
基于知识角色的信息学研究方法识别*
2021-07-20 07:18李鹏程程齐凯
情报杂志 2021年7期
李鹏程 程齐凯
(武汉大学信息管理学院 武汉 430072)
0 引 言
学术文本作为一种高信息密度的文档资源,是科研工作者实现知识生产、知识组织以及知识传播的重要载体。学术论文中包含大量的研究方法类实体,这些方法是文献作者在文中用以解决预设问题所提出或使用的技术、工具或手段[1],是科技文献中最为核心的知识单元。H.D.Ribaupierre等[2]认为科研人员信息获取行为往往以任务目标为导向,如通过查阅文献以寻求解决目标任务或问题的相关技术方法。然而,随着可获取数字图书资源的不断激增,了解和掌握一个学科领域中的方法知识已愈发困难。针对于此,本文的目标是在理解文本语义信息的基础上实现学术文本中研究方法的自动识别获取,为构建完备的领域方法知识库提供可行的技术路线。
研究方法在科学研究的推进乃至学科的建设发展中都扮演着至关重要的角色。经过数十载的持续发展,学者们从定性与定量、实证与非实证等角度对图书情报领域中研究方法的使用情况及框架体系进了探讨[3-4]。在本文中,图书情报学研究方法是指在图书情报学研究过程中为实现特定目标或效果所采用的某个确切方法类实体,包括且不限于模型、算法及工具等等。目前而言,研究方法实体的自动识别抽取总体可分为两种:基于规则模板的方法和基于统计学习的方法。前者依靠人工构建的规则、字典及模板,通过字符串匹配的方法从文本中获取方法词或方法句[5];后者则是采用有监督或无监督的学习方式完成所构建模型的训练拟合[6]。虽然基于规则模板的方法能够在特定语料上获得较优的识别效果,但由于存在泛化性差、局限性高及规则构造繁琐等问题,当前更多的是采用基于统计学习或统计学习与规则模板相结合的方法进行研究方法实体识别。
近年来,针对图书情报领域的方法识别研究已取得一定进展,通过NLP及深度学习技术的应用,现有识别模型能够在学习文本中词汇、句法及语义等特征信息的基础上对研究方法实体予以识别抽取[7]。然而,基于有监督学习的识别策略严重依赖于大规模高质量的标注数据集。图书情报学作为跨学科现象显著的一门科学,领域中的研究方法极其杂糅,抛开文献计量法、引文网络法及共词分析法等传统图书情报学方法之外,还借鉴、融入了大量来自其他领域的技术方法[8],使得大规模的数据标注极为不易。为克服现有方法实体识别研究中的数据获取难题,本文利用图书情报学的跨学科属性,依循图书情报学与计算机学之间的知识角色迁移规律,提出了一种基于跨学科知识角色迁移规律的研究方法识别路线,应用bootstrapping自学习策略构建了图书情报领域的方法实体字典,继而完成训练所需语料的自动标注。
1 相关研究概述

