
基于深度学习的多步预测方法在太阳风速度预测上的应用
2021-07-13 07:46:52毛凯舟谢宗霞孙彦茹刘梓璇
航天器环境工程 2021年3期
毛凯舟,谢宗霞,孙彦茹,刘梓璇
(天津大学智能与计算学部,天津 300350)
0 引言
恶劣空间天气对依赖于电磁环境的高科技系统具有重要影响。这些空间天气包括太阳耀斑、日冕物质抛射、太阳质子事件以及电子暴、地磁暴等由于太阳的剧烈活动引起的短时间尺度的变化。在太阳系内,空间天气受到太阳风的巨大影响。
太阳风是一种连续存在、来自太阳并以200~800 km/s的速度运动的高速带电粒子流,对人类的生产生活有着重要影响:当太阳风掠过地球时,会使电磁场发生变化,引起地磁暴、电离层暴,并影响通信,特别是短波通信;对地面的电力网、管道和其他大型结构发送强大元电荷,影响输电、输油、输气管线系统的安全;对卫星的安全运行也会产生影响;还可能引发火山爆发、地震灾害,等等。对近地环境太阳风状况进行可靠的预测,旨在减轻空间天气对人类生产生活的影响,保证近地空间区域的航天活动安全,导航与无线电系统的正常工作,以及地面重要电力网络系统的安全。
目前,对太阳风的各项参数进行预测的技术和方法主要可以分为3类:1)基于物理的磁流体动力学(Magnetohydro-dynamics,MHD)模型的方法,通过检测太阳表面日冕面积的大小,判断当前的太阳状态[1-4];2)基于人工观测的方法,由大量的观测员对太阳的活动进行实时监测,通过他们的经验知识对太阳每个时刻的状态进行判断[5-7];3)机器学习方法,采用支持向量机(support vector machine,SVM),由人工神经网络(artificial neural network,ANN)对数据进行训练来判断太阳状态。
由于太阳活动的复杂性和灾害性空间天气事件预报时效性的迫切需求,需要寻找不同于传统MHD模型与经验模型的处理途径,ANN方法正是能够适应新需求的一种技术手段。Liu D D等[8]使用SVM算法预测了太阳风速度,但他们的预测仅能提前3 h。Wintoft 等[9]开发了一种结合半经验PFSS模型和ANN 的混合智能系统,可以预测太阳风的日平均速度。Jones等[10]研究发现,使用基于图像的信息可以改善全球日冕磁场模型。2018年,杨易和沈芳等[11]开发了一种基于ANN技术的、利用更多观测数据驱动的近地太阳风速度预报模型,称为Hybrid Intelligent Source Surface(HISS)模型;他们对该模型2007年—2016年(包含1个完整太阳活动周的极小、上升、极大、下降全部4 个活动相)太阳风速度的计算结果与近地观测数据进行了比较以及误差分析和高速流事件分析,结果显示模型计算结果与观测数据较为一致。Upendran 等[12]使用预训练的ConvNet 网络结合LSTM网络开发出优于基准持久模型和自回归模型的ANN模型。
本文希望基于ANN 方法,利用多步预测思想进行太阳风速度预测,拟使用多元时间序列数据,并基于长短时记忆(long short-term memory networks,LSTM)网络开发单一LSTM模型、编解码器LSTM模型和CNN-LSTM 编解码器模型3种深度学习预测模型,用以对未来24、48、72、96 h 的太阳风速度进行预测。对于每种模型,除了直接对目标时间点进行预测,还引入多步预测的方法对包含目标时间点的连续多个时间步进行预测。
