
基于卷积神经网络的商品图像识别系统设计
2021-07-28 02:27蒋达央
北京工业职业技术学院学报 2021年3期
蒋达央
(常州信息职业技术学院,江苏 常州213164)
0 引言
随着人工智能技术的发展,在商业领域基于机器识别的AI应用越来越广泛。用二维码扫描商品的传统结算模式因结算误差率高、人工占用多、结算效率低等问题而矛盾凸显。基于AI技术的新零售商品结算形式——商品图像识别自动结算系统正逐步成为研究的热点。基于卷积神经网络的商品图像识别系统涉及的内容很多,笔者重点针对系统设计、网络架构和学习设计展开研究。
1 卷积神经网络(CNN)概述
卷积神经网络(CNN)是一种人工神经网络,具有深度前馈特性[1]。CNN与传统BP神经网络相比,其优势在于对图像这类二维矩阵有良好的抽象表达,每个神经元可以直接输入,做卷积计算。一个典型的CNN包含5个层:数据输入层、卷积层、ReLU激励层、池化层、全连接层[2]。基于神经网络的图像识别人工智能在安防领域应用广泛,如人脸识别、车牌识别、违禁物体检测等。目前流行的CNN框架有FACEBOOK使用的Torch、Google使用的TensorFlow、Berkeley的CV工具包Caffe[3]。
在一个图像识别网络系统中,卷积网络的输入层负责将商品图像信息录入并进行预处理,是一个二维矩阵;卷积层将挖掘二维图像矩阵的关联性和不变性特征;激励层是指卷积神经采用收敛速度更快、梯度运算更简单的ReLU激励函数[4];池化层通常也称为采样层,主要用来降低图像的维度,例如过滤不重要的高频信息,减少冗余信息,通俗说法就是压缩图像;全连接层是指在各个卷积层之间,层与层都有神经元连接。
2 商品图像识别系统设计
根据智能商务运行的需求分析和使用场景,综合考虑系统的响应时间、识别准确率、系统稳定性这3个性能指标,笔者着重从总体框架和网络架构2个层面展开分析。
2.1 总体设计
基于CNN的商品图像识别系统总体框架如图1所示。
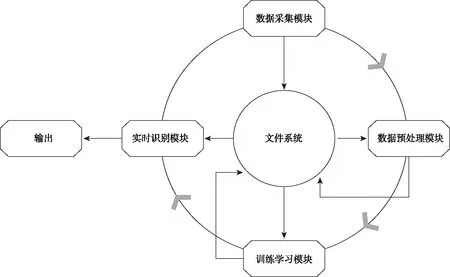
图1 商品图像识别系统总体框架图
商品图像由数据采集模块将采集到的多张原始商品图片数据进行处理,并筛选出相机在不同角度拍摄而产生的商品差异化照片,而后按类别分类存放于文件系统;数据预处理模块主要对文件系统中的原始照片数据进行诸如去除背景、凸显图像特征等数据归一化处理操作,并将处理后的数据存放于文件系统;训练学习模块则从文件系统中读取预处理后的数据,实施卷积训练学习计算,并将学习结果置于文件系统;实时识别模块则对训练学习文件进行识别,得到最终的识别结果,而后根据数据库中查到的相关商品信息,核算出该商品的价格。
2.2 CNN架构
2幅图像在CNN中的对比是划块进行的,这些被划分的小区域被称为特征。相比于采用基于全图逐像素的全量匹配比较,CNN效率更高。它通过寻找给定的2张图片中相似位置上的粗糙特征实施匹配计算,可以更快、更好地反映图片的相似度。通常使用滤波器来计算这些特征,这个滤波器又称为卷积模板。
目前主流CNN的卷积核通常采用3×3,5×5,11×11尺寸。在实际应用中,针对不同使用场景,可以采用不同尺寸的卷积核。卷积核越大,感受域(receptive field)就越大,图片包含的信息就越多,因此获得的图像特征就越完整。但是卷积核越大,同时也造成计算量暴增,不利于图像模型的深度增加,因而会降低计算性能。综合考虑,通常使用多个小卷积核叠加的方式来替代1个单独的大卷积核。这种方式的效果是在连通性保持不变的情况下,可以有效降低计算复杂度和参数个数。
系统的神经网络由3层卷积层和3层池化层组成。在第1层模型中,采用3×3卷积核、深度为32、通道数为32、步长为1的相同填充的办法进行卷积计算,并使用2×2最大池化(max-pooling)的方式进行池化计算;在第2层模型中,采用以第1层的输出作为输入,除了深度和通道数变为64,其余均不变的办法进行卷积和池化计算;第3层模型与第2层模型类似,以第2层的输出为输入,卷积核大小不变,深度改为128,通道数改为128,步长不变,填充方法不变,进行卷积计算和池化计算。当3层卷积和池化计算完成后,输出数据进入全连接层。在全连接层,要对第3层的输出做全连接,且要得出训练结果,并将结果存储到模型文件中。
3 商品图像识别训练学习设计
训练学习设计是在搭建基础的运行环境的前提下,通过对商品实时识别系统设计CNN,并对输入的商品图像数据进行训练学习。针对训练学习的结果,提供相应的接口给其他的功能模块调用。
3.1 神经网络模型结构构建
系统采用大型深度CNN算法中的AlexNet模型,这种模型的优势在于训练时间加快,且能有效地防止过拟合。MXNet作为其中功能强大的工具包,能满足CNN的结构和每个卷积层的设置。精简模型代码如下:
#INPUT
Import_data=mxnet.symbol.Variable('pic')
#one /*第一层*/
conv1=mx.symbol.Convolution(kernel=(11,11),stride=(3,3),num_filter=95,data=import_data) /*设置第一层卷积层的参数*/
R1=mx.symbol.Activation(act_type="relu",data=conv1) /*设置激活层参数*/
P1=mx.symbol.Pooling(pool_type="max",kernel=(4,4),stride=(3,3),data=R1) /*设置池化层参数*/
L1=mx.symbol.LRN(alpha=0.00001,nsize=6,beta=0.77,knorm=2,data=P1)
#two /*第二层*/
conv2=mx.symbol.Convolution(kernel=(4,4),pad=(1,1),num_filter=384,data=l1)
R2=mx.symbol.Activation(act_type="relu",data=conv2)
