
基于经验模态分解的多模型融合售电量预测模型
2021-07-25 05:12张强欧渊沈晓东唐冬来
科技创新导报 2021年6期
张强 欧渊 沈晓东 唐冬来


摘 要:售电量预测的精度是影响售电公司利润的一个重要因素。传统售电量预测方法难以解决售电量数据序列的趋势性、周期性与随机性等问题。为此,本文提出一种多模型融合的售电量预测方法。首先,采用基于经验模态分解方法将日和月度售电量分解为高、中、低频分量,构建三种独立的基模型,分别对不同频分量进行预测;然后,基于历史数据和同期的外部因素,包括时间和天气条件等数据,独立训练基模型,再将各基模型的输出进行融合获得售电量预测数据。本文采用均方根误差和平均绝对百分误差作为评价标准。实验结果表明,本文所提融合模型对比传统单模型有更高的预测精度,且相比现有预测算法,融合模型预测更加准确和稳定。
关键词:经验模态分解 多模型融合 售电量预测 深度学习
中图分类号:TU 47 文献标识码:A 文章编号:1674-098X(2021)02(c)-0037-06
A Model Fusion Electricity Sales Forecasting Model Based on Empirical Modal Decomposition
ZHANG Qiang1 OU Yuan1 SHEN Xiaodong2* TANG Donglai1
(1.Aostar Information Technologies Co., Ltd., Chengdu, Sichuan Province, 610041 China; 2.College of Electrical Engineering, Sichuan University, Chengdu, Sichuan Province, 610065 China)
Abstract:The precision of electricity sales forecast is an important factor affecting the profit of electricity sales companies. It is difficult to solve the trend, periodicity and randomness of data series of electricity sold by traditional forecasting methods. Therefore, this paper proposes a multi-model fusion method for electricity sales prediction. Firstly, daily and monthly electricity sold were decomposed into high, medium and low frequency components by empirical modal decomposition method. Three independent base models were constructed to predict different frequency components respectively. Then, based on the historical data and external factors of the same period, including time and weather conditions, the independent training base model was used, and then the output of each base model was fused to obtain the forecast data of electricity sales. In this paper, root mean square error and mean absolute percentage error are used as evaluation criteria. Experimental results show that the proposed fusion model has higher prediction accuracy than the traditional single model, and the fusion model is more accurate and stable than the existing prediction algorithms.