1 多元时间序列数据及评价指标
1.1 数据选择
1.1.1 时间序列数据
NASA 发布的OMNI数据集(https://omniweb.gsfc.nasa.gov/index.html)包括:
1)低分辨率OMNI(low resolution OMNI, LRO)数据,包括每小时的近地太阳风磁场、等离子体数据,高能质子(能量超过1~60 MeV)通量,以及地磁和太阳活动指数等。除每小时分辨率外,LRO数据还有每日和每27天2种分辨率。
2)高分辨率OMNI(high resolution OMNI)数据,包括1 min 和5 min 的地球弓形激波鼻处的太阳风磁场和等离子体数据,以及地磁活动指数等。
本文选用的数据集为2011年—2017年、分辨率为1 h 的LRO数据集,包含小时分辨率的太阳风磁场和等离子体数据。这些数据来自日地拉格朗日点1(L1)附近轨道上的许多航天器观测数据。
预测模型的目标输出是在L1处的每小时平均太阳风速度。由于每小时的风速变化不大,所以使用每小时平均值,并且平均值的变化表明了风速值的不确定性。在OMNIWEB档案库中(可在https://omniweb上在线获得),将变化量(或标准偏差σ)计算为1天中每小时测量的变化量。
1.1.2 图像数据
太阳动力学天文台(Solar Dynamics Observatory,SDO)是NASA 的“与星共栖”(LWS)计划发起的第一个任务,旨在了解太阳变化的原因及其对地球的影响。SDO通过在小范围的时空和同时在多个波长下研究太阳大气来了解太阳对地球和近地空间的影响,其目标是通过确定太阳磁场的产生和结构方式以及如何将存储的磁能转换并释放到日光层和地球空间中,来理解太阳活动(包括太阳风、高能粒子和太阳辐照度等变化)及其对空间天气的影响,并推动对空间天气的预测。
SDO任务搭载了大气成像组件(AIA)、EUV 可变性实验(EVE)、地震和磁成像仪(HMI)3个科学载荷。这3台仪器将同时观测太阳,覆盖了解太阳变化所需的整个测量范围,以期测量表征太阳如何变化以及为什么变化。
AIA 是一个四望远镜阵列,可观测可见光、UV 和EUV 波长下的整个太阳,对多种波长的太阳大气成像,以将太阳表面变化与其内部变化联系起来。由SDO整理的机器学习数据集(以下称为SDOML)已公开可用,其中的AIA 图像已被重新采样到512×512像素的网格上,并以Python NumPy格式存储为二进制数组,数据每10 s包含10 个波长的太阳图像。本文的训练和测试数据包括每小时UTC拍摄的AIA 太阳图像(见图1),所选图像构成了整个观察时间的代表;如果不存在该小时处的图像(很多天都是这种情况),则将当天最接近此时间点的图像用作该小时图像的代替。

图1 AIA 太阳图像数据Fig.1 AIA solar image data
1.2 数据预处理
1.2.1 输入特征
