
基于深度卷积网络的工程车辆检测算法
2021-07-16 07:02孔小红石伟伟
南京工程学院学报(自然科学版) 2021年2期
浦 东,陈 瑞,孔小红,石伟伟
(1. 南京工程学院人工智能产业技术研究院, 江苏 南京 211167;2. 南京供电公司, 江苏 南京 210008;3. 江苏量为石科技股份有限公司, 江苏 南京 210023)
随着我国经济的不断发展,电网基本上已经实现全国覆盖,每年新建的输电线路越来越多[1],但是恶劣的自然环境和一些破坏性外力使得输电线存在被破坏的可能,进而引发一片区域的停电,造成不可逆的严重危害[2].因此,提前预防线路被破坏显得尤为重要[3].这就需要电力巡检人员进行定期检查,在输电线路旁有施工任务时及时给予指引.但是这种方法不仅效率低下,而且更受到自然因素的影响[4].将计算机视觉技术和远程视频监控系统相结合,能够实现对监控目标的自动检测,这不仅充分利用了计算机视觉高效与高速的性能,还极大降低了人的劳动强度[5].
目前,基于深度学习的目标检测方法可以分为基于候选区域的目标检测方法和基于回归的目标检测方法.基于候选区域的目标检测方法和人为设计的特征表达结合分类器的目标检测方法在检测流程上大体相同:选取候选区域,对候选区域进行特征提取,在候选区域中进行预测.基于候选区域的目标检测方法在流程中的每一步都是以深度学习算法为核心,结构比较复杂.选取候选区域相当于在进行目标检测之前增加一个先验知识,降低了下一步分类和边框回归的难度,检测精度较高.不过选取候选区域也是整个检测流程中最耗时的一步,导致整体检测速度下降,无法实时应用[6].典型的算法有Faster R-CNN[7]等.基于回归的目标检测算法就是在基于候选区域的目标检测方法的基础上进行简化,删去选取候选区域这个步骤.因此,基于回归的目标检测方法的检测速度要快得多,而且结构更加简单、直观.基于回归的目标检测方法是直接利用基础边框的特征进行预测,基础边框中并不包含先验知识,导致分类和边框回归的误差较大,检测精度略有下降.典型的算法有YOLO(you only look once)[8]、SSD[9]、Retina-Net[10]等.但是这两大类方法对小目标的检测效果均较差.
本文以YOLO v3[11]算法为基础对工程车辆进行目标检测,将聚类算法中欧式距离函数替换为交并比损失函数IoU_Loss,加快YOLO v3算法的提取能力,并对其损失函数以及极大值抑制进行改进,从而使模型的检测性能提高.
1 YOLO v3算法介绍及改进
YOLO算法是一种多框检测的One-stage算法,该快速检测算法可满足小尺度密集工程车辆检测在速度上和精度上的要求,YOLO v3输出了3个不同尺度的特征图,通过这种多尺度输出来对不同尺寸的目标进行检测,越精细的网格就可以检测出越精细的物体,这个方法加强了对小物体的输出精度,因此YOLO v3对远距离的工程车辆检测有较好的效果.
1.1 YOLO v3网络结构
YOLO v3的网络框架主要包括两大部分:1) 主干网络,主要作用是对输入的图片进行特征提取;2) 预测部分,主要作用是在特征提取的基础上进行上采样,输出三个不同的尺度.YOLO v3网络结构图如图1所示.

