
改进YOLOv3的工业指针式仪表检测方法
2021-07-21 03:46:44刘家乐吴怀宇陈志环
计算机工程与设计 2021年7期
刘家乐,吴怀宇,+,陈志环
(1.武汉科技大学 机器人与智能系统研究院,湖北 武汉 430081;2.武汉科技大学 信息科学与工程学院,湖北 武汉 430081)
0 引 言
指针式仪表制造成本低,结构简单易维护,广泛用于大规模工业上的生产监测。矿厂、变电站、化工企业的指针式仪表数量众多且不固定、多分布在高温、高压场所,这种精密器件都需要按时校准来维持自身精确度。传统的检测方法是通过人工完成,而个人可能因主观干扰和危险环境而导致误检造成巨大经济损失。到目前为止,国内外学者对仪表自动检测方法已有大量的研究,此外,指针式仪表目标多为室外高处的小目标,提高小目标的检测效果是目前一大挑战。
以往的目标检测采用的大多是Hough变换等进行监测,而其对噪声太敏感、泛化能力弱、复杂度较高,容易漏检或多检导致误差。随着深度学习的发展,已经有许多学者利用其解决目标检测识别方面类似的问题,且已经取得不错的成效。目前,基于深度学习的目标检测方法已经取得的突破大致可分为两类。一种是基于区域推荐的Two Stage算法,如:Fast RCNN[1]、Faster RCNN[2],它们通常具有高精度,但通常实时性不足。另一种是基于回归方法的One Stage算法,如YOLO[3]、SSD[4]、YOLOv3[5],其将检测问题作为回归问题来解决并直接预测目标位置和类别,这些方法通常速度快但准确度低。
Laroca R等[6]利用卷积神经网络对仪表图像进行分析,但精确度不够;He P等[7]使用Mask RCNN来分割自然场景仪表盘,但实时性不高;Wang L等[8]使用YOLOv2对仪表进行定位,但对小目标的检测效果有待提升。计算机内置的内存单元与计算单元有限,尽管目前利用深度学习实现指针式仪表检测算法越来越多,但这些方法网络规模大,实时性和准确性仍有待提高,难以在算力有限的计算机上完成对指针式仪表的实时高效检测,因此不能满足工业上的实际工作[9]需要。
针对以上问题,本文首先对工业上的指针式仪表的数据集进行采集与制作,然后对YOLOv3算法的系统模型框架结构、损失函数、先验框聚类[10]进行设计与改进,通过常用的评估指标来对不同算法与改进版YOLOv3进行对比实验。最后对实验结果进行分析,结果表明改进的YOLOv3算法,针对工业中的半盘、整盘式指针式仪表检测有较高的精度与速度,对小目标检测效果大幅提升,能够满足工业上指针式仪表检测的实际需要。
