
一种从网络报文中提取特定信息的方法
2021-07-12 10:54:25景阳
电子乐园·下旬刊 2021年4期
景阳
摘要:从网络报文中获取用户关注的特定信息,是一项很重要且极具意义的工作。在网络信息监控、安全防御系统中,经常需要从报文中,按照使用者指定的内容提取某些信息。目前这项工作面临的主要挑战是:针对不同的用户需求,需要提取的内容及格式不一样,如何在低耗时、低开发成本的情况下,快速、准确的找到要提取的信息的位置,并用合适的方式提取出来。本文提出了一种基于规则编写的报文特定信息提取方法,可以使报文分析人员与信息提取人员工作解耦合,并且可以达到避免大量重复工作的效果,来快速的相应市场需求。
关键字:网络安全;报文特征分析;报文特定信息提取;账号信息提取;规则编制;规则匹配
引言
随着互联网技术的发展,一方面,维护网络安全变的越来越重要,另一方面,人们对网络安全意识也越来越强。所以目前在大多数局域网、企业网中,人们越来越注意保护互联网使用者的个人信息。比如,某些公司从数据安全方面考虑,会希望传入运营商网络的数据是经过重要信息脱敏处理的。信息脱敏指的是,一些私人信息,或者公司层重要的数据,在传入外网的时候被删除或者打上马赛克等等。另外,可能还有一些特殊场景下,需要监控一些常用软件的账号信息,从而关联查找其他下联信息等等。上述所有这些类似的用户需求,抽象出来就是要在网络流量中按照使用者需要提取到特定的信息,在提取到这些特定信息的基础上,再对这些信息做其他处理。所以对于做网络安全设备、网络监控设备的厂商来说,需要解决的问题就是如何快速、有效的按照用户指定需求,从网络报文中提取特定信息。
相关工作
对于上文提出的从报文中提取指定信息的问题,我们从学术界和厂商实现两个角度来说明一些方法及观点。首先,在学术界,对于流量分析、流量识别、流量特征提取等方面,目前比较火的方法是机器学习和深度学习[1-2]。近几年学者们在这方面确实取得了获得成果,但是从实际效果来看,应用到生产实践中的效果并不是特别理想。主要体现在,在实验室条件下,即在给定的数据集中学习、验证,给出的效果往往很好,准确率可以达到95%以上,但是这些方法用在现网流量中准确率却很差。主要原因有两点:一是,现网流量复杂,对一些机器学习方法的临界值的冲击非常大,导致算法准确度下降;二是,实验用的数据集更新太慢,这主要是数据集的搜集、制作过程太费时导致的,由于更新速度较慢的数据集无法对应目前急速变化的现网变化,导致基于古老数据集的算法在现网流量中准确度下降。所以在学术界虽然已经有了很多先进的方法,但是距离真正生产实用还是有点差距的,并且更新换代较慢。其次,在厂商实现上,目前就是私有协议研发与各种网络安全设备厂商之间的博弈过程。具体来说就是:一方面,协议应用方发现自己的协议在使用过程中被各种监控软件、黑客越来越方便的获取关键信息,所以对私有协议做升级、变形等;而另一方面,安全设备厂商发现原有方法检查率下降,就会重新研发适配,即一直在对软件系统升级,来是配更新了的私有协议[3-4]。这样使得两者之间的博弈始终存在,并且进程不断加快,导致网络流量复杂度提升速度也越来越快。综上所述,私有协议研发与各种网络安全设备厂商之间的博弈过程,加剧了网络流量向越来越复杂的方向演进,而学术研究方面,往往需要很长的周期才能做到很好的适配。所以,在具有针对性需求的网络流量特征提取方法上,我们更倾向于采用生产实践中的方法去快速的追逐不断变换的市场需求,虽然有的方法比较耗时耗力的,但是却更能快速的解决来源于实际中的问题。
在实际应用中,目前大多数安全设备厂商,在对流量中指定信息做位置定位和信息提取的时候,采取的方法都很传统,基本方法如下:第一步,先让用户给出需要从报文中提取的内容。第二步,拿回来做分析,先在网络上大量截获相关的报文,然按照用户需求对指定类型的报文或者某些私有协议做分析。第三步,对照分析结果做编码实现。第四步,不断丰富信息提取库,即始终在维护这些类型的报文的特征提取需求,不断跟某种协议的不同版本、不同应用的各类信息,这是目前最耗时耗力的部分。当前的处理方式虽然普遍且适应市场需求更快,但是有如下缺点:第一,做具体报文分析的人员,与按照分析结果做编码实现的人员,一般情况下是两批工程师,那么他们的工作就有非常强的耦合性,这种耦合性会对他们的工作产生影响。第二,市场环境下,只要客户需求稍微一变化,则上面提到的一至四歩就需要重新做一遍,非常耗时耗力,并且有时候对开发者来说这种需求变更是灾难性的。第三,现网中应用协议类型在不断增加,需要提取的信息的种类也在不断的增加,这样会使网络安全设备的负担越来越重,因为像这种程度的报文解析及信息提取,都是基于每个报文的,并且要从大段的报文内容中查找多次才结束的,所以對安全设备性能的冲击非常大。