1)引入冕洞特征——将0131波段的AIA 太阳表面图像转换为灰度图,计算图中像素值小于15的像素值之和,代表冕洞的影响,记为area。
2)引入行星际日冕物质抛射(interplanetary coronal massejection,ICME)因素——将ICME列表二值化为一个新特征,有日冕物质抛射事件对应时刻的特征值为1,其他时刻特征值为0。
3)除了area、ICME 事件之外,选择5个影响因素一起作为输入——bulk speed(历史太阳风速度)、proton density(质子密度)、proton temperature(质子温度)、flow pressure(流压力)和σB(场矢量的均方根标准偏差)。其中σB是由分量平均值的标准偏差形成的向量的长度,即
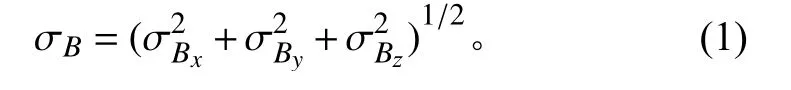
1.2.2 异常值处理
1)对于数据中存在的异常值,采用三阶B样条曲线插值的方法进行填充。B样条曲线的总方程为

式中:Pi为控制曲线的特征点;Fi,k(t)为k阶B样条基函数。
三阶B样条曲线方程中的基函数为
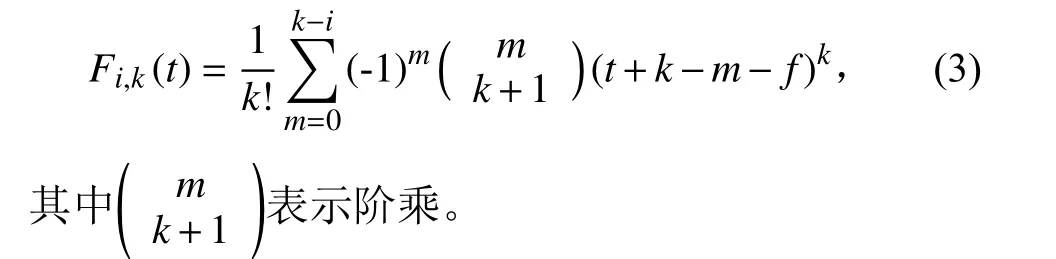
2)图像的异常值处理——图像的异常值多为缺失或者拍摄不清晰,可采用高频率数据集中临近时间的图像作为代替补充。
1.3 数据标准化
不同评价指标往往具有不同的量纲,不利于数据分析。为此,需要进行数据标准化处理,使不同数据指标间具有可比性;且原始数据经过标准化处理后,可使各指标处于同一数量级,便于进行综合对比评价。
本文的数据标准化采用了标准差标准化,根据原始数据的均值和标准差进行数据标准化,经过处理的数据符合标准正态分布,即均值为0,方差为1。标准化处理公式为

式中:x*和x分别为标准化的数据和原始数据;μ为所有样本数据的均值;σ为所有样本数据的标准差,计算时对每个属性/每列分别进行。
1.4 数据集划分
本文实验采用2011年—2017年的数据,其中,2011年—2015年的数据作为训练集,共有43 824个;2016年的数据作为验证集,共有8784个;2017年的数据作为测试集,共有8760个。数据构建完成后的结构如表1所示。

表1 太阳风时间序列数据集划分Table 1 Partitioning of the solar wind time series data sets
1.5 评价指标
为明确量化拟合的优劣,定义了3个指标来评估拟合优度——均方根误差(RMSE)、平均绝对误差(MAE)和相关系数(CC)。它们的定义如下:

这些指标从不同的角度评估模型,RMSE 和MAE表征测量误差,CC表征模型预测速度和观测速度之间的拟合程度。因此,RMSE 和MAE 越小,CC越大,则表明预测效果越好。
2 预测方法
2.1 多步预测
多步预测又称为长期预测,其含义是运用历史的时间序列[y1,···,yn]预测之后的t步序列[ym+1,···,ym+t],其中:n表示已观测数据的个数;m是≥n的一个时间点;t>1,表示预测范围。多步预测方法的有效性已在机器学习领域得到验证以及快速发展和完善[13-18]。