Key Words: Empirical modal decomposition; Multi model fusion; Electricity consumption forecast; Deep learning
随着新一轮电改的逐步深入,电力交易市场进一步放开,售电市场逐步放开,产生了很多售电公司,但由于目前国内尚未建立成熟的电力现货市场机制,偏差电量考核成为了影响售电公司利润的一个重要因素[1]。目前,降低偏差电量的方法多采用精确感知用户行为、可控负荷调整[2]和基于市场交易的方式。但是,可控负荷的调整和基于市场交易的方式,可操作性差,主要还是停留在概念层面, 且能调整的幅度较小。在电力市场背景下,更加精确的用户行为感知,将会最小化购售电偏差,降低由于偏差考核较大所带来的惩罚费用,提高自身收益[3-4]。
传统的用户行为感知研究主要着眼于负荷预测。节点负荷与运行状况紧密相关,直接受到气候条件等外部因素的影响,故当前的负荷预测主要通过分析外部因素及节点的历史负荷数据以实施预测。按照其所采用的预测算法,可以分为两类:基于统计的方法和人工智能方法。基于统计分析的方法,主要采用多元回归分析、自回归和滑动平均模型(ARMA)等技术进行。基于人工智能技术的算法,包括传统的机器学习方法,即通过特征工程构造并提取相应的特征,并通过支持向量机等机器学习模型进行负荷预测;以及深度学习算法,即基于LSTM、GRU等神经网络架构进行特征的自主學习并实施预测。上述提到的应用于负荷预测的方法基本都是单一模型,文献[5-6]提出使用模型组合的方式来提高预测精度并增强模型泛化能力,融合的方法主要是采用简单的均值计算。然而各个模型对预测结果的作用是不同的,采用取平均的方法不能体现出这一点。
上述方法可用于日前或月前预测,但无法满足售电市场中年度双边协商交易和月度集中竞价交易对不同时间维度的预测需要。本文提出一种多模型融合的售电量预测方法。采用基于经验模态分解方法将日和月度售电量分解为高、中、低频分量,构建三种独立的基模型,分别对不同频分量进行预测。基于历史数据和同期的外部因素,包括时间和天气条件等数据,独立训练基模型,再将各基模型的输出进行融合获得售电量预测数据。
1 基于经验模态分解的日和月度售电量分解
日和月售电量受温度变化、环境变化、节假日、季节变化、产业发展以及经济结构变化等外部环境因素的影响,呈现出明显的趋势性、周期性与随机性。针对这三种特性采取不同的预估方法能减少各分量之间的相互影响。因此本文经验模态分解法(empirical mode decomposition, EMD )对日和月用电量序列进行分解,针对各分量不同特征进行处理。
经验模态分解能够有效地分解非平稳、非线性的时间序列,与传统分解方法相比的优点在于:在分解序列之前不必预先设置基函数,在实际的分解过程中对任何类型的非平稳、非线性信号都能够得到较好的分解结果,并且具有很高的信噪比。EMD算法认为信号由不同的IMF分量组合而成,并且这些分量同时具备线性和非线性特点。EMD分解的步骤如下。
(1)求出原始信号的极大值和极小值,而后按照找到的极大值和极小值得到上下的包络线和。
(2)计算均值m(t)和差值d(t):
(1)
(2)
(3)如果d(t)满足IMF上述所必需的两个条件,则将其作为第一个IMF分量,记做c1,如果不符合条件重新执行前两个步骤,直到符合IMF分量的必要条件。将第一个IMF分量c1从信号中分离出来,可以得到残余序列r1。
(3)
(4)将残余序列r1重新进行步驟1和步骤2,当rn单调或者小于预先设置的的常数值时,结束分解,此时的原始信号会被分解成n-1个IMF分量ci并得到最终的残余分量rn,并且这些IMF分量包含了原始信号中的局部特征信息。EMD分解的完整过程可以由式(4)表示。
(4)
2 各融合模型
2.1 基于注意力机制的长短时记忆网络模型
LSTM网络是一种改进的时间循环神经网络(RNN),用于处理时序信号。LSTM基本单元主要由输入门、输出门、遗忘门组成。在基本单元处理信息的过程中,最重要的是单元状态的传递,即图1中上方从ct-1到ct的水平线,它将信息从上一个单元传递到下一个单元。
LSTM单元根据t-1时刻记忆单元状态值ct-1、隐藏层t-1时刻输出值ht-1和t时刻输入值,计算t时刻隐藏层输出值ht。
Attention Model是一种模拟人脑注意力的机制模型,其目的是使神经网络有选择地关注输入特征,并将学习到的特征权重保存赋值给下一个时间步长的输入向量,利用权值矩阵分配注意力,从而突出关键输入特征对负荷预测的影响。
本文采用的注意力机制模型的第二层LSTM节点的输出值表示Attention结构的输入特征序列,也作为Attention第一层隐藏层中的状态值;表示当序列点经过注意力系数加权后的向量,是Attention最后一层隐藏层中所保存的向量,也是Attention层的输出。
