
速度协调的Q学习模型研究
2021-07-16 12:03:52刘元元卢守峰刘肖亮朱婷婷
交通科学与工程 2021年2期
刘元元,卢守峰,刘肖亮,朱婷婷
速度协调的Q学习模型研究
刘元元1,卢守峰1,刘肖亮2,朱婷婷1
(1. 长沙理工大学 交通运输工程学院,湖南 长沙 410114;2. 湖南联智科技股份有限公司,湖南 长沙 410219)
为平滑高速公路瓶颈区域上、下游车流速度,基于单位距离速度变化量和多项式SG卷积平滑处理的2个奖励函数,分别建立了2个速度协调的Q学习模型。利用Excel-VBA、VISSIM和MATLAB的集成仿真平台,对奖励函数的性能进行了仿真分析。研究结果表明:基于SG卷积平滑的奖励函数,可以有效地缓解瓶颈上游“走走停停”的现象,减小速度的波动幅度。速度协调的Q学习模型可以根据交通状态实时选择最优的运行速度。
速度协调;Q学习算法;SG卷积平滑;集成仿真平台
小汽车拥有量日益骤增,交通密度增大,交通流处于不稳定状态,加之车道变窄、合流分流、不良天气、急刹车等因素,容易导致车辆加减速循环、走走停停,不仅延误行程,降低通行能力,还增加燃油消耗,产生大量的有害气体,污染环境。因此,如何有效缓解高速公路交通拥堵现象,已成为许多学者深思的问题。
有学者提出高速公路速度控制方法,即速度协调(基于可变速度限制、车辆信息共享和自动车辆控制等策略,平滑车辆在高速公路运行时的速度变化,使得交通顺畅,提高道路通行能力,缓解交通拥堵)。国内外学者对该方向进行了大量研究。Li[1−2]等人提出了基于描述函数的理论特性和强化学习的汽车跟随模型,与传统的建模方法相比,构建策略可以有效地抑制振荡幅度的发展,从而减少油耗和废气排放。Ma[3−4]等人提出了时间−距离线性速度协调算法和Bang-bang反馈控制速度协调算法,发现速度协调后的交通流轨迹可降低振荡行为。Ghiasi[5−6]等人基于智能网联车辆(connected automated vehicles,简称为CAV)的轨迹平滑概念,用CAV实时协调交通,通过CAV和交通传感器提供的信息,检测下游速度的下降和振荡,预测其向上游的传播。该策略可以获得更平滑的轨迹,提高交通流的总体平稳性。