图1 YOLO v3网络结构图
YOLO v3以Darknet-53特征提取网络为基础,借鉴了ResNet网络中的残差结构,可以有效防止当网络变深时训练网络出现梯度消失问题.Darknet网络主要由DBL组件和RES组件构成,DBL由卷积层(conv2d)、归一化层(BN)、激活函数层(leaky relu)构成.
1.2 改进策略
本文通过改进YOLO v3的结构网络,可以较好地将YOLO v3应用到工程车辆检测中.
1.2.1 聚类算法
YOLO v3模型在检测小目标工程车辆时,首先会初始化先验框(bounding box)的参数,然后使用工程车辆数据集进行训练,参数被更新,最终在神经网络的输出层输出预测目标位置.由于每次发生函数是随机的,先验框模型的好坏往往会对后面的模型训练起着关键作用,这不仅导致网络训练时间延长,同时模型可能不收敛.在初始化时采用k-means聚类算法,在实际模型训练中发现将欧式距离作为损失函数,较大的参考框会比较小的参考框产生更大误差.为了加快模型训练速度,提高网络的预测精度,对k-means算法进行改进,使用先验框与真实框之间的交并比IoU作为损失函数替代欧式距离,改进的距离函数定义为:
(1)
式中:boxi为先验框,Truthj为真实框.
结合小尺度密集工程车辆的长宽比接近3∶1或1∶1且像素区域内像素边缘与背景之间梯度较大的特点,通过改进,得到先验边界框尺寸为(14,16)、(15,43)、(29,26)、(42,42)、(29,85)、(71,68)、(55,168)、(120,124)、(81,232),聚类结果如图2所示.
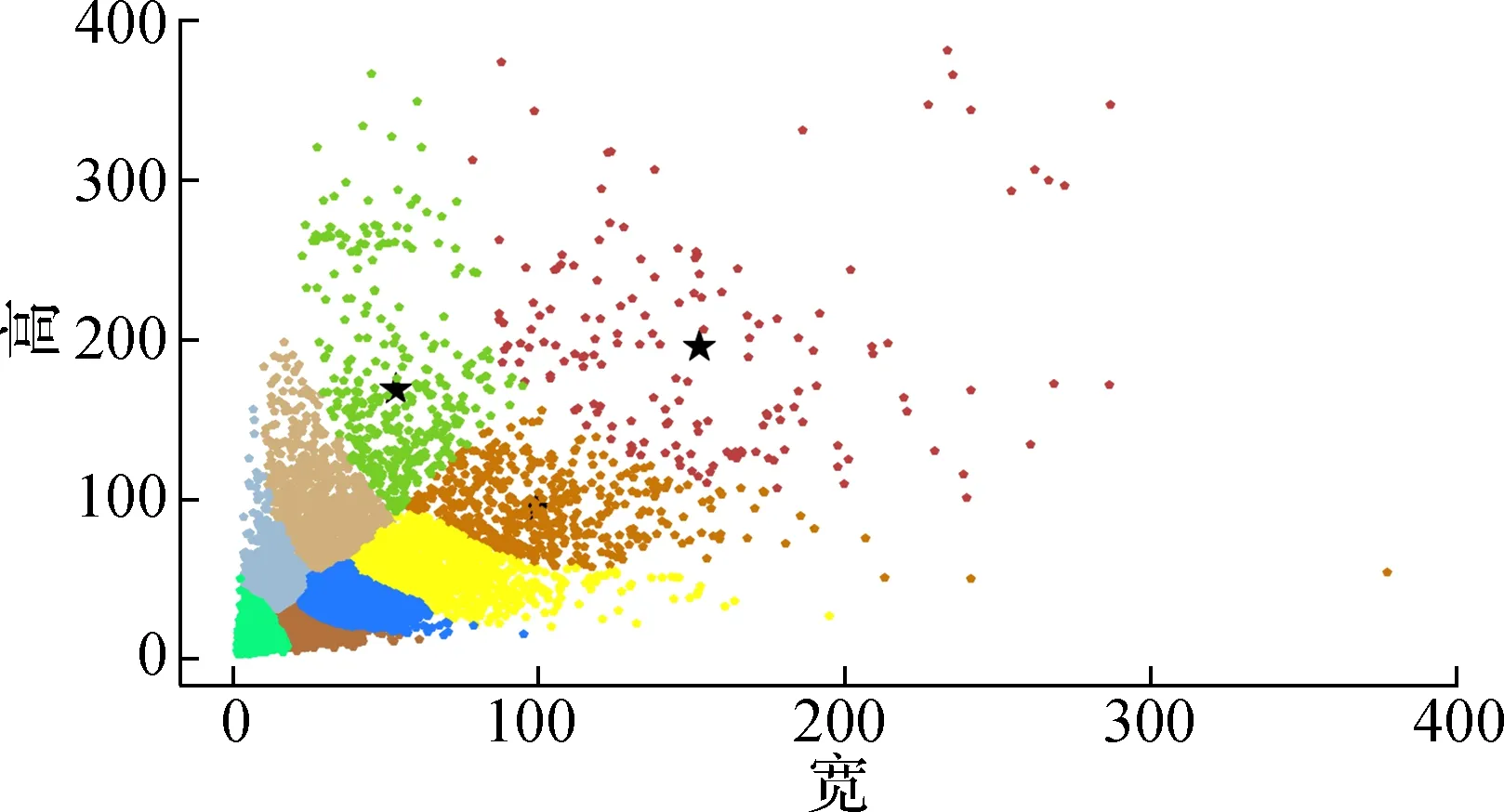
图2 聚类结果散点图
1.2.2 改善预测层的损失函数
YOLO v3用损失函数(loss function)的大小来表示训练模型的好坏,通过不断训练迭代来降低损失函数、提高模型精度.YOLO v3的损失函数采用误差的平方和,主要包括预测框与真实框之间定位误差(预测框是计算机根据训练出来的模型框选出真实图片中的目标,真实框是通过人工对图片进行标注的框)、有无目标的IoU误差以及检测物体类别误差,公式为:
loss(object)YOLO v3=lossbbox+losscla+lossconf
(2)
式中:lossbbox为边界框运用均方误差;losscla为类别运用交叉熵;lossconf为置信度运用交叉熵.
(3)
(4)
(5)