2.2 随机森林模型
随机森林是Beriman在2001年提出的一种基于Bagging算法的机器学习集成算法。随机森林算法步骤如下:
(1)假设有无功负荷原始数据集A,则有放回的从A中随机采样生成n个训练集;
(2)利用每个训练集ai组成其对应的决策树,在决策树的每个节点有M个特征,随机从这M个特征中选取出m(mM)2)个特征作为当前节点的分裂特征集,在每个节点上根据Gini系数选取最优特征对该节点进行分裂;
(3)决策树形成的过程中每个节点都要按照步骤2来分裂,假设重复以上步骤k次,构造k棵最优决策树组成随机森林;
(4)使用随机森林进行决策,假设y代表输出的负荷预测值,ti表示单棵决策树,R为随机森林模型,则决策公式为:
(5)
汇总每个决策树对数据集的预测结果,得票数最多的预测值为最后的预测结果。随机森林的随机性体现在每颗数的训练样本是随机的,树中每个节点的分类属性也是随机选择的。有了这两个随机的保证,随机森林就不会产生过拟合的现象了,并且实现简单,计算资源开销小。
2.3 XGBoost模型
XGBoos是一种广泛使用的集成学习算法,是对传统的Boosting算法的改进。传统思路是结合多个弱学习器,每个弱学习器是一个CART回归树,然后对其输出线性求和从而优化模型。XGBoost模型表示如下所示:
(6)
式中,为第i个样本的预测值;K为树的数目,L为树的集合空间;表示第i个数据点的特征向量;对应第k棵树独立的树的结构q和叶子节点权重w的相关状况。
3 基于经验模态分解的多模型融合模型
具体的建模步骤如下:
(1)运用EMD分解算法得到多个不同的子序列。
(2)依据将序列分为高、中、低频三类。
(3)分别使用基于注意力机制的长短时记忆网络模型、随机森林和XGBoost对高、中、低频序列进行预测,分别得到各个子序列的预测结果。
(4)叠加并重构各个子序列的预测结果,得到实际的预测结果。
4 算例分析
本文实验设备为Windows10 64位操作系统,处理器为Intel(R) Core(TM)i5-8400 CPU @ 2.80GHz,内存为8GB,硬盘4T,GPU显卡GTX1080Ti11G。软件架构采用基于TensorFlow框架的Keras深度学习工具进行开发。Keras支持现代人工智能领域的主流算法,包括前馈结构和递归结构的神经网络,也可以通过封装参与构建统计学习模型。
4.1 数据准备
本文实验使用某省电力市场2018年交易数据作为基础样本,参考广东电力市场月度偏差电量考核方式。
时间规则包括三个方面:首先,工业用电是当今电力系统的主要负荷,由于政策因素,法定节假日的工业用电与其他时间极为不同,对售电量预测结果会产生一定的影响。本文中对于节假日和非节假日,分别用1和2表示;其次,以周为单位时段,工业、商用和民用用电均在一定程度上表现出周期性。本文使用0、1表示周六、周日,2~6表示周一到周五。最后,受用电习惯影响,一天之中白天的负荷远高于夜间。本文将单日分为22:00~6:59和7:00~21:59,分别用1和2表示。以上三个尺度的信息构成了售电量的时间特征。
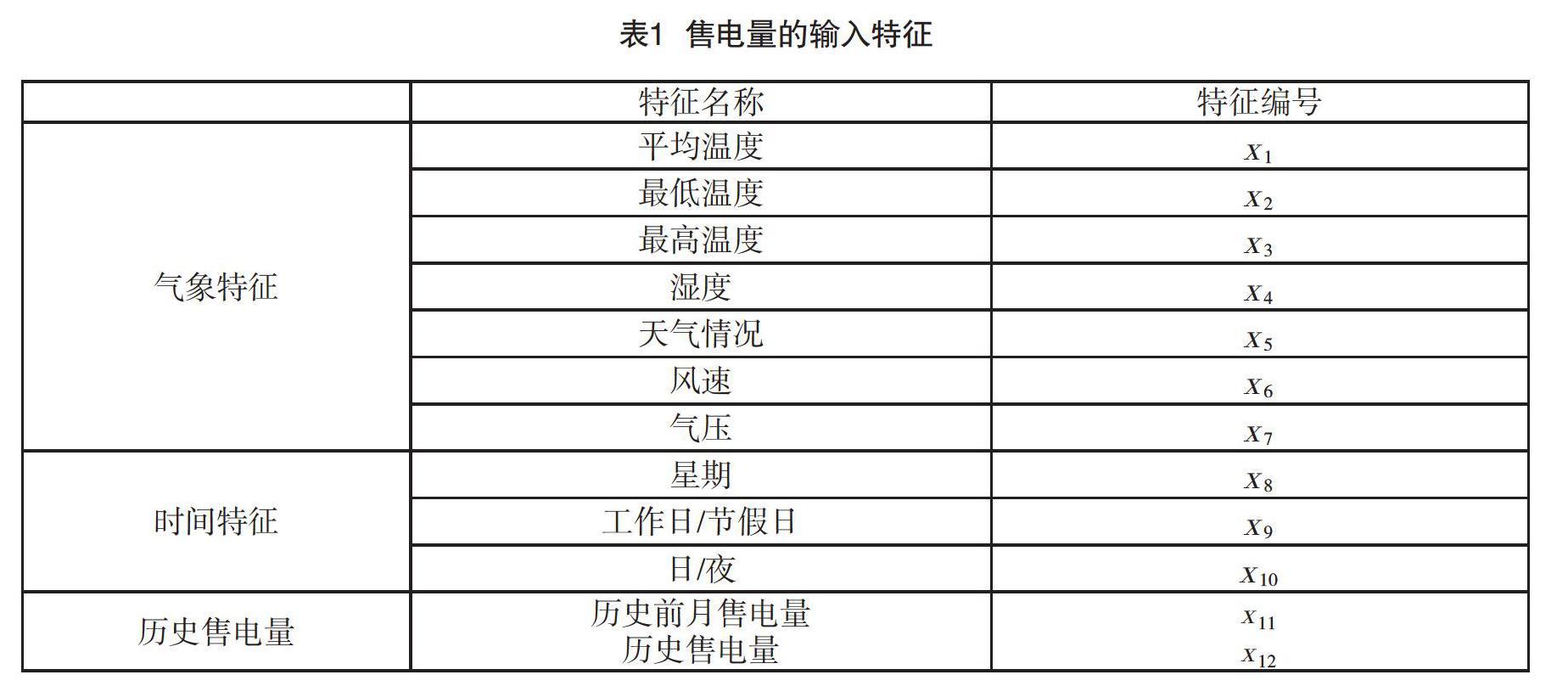
天气信息也是影响预测精度的关键外部因素,包括温度条件和气象条件两类:温度条件包括平均温度、最高温度和最低温度。气象条件包括湿度、风速、气压和天气类型。本文中所采用的天气数据均来源于中国气象网。
本文使用的输入数据包含的特征如表1所示。在訓练模型时候我们用向量来表示t时刻的数据点,其中包含了表1中所述的12个特征,然后用一个输入序列来预测相应的售电量输出序列,yt表示t时刻未来时刻的售电量。
4.2 数据预处理
本文采用min-max数据标准化将原始数据进行归一化处理,缩小其动态范围,如式(7)所示。
(7)
式中,q*为标准化后的售电量;,分别为数据中的最大值和最小值。
4.3 误差指标
本文采用平均相对误差(mean absolute percentage error, MAPE)和均方根误差(root mean squard error, RMSE)用以评判模型预测的准确性,计算公式为:
(8)
(9)
式中:为预测值;yt为实际值;N为总的样本个数。
4.4 EMD分解
通过对原始的售电量时间序列进行经验模态分解,逐步分离出了11组IMF分量与1组残余分量,分解结果如图1所示。
从图1的分解结果中可以看出,对于不同频率的IMF分量,频率较低的序列平稳性大大提高,波动性较低。对于高频的IMF分量,其随机性和波动性十分明显,无明显规律可言。针对每个分量序列,可以通过大小将其大致分为高、中、低频三类。