王正武[7−8]等人构建了基于优化强制换道模型和考虑驾驶风格车辆的换道时间和距离预测模型,可以较准确地预测和解释换道行为。Malikopoulos[9]等人提出了可以实时实施的车速控制策略,实现交通流中的速度协调,使每辆车实现最佳的加速或减速。Park[10]等人提出了车速控制策略,采用最小化自动驾驶环境中的车祸风险,通过车辆间风险分析,执行车辆速度控制,实现交通流中的速度协调。
1 Q学习模型简介
强化学习可以分为无模型和模型化[11]。1989年Watkins提出的Q学习算法,是一种基于值函数的典型无模型强化学习算法,可用于解决马尔可夫决策。其原理是智能体根据当前状态,选择某一动作作用于环境,发生状态改变,同时产生一个强化信号(奖或惩)反馈给智能系统,智能系统再根据强化信号和当前环境状态,选择下一个动作,如此迭代循环,直至目标获得最大奖赏,其框架如图1 所示。
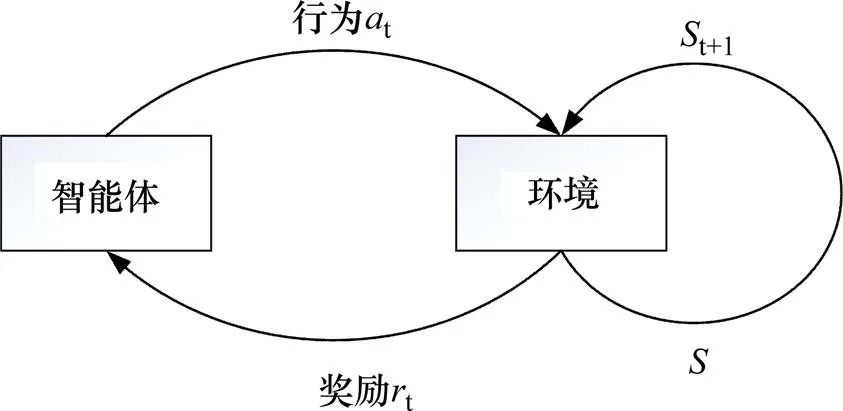
图1 强化学习框架
(,)是指某一时刻的状态(∈),采取动作(∈)能够获得回报的期望值。环境会根据智能体的动作反馈相应的回报,可以用矩阵来存储(,)值。然后根据(,)值选取能够获得最大回报的动作。(,)值的更新公式为:
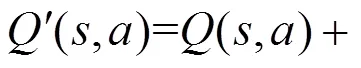
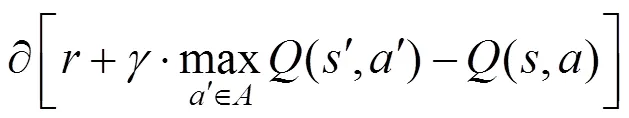
2 速度协调的Q学习模型构建
状态、行为、奖赏是Q学习模型构建的3个主要元素。为实现速度协调,引入CAV作为控制车辆。通过优化CAV的速度,达到平滑速度波动的效果。针对速度协调的特点,状态选取每个步长下游检测器测得的平均车速,行为指CAV的建议运行速度,构建了2个奖赏函数。
2.1 基于单位距离速度变化量的奖励函数
受线性速度协调算法[3]的启发,提出了基于单位距离速度变化量的奖励函数,具体公式为式(2)~(5)。结合Q学习算法,形成了基于单位距离速度变化量奖励函数的Q学习算法,简称为D-Q算法。
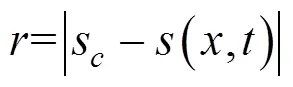

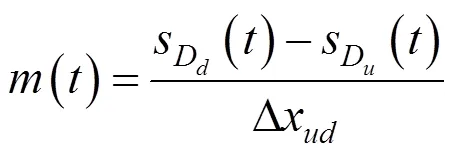