1 YOLOv3算法
YOLOv3借鉴了图像金字塔FPN(feature pyramid networks)的思想,在3种不同的规模的特征图下进行预测,大尺寸特征图用来检测小目标,小尺寸特征图用来检测大目标,而中间特征层则适合检测中等目标。通过聚类选取先验框,对不同大小目标的检测识别都能很好兼顾。图1为YOLOv3的自上而下检测的FPN结构图。
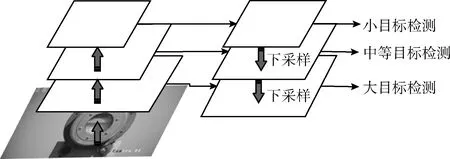
图1 YOLOv3的图像金字塔结构
框架上,YOLOv3参考SSD和ResNet网络结构,设计了分类网络基础模型DarkNet-53,相较于YOLOv2的DarkNet-19,DarkNet-53扩充为更大的网络,共使用52层卷积层,且每个卷积层后都有归一化操作(batch normalization)来防止过拟合;考虑到网络复杂度与检测准确率,所以与常用的特征提取网络VGG-16相比,DarkNet-53降低了模型运算量,同时为了避免网络层数的加深模型在训练过程中产生梯度爆炸的现象,使用了残差学习的思想,在网络中添加了大量的残差块。
YOLOv3使用多标签分类,这与先前版本中使用的互斥标签不同,它使用逻辑分类器来计算特定标签对象的可能性。所以对于分类损失,其模型摒弃了Softmax函数作为最终分类器,它使用每个标签的二进制交叉熵损失,即常用的Logistic损失函数来作分类损失的损失函数,而非YOLOv2中使用的一般均方误差。表1为检测网络性能比较对比表,其中mAP为平均类别精度,FPS为帧率。

表1 检测网络性能比较对比
由表1可以看出,YOLOv3各指标在检测算法中表现较为均衡,且在精确度和速度性能上均取得了良好的效果。
2 改进的YOLOv3算法
尽管YOLOv3在目标检测领域已经取得不错的效果,但是对于本文工业上的指针式仪表数据集上来说,其对小目标的检测效果不太理想,且检测速度仍难以应对庞大数据量的检测任务,故需要对YOLOv3算法做适当改进,以更好适应实际工业应用中的指针式仪表的检测任务。
为了应对工业上的指针式仪表检测问题,本文主要对YOLOv3算法做如下3个改进。
(1)改进Kmeans聚类。使用最新的Mini Batch Kmeans来加速聚类时间,来应对大量数据集的锚框Anchors选择,主要作用是更快寻找到更合适的预测矩形框来检测仪表图像;