公式中先验框的坐标误差包含预测框与真实框的中心误差与宽高坐标误差.当第i个网格的第j个锚框负责某一个真实目标时,这个锚框所产生的先验框应该和真实目标框进行比较,计算得到宽高的误差.但是这会产生两个问题:1) 当预测框和目标框不相交时,IoU=0,无法反应两个框距离的远近,此时损失函数不可导,梯度无法回传,IoU_Loss无法优化两个框不相交的情况,如图3所示;2) 当两个预测框大小相同、两个IoU也相同时,IoU_Loss无法区分两者相交情况以及无法衡量两框的距离,如图4和图5所示.

图3 状态1

图4 状态2

图5 状态3
针对以上问题,本文采用完全交并比损失函数CIoU_Loss来进行改进.一个好的目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离、长宽比.其实就是为了解决如何最小化预测框和目标框之间的归一化距离、如何在预测框和目标框重叠时回归得更准确.CIoU_Loss考虑了重叠面积和中心点距离,当目标框包裹预测框的时候,直接度量2个框的距离,因此CIoU_Loss收敛得更快,同时CIoU_Loss考虑了预测框和目标框的长宽比,增加了一个影响因子,公式为:
LCIoU=1-IoU+ρ2(b,bgt)/c2+αν
(6)

从α参数的定义可以看出,损失函数会更加倾向于往重叠区域增多方向优化,尤其是IoU为0时.
1.2.3 改进预测层的nms函数
YOLO v3中的nms(non-maximun suppression)函数主要是解决一个目标被多次检测的问题,首先从所有的检测框中找到置信度最大的那个框,然后依次计算其与剩余框的IoU,如果其值大于一定阈值(重合度过高),那么就将该框的置信度归为0;确定各个框的类别,当其置信度值不为0时输出检测结果.但当两个物体靠得很近时,容易造成漏检,nms的阈值也不太容易确定,设置过小,易发生多框问题,设置过大,易发生漏检问题.
如图6所示,在工程车辆重叠在一起、IoU过大的情况下,使用该方法时预测框会被删除,导致漏检率上升.

图6 工程车辆数据图
针对以上问题,本文采用DIoU的非最大抑制法,抑制准则中不仅要考虑重叠区域,还要考虑两个盒子之间的中心点距离.对于得分最高的预测框M,中心点距离交并比非极大抑制DIoU_nms可以定义为:
(7)
式中:si为分类得分;ε为nms阈值;M为预测框中最高得分框;B={(Bn,Sn),n=1,…,N}.
通过同时考虑IoU和两个框中心点之间的距离来移除预测框.
2 试验
2.1 试验平台及数据集
试验平台及参数配置为:操作系统Centos 7,CPU Intel(R) Xeon(R) Glod5118 CPU@2.3 GHz,GPU GeForce RTX2080T,显存24 G,内存 128 G,框架 Darknet53,编程环境Python.
工程车辆数据原始图是由某公司提供,总计10 537张,其中起重机图片4 997张,挖掘机图片5 015张,叉车图片651张,混凝土浇灌车的图片587张,混凝土搅拌车图片397张,压路机图片169张,数据集类别及数量见表1.该数据集是来自不同环境、不同光照情况下的照片,存在图片太过模糊、整张图片色调过暗的问题,需要对该数据集进行数据清洗.本文使用图像无参考清晰度检测方法,将图片进行统一灰度化处理,利用scharr算子求得整张图像的梯度图,并对此进行叠加,对图像的整体模糊度进行判断,剔除较模糊的图片,使得网络训练有一个较优的模型.