由式(3)可知,奖励函数的含义为智能网联测试车的建议速度越接近单位距离速度变化量下的建议速度时,越小,惩罚值也越小。
2.2 基于SG卷积平滑算法的奖励函数
VISSIM仿真分析可知,下游检测器测得的速度波动幅度大,导致(,)的取值出现大幅的波动。因此,提出基于多项式(savitsky-golay,简称为SG)卷积平滑算法的奖励函数(通过SG卷积平滑算法将下游检测器测得的速度进行平滑处理),结合Q学习算法,形成基于SG卷积平滑算法的奖励函数的Q学习算法,简称S-G算法。
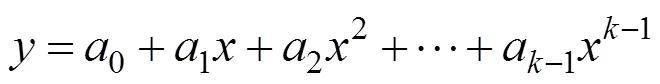
式中:为坐标轴上的数据点,∈。
由式(6)可得到个方程,组成元线性方程组,≥时(一般选择>),方程组有解,采用最小二乘法拟合确定参数。
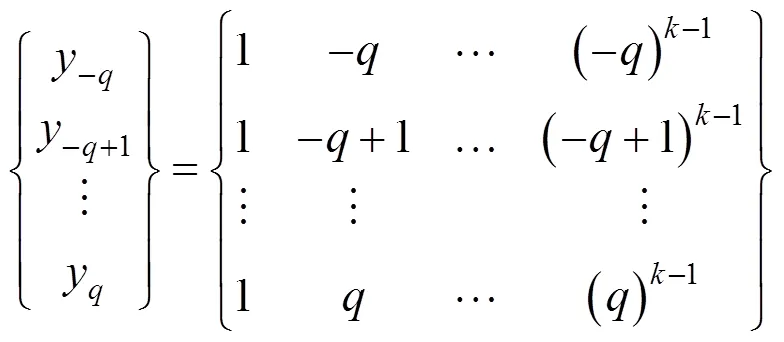
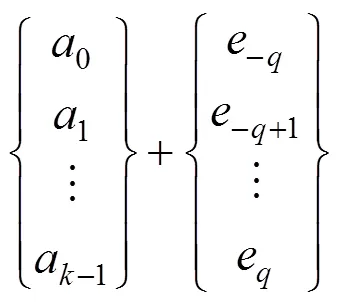
式(7)用矩阵形式表示为:
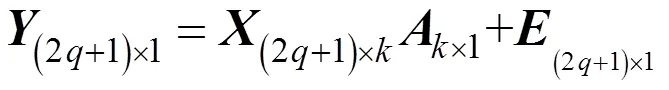
其中,乘以1之后代表矩阵形式。
则式(8)中的最小二乘解为:
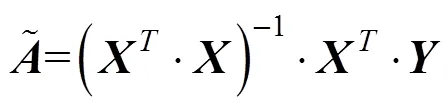
式中:为平滑前的值。
则的滤波值为:
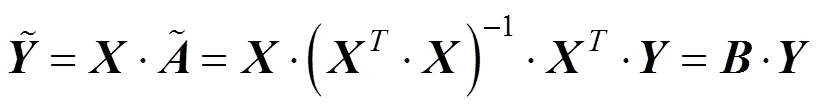
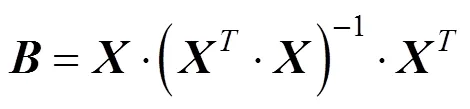
经SG卷积平滑算法分析,结合本试验实例,取平滑窗口的宽度为=4,=3,则=9,得:
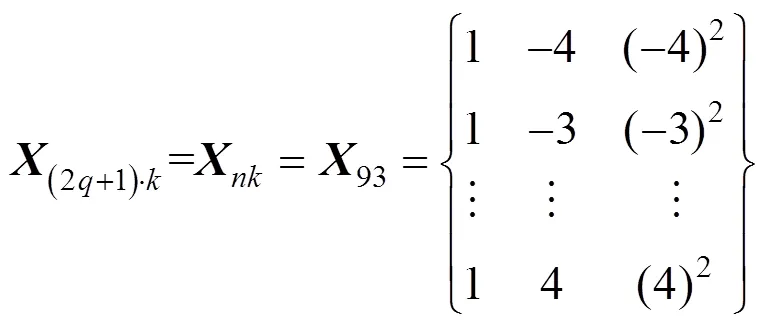
。 (13)
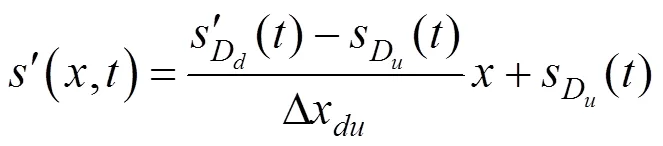
2.3 基于集成仿真平台的在线仿真
利用集成仿真平台[12]方法,构建了速度协调在线仿真模型。基于VISSIM的COM接口与Excel VBA、MATLAB相结合,对速度协调的Q学习模型进行仿真,运算步骤为:
1) 建立VISSIM路网文件(net文件)。包括建立道路网、设置车辆数、检测器的位置和个数、车辆组成、期望速度等,设置相应的评估参数,以便分析后续所需数据。
