侧输出为标注了小狗位置的图片,要使用深度学习算法[5]实现上述的处理,就需要用大量标注了小狗位置的图片对神经网络进行训练。本文建立的图片样本库将仿照PASCAL VOC数据集对图片进行分类存储[6],并产生相应的标签文件,对图片中的信息进行存储[7]。
3.2 层级结构
目前分成4大类、8小类,后续可针对相应的需求进行扩展,加粗字体为最终检测的目标,层级结构图如图3所示。
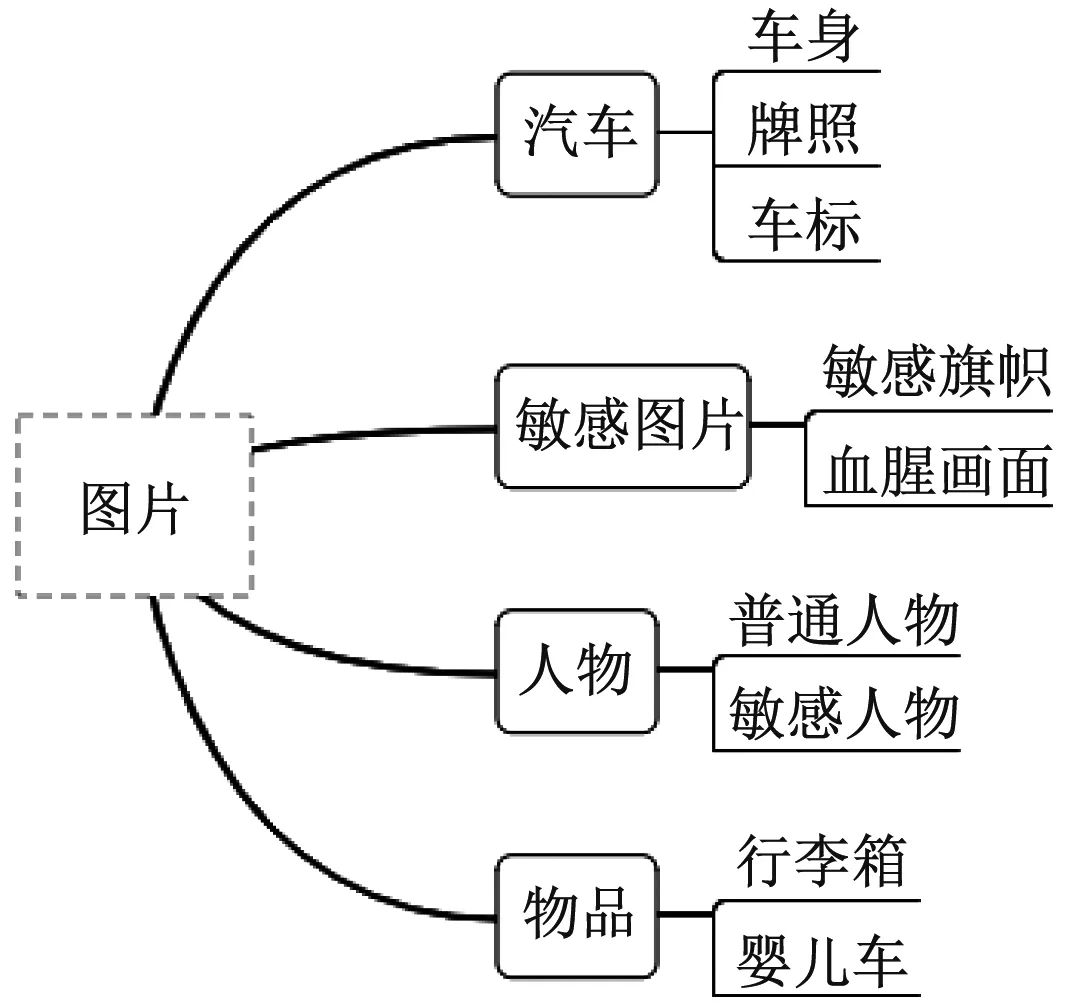
图3 层级结构图
3.3 编码设计
(1)图片文件名:使用字符化正整数作为ID表示,从1开始每个文件增加1。具有后缀‘.jpg’。
(2)xml标签文件[8]:使用字符化正整数作为ID表示,文件名与对应的图片相同。具有后缀‘.xml’。
(3)数据集分割文件名:训练集为train,验证集为val,测试集为test,并且具有后缀‘.txt’。
3.4 标签文件设计
图片的注释方式为xml文件,注释规则[9]如表1所示。
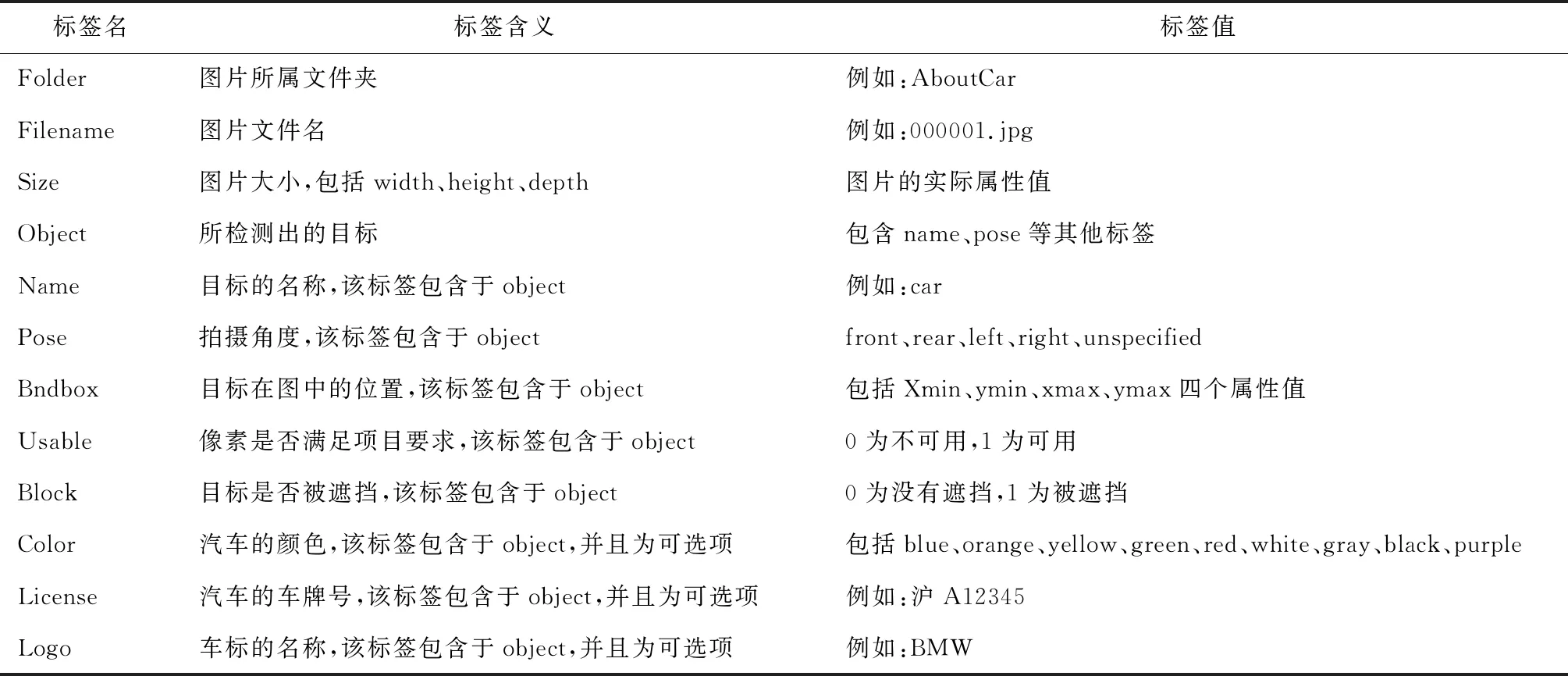
表1 xml注释规则表
4 总结
本文针对当前海量音视频样本数据管理难的问题,形成了一套面向大规模音视频数据的入库规范,在实验中运行声音识别算法和视频处理算法时,都能够正确调用特定范围的音视频。在一定程度上优化了音视频数据的调用效率,减少了数据的冗余度。
在数据实验过程中发现,大规模音视频样本数据集仍存在一些问题,例如数据重叠、数据分类不明确等,对数据调用的准确性有一定影响。后续将对样本入库规范进一步优化,细化数据信息,尽可能降低数据的冗余。此外将结合半自动化标注工具,为用户提供接口,针对模糊数据进行人工修正和更新,以保证样本库的准确性和时效性。
猜你喜欢
作文周刊·小学一年级版(2023年40期)2023-10-18 08:07:57
新世纪智能(语文备考)(2019年10期)2019-12-18 02:46:14
山东冶金(2019年5期)2019-11-16 09:09:22
电脑爱好者(2019年9期)2019-10-30 03:43:29
电脑爱好者(2019年13期)2019-10-30 03:36:29
家庭影院技术(2019年7期)2019-08-27 02:42:20
中学生数理化·七年级数学人教版(2018年9期)2018-11-09 01:24:56
电子制作(2018年12期)2018-08-01 00:48:06
中国交通信息化(2017年2期)2017-06-06 05:49:47
电脑迷(2014年8期)2014-04-29 07:37:40