针对图书情报领域中的研究方法识别,国内学者也从多个层面进行了尝试探索。化柏林[5]依据图书情报领域中方法类术语的表述形式,采用规则的方法从学术文本中识别出方法句,在此基础上结合词表从方法句中抽取方法术语。赵洪等[18]通过研究科技文献中理论术语的特征,构建了一种基于弱监督学习的理论术语抽取模型,以解决现有方法识别研究中存在的语料匮乏问题。程齐凯等[19]在词法、句法及组块等多个特征的基础上,设计了一种基于条件随机场的学术文献问题方法识别模型。张颖怡等[6]分析比较了CNN(Convolutional Neural Networks)、LSTM(Long-Short Term Memory)及BERT(Bidirectional Encoder Representation from Transformers)等多种神经网络模型在方法句分类中的效果,发现基于BERT的双向LSTM模型能够较好识别文献中的方法句。章成志等[7]在前者的基础上进一步对所使用的深度学习方法进行了扩充,对比了8种神经网络在学术文本方法实体自动识别中的实验效果,并将识别粒度细化到词汇层面以实现方法实体词的自动获取。
从现有成果看,方法实体识别已得到图书情报领域学者们的重视并取得了一定进展。随着统计学习及相关配套技术的日益成熟,机器学习也逐步替代规则模板成为当前方法实体识别研究中的主流选择。基于机器学习的方法虽能在多种实体识别任务上取得较好的效果,但却极其依赖大规模、高质量的训练样本。跨学科属性使得图书情报领域中的方法来源多样、类型不一,已有的方法语料库[20]多采用人工标注的形式完成数据集构建,不仅成本高昂、文本主题单一,且数据体量有限。针对以上,本文依循图书情报领域的跨学科属性,提出了一种基于知识角色迁移规律的数据自动标注方法,通过大批量标注语料的自动获取,实现自建研究方法识别模型的训练拟合,进而更为鲁棒的识别图书情报学领域中的方法实体。
1.2知识角色迁移的显现机理知识迁移是迁移学习的重要理论基础[21],其思想是通过将源领域中学习到的知识应用到目标领域以辅助目标问题的求解。图书情报学作为一门交叉属性明显的学科,其在成长过程中不断积极吸收自然科学、技术科学和社会科学中的多源知识。近年来,随着计算机科学技术的不断发展与革新,计算机与图书情报学科之间的知识迁移现象更是愈发显著,大量的计算机算法、模型、工具及系统被应用于图书情报研究工作中。针对图书情报领域的知识迁移现象,张瑞[8]、冯志刚等[22]及王旻霞等[23]通过引文网络研究了图书情报学的知识流入特征,指出计算机学科是向图书情报学科输入知识最多的学科。邱均平等[24]从作者发文领域分布的视角分析了图书情报学科与计算机学科间的密切联系。王思茗等[25]采用网络分析与和弦图分析相结合的方法对图书情报领域中的学科交叉现象进了细致分析,认为图书情报科学与计算机科学处于高度交叉状态且已从研究对象层面交叉转向技术层面交叉。
总体而言,一个学科的交叉特性多能够在其研究方法上得以体现[26]。司莉等[27]以《中国图书馆学报》《情报学报》及《图书情报工作》等期刊于2013-2017年所刊载4285篇论文为研究对象,对论文所使用研究方法的统计结果表明“实证分析法+模型展示法”成为我国图书情报学研究中结合使用最为频繁的方法。王芳等通过计量分析发现,计算机学科是图书情报学中方法[28]、理论[29]来源占比最高的学科。