2) vba程序中,声明所使用的VISSIM的相关变量与对象,例如Vehicles(车辆对象),DataCollection(检测器对象)等;定义相应的初始化函数,例如StartVISSIM (启动VISSIM软件)、ReadINPFile(读入Net文件)、main(主函数)等。
3) 主程序中,通过COM接口的Get Data CollectionByNumber对象,连接VISSIM文件中设置的检测器,实现数据的实时读取;通过AddVehicleAtLinkCoordinate对象,将本文定义的自动网联测试车加入路网中,实现对车辆的控制;通过检测器的GetResult属性,实现检测器数据的采集;通过ActiveWorkbook.Save功能,将VISSIM仿真的实时数据进行输出。
4) 获取最优矩阵。采用在线Q学习算法进行VISSIM仿真学习,通过多次运行在线Q学习仿真程序,获得最优矩阵。首先,在Excel VBA中执行VISSIM仿真程序,以2 s为一个步长,实时获取路网的交通状态、评价指标等信息。然后,通过式(1),更新矩阵,当其达到终止条件时,停止运行。单次VISSIM仿真停止运行条件为测试车到达下游检测器附近停止运行。如果本次运行的最终矩阵未到达收敛条件时,将本次仿真的最终矩阵作为下一次仿真时的初始矩阵,直到达到收敛条件,获得最优矩阵。
5) 执行最优矩阵方案,获取最优建议速度。通过Excel-VBA程序,控制VISSIM仿真运行。通过最优矩阵方案,VISSIM仿真的下游检测器的实时状态,获取最优建议速度,并将建议速度应用到VISSIM仿真中,检验速度协调效果。获取最优矩阵后的VISSIM仿真运行流程如图2所示。
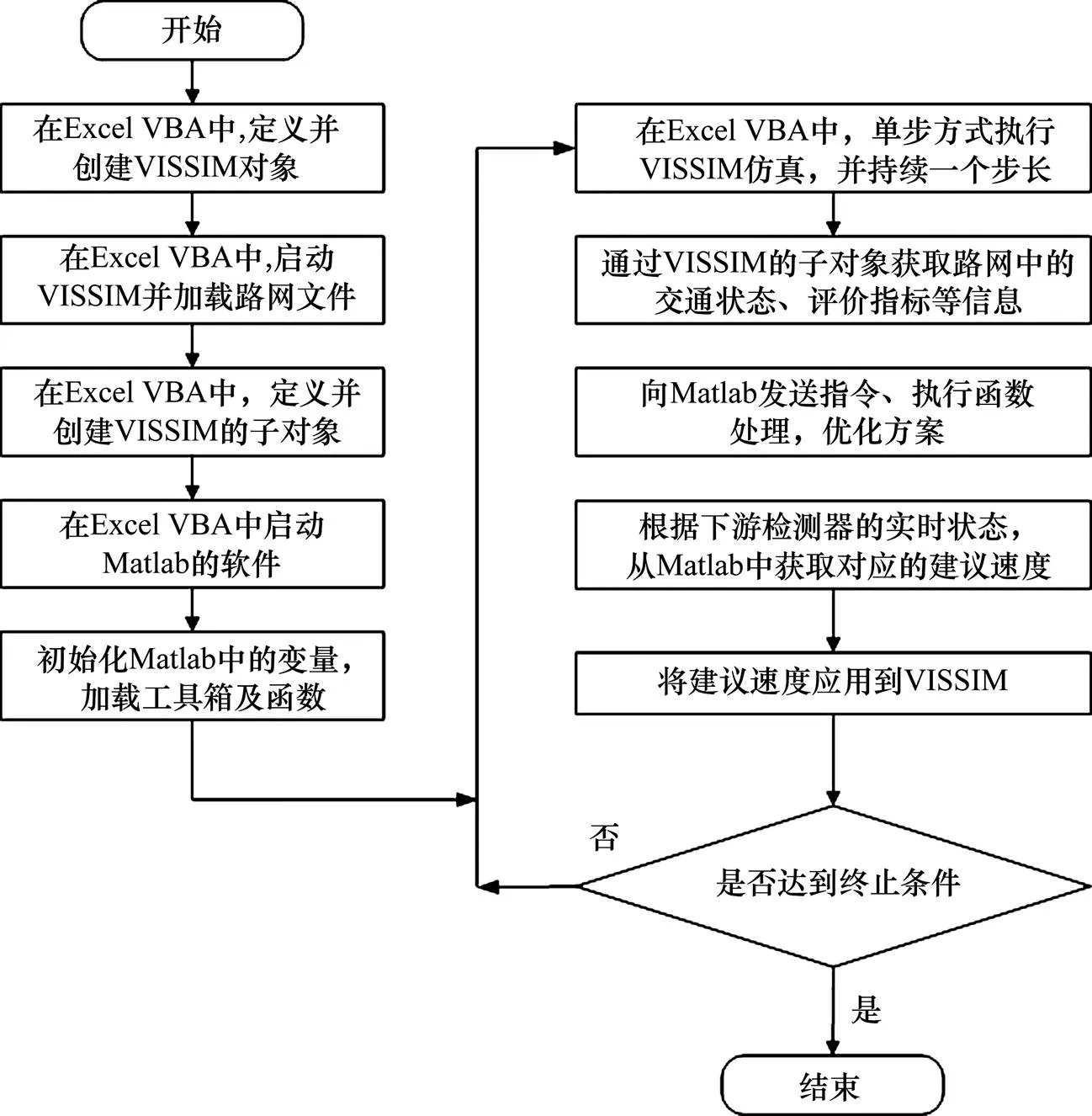
图2 集成仿真平台流程
3 算例分析
3.1 实验环境
以VISSIM为仿真平台,构建一条三车道的高速公路试验路段。道路5 km处,由三车道变成两车道,形成物理瓶颈。其中,仿真路段总长6.68 km,三车道路段为6 km,瓶颈路段长600 m,渐变段长度为40 m。道路1 km处设置上游检测器u,4.9 km处设置下游检测器d,用于检测某一时刻车辆通过该检测器时的平均速度。设置道路的交通流量为 3 780辆/h,饱和度为0.7,具体道路网的示意如图3所示。