本文将多步预测的思想应用于太阳风速度预测,并采用一种较好的策略——多目标输出的多步预测策略,进行后续的建模和实验,遍历时间步并将数据划分为重叠的窗口,每次迭代都前进1个时间步,并预测包含目标时间点的连续多个时间步的太阳风速度。该方法的单步预测和多步预测模型的输入和输出可以表示为

相比于单步预测,采用多步预测的方法在模型训练过程中添加了输出端太阳风速度的连续变化信息,在预测过程中携带了目标时间步之前的预测信息。因此,我们预期多步预测能够实现更好的预测效果。
2.2 基于LSTM神经网络的太阳风速度预测模型
循环神经网络(recurrent neural networks,RNN)用前一个时间步的输出作为其后续时间步的输入,允许模型根据当前时间步的输入和前一个时间步的输出的直接知识来共同决定模型下一步的操作。
LSTM神经网络可能是一种最成功、应用最广泛的RNN。LSTM神经网络克服了RNN 所面临的长依赖关系,得到了稳定可靠的模型;除了利用前一个时间步的输出的循环连接之外,LSTM 神经网络还有一个内部存储,其操作类似于一个局部变量,允许它们在输入序列上累积状态。因此,当涉及多步时间序列预测时,LSTM神经网络具备很多优势:1)LSTM 神经网络是一种循环网络,被设计成以序列数据作为输入,不同于其他必须以滞后观测作为输入特征的模型。2)LSTM神经网络直接支持多元输入的多个并行输入序列,而不像其他模型中多元输入以扁平结构表示。3)与其他神经网络一样,LSTM 神经网络能够将输入数据直接映射到一个可能表示多个输出时间步长的输出向量。
下面介绍本文基于LSTM神经网络构建的3种预测模型。
2.2.1 单一LSTM模型
单一LSTM 模型使用1个普通的LSTM层,以20个LSTM 神经元作为参数;LSTM 层之后经过1 个dropout 层减小模型的过拟合;然后是1个具有10个节点的全连接层(dense_1),用于解释LSTM层习得的特性;最后,以另1个全连接层(dense_2)作为输出层,用于直接输出1个预测向量,该向量的维度与训练输出的维度一致,在输出序列中每个时间步对应1个元素。图2展示了24 h 多步预测实验中连续5步预测所用的单一LSTM 模型结构。

图2 单一LSTM 模型结构Fig.2 Structure of the single LSTM model
2.2.2 编解码器LSTM 模型
编解码器LSTM模型由2个子模型组成——用于读取和编码输入序列的编码器;读取编码的输入序列并对输出序列中的每个元素进行1步预测的解码器。该模型首先定义1个包含20个单元的LSTM 层(lstm_1)作为编码器模型,用于读取输入序列并输出1个包含20个元素的向量(每个单元1 个输出),以便从输入序列中获取特征信息;然后,对输入序列的内部表示进行多次重复,对于输出序列中的每个时间步重复1次,这个向量序列将被呈现给LSTM解码器;之后,使用repeat vector 将编码器的输出序列的最后1个作为内部表示复制N份,作为LSTM 解码器的N次输入(N代表N步预测);定义另1个包含20个单元的LSTM层(lstm_2)作为解码器,输出整个序列而不仅仅是输出序列的末尾;经过dropout 层后,使用全连接层(dense_1和dense_2)来解释解码器输出序列中的每个时间步长,并输出预测。这意味着须对输出序列中的每个步骤使用相同的层。为了实现这一点,将解释层和输出层封装在1个time_distributed 包装器中,该包装器允许解码器每次执行操作时都使用所封装的层。图3展示了24 h 多步预测实验中连续5步预测所用的编解码器LSTM 模型结构。