(2)改进YOLOv3框架。使用轻量级框架MobileNet加速YOLOv3的训练时间,保证精确度的同时大幅度提高实时性;
(3)设计更合理损失函数。使用设计好的损失函数进行训练,减小损失率,提升系统对小目标仪表盘的检测效果。图2为改进YOLOv3的检测流程。

图2 改进版YOLOv3检测结构
2.1 Mini Batch Kmeans聚类anchor选取
SSD与Faster RCNN中边界框尺寸都是通过主观选择的,这种方式会因数据集大小类别不同而产生较大误差,故YOLOv3采用Kmeans聚类来自动选取边界框的尺寸与数量,图3为Kmeans聚类例图,聚类中心用X表示,横纵坐标分别为样本的序号和特征的分布情况。
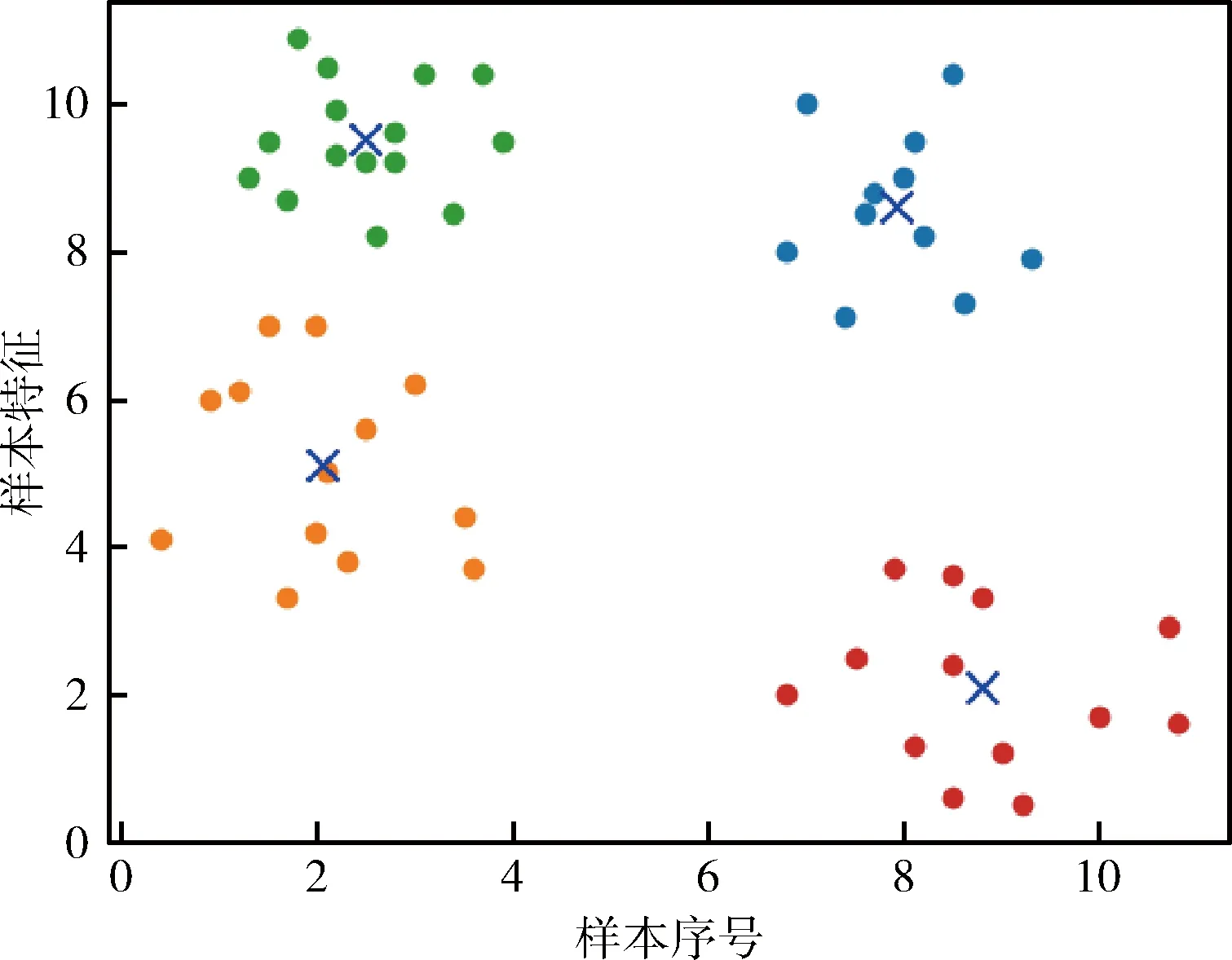
图3 Kmeans聚类
如图3所示,传统的Kmeans流程都是随机初始化K个聚类中心,然后将样本点分配到最近的中心,分开成K个类别,再更新中心点,如此循环直到K个中心点不再变化或达到迭代阈值。因为随机初始化K个聚类中心会导致聚类结果准确度不稳定,所以使用Kmeans++初始化可以弥补Kmeans在初始化中心点的选择上的不足,只预先选取一个中心点,再计算每个点到与其最近的中心点的距离的概率,随机选择一个点作为中心点加入集合中,重复步骤直到选定K个中心点。随着数据集的大小进入万级百万级,日常目标检测所需要的精度越来越高,传统聚类耗时费资源且效果有限,而在聚类环节耗费的时间可以用更加效率的Mini Batch弥补。具体步骤为:
(1)随机拆分训练集为n份,首先抽取第一份训练集,使用Kmeans++初始化构建出K个聚簇点的模型;
(2)继续抽取训练集中的下一份样本的数据,并将其添加到模型中,且分配给距离最近的聚簇中心;
(3)更新聚簇的中心点坐标(每次更新都只用抽取出来的部分数据集)。
Mini Batch Kmeans模型能在保持聚类准确性情况下大幅度降低计算时间。它采用分小批量的方法划分数据子集,以此减少计算时间,同时仍试图优化目标函数,采用这些随机选取的数据进行训练,极大减少了计算与Kmeans算法收敛的时间,这适用于当数据量与类别数非常大时做聚类,选用通过Kmeans++初始化之后的Mini Batch Kmeans算法能在提升精度的情况下加速聚类时间。
2.2 框架选择