当仿真初始化10 min后,由于瓶颈的存在,道路上出现明显拥堵。此时,道路的1 km处(即上游检测器D),控制三辆CAV车辆(C1、C2和C3)并排进入实验路段,下游检测器D测得的平均速度为Q学习算法中的状态,三辆CAV车辆采取的建议运行速度均为Q学习算法中动作,以Δ=2 s为迭代步长,每隔2 s,由下游检测器测得的平均车速。根据Q学习算法,计算出此时上游三辆CAV车辆应采取的建议运行速度,使当前时刻的奖励函数达到最大,如此循环迭代,优化Q值函数,选取最优动作,直到满足收敛条件,结束实验。
3.2 状态划分
Q学习算法的状态为下游检测器的速度值,即下游检测器D在每个步长所测得的平均速度。通过对VISSIM仿真状态进行分析,然后初始化,下游检测器的速度值多分布在20~50 km/h之间,因为状态数为一个确定的值或区间,所以本研究将下游检测器的速度进行分段离散划分,把下游检测器速度[20,50] km/h划分为15个区间,划分区间如图4所示。

图3 路段示意图(单位:m)

图4 基于D−Q算法的状态划分
划分后,得到状态集为:

Q学习算法行为是CAV的实时速度,即测试车C1,C2,C3的速度值,速度区间为[40,120]。同时,将测试车的速度进行分段离散划分,将速度区间[40,120]划分为40个区间,划分区间如图5所示。
划分后,得到状态集为:

3.3 试验结果分析
根据本研究提出的基于单位距离速度变化量的奖励函数和基于SG卷积平滑算法奖励函数的Q学习算法,对C1、C2、C3分别进行2种奖励函数Q学习算法的仿真试验,并与“无控制情况”的结果做对比。
3.3.1 3种不同情况下C1、C2、C3的速度协调曲线
CAV在无控制时,速度协调曲线如图6所示。从图6中可以看出,无控制情况下3辆控制车辆的初始速度较大,经过4.6 km后,控制车辆的速度骤降,速度从90~120 km/h降到0~40 km/h,车辆的速度波动大,在瓶颈处形成“交通震荡”,符合无控制情况下的实际情况。基于单位距离速度变化量奖励函数的Q学习算法,对控制车辆进行控制的位置−速度曲线如图7所示。与图6相比,虽然速度呈整体下降趋势,但是波动减小,表明:该算法起到了“速度协调”的作用。基于SG卷积平滑算法,奖励函数的Q学习算法对控制车辆进行控制的位置−速度曲线如图8所示。从图8中可以看出,其速度曲线比图6、7中的曲线更为平滑,速度波动幅度更小,有较好的速度协调效果。