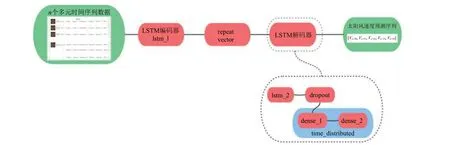
图3 编解码器LSTM 模型结构Fig.3 Structure of the codec LSTM model
2.2.3 CNN-LSTM 编解码器模型
本文将使用CNN 和LSTM的混合模型称为CNN-LSTM编解码器模型。该模型以一维CNN作为编解码器结构中的编码器,能够直接支持序列输入并自动学习显著特征;使用LSTM解码器解释这些特征。CNN-LSTM编解码器模型将编码器定义为一个简单而有效的CNN 架构,由2个卷积层(convld_1和convld_2)以及1个最大池化层(max_pooling ld)组成,然后将结果扁平化(flatten)。第1个卷积层读取输入序列并将结果投射到特征图上;第2个卷积层对第1层创建的特征图执行相同的操作,以期放大所有显著的特征。每个卷积层使用16个特征图,读取卷积核大小为3个时间步长的输入序列。最大池化层通过保留最大信号值的1/4来简化特征映射。在池化层之后提取的特征映射被扁平化为一个长向量,可以用作解码器的输入。解码器与编解码器LSTM模型定义的解码器相同。图4展示了24 h 多步预测实验中连续5步预测所用的CNN-LSTM 编解码器模型结构。
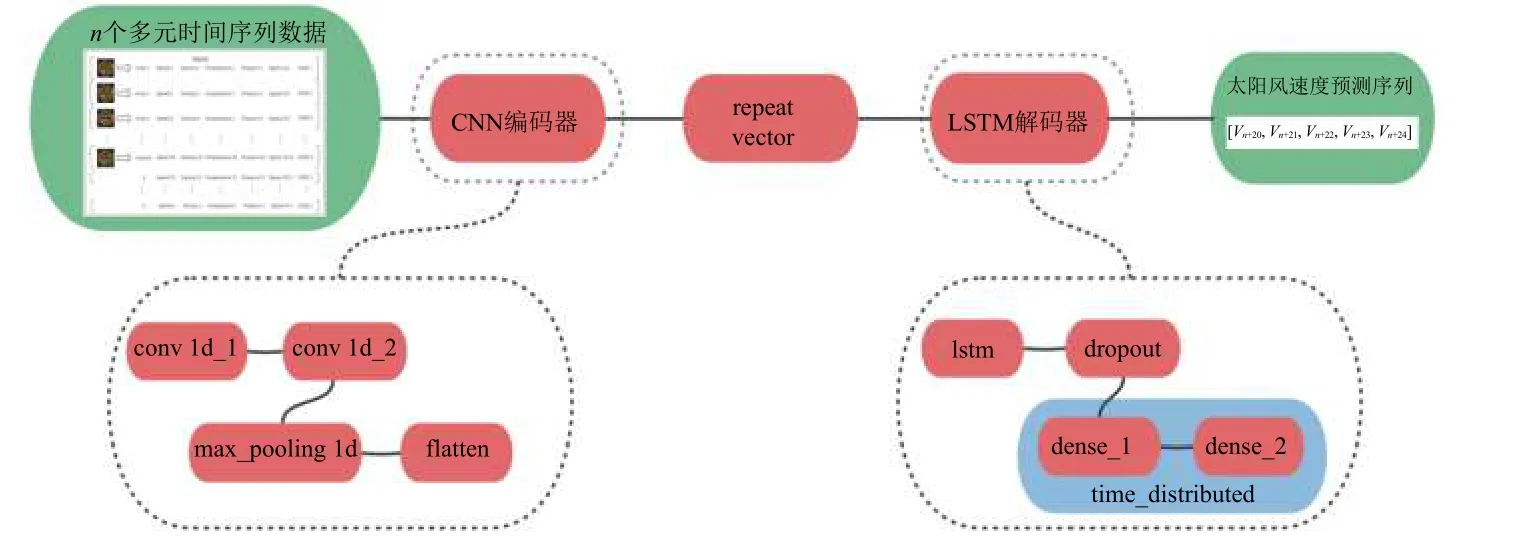
图4 CNN-LSTM 编解码器模型结构Fig.4 Structure of the CNN-LSTM codec model
3 预测实验结果分析
本文使用2.2节所述的3种模型对未来24、48、72、96 h 的太阳风速度进行预测;并且对于每个预测时间点和每种模型,分别进行单步预测和多步预测实验。在单步预测中,一系列训练输入对应未来T时间步后的1个训练输出;在N步预测中,一系列训练输入对应未来连续N个训练输出VT-N+1,VT-N+2,…,VT。每个预测时间点和每种模型的实验重复3次,记录下最优结果。
24 h 预测的实验结果如表2所示,多步预测为5步预测。为了说明模型的有效性,以24 h 持久模型作为基准模型——预测结果为24 h 之前的太阳风速度。从实验结果可以看出,3种模型都显示了较好的预测性能,且均表现为多步预测效果优于单步预测效果。这可以归因于多步预测携带了目标时间步之前的预测信息。3种模型中,最简单的单一LSTM 模型的预测效果最佳,其多步预测结果与观测数据的相关系数为0.789,RMSE 为62.469 km/s,MAE为46.476 km/s。

表2 24 h预测实验结果Table 2 Predicted experimental results at 24 h