随着卷积神经网络的层数加深,实际工程中所消耗的计算资源越来越大,大量的参数导致网络训练与检测速度缓慢,为了解决这个问题,最好办法就是对模型进行压缩,在不损失网络性能情况下提高运行速度与检测速度,因此,本文选用轻量级网络MobileNet代替YOLOv3中使用的Darknet-53网络。
MobileNet的主要优点是深度可分离卷积 (depthwise separable convolution),它将常用的标准卷积神经网络进行分解,变成深度卷积和1×1的逐点卷积,首先用深度卷积针对每个单输入进行单滤波器滤波,后用逐点卷积的方式结合深度卷积的输出,这种分解方式能大幅减少计算量,减小模型的大小。MobileNet在计算量,权重内存和精确度方面找到了非常合适的平衡点。表2为相同输入分辨率数据集情况下,YOLOv3框架MobileNet与DarkeNet-53间在ImageNet数据集上的性能比较。
由表2可以看出,在相同条件下,YOLOv3使用MobileNet框架在参数数量上较DarkNet-53框架减小3倍;浮点数运算量上MobileNet仅需150亿次,将运算量较DarkNet-53减小了4倍以上。从计算量和参数量来说MobileNet具有绝对优势,能有效加快训练速度,缩短训练时间。

表2 YOLOv3各框架之间的性能比较
图4所示是改进后的MobileNet的框架图,共有27层卷积层,每个卷积层后都接有Batch Norm归一化和激活函数,抽出其中的第9层、14层、24层的特征图出来进行后续训练检测操作。这里选用ELU代替原来的Relu激活函数,函数在左侧的负值赋予非零的斜率,不仅能避免或缓解梯度消失和梯度爆炸,而且能极大程度加速训练过程,使收敛速度加快,对仪表图像的噪声有更佳的鲁棒性。
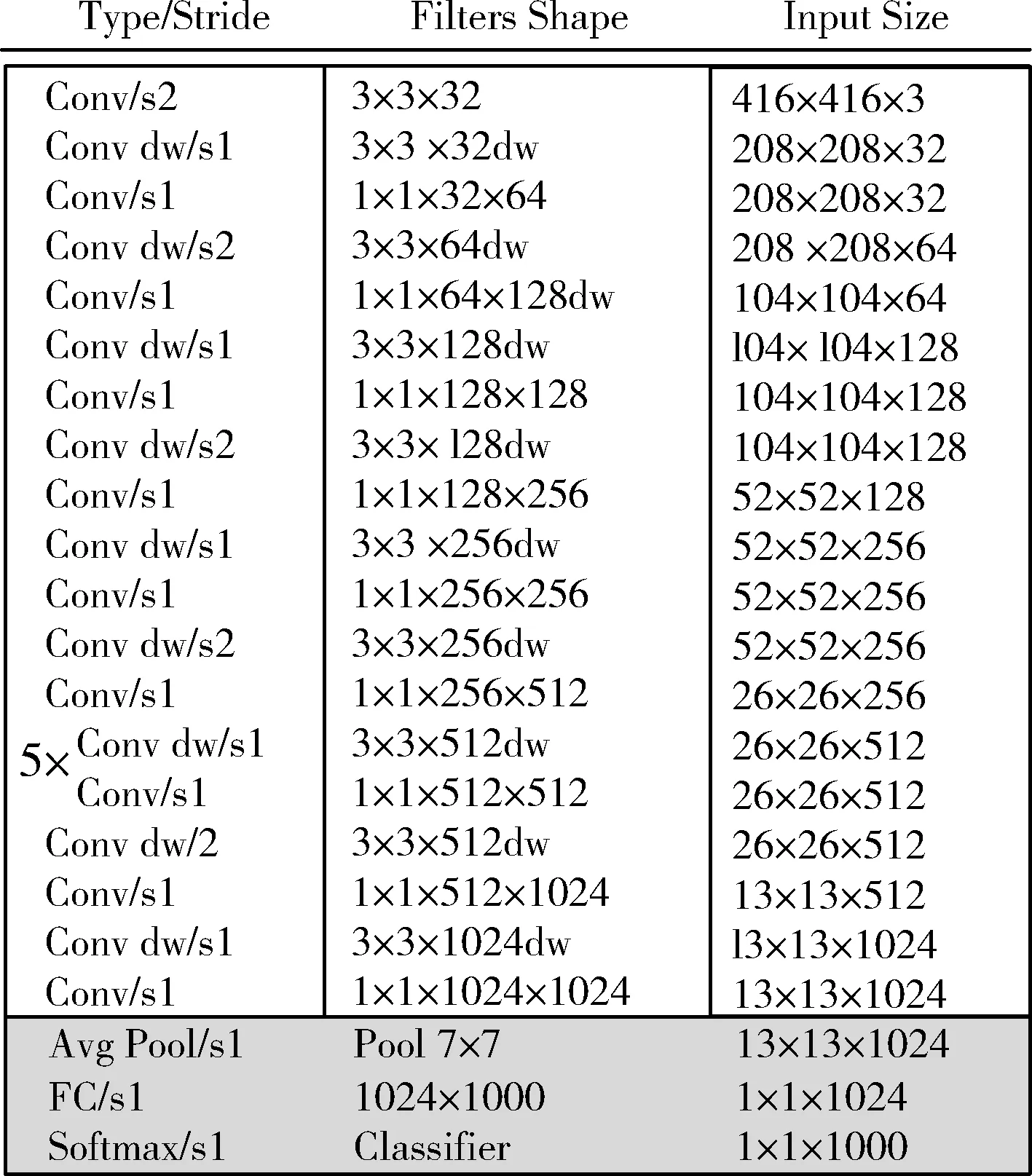
图4 MobileNet框架
2.3 损失函数的设计
损失函数作为衡量预测值与真实值之间的误差的指标,对于网络模型检测效果的好坏起着至关重要作用,一般来说,损失函数下降速率越快,损失值越小,系统模型越好。对于YOLOv3来说,损失函数共分为:f1边界框的预测(bounding box prediction)、f2置信度计算(confidence prediction)、f3类别预测(class prediction)这3个部分,其总损失为
Loss=f1+f2+f3
(1)
其中,各部分损失为
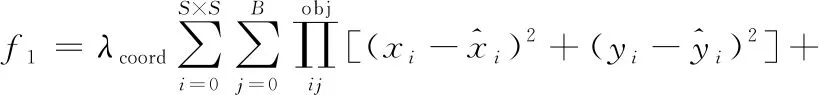
(2)
