
基于DCGAN的DOCX对抗样本生成
2021-07-20 00:05杨琦贾鹏刘嘉勇
现代计算机 2021年15期
杨琦,贾鹏,刘嘉勇
(四川大学网络空间安全学院,成都610225)
0 引言
国际知名安全实验室McAfee Lab对2020年上半年总题恶意软件攻击情况的研究表明,今年上半年观测到的恶意软件的威胁数量持续上升,每分钟的威胁数量达到了419个,表明恶意软件仍是影响网络安全的重要因素之一。由于恶意软件数量多、范围广,众多安全研究者引入了在分类领域表现出色的各种机器学习算法来应对恶意软件的威胁,众多研究结果表明机器学习算法不仅在数据分类[1]、模式识别、自然语言处理[2]等方面有着出色表现,在垃圾邮件检测和恶意文档检测[3]等方面也有着较高的准确率和效率,因此机器学习算法在恶意软件检测领域有着广泛的应用。
基于机器学习的恶意文档检测技术被大量应用,有许多研究表明其基于特征的检测方式很容易被攻击者精心构造的特征所欺骗,从而达到使分类器错误分类的效果。大量研究者运用不同的方法,不断学习检测器的检测规则,不断降低检测器的准确性,从而生成可以逃逸检测器检测的对抗样本。
深度神经网络的脆弱性问题[4]首次被Szegedy等人提出,他们的L-BFGS方法将人眼无法察觉到的扰动添加进图像中,使DNN图片分类器错误分类,将大熊猫图片识别成了长臂猿,在业界引起了对对抗样本的广泛关注。紧接着Goodfellow等人提出了一种有效的非针对性攻击,他们提出的FGSM方法寻找特征空间中逼近于良性样本的对抗样本,它沿着梯度更新方向一步步攻击,是一种典型的one-step攻击。随后Kurakin等人提出了BIM方法利用更加精细的迭代器对FGSM方法进行迭代优化,与FGSM相比采用更短的步长和切片来更新对抗样本。Dong等人[5]受到动量优化器的启发,提出了MI-FGSM方法,将将动量存储器集成到BIM迭代过程中,旨在构建一个模型集合,以攻击黑盒/灰盒设置中的模型,基本思想是考虑多个模型相对于输入的梯度,并确定更有可能转移到其他模型的梯度方向。
Zheng等人[6]提出一种叫做分布式对抗样本攻击(Distributionally Adversarial Attack,DAA)的新的对抗性攻击,对概率度量的空间进行攻击,与PGD不同的是,对抗性样本是为每个良性样本独立生成的,DAA对潜在的对抗性分布进行优化。此方法所提出的目标首先包括在计算对抗性损失时,对抗性数据分布与良性数据分布之间的Kraft-McMillan(KL)发散,以增加优化过程中的对抗性泛化风险,对后面的工作具有很大的启发意义。
Carlini和Wagner等人[7]提出了一种基于优化的对抗性攻击C&W攻击,C&W方法会逐渐优化对抗样本以找到最优对抗样本。针对DNN,C&W攻击方法在MNIST、CIFAR-10、和ImageNet上达到了100%的攻击成功率。
Moosavi-Dezfooli等人[8]提出了一种新的算法DeepFool,在仿射二进制分类器和一般二进制可微分类器上找到最小对抗性扰动添加进对抗样本。DeepFool方法也可以扩展到攻击一般的多类分类器,其中问题被转化为计算由所有类之间的决策边界形成的凸多面体从重心到表面的距离,实验结果表明,DeepFool方法在几个基准数据集上的扰动添加量均小于FGSM方法。
在上述攻击算法中,良性样本的所有元素(例如,良性图像中的所有像素)都受到干扰。最近的研究表明,在一个受限制的区域/良性样本段中的扰动也可以愚弄深度学习模型,这些扰动被称为对抗性补丁。Sharif等人[9-10]提出只在附在面部图像上的眼镜架上制作对抗性扰动,通过对交叉熵等常用对抗性损失进行优化,局部微扰很容易愚弄VGG-Face卷积神经网络(CNN)。作者在物理世界中实现了这种攻击,方法是用产生的扰动打印眼镜对。这项工作还提供了视频演示,其中戴对抗性眼镜的人被真正的VGG-Face CNN系统识别为攻击目标。
目前国内外现有的对抗样本生成攻击大多是针对图片的,在恶意文档检测器领域的对抗样本攻击主要是在初期基于大多白盒,现阶段的研究主要集中在灰盒场景下。研究趋势从不计成本的随机生成转向注重效率的生成,从白盒场景转向黑盒场景下的生成,从单一场景转向更复杂的场景下生成。
1 DOCX-GAN框架设计与实现
DOCX-GAN总体上是一个利用GCGAN网络,通过对恶意DOCX文档检测器的检测规则进行学习,将生成器生成的扰动特征添加到恶意样本中,在不影响恶意样本功能的前提下,生成可以使检测器错误分类的对抗样本。
DOCX-GAN总体结构由检测器、生成器、鉴别器和样本处理四个模块构成。算法流程如图1。