P2=mx.symbol.Pooling(kernel=(4,4),stride=(3,3),pool_type="max",data=R2)
L2=mx.symbol.LRN(alpha=0.00001,beta=0.77,knorm=2,nsize=6,data=P2)
#thr /*第三层*/
conv3=mx.symbol.Convolution(kernel=(5,5),pad=(1,1),num_filter=256,data=L2)
R3=mx.symbol.Activation(act_type="relu",data=conv3)
#four /*第四层*/
conv4=mx.symbol.Convolution(kernel=(5,5),pad=(1,1),num_filter=256,data=R3)
R4=mx.symbol.Activation(act_type="relu",data=conv4)
#five /*第五层*/
conv5=mx.symbol.Convolution(kernel=(4,4),pad=(1,1),num_filter=384,data=R4)
R5=mx.symbol.Activation(act_type="relu",data=conv5)
P3=mx.symbol.Pooling(kernel=(4,4),stride=(3,3),pool_type="max",data=R5)
#six /*第六层*/
Flat6=mx.symbol.Flatten(data=P3) /*j将多位数据转化为1维数据*/
Fc6=mx.symbol.Fully Connected(num_hidden=6144,data=Flat6) /*设置全连接层参数*/
R6=mx.symbol.Activation(act_type="relu",data=Fc6)
Drop1=mx.symbol.Dropout(p=1,data=R6)
#sev /*第七层*/
Fc7=mx.symbol.Fully Connected(data=Drop1,num_hidden=6144)
R7=mx.symbol.Activation(act_type="relu",data=Fc7)
Drop2=mx.symbol.Dropout(p=1,data=R7)
#eight /*第八层*/
Conn8=mx.symbol.Fully Connected(num_hidden=55,data=Drop2)
#OUTPUT
Img_symbol=mxnet.symbol.Softmax Output(data=Fc8,name='imgmax') /*对输出层神经元产生的误差值进行调整*/
3.2 交叉训练网络模型构建
首先通过初始化网络模型结构,设置模型训练次数train_num为200次,显示误差值的迭代频率frequent为20次,设置学习率learning_rate=0.02。在经过对该神经网络进行4 000次的迭代,得到最终训练结果[5]。核心算法如下:
NM1=mxnet.mod.Module(context=mxnet.Gpu(),symbol=img_sym)
NM1.fit(optimizer='SGD',le_data=val_Fliter,execise_Fliter,optimizer_pams={'learning_rate':0.02},le_metric='acd',finnal_batch=mxnet.callback.Speedometer(batch_size=40,frequent=20),train_num=200)
Rigth_levl=NM1.score(le_fiter,['acd']) /*对训练结果实施评估,预测数据集并计算准确率*/
经过6 h左右的计算训练后,系统得出了稳定的有效结果,交叉训练网络模型获得的bath数据集的准确率基本稳定在81.34%。收敛结果如下所示:
Train_right_result=0.8134245
Validation_right_result=0.802854
3.3 模型保存
通过观察图像识别训练模型每次训练得出的模型正确率,由于初始数据样本较小,准确率不稳定,待多次训练后准确率逐步趋于稳定。最终通过使用model.save()函数,即可保存训练稳定后的网络结构模型与相关参数,且所保存的文件占内存很小。
4 商品图像识别和结算
系统基于商品图像识别训练模型展开学习训练后,得到学习的最终结果。而后利用商品图像实时识别模块对摆放在底座的商品的多个场景(如完整商品、80%挤压变形商品、60%挤压变形商品)进行图像识别。测试发现,图像的识别率提升明显,识别速度显著提高。对于商品外包装完整的商品,识别率在100%;挤压变形率80%的商品,识别率在90%以上,其价格显示以及总价累计均正确;对于变形率低于80%的商品,则会提示重新扫描,出现无法计价情况。综合测试,该系统的识别结果不会影响商品的正确结算,系统达到预期要求。
5 结论
基于CNN的商品图像识别系统的应用前景非常广阔,但由于实际使用环境不同,导致商品识别的效果和性能受到不同程度的影响,进而采用的系统优化设计方案也会有差异。这种差异性设计限制了系统的产品化发展,在一定程度上影响了商业推广应用。尽管商品图像自动识别系统利用CNN技术提高了应用效果,但还有很多实际问题需要解决,诸如识别性能和模型结构的优化,尤其是当前云计算技术的发展,给卷积计算提供了另一种提高计算效率的途径,给CNN的发展提供了新的挑战和机遇。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
舰船科学技术(2022年11期)2022-07-15
国际商业技术(2022年4期)2022-04-21
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
数码世界(2019年6期)2019-09-09