上述公式中各参数信息详见文献[5]所示。对于式(2)中边界框的预测f1采用的是真实值坐标与预测值坐标误差的平方;而置信度计算f2与类别预测f3均采用的是交叉熵损失函数。对于边界框的坐标预测来说,自由场景下采集到的图像可能尺寸大小不一,使YOLOv3检测小目标的效果会受到影响,因此,本文对于坐标误差的宽高部分损失函数的改进:采用了预测值和真实值的平方和作为损失。这是由于较大目标的误差相对较小目标的误差对最终的损失值影响更小,若损失函数不变,则损失函数难以下降,对小目标检测结果较差。根据本文模型的指针式仪表,为了更好拟合数据,设计边界框预测损失函数如式(3)所示
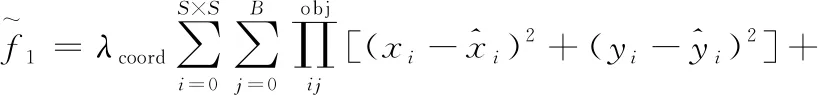
(3)
最后本文在坐标误差后加入激活函数tanh来减小预测框过大而产生的误差,使预测框更加精确的检测出仪表圆盘。最终总损失函数如式(4)所示
(4)
2.4 模型评价指标
根据以上问题,本文选择精确率均值AP(average precision),每秒检测帧数FPS(frames per second)、平均IOU(交并比)作为模型评价指标,其中AP和FPS为检测环节精度效率的评价指标,平均IOU为评价边界框聚类准度指标
(5)
式中:TP(true positive)指的是正样本,FP(false positive)指的是被判定为正样本,但实际上是负样本的样本数,其中TP与FP相加结果为总样本数M,AP是针对单一类别预测,目前为止使用频率最高,效果最优的评价标准和度量指标之一
(6)
帧率FPS(frames per second),即是每秒钟内最大可以处理的图片数量。式(6)中S为测试总时间,一般以秒为单位,F为该S秒单位时间内系统检测的图片数量。一般显卡的内存越大,一次性处理的图片数量越大,则处理一张图片所需要消耗的检测时间越短,速度越快
(7)
平均IOU是评价真实框Ground Truth与预测边框差异性的指标,其中P为预测框大小、G为真实框大小。其式(7)可以理解为神经网络计算出的框与标记框的重合程度,即是检测结果与真实框的交集比上其并集。IOU的值越高,预测边界框的位置越准。
根据以上3点改进,下面将进行实验。
3 实验过程及结果分析
本文将根据实验的软硬件开发环境,对工业上指针式仪表数据集进行制作,包括变电站、化工厂等场景实地拍摄,并对训练集进行聚类,得到合适的先验框输入网络进行训练,通过不同算法的对比实验,得出结论。
3.1 软硬件开发环境