图1 DOCX-GAN算法流程图
1.1 检测器
检测器是一个利用机器学习技术搭建的二分类器。在得到DOCX文件输入之后,检测器对文件进行预处理后得到特征向量,利用随机森林(Random Forest,RF)、支持向量机(Support Vector Machine,SVM)和决策树(Decision Tree,DT)等机器学习算法,根据训练好的模型对特征向量对文件的恶意性进行判别,最终对输入判别结果,即输入的文件是恶意的还是良性的。
1.2 生成器
生成器是一个利用深度卷积神经网络搭建的前反馈网络结构,用于生成扰动特征。它基于鉴别器学习到的检测器的检测规则,向样本中增加一些扰动特征使恶意DOCX文档被检测器错误分类为良性DOCX文档。训练时,生成器通过随机添加噪声来生成样本,之后通过鉴别器的反馈进行梯度更新,生成与真实良性样本更相似的对抗样本。生成器的网络结构如下表1所示。
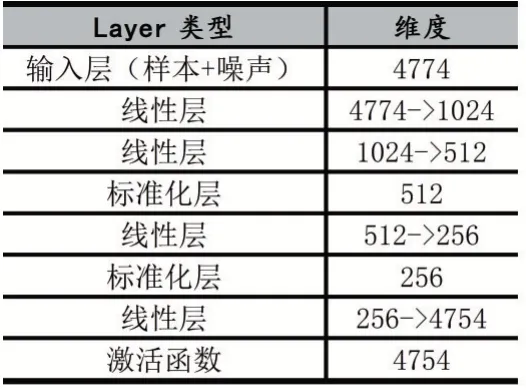
表1 生成器网络结构
为保证生成的对抗样本仍能够保留原有的恶意功能,本方法定义生成器在生成对抗样本时只能采用添加的方式扰动特征的方式修改样本,因为删除和修改的方式可能会破坏恶意样本原有的恶意功能。扰动添加规则如下公式(1):

其中m'为生成器所生成的对抗样本,m为恶意样本,g为生成器生成的扰动特征。
1.3 鉴别器
鉴别器同样是一个利用深度卷积神经网络搭建的前反馈网络结构,用于学习检测器的检测规则。由于检测器并只提供恶意或良性的二进制检测结果,生成器无法有效地学习如何构建对抗样本,鉴别器的作用就是学习检测器的检测规则并提供一个可微的函数帮助检测器进行梯度更新。鉴别器的网络结构如表2所示。
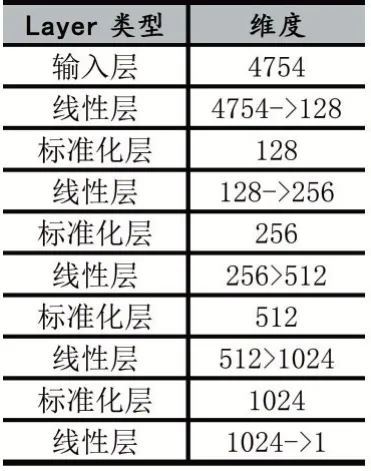
表2 鉴别器网络结构
1.4 特征工程
DOCX文档由不同文件夹中的XML文件组成,每个XML文件中包含文档的实际内容,每个XML文件中包含文档的属性和动作,文档的资源文件保存在“midea”、“embeddings”等文件夹下。鉴于DOCX文档的层级路径结构,本文采用SFEM(Structural Feature Extraction Methodology)方法来提取路径结构特征,把路径转换成唯一的路径列表。图2为样本文档利用SEFM提取的路径列表的一部分。