对于海外图书情报学,陶俊等[30]统计了JASIST、IPM及JIS等5种国际一流期刊于2013年和2018年两个时间窗内的研究方法使用情况,指出计算测试——计算机科学研究范式,已逐步成为当前海外图书情报学研究中应用比重最高的方法。事实上,随着跨学科合作成为当前知识生产的主流模式,以计算机为代表的学科对图书情报学的渗透和影响不断强化[31],借助利用计算机领域中的算法、模型或工具解决图书情报领域中的研究问题已屡见不鲜[32]。这些在计算机领域被视为研究对象的算法、模型或工具,在图书情报领域多被作为解决特定问题的研究方法。在这一知识角色转变背景下,本文提出了一种基于跨学科知识角色迁移规律的方法实体识别方法,通过构建计算机领域中的算法、模型字典完成图书情报领域方法实体语料的标注,继而解决数据需求问题,提升识别模型的泛化性和鲁棒性。
2 研究方法
2.1研究思路概述为了解决图书情报领域中的研究方法自动识别问题,本文依据图书情报领域与计算机领域间的知识角色迁移规律,提出了一种基于弱监督学习的神经网络模型,通过大批量标注样本的训练拟合,实现更加精确和鲁棒的图书情报学研究方法识别。本文的整体研究框架如图1所示,总共可分为3个步骤:a.数据获取及预处理。采用字典结合bootstrapping的自学习策略获取图书情报领域中的方法字典,这些方法均为计算机领域中的算法、模型等实体,基于该字典完成训练语料的标注;b.深度学习模型选择。选择当前3种较为主流前沿的神经网络模型,通过实验检测方法实体识别的效果;c.方法实体识别,应用经训练拟合后的模型完成学术文本中研究方法的识别。

图1 研究方法实体识别整体框架
2.2数据获取及预处理鉴于计算机领域中的算法及模型在图书情报领域中通常作为解决研究问题的方法出现,本文提出了一种基于跨学科知识角色迁移规律的数据自动标注策略。具体而言,首先从百度学术、谷歌学术中收集本次研究所需的原始数据语料;其次,采用人工结合bootstrapping的方法构建计算机领域的算法模型字典集;随后,应用计算机领域的算法模型字典匹配图书情报领域的文本数据,基于计算机领域与图书情报领域间的知识角色迁移规律,将出现在图书情报文献中的计算机算法或模型均默认为其研究方法,得到批量关于方法实体的标注数据。
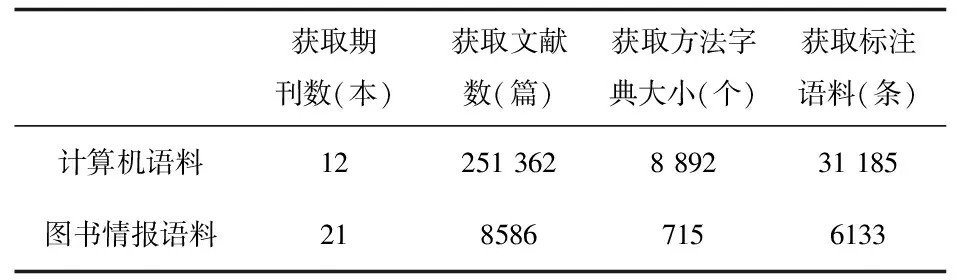
表1 数据获取及预处理结果概览
在数据采集方面,获取《计算机学报》《软件学报》《计算机工程》及《计算机科学》等12本计算机领域期刊2010-2019年刊载的学术文献共计251 362篇;获取《中国图书馆学报》《情报学报》及《图书情报工作》等21本图书情报领域期刊于2010年-2019年刊载的学术文献共计8 586篇。在获取原始文献数据后,考虑到论文全文中含有大量与方法实体无关的语句,本文选用信息量更为富集的文献摘要作为训练语料的获取来源。
在计算机领域算法及模型的字典构建上,本文首先采用规则结合人工的方式从计算机语料中获取了3000个常见算法及模型实体词,作为bootstrapping策略的原始字典。随后应用原始字典从计算机语料中匹配出若干条描述字典中算法或模型的语句,对该语句标注并用以完成NER模型训练。最后,利用拟合好的NER模型对计算机语料进行算法、模型的实体识别,将识别出的算法模型实体扩充至原字典。对上述步骤多次重复迭代后,得到规模大小约为9 000的计算机领域模型算法字典。