实验环境配置如下:AMD Ryzen 5 2600 Six-Core Processor 处理器,NVIDIA GeForce GTX 1060 5 GB独立显卡,CUDA版本为9.0,Python版本为3.6,基于Tensorflow/Keras框架,操作系统为Windows 10,网络具体参数配置见表3。
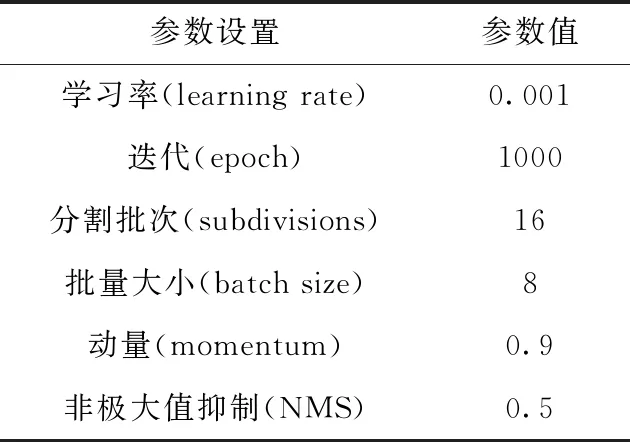
表3 网络参数配置说明
3.2 数据集制作
针对本文的研究环境范围主要是工业应用,如变电站、化工厂等,而指针式仪表一般在比较隐蔽的高处,像电线杆上和相关管道处,且表盘多因环境原因模糊不清,因此,数据集的搜集非常不便。本文利用python网络爬虫技术从网络爬取指针式仪表的数据集400张,实地拍摄仪表盘图像照片300余张,用数据增强(data augmentation)手段扩充数据集至1000张图片,输入到神经网络进行训练。样本划分具体是:训练集、交叉验证集、测试集之间的比例为6∶2∶2。
图5是标定数据集中真实框的分布,横纵坐标分别为各先验框坐标的分布情况。

图5 真实框Ground Truth分布
3.3 改进YOLOv3训练实验
3.3.1 Mini Batch Kmeans聚类结果
图6为Mini Batch Kmeans算法的聚类结果图,横纵坐标分别为先验框选取的个数和平均IOU的大小。
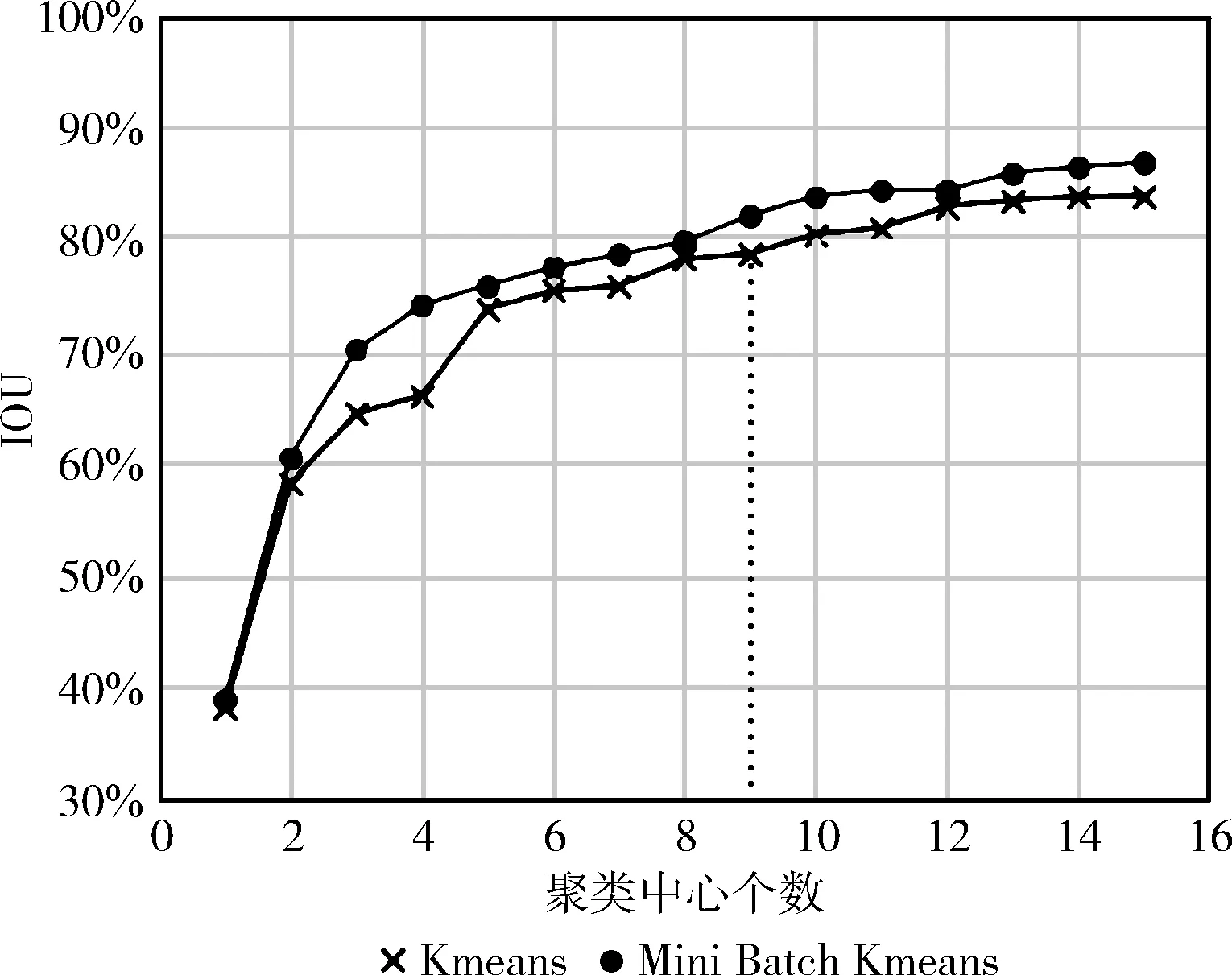
图6 Mini Batch Kmeans聚类结果
图6中Mini Batch Kmeans算法平均IOU值明显大于Kmeans,且聚类损耗时间短;鉴于增加候选框数量会影响系统模型的检测速度,本文最终选择9个聚类中心。经过测验得到此时的精确度为81.97%,相对于普通的Kmeans算法提高了4.1%。这种对时间优化的思路还广泛应用于梯度下降、深度网络等。
3.3.2 网络训练及其测试
为更好检测大中小目标,在YOLOv3的网络中,将图片共分为3个不同尺寸的特征图。每个特征图设置有3个锚框Anchor boxes,因此会获得9个Anchor boxes来进行预测。根据预测的边界框和实际边界框之间的IOU进行非极大抑制。根据反复实验,减小学习率和增大迭代次数并不能有效减小损失值,故本次实验迭代次数定为1000次。图7为改进版YOLOv3与原版的损失函数对比曲线图。

图7 训练损失函数对比