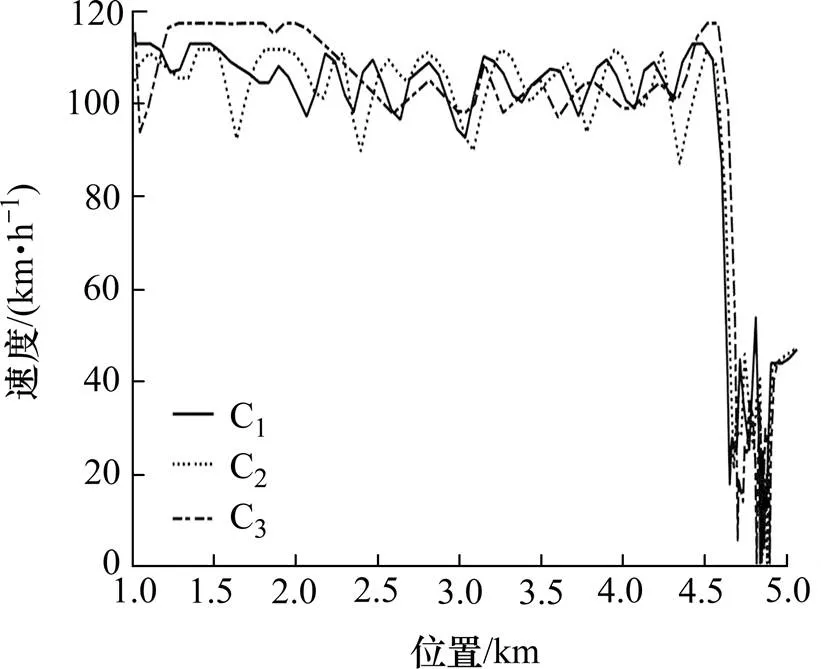
图6 无控制时速度协调曲线
3.3.2 三种不同情况下的C2的速度协调曲线
由于C1、C2、C3的速度大致相同,以C2为例,分析无控制、基于单位距离速度变化量奖励函数的Q学习算法、基于SG卷积平滑算法奖励函数的Q学习算法3种不同情况下的C2速度变化,如图9所示。
从图9中可以看出,C2车辆从起点1 km到5 km处的速度变化很明显。C2的初始速度很大,达110 km/h。由于处于无控制情况下,C2无法知道路段下游的道路状况,影响C2车速的主要因素是C2周围的车辆情况,而不是道路下游的车辆情况,导致C2前期一直处于高速状态,直到经过4.6 km后接近瓶颈,从110 km/h骤降到20 km/h,速度变化波动大,在此处产生典型的交通震荡。
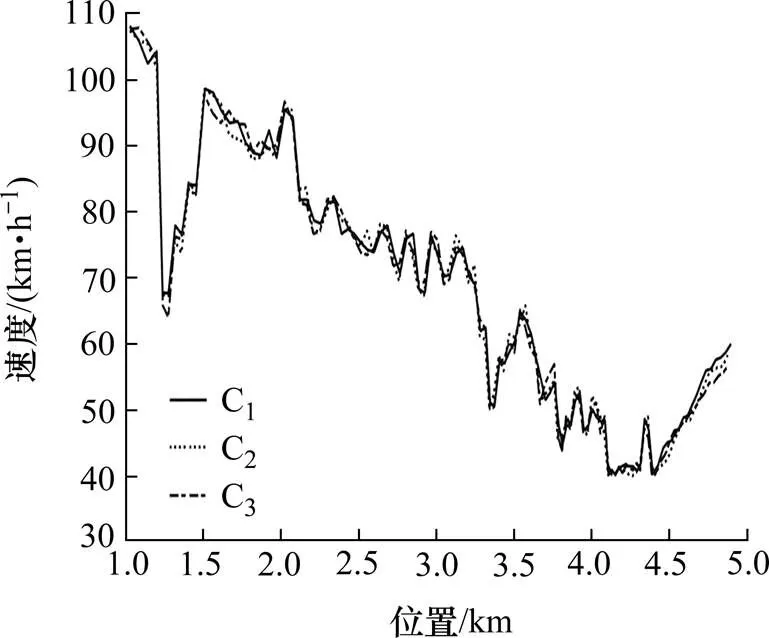
图7 基于D-Q算法的速度协调曲线
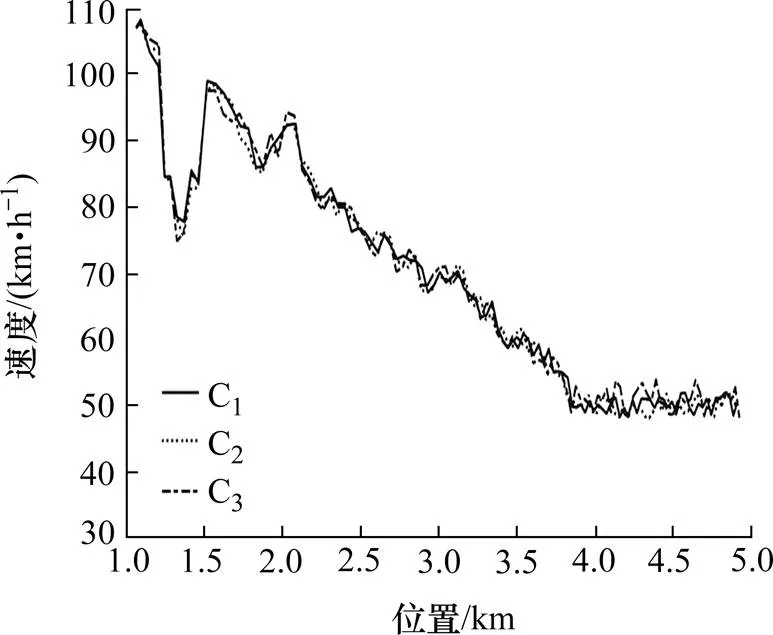
图8 基于SG-Q的速度协调曲线
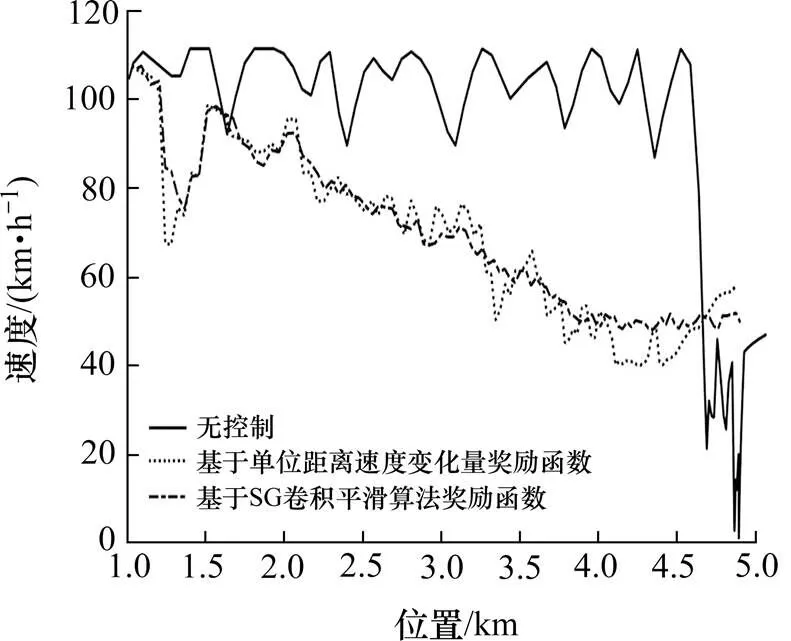
图9 C2速度协调效果对比
从图9中还可以看出,基于单位距离速度变化量奖励函数的Q学习算法,对C2进行速度控制达到速度协调效果。由于引入了单位距离速度变化量奖励函数的Q学习算法,系统每间隔2 s,根据道路下游检测器d测得平均速度。通过Q学习算法计算,此时C2应该采取最优速度。C2根据计算推荐的最优速度,每隔2 s更新速度,使得C2的速度波动减小幅度下降,而不是骤降,减小了“交通震荡”。与无控制情况相比,基于单位距离速度变化量奖励函数的Q学习算法,更有效地协调了C2的速度。