在图书情报理领域方法标注语料获取方面,本文应用扩充后的计算机领域模型算法字典从图书情报领域语料中匹配出6 642条含有字典中算法或模型的语句,通过人工过滤后得到6 133条关于图书情报领域研究方法的标注语料。
2.3关键技术描述为识别图书情报领域学术文献中的研究方法,本文采用了一种跨学科知识角色迁移规律的数据标注策略,以解决现有研究中数据获取成本高昂的问题。在实验设置上,选择了当前较为主流及前沿的3种神经网络模型用以测试研究方法的识别效果。下面对这3种模型进行概要介绍。
2.3.1 BiLSTM+CRF LSTM(长短时记忆网络,Long Short-Term Memory)作为RNN (循环神经网络,Recurrent Neural Network)的一种改进,解决了传统RNN中反向传播所导致的梯度消失和梯度爆炸问题[33]。通过引入输入门、遗忘门和输出门等机制,LSTM能够较好的存取序列中历史关联信息。BiLSTM(双向长短时记忆网络)则是使用两层LSTM从正向和反向进行序列信息捕获。CRF(条件随机场,Conditional Random Field)是一种鉴别式概率模型,因能对标签转移关系建模而被广泛应用于序列标注任务中[34]。
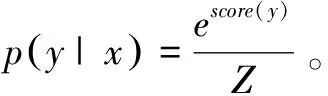
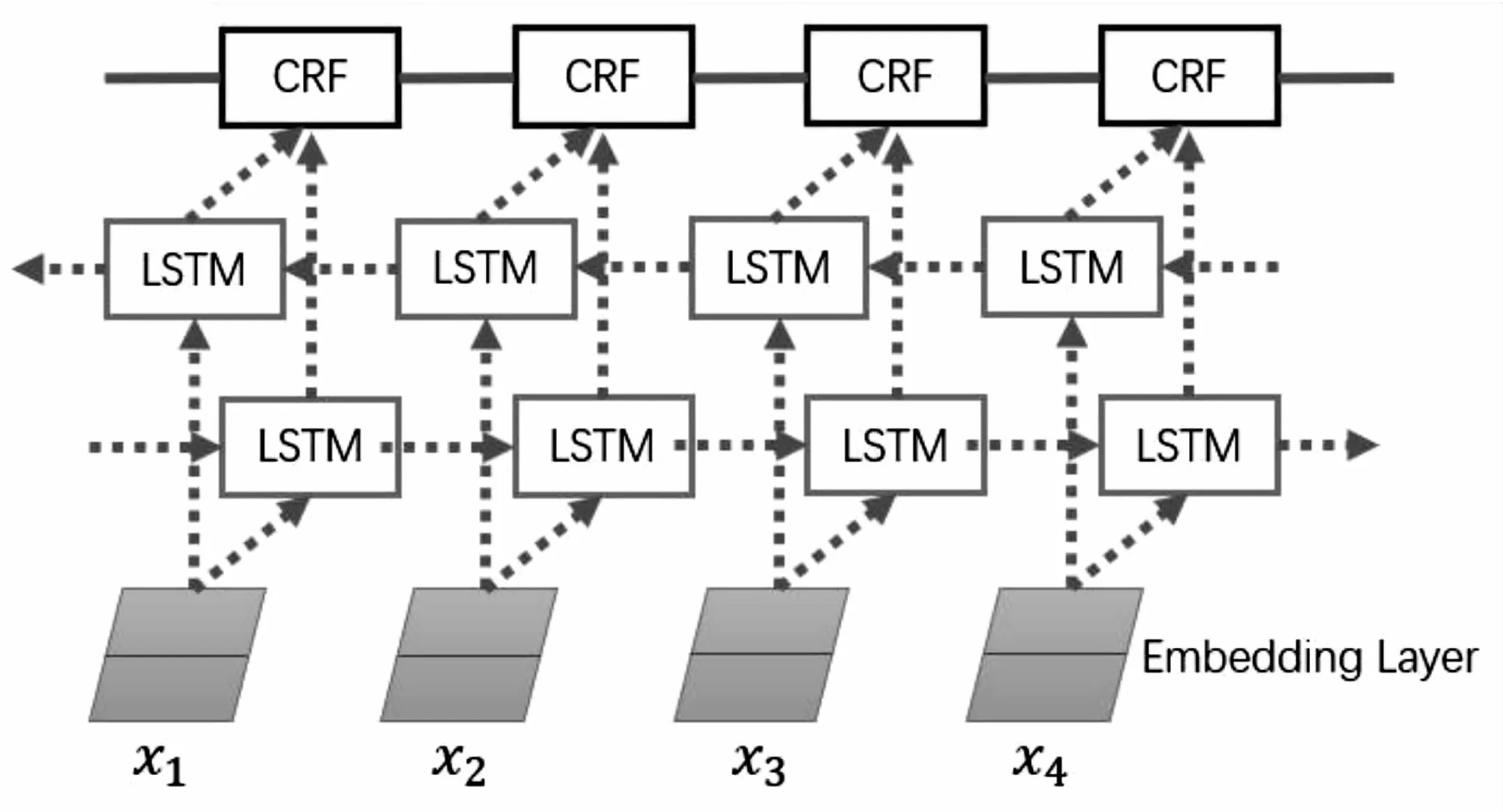
图2 基于BiLSTM+CRF实体识别模型
2.3.2 BERT BERT(Bidirectional Encoder Representation from Transformers)是Google AI团队于2018年提出了一种基于Attention机制[37]的预训练模型[38]。作为当前最为前沿的深度学习模型, BERT网络模型能够在字符、词汇及语句三个粒度层面实现文本的语义特征挖掘,学习文本中的词性、句法和语义等潜在信息(见图3)。相较传统神经网络模型,BERT网络采用Transformer作为模型的基本构架,多层可叠加的self-attention使得BERT模型能够无视空间和距离学习序列中的词位交互信息。此外,为弥补self-attention机制所引起的序列位置信息损失,BERT使用了position encoding层记录序列中每个元素的所在位置。

图3 BERT多粒度特征挖掘示意图
基于BERT模型的研究方法识别可看作为联合学习(Joint learning)策略[39]下的序列标注任务,即要求模型同时完成BERT网络自身中的语句配对任务以及本次研究中方法实体词的BIO标注任务。通过共享各项任务中模型所学习的特征信息,多任务学习模式下的神经网络模型具备更强的泛化能力,因而能够对学术文本中的研究方法实体更为鲁棒的识别。