图7中输入图像分辨率为416×416,虚线为YOLOv3损失曲线,实线为改进版YOLOv3曲线。培训结束后,整合培训过程中的数据,由原版loss曲线可看出曲线前期震荡较大,至900次迭代后趋于稳定不再变化;由改进版loss曲线图可知在400次迭代epoch之前损失急速下降,随着学习率的不断减小,损失持续小范围下降,后期迭代loss基本不再变化;最终改进版YOLOv3损失值降为2.8,较原版损失率降低30%。
3.3.3 不同图像分辨率的性能比较
根据多尺度训练方式,YOLOv3在不同的图像分辨率下都有很好的检测效果,鲁棒性较好。为了验证YOLOv3和改进YOLOv3的在不同图像分辨率下的检测效果,本文选出低、中、高{320,416,608}这3种不同分辨率下的图像进行算法检测性能评估。由图8可以看出改进版的YOLOv3在不同分辨率大小上的检测效果情况,左柱状图为YOLOv3效果图,右柱状图为改进版本YOLOv3效果图。
由图8可知,在不同分辨率输入下改进版本YOLOv3均比原版YOLOv3的检测效果好。由此可得本文所提改进算法能够适应不同分辨率大小的图像,且精确度较原版有一定幅度提高。

图8 两种算法的图像分辨率敏感性分析
3.4 指针式仪表对比实验
为体现各不同检测算法在指针式仪表数据集上的检测效果,本文选取中分辨率的情况下,对原版YOLOv3与改进版本的YOLOv3以及SSD、Mask RCNN在本数据集上进行指标评估对比,得出实验结果指标对比表格。
通过表4可知YOLOv3的精确度(AP)为90.6%,精度方面比Mask RCNN低2%,比SSD高2%;实时性方面,YOLOv3帧率是Mask RCNN的20倍,较SSD提高16%,且小目标检出率达到81%;综合来看,YOLOv3综合性能最好,效果最优;而改进版YOLOv3在精度方面高于Mask RCNN,且在视频检测方面的帧率(FPS)上每秒处理24帧图像,较原版YOLOv3提升了66.7%,且小目标检出率提升了7.4%,每百张图的小目标检出为87张,体现出本模型优越的性能,因此综合来看,本文提出的改进版YOLOv3算法能够在工业上指针式仪表检测任务中,比原版算法更好,更符合工业环境下的检测需求。

表4 IOU阈值为0.5时各算法的评估结果对比
3.5 测试结果分析
本文选取以上4种算法进行实际的检测指针式仪表,以更直观感受各算法的优劣和效果,比较各算法使用的性能。