由于基于单位距离速度变化量奖励函数的Q学习算法的速度协调效果曲线中,道路下游检测器d测得的平均波动较大。为使速度波动更小,速度曲线更平滑,引入基于SG卷积平滑算法奖励函数的Q学习算法对道路下游检测器d进行速度控制,在基于单位距离速度变化量奖励函数基础上,得到平滑下游检测器所测得的平均速度。表明:与基于单位距离速度变化量奖励函数的Q学习算法相比,基于SG卷积平滑算法奖励函数的Q学习算法的速度协调效果曲线更平滑,C2的速度波动更小,更有效地协调了C2的速度变化。因此,基于SG卷积平滑算法奖励函数的Q学习算法对C2的速度协调效果最好。
3.4 Q值收敛情况
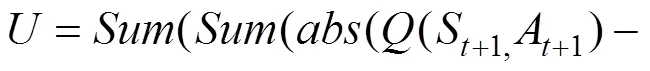
基于D-Q算法、SG-Q算法的值收敛如图10、11所示。从图10中可以看出,基于单位距离速度变化量奖励函数的Q学习算法,迭代次数在203与903区间中。连续700次,迭代收敛值小于9。从图11中可以看出,基于SG卷积平滑算法奖励函数的Q学习算法,迭代次数在98与798区间中。连续700次,迭代收敛值小于9。因此,可以看出前者迭代次数为903次,后者迭代次数为798次,2个奖励函数均收敛,且后者收敛速度更快。
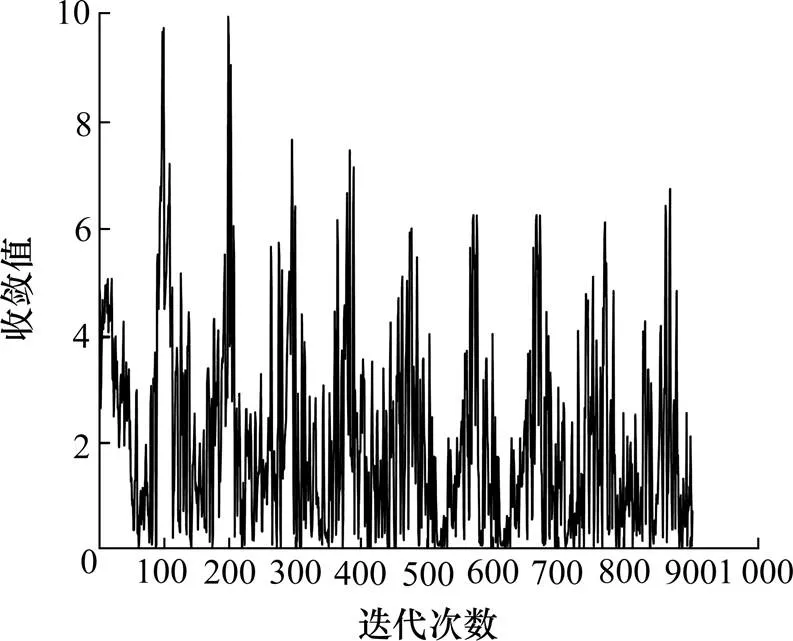
图10 基于D-Q算法的Q值收敛
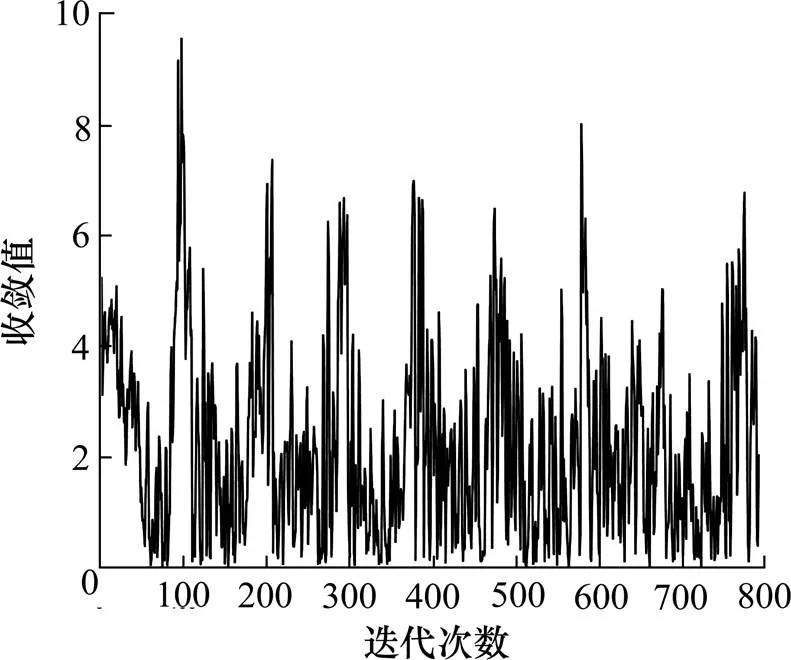
图11 基于SG-Q算法的Q值收敛
4 结论
基于SG卷积平滑算法奖励函数的Q学习算法,速度波动最小,速度曲线最平滑。同时,从收敛情况可知,基于单位距离速度变化量奖励函数收敛的稳定性更好,基于SG卷积平滑算法奖励函数的收敛速度更快。因此,提出的D−Q算法、SG−Q算法2个奖励函数均能有效地协调高速公路上车辆的速度变化,减小了“速度震荡”。当高速公路瓶颈处发生严重排队现象时,上游车辆到达瓶颈处,将减少“走走停停”的现象。
[1] Li X P, Cui J X, An S, et al. Stop-and-go traffic analysis: Theoretical properties, environmental impacts and oscillation mitigation[J]. Transportation Research Part B: Methodological, 2014, 70: 319−339.