2.3.3 ALBERT BERT预训练模型在众多NLP任务均获取了不俗表现,但高达数亿的参数量也引起了诸多其他问题,如硬件算力要求苛刻、模型训练时间过长以及小批量数据下易欠拟合等。为了提高参数的利用效率,Lan在BERT的基础上提出了更为精巧的ALBERT模型[40]。通过在嵌入层分解词向量矩阵(factorized embedding parameterization)以降低其维度,并在全连接层和注意力层采用参数共享机制(cross-layer parameter sharing)的同时移除dropout策略,ALBERT网络有效减少了模型参数量 (BERT_large参数大大小为334M,ALBER_large参数大小仅为18M),解决了BERT网络中的模型退化问题。
与BERT网络相似,基于ALBERT模型的研究方法识别同样可视为联合学习下的序列标注。稍有区别的是ALBERT将BERT中原有的句子匹配任务(Next sentence prediction)替换为语序预测(Sentence Order Prediction),以提高模型在句对关系推理上的能力。
3 实验与结果分析
3.1实验环境及评价指标本文的所有实验均在表2所示的环境配置中完成。

表2 实验环境
在评价指标上,选择查准率(precision)、召回率(recall)及F1值来检测模型对于图书情报领域研究方法实体的识别效果。其中,F1值为查准率和召回率的调和平均数,用以评价模型的综合性能,计算公式如下:
F1=(Precision+Recall)/2
(1)
3.2优化策略参数设定及优化策略对于BiLSTM+CRF模型,选用序列标注任务中常用的预设初始参数值,经40个epoch迭代调优后:向量化维度为100,LSTM神经元数为100,batch_size为32,学习率设置为0.001,选择Relu激活函数作为正则化方法,droupout设置为0.5,应用Adam梯度下降法加快模型的收敛速度,采用Glove向量化。
对于BERT模型,使用base及large两个版本进行对比试验。其中,应用bert_base_config.json文件和bert_large_congfig.json文件设置相应参数初始值,经多40个epoch迭代调优后:向量化维度为512,batch_size为32,学习率设置为5e-5,选择Gelu激活函数作为正则化方法,attention_dropout设为0.1,使用Adam梯度优化策略。
对于ALBERT模型,同使用base及large两个版本进行对比试验。其中,应用albert_base_config.json文件和albert_large_congfig.json文件设置相应参数初始值,经多40个epoch迭代调优后:向量化维度为128,隐藏层维度为1024,学习率设置为5e-5,选择Gelu激活函数作为正则化方法,attention_dropout设为0,同样使用Adam梯度优化策略。
3.3实验结果及分析本文分别选用了BiLSTM+CRF、BERT以及ALBERT三种深度学习模型进行对照实验,以检验本文所提出方法实体识别方法的表现效果。基于数据集规模采用了5折交叉验证的方式得到各模型最终的平均评测结果,如表3所示(其中,BERT与ALBERT分别使用了base和 large两个版本进行实验)。