图2 路径结构列表
其中,红色的路径代表文件夹,绿色的路径代表XML文档,灰色的路径代表每个XML文档中包含的属性。本方法保留了XML文档中属性的名称标签,没有保留属性的值,有利于缩减特征的数量,在保证准确率的前提下,大大提升效率。
2 实验结果与分析
本文构建的实验场景为灰盒场景,设定如下:
●攻击者知晓恶意DOCX恶意文档分类器所采用特征种类是路径结构特征;
●攻击者对特征数量、分类器所采用的机器学习算法、分类器的训练样本等信息是未知的;
●外部不能访问分类器的内部结构从而得到梯度信息,分类器的返回结果仅仅是恶意或良性;
●不能利用样本进行投毒攻击,不能损坏分类器。
实验环境和参数如表3所示。

表3 实验环境
2.1 数据集
本文所采用数据集来源于网络收集、VirusTotal病毒库和Contagio样本集,总计7354个DOCX文档,其中包含5334个良性样本和2020个恶意样本。所用的良性样本均为网络爬取的正常DOCX文档,为保证实验的准确性,本文所使用的样本均经过VirusTotal的验证,只有所有杀毒引擎都判断为良性的文档才加入良性样本集,凡是至少有一个杀毒引擎判断为恶意的样本皆归为恶意样本集。此外,本文还剔除了文件大小小于10KB或大于10M的样本以排除极端情况。
2.2 预处理
本文所有样本在输入网络之前均需经过SEFM方法进行特征提取,提取成为每个样本对应的路径结构特征,接下来还需将路径结构特征通过one-hot编码将恶意样本和良性样本分别构建成恶意特征矩阵和良性特征矩阵以继续处理。构建好的矩阵如表4所示。

表4 特征矩阵
2.3 有效性评估
本次实验采取下列四种评估指标:
MSR:样本修改成功率(Modification Success Rate),对样本修改后能够保留恶意功能
ASR:样本攻击成功率(Attack Success Rate),样本修改后绕过检测器的概率
AMC:平均修改成本(Average Modification Cost),平均生成每个对抗样本需要修改的特征数量
CSR:综合成功率(Comprehensive Success Rate),单次攻击整体的成功率

本文在五种黑盒分类算法中测试了DOCX-GAN生成对抗样本的有效性,包括逻辑回归、多层感知机、随机森林、决策树和支持向量机。在每次实验中,把数据集划分为60%的训练集,20%的验证集和20%的测试集。
表5为针对五种黑盒机器学习算法生成对抗样本有效性的评估。

表5 有效性评估
通过对以上五种黑盒分类的分类结果观察可知:五种分类器对恶意文档检出的概率均在93%以上,具有较好的分类性能,决策树的性能最佳。五种分类器的误报率都在8-12%之间,具有较高的误报率,说明分类器对恶意样本的分类规则均比较严格,在这样的条件下,对抗样本的攻击难度会增大。但结果表明,本方法所生成的对抗样本被五种检测器检出的概率均低于2%,针对逻辑回归、多层感知机、支持向量机的攻击成功率都达到了100%,说明本方法能够有效地生成对抗样本,使基于机器学习地分类器对对抗样本做出错误的分类。
3 结语
本文提出了一种利用深度卷积生成式对抗网络搭建的DOCX对抗样本生成框架,实验结果表明利用此框架生成的对抗样本可以较好地绕过逻辑回归、随机森林、决策树、支持向量机和多层感知机等机器学习算法搭建的检测器,攻击成功率达到了98%以上。
接下来的工作将围绕如何绕过对抗样本防御算法来避免被检测,达到绕过更多机器学习算法和神经网络来进行。
猜你喜欢
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
东方教育(2018年19期)2018-08-23
科技风(2018年15期)2018-05-14
魅力中国(2016年52期)2017-09-01
软件导刊(2017年4期)2017-06-20
新闻界(2014年5期)2014-07-09