[2] Qu X B, Yu Y, Zhou M F, et al. Jointly dampening traffic oscillations and improving energy consumption with electric, connected and automated vehicles: A reinforcement learning based approach[J]. Applied Energy, 2020, 257: 114030.
[3] Ma J Q, Li X P, Shladover S, et al. Freeway speed harmonization[J]. IEEE Transactions on Intelligent Vehicles, 2016, 1(1): 78−89.
[4] Yang H, Rakha H. Feedback control speed harmonization algorithm: Methodology and preliminary testing[J]. Transportation Research Part C: Emerging Technologies, 2017, 81: 209−226.
[5] Ghiasi A , Ma J , Zhou F , et al. Speed harmonization algorithm using connected autonomous vehicles[C]// The 96th Annual Meeting of the Transportation Research Board, transportation Research Board, 2017.
[6] Ghiasi A, Li X P, Ma J Q. A mixed traffic speed harmonization model with connected autonomous vehicles[J]. Transportation Research Part C: Emerging Technologies, 2019, 104: 210-233.
[7] 王正武, 邹文竹, 郝威. 高速公路交通事故后基于优化的强制换道研究[J]. 交通科学与工程, 2020, 36(1): 87−92.(WANG Zheng-wu, ZOU Wen-zhu, HAO Wei. Research on mandatory lane change based on optimization after traffic accidents on the expressway[J]. Journal of Transport Science and Engineering, 2020, 36(1): 87−92.(in Chinese))
[8] 刘思源, 喻伟, 刘洁莹, 等. 考虑驾驶风格的车辆换道行为及预测模型[J]. 长沙理工大学学报(自然科学版), 2019, 16(1): 28−35. (LIU Si-yuan, YU Wei, LIU Jie-ying, et al. Characteristics analysis and prediction model of lane changing behavior under different driving styles[J]. Journal of Changsha University of Science & Technology (Natural Science), 2019, 16(1): 28−35.(in Chinese))
[9] Malikopoulos A A, Hong S, Park B B, et al. Optimal control for speed harmonization of automated vehicles[J]. IEEE Transactions on Intelligent Transportation Systems, 2019, 20(7): 2405−2417.
[10] Park H, Oh C. A vehicle speed harmonization strategy for minimizing inter-vehicle crash risks[J]. Accident Analysis & Prevention, 2019, 128: 230−239.
[11] 赵婷婷, 孔乐, 韩雅杰, 等. 模型化强化学习研究综述[J].计算机科学与探索,2020,14(6):918−927.(ZHAO Ting-ting, KONG Le, HAN Ya-jie, et al. Review of model-based reinforcement learning[J]. Journal of Frontiers of Computer Science and Technology, 2020, 14(6): 918−927.(in Chinese))
[12] 卢守峰, 韦钦平, 沈文, 等. 集成VISSIM、Excel VBA和MATLAB的仿真平台研究[J]. 交通运输系统工程与信息, 2012, 12(4): 43−48, 63. (LU Shou-feng, WEI Qin-ping, SHEN Wen, et al. Integrated simulation platform of VISSIM, excel VBA, MATLAB[J]. Journal of Transportation Systems Engineering and Information Technology, 2012, 12(4): 43−48, 63.(in Chinese))
Research on Q-Learning model of speed harmonization
LIU Yuan-yuan1, LU Shou-feng1, LIU Xiao-liang2, ZHU Ting-ting1
(1.Traffic and Transportation Engineering College, Changsha University of Science & Technology, Changsha 410114, China; 2. Hunan Lianzhi Technology Co., Ltd., Changsha 410219, China)
In order to optimize the speed of upstream and downstream traffic flow in the bottleneck area of expressway, two reward functions based on unit distance velocity variation and SG convolution smoothing were proposed, and two Q-learning models of speed harmonization were established. The integrated simulation platform combining Excel-VBA, VISSIM and MATLAB was used to simulate the reward functions. The results show that, the reward function based on SG convolution smoothing can effectively relieve the stop-and-go traffic on the upstream of the bottleneck. The fluctuation amplitude of speed was reduced. The Q-Learning model of speed-coordinated can suggest the optimal real time speed according to the traffic state.
speed harmonization; Q-Learning model; SG convolution smoothing; integrated simulation platform
U491.4
A
1674 − 599X(2021)02 − 0098 − 07
2020−10−30
刘元元(1995−),女,长沙理工大学硕士生。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
小学生导刊(2018年34期)2018-12-18 01:53:14
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中国交通信息化(2017年9期)2017-06-06 07:14:57
工业设计(2016年11期)2016-04-16 02:49:43
山东青年(2016年3期)2016-02-28 14:25:55
母子健康(2015年1期)2015-02-28 11:21:33
电视技术(2014年19期)2014-03-11 15:38:20
延河(下半月)(2014年3期)2014-02-28 21:06:45