就整体识别效果而言,通过多轮迭代训练,本文所选用的三种模型均能在本次方法实体识别任务中取得较好的效果,在各项评测指标上的实验结果均不低于93%,该结果表明大规模训练语料下的深度学习模型能够在词汇粒度层面对非结构化文本中的方法类实体予以有效识别。其次,通过对比各个模型的具体效果可知,BiLSTM+CRF的识别效果最优,在Precision、Recall和F1-Score三项指标上的结果数值均略高于其他模型。针对该现象,笔者认为BERT及ALBERT模型虽然通过多粒度特征关系挖掘来进一步增加词向量模型的泛化能力,依靠字符、词汇及语句层面的文本语义表征实现更为鲁棒的潜在上下文信息捕获,但自注意力机制所导致的位置信息丢失使得模型无法对序列数据中上下文信息的依赖关系进行较好关联。即使 BERT及ALBERT模型均引入了Position-Encoding层以期编码文本的绝对位置信息,但字符相对位置信息的丢失使其无法较好的直接适用于对位置信息表现敏感的序列标注任务。相较而言,BiLSTM能够在迭代循环机制中直接通过顺序结构及时间维度获取文本的相对和绝对位置信息,因此在研究方法实体识别的表现上,BiLSTM+CRF模型较BERT及ALBERT模型更优。
对于BERT及ALBERT模型而言,BERT模型以微弱优势略胜于ALBERT模型,但ALBERT模型在本次任务中的训练拟合时间显著低于BERT模型,该结果表明ALBERT模型能够在大幅度降低计算量的同时仍能保持较好的方法实体识别性能。其次,通过增加网络层数和对应参数,BERT及ALBERT的 large版本均能够在原base版本的基础上得到小幅度提升,但提升效果也较为有限,差值仅在1%以内。
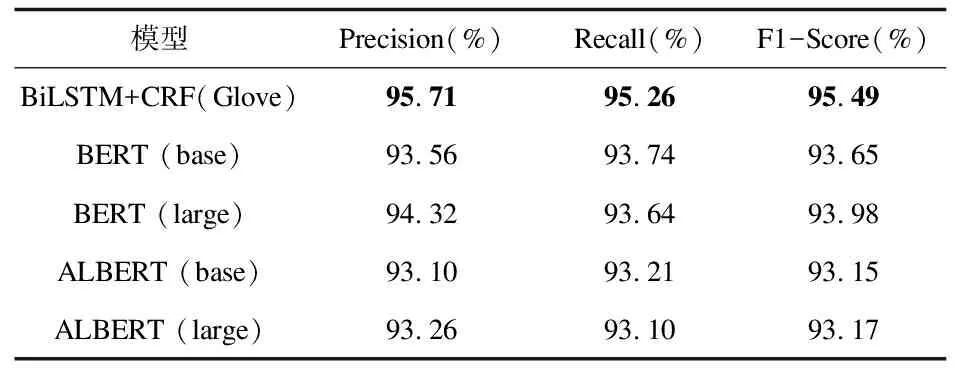
表3 各类模型实验结果
本文提出了一种基于知识角色迁移规律的图书情报领域研究方法自动识别方案,为验证该方法的真实有效性,本文采用人工标注的形式获取了200条数据以用于实验测试。具体标注方法如下:由1位情报学博士研究生和2位情报学硕士研究生对随机抽取的200条数据进行人工标注。标注过程分为两轮,第一轮由个人独立标注,对于个人不能确定的数据或标注不一致的数据,由3位同学在第二轮中投票决定。最后,使用Kappa系数[41]进行人工标注数据的一致性校验,计算结果(Kappa=0.89>0.8)显示该数据具备较高的置信度。表4为3种模型在人工标注数据上的实验结果。

表4 人工标注数据实验结果
选取BiLSTM+CRF、BERT(large)以及ALBERT(large)进行实验测试,从表4结果可知,各个模型均在所有指标上出现了不同程度的下降,但总体而言尚可接受。其中,LSTM的各项表现下降最为明显,这是由于BERT及ALBERT自身携有的强大语义表征能力能够支持模型更好的捕获文本上下文信息,该结果表明BERT及ALBERT模型相较于LSTM模型具有更优的泛化性和鲁棒性。