4.5 验证融合模型的预测性能
为验证本文所提出融合模型在进行短期售电量预测的性能,本节以2018年的数据作为训练集。
图2为训练好的3个基模型和融合模型在测试集上的预测曲线图。可观察到,随机森林RF的预测曲线比真实值偏高,XGBoost的预测曲线比偏低,Attention-LSTM的曲线拟合的程度最好。
本文选择支持向量机回归SVR模型[7]和人工神经ANN网络模型[8]与本文的融合模型进行横向对比,SVR和ANN模型结构与参考文献中相同。如图3和图4所示为三个模型在测试集上的MAPE和RMSE对比。可以看到融合模型的RMSE和MAPE值都是最优。
4.6 验证融合模型的稳定性
模型在不同时间长度上的预测情况可以反映其稳定性的强弱。因此为了验证本文所提融合模型的稳定性,选取数据集中12月份的第一天以及当月分别建立天测试集和月测试集,使用本文方法进行预测。实验结果如表2所示,可以看到在两个测试集上本文所提的融合模型的RMSE和MAPE都最优,表明本文方法进行预测的预测精度和稳定性都更强。
5 结语
售电量预测的精度是影响售电公司收益的主导因素。本文提出一种多模型融合的售电量预测方法。采用基于经验模态分解方法将日和月度售电量分解为高、中、低频分量,构建三种独立的基模型,分别对不同频分量进行预测。基于历史数据和同期的外部因素,包括时间和天气条件等数据,独立训练基模型,再将各基模型的输出进行融合获得售电量预测数据。实验结果表明,本文提出的融合模型相比各基模型的预测精度有较大提升,且稳定性高。另外相比ANN和SVR售电量预测算法,本文方法预测的结果更优。
参考文献
[1] 赵博石,严宇,刘永辉,等.基于区域发电成本核准的跨区跨省电力交易偏差电量定价方法[J].电网技术,2016,40(11):3334-33418.
[2] Abdulaal A, Moghaddass R, Asfour S. Two-stage discrete-continuous multi-objective load optimization: An industrial consumer utility approach to demand response[J]. Applied Energy, 2017, 206(15):206-221.
[3] 白登辉.计及偏差电量考核机制的人工神经网络售电量预测模型[J].电工电能新技术,2020,39(6):58-66.
[4] 喻小宝,谭忠富,马佳乐,等.计及需求响应的售电 公司正偏差电量考核优化模[J].电力系统自动化,2019,43(7):120-128.
[5] 刘文霞,龙日尚,徐晓波,等.考虑数据新鲜度和交叉熵的电动汽车短期充电负荷预测模型[J].电力系统自动化,2016,40(12):45-52.
[6] LI ZHIYI,LIU XUAN,CHEN LIYUAN.Load interval forecasting methods based on an ensemble of Extreme Learning Machines[C]//Proceedings of 2015 IEEE Power & Energy Society General Meeting.Denver,CO,USA: IEEE,2015:1-5.
[7] A BRACALE, G CARPINELLI, P De FALCO, T HONG. Short-term industrial reactive power forecasting. International Journal of Electrical Power & Energy Systems, vol. 107, pp. 177-185, May, 2019.
[8] J N FIDALGO, and J. A. P. LOPES. Load forecasting performance enhancement when facing anomalous events. IEEE Transactions on Power Systems, vol. 20, no. 1, pp. 408-415, Feb, 2005.
猜你喜欢
现代电子技术(2017年3期)2017-03-04
现代电子技术(2017年3期)2017-03-04
现代电子技术(2016年23期)2017-01-12
江苏教育·中学教学版(2016年11期)2016-12-21
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