表1 数据集类别及数量 张
图片预处理后,用LabelImg软件按照对应标签进行标注,标注完的信息以xml的格式保存在相同路径下.
2.2 性能评价
本文采用准确率(precision)和召回率(recall)[13]对算法的性能进行定量评估,精确率表示有多少目标被正确预测,召回率表示找到了多少目标,计算公式为:
Precision=TP/(TP+FP)
(8)
Recall=TP/(TP+FN)
(9)
式中:TP为所有被人工标注的工程车辆中正确地划分为工程车辆的个数;FP为图片中与工程车辆相似的目标被错误地划分为工程车辆的个数;FN为未被识别出的工程车辆的个数.
2.3 试验过程及结果
2.3.1 改进候选框
对于改进前后的候选框,在聚类后,采用相同的YOLO v3网络进行训练,并在测试集上进行测试.由表2可以看出,本文算法的平均准确率比原来提升了1.8%左右,各工程车辆均有不同程度的提升.这是由于算法改进了目标框的分布情况,更有利于网络的学习.
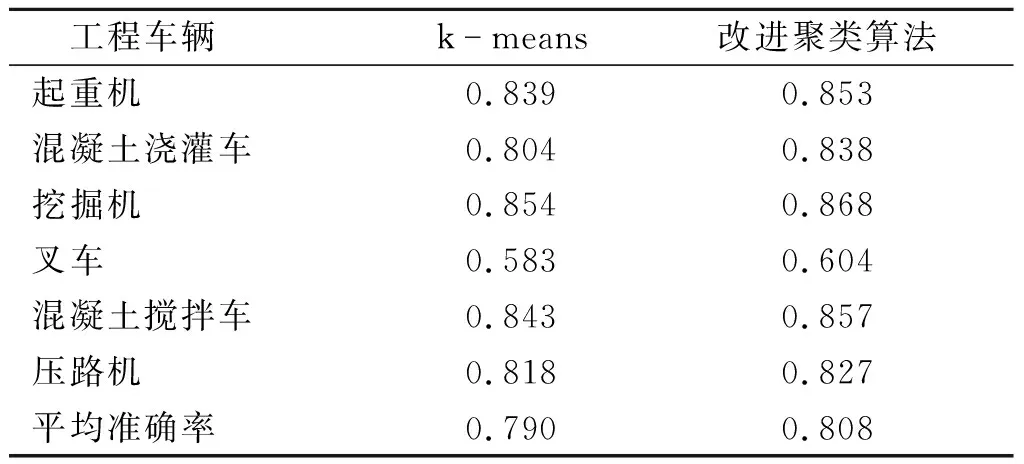
表2 聚类结果对比
2.3.2 网络训练
使用Darknet-53框架搭建网络,并在服务器上训练网络.将改进的YOLO v3和原始YOLO v3算法进行比较,为了公平性,本试验将对训练时的批尺寸、学习率、学习衰减率、迭代次数进行统一设置.将批尺寸batch设置为32、学习率设置为0.001,迭代到10 000次和20 000次时衰减,迭代总次数为24 000次.从图7中可以看出,将原来的二元交叉熵损失函数改为CIoU_Loss后,模型收敛性有了一定的提升,训练初期损失下降很快,随着迭代次数增加,大约在3 000次时趋于平稳,改进后的模型大约比改进前的模型快500个训练批次,最终网络的损失值约在1.1.

图7 损失函数曲线图
2.3.3 性能对比
以Darknet-53为基础的YOLO v3检测框架在处理图片时最快约50 ms处理一张图片,由于硬件差异和其他的图片预处理,检测速度可能会更慢.为验证本文改进网络的有效性,将YOLO v3和改进后的网络进行对比,改进后的网络由于改变了损失函数和采用非极大值抑制法,每张图片的处理时间由原120 ms增加到150 ms,增加了大约30 ms,可能是改变模块后增加了模型前向传播的时间,但图片的召回率提高了约10%,准确率提高了2%(见表3),网络的可靠性有了较大的提升.改进后的网络针对远处的小目标能够更好地提取特征并且改善检测效果,对工程车辆检测具有更好的泛化性.

表3 不同网络性能对比
图8为改进前后算法的实物检测结果,由图8可以看到改进后的算法更加贴合实际,准确度更高,是一种可行的电力通道实时检测方法.

(a) 改进前

(b) 改进后
3 结语
本文针对小尺度远距离工程车辆检测问题,提出基于改进YOLO v3算法的目标检测网络,将框交并比作为损失函数替代k-means聚类算法中的欧式距离,结合工程车辆真实框长宽之比约为3∶1或1∶1的特点,对候选框进行聚类;将损失函数中的坐标预测误差函数由原来的IoU_Loss改为CIoU_Loss,提高了模型检测率;将预测输出框的nms极大值抑制函数替换为DIoU_nms函数,很好地平衡了物体多框问题,降低了漏检率.试验结果表明本文提出的改进方法比原YOLO v3算法更能实现远距离小目标的检测,能够提升目标检测的准确度.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
新世纪智能(数学备考)(2021年9期)2021-11-24
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
小天使·二年级语数英综合(2019年10期)2019-11-08
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
共产党员(辽宁)(2015年2期)2015-12-06