其中图9为近处的半盘式(即刻度区约占表盘一半)指针式仪表,图10为经过局部放大后的远处整盘式(即刻度区覆盖整个仪表表盘)指针式仪表图像;图(a)~图(d)分别为SSD、Mask RCNN、YOLOv3、改进YOLOv3的检测效果图像,图像上附有各算法识别概率大小和仪表预测框的定位情况。
由图9、图10可知,各算法都能准确预测,框出不同的指针式仪表表盘,但SSD准确率不高,对表盘的检测框偏差较大;Mask RCNN通过实例分割进行仪表盘预测较为精准,但失去了一些边界信息;原版YOLOv3对远处仪表盘的小目标检测准确率低;而改进版YOLOv3可以精确检测出近处的半盘式仪表,也能快速准确地检测小目标的整盘式仪表。通过实验结果可看出,本文提出的改进版YOLOv3的准确性、实时性和损失率基本已达到预期效果,并验证了这些思路和方法的可行性,能够为工业上的指针式仪表检测问题提供更优秀的方案。

图9 近处的半盘式指针式仪表(5 m)

图10 远处的整盘式指针式仪表(10 m 局部放大)
4 结束语
本文提出一种基于改进YOLOv3的工业指针式仪表检测识别方法。本算法通过Mini Batch Kmeans聚类算法对数据集聚类找出更合适样本的先验框,并设计新损失函数与使用轻量级网络MobileNet模型框架来进行多尺度训练、预测。实验结果表明,改进的YOLOv3算法在保证较高准确率的同时能够有快速的检测速率,能够较好检测出半盘式、整盘式等不同的指针式仪表表盘,且训练耗时短,对小目标检测定位效果提升明显,该方法具有较好的鲁棒性和实用性,能够满足在算力有限的计算机上完成指针式仪表的自动检测任务,也将为未来的指针式仪表指针提取及读数工作提供思路。
猜你喜欢
建筑与预算(2023年2期)2023-03-10 13:13:36
青海草业(2022年2期)2022-07-23 09:23:12
建筑与预算(2022年5期)2022-06-09 00:55:10
江西教育·职教版(2022年9期)2022-04-29 00:44:03
建筑与预算(2022年2期)2022-03-08 08:40:56
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
今日农业(2019年15期)2019-01-03 12:11:33
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
黑龙江科学(2015年11期)2015-03-27 03:38:17
电测与仪表(2014年18期)2014-04-04 12:33:04