48 h 预测的实验结果如表3所示,多步预测为5步预测,3种模型均表现为多步预测效果优于单步预测效果,其中编解码器LSTM 模型的预测效果最佳,其多步预测结果与观测数据的相关系数为0.522,RMSE为87.310 km/s,MAE 为67.976 km/s。
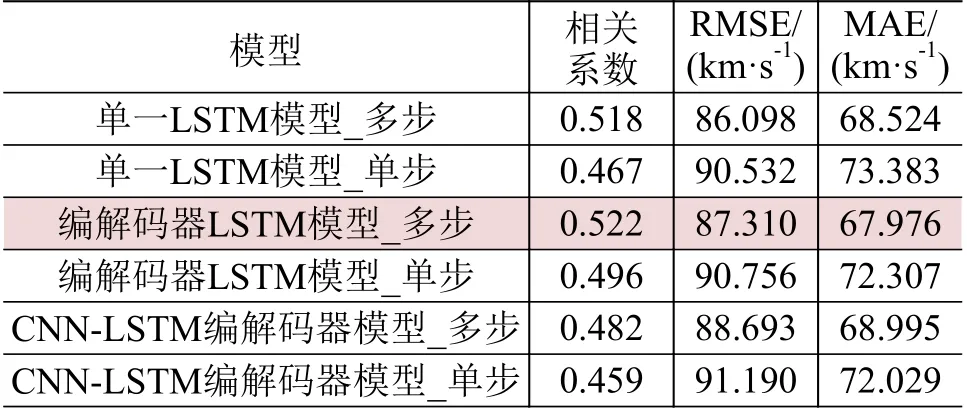
表3 48 h预测实验结果Table 3 Predicted experimental resultsat 48 h
72 h 和96 h 预测的实验中,为了避免预测步长过大,对数据的尺度进行放大,由原先每小时1个数据改为每天(24 h)1个数据,取每天00:00时的数据进行训练和预测。这种情况下,多步预测为3步预测。72 h 和96 h 预测的实验结果分别如表4和表5所示。从实验结果可以看出:3种模型均表现为多步预测效果优于单步预测效果;对于远期的预测,CNN-LSTM 编解码器模型依然有效,且预测效果最佳,而单一LSTM模型和编解码器LSTM模型的预测效果急剧下降。其原因是,在远期的预测中CNN 对于数据特征的提取依然可靠有效。CNNLSTM编解码器模型72 h 的多步预测结果与观测数据的相关系数为0.519,RMSE 为89.493 km/s,MAE 为72.556 km/s;96 h 的多步预测结果与观测数据的相关系数为0.428,RMSE 为93.924 km/s,MAE为75.605 km/s。

表4 72 h预测实验结果Table 4 Predicted experimental resultsat 72 h
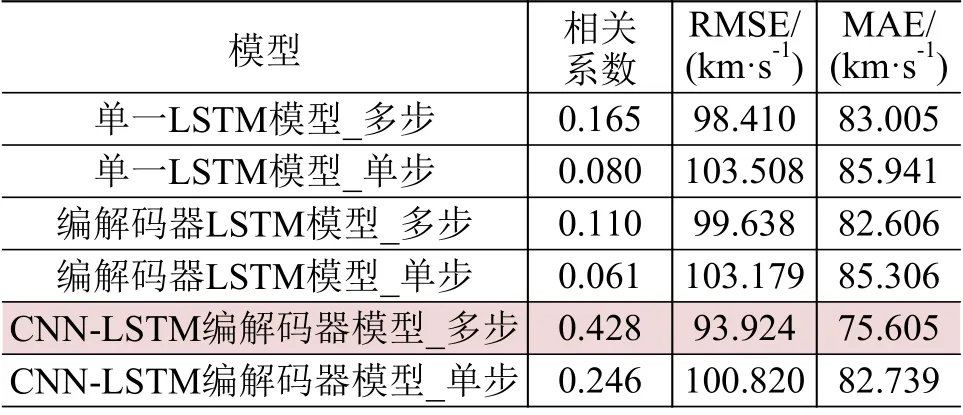
表5 96 h预测实验结果Table 5 Predicted experimental results at 96 h
4 结束语
本文采用深度学习的方法,根据多元时间序列数据来预测在太阳与地球之间的拉格朗日点1(L1)处的太阳风速度;基于LSTM 开发了3种深度学习预测模型——单一LSTM 模型、编解码器LSTM 模型和CNN-LSTM编解码器模型;并使用这3种模型对未来24、48、72、96 h 的太阳风速度进行预测。对于每种模型,除了直接对目标时间点进行预测,还引入多步预测的方法,对包含目标时间点的连续多个时间步进行预测。实验结果表明,每种模型的多步预测效果均优于单步预测效果。
将来,深度学习和多步预测的方法可能会帮助我们发现太阳物理学中的新关系,或者进一步提高太阳风速度的预测精度,支持建立有效的空间天气预报体系。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
空间科学学报(2020年3期)2020-07-24 09:23:00
空间科学学报(2020年6期)2020-07-21 05:36:32
家庭影院技术(2019年8期)2019-12-04 14:43:19
学苑创造·A版(2017年4期)2017-05-13 22:56:06
初中生学习·高(2015年9期)2015-09-28 17:52:06
太空探索(2015年5期)2015-07-12 12:52:26
小天使·一年级语数英综合(2015年8期)2015-07-06 06:28:12