其次,针对于各项指标,各个模型在召回率(Recall)上的下降程度整体上明显高于准确率(Precision)。通过错例分析发现,对于图书情报文献中的模型及算法类方法实体,模型通常能够以相对较高的准确率和召回率予以识别,但对于其他描述形式的方法实体,由于命名实体识别模型在训练过程中缺乏足够的数据进行特征捕获,因此在模型及算法之外的方法实体识别表现上较为有限,尤其在召回率上表现糟糕。造成该结果的主要原因在于数据标注所构建的种子字典中只囊括了计算机领域中的算法和模型,导致标注语料中方法类实体的外在特征较为单一且显著,过于依赖该特征的方法实体识别模型无法获得一个较为可观的鲁棒性能。人工标注数据集上的测试结果显现出本文所提出的方法在泛化性上仍具有较大的提升空间,因此,在后续研究中将采用与BERT模型相似的Mask机制对语句中的方法实体词进行随机概率遮掩,迫使模型学习语句中的语法等信息,进而弱化方法实体词本身的词汇特征信息,以进一步提升识别模型的泛化性能。此外,应用BERT结合BiLSTM的方式,在获取BERT强大语义表征能力的同时借助BiLSTM完成文本位置信息的编码,实现对图书情报学研究方法实体更为精准和鲁棒的识别。
4 结 语
本文的目的是在词汇粒度层面实现图书情报领域中方法实体的自动抽取。针对现有基于机器学习的方法实体识别研究中存在的数据获取难题,本文提出了一种基于深度学习和知识角色迁移规律的学术文本研究方法识别策略,通过分析图书情报领域与计算机领域之间的知识流入流出特性,在依循知识角色迁移规律的基础上实现大规模的数据批量标注,最后采用序列标注的任务形式获取非结构化文本中的方法实体词。实验结果表明,虽然本文的假设前提具有一定的风险性,即将出现在图书情报领域中的计算机学算法及模型均视为其解决问题的研究方法,但通过大规模语料的有监督学习,本文中的深度学习模型能够在方法实体识别上获得较为可观的表现效果。
本研究仍然存在诸多不足:首先,本文仅考虑了算法和模型这两种在图书情报领域中应用较为频繁的方法实体,与之相似的实体词还包括计算机领域中的软件、系统及工具等;其次,与图书情报领域存在较多知识流入流出的领域学科还包括:档案出版学、新闻与传播及高等教育等,这些领域中的技术或理论也多被作为方法在图书情报领域中广为应用;最后,基于字典和自学习策略的数据获取方式,存在字符特征过强的问题。在未来研究中将通过构建更为多源、多样的方法类实体字典,同时应用同义替换、随机掩盖等数据增强技术,以实现更加精确和鲁棒的方法实体识别。
猜你喜欢
情报杂志(2022年10期)2022-10-20
现代装饰(2022年5期)2022-10-13
现代装饰(2022年3期)2022-07-05
现代装饰(2022年2期)2022-05-23
厦门大学学报(自然科学版)(2021年4期)2021-06-22
计算机应用与软件(2018年9期)2018-09-26
办公室业务(2017年17期)2017-11-25
现代情报(2017年1期)2017-02-27
小天使·一年级语数英综合(2015年10期)2015-10-14
长江丛刊(2015年10期)2015-08-15