针对上述生产实践中的实际问题,我们本着解工作耦合性、降低重复工作量、减少内容查找次数的原则,提出了一种从报文中提取特定信息方法。具体方法见下面章节。
我们的解决方法
我们提出的针对网络报文中特定信息的提取方法,包含两个部分:第一部分,用通用的规则文件给出从报文中提取信息的方法,即用给定的规则文件的格式,将要提取的信息所在位置、偏移量、长度等等信息表达出来。这部分工作一般由协议分析人员按用户要求来完成。第二部分,按照生成的规则文件,使用优化的算法,将特征信息提取出来。而这部分工作一般由信息提取人员,按照通用规则文件格式来编码实现,此过程只需要关注提取方法的本身,而不需要关注具体报文格式。这样就使报文分析人员和信息提取人员的工作完全解分开了。一方面,报文分析人员可以通过各种手段,比如人工分析、写网络爬虫等等,来编写规则文件。另一方面,信息提取人员只需要关注规则文件,使用合适的算法,将文件中的规则转换成有效的报文提取方法。这样使得特征信息提取工作,在规则文件层完全解耦合,并使得所有工作极具有通用性,又具有特殊性,给了开发人员极大的发挥空间。不难看出,上述工作中最重要的就是规则编制方式,因为它涉及到易用性和信息匹配、查找性能等。下面我们以实践中用到的应用软件账号信息提取为例[5],来说明我们的规则设置方式,及规则解析、信息提取方式。而其他的信息的提取需要在用户需求和实践中不断丰富进来,我们的规则设置和解析中也已经预留了其他信息提取的接口。
规则文件设置
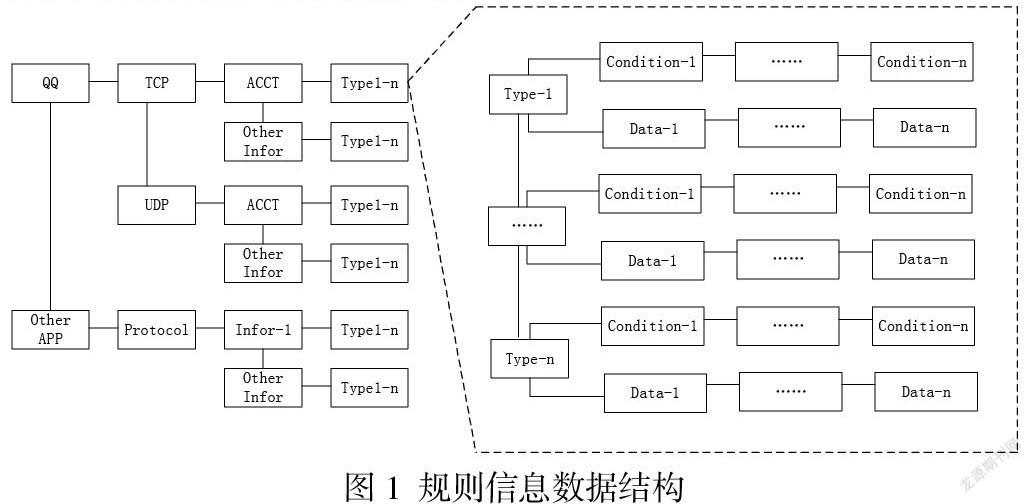
对于应用软件的账号信息提取,规则文件方面我们使用的是xml格式的文件,下面简称“规则文件”,规则设置的具体信息如下。首先,我们将规则文件分为了几个层次,用来表示报文的分类、信息提取条件、信息提取位置等信息。具体表现为:第一层是应用名称信息设置。比如我们要对腾讯QQ应用来提取账号信息,则用xml文件的<QQ></QQ>表示应用名称为腾讯QQ应用。第二层是为应用设置的编号。设置编号的目的是方面信息映射及查找,比如同样是腾讯QQ应用,我们为他设置的编号是1,则用xml文件的<APP-ID>1</APP-ID>格式表示。第三层是传输层协议分类。如用<TCP></TCP>表示传输层协议为TCP。第四层是我们人为划分的要提取的信息的类型。如使用<ACCT></ACCT>表示要提取的信息类型为应用的私人账号信息。第五层是具体的信息提取方式。因为信息提取方式可以有多种,所以我们用不同的<type></type>中的内容来表示不同的提取方式。比如,在账号信息中用<type value="1">表示提取账号的第一种方式,<type value="2">表示提取账号的第二种方式等等。第六层是提取信息的条件和信息所在位置。我们用<condition>节点表示报文需要满足的条件,后续我们将此节点称为“條件节点”。用<data>节点表示信息所在位置,后续我们将此节点称为“数据节点”。这两种节点组合使用的意思就是“满足某种条件的报文需要在什么位置获取到指定的信息”,这是我们提供的这套方法的最关键的点。然后条件节点和数据节点的下级中有设置的各种匹配参数,这些参数有通用的和特殊的两种,通用的用来描述共性问题,特殊的用来描述个性问题。所以一般情况下通用参数可以用来描述大部分匹配条件,只有当报文比价特殊时才会增加适配特殊参数。因此我们的系统使用了通用参数的性质来避免重复工作量,使用特殊参数来增补规则的差异性。下面我们给出一个简单的规则文件示例。
<QQ>
<ID>1</ID>
<TCP> <ACCT> <type value="1"> <condition value="1"> <port> <start>80</start> <end>80</end> </port> <http_request_method>GET</http_request_method> <string_match> <http_host>qq.com</http_host> </string_match> </condition> <data value="1"> <http_cookie> <string_data value="1"> <string>uin_cookie=</string> <end_char value="1">;</end_char> <end_char value="3338">\r\n</end_char> <isnum>yes</isnum> </string_data> </http_cookie> </data> </type> </ACCT>
</TCP>
</QQ>
规则信息管理
对上述规则文件的保存和使用,我们采用哈希表做的管理。方便后续的条件匹配和信息提取操作。首先,以第五层的节点为一个结构体节点保存起来,其中需要包含其上各个层级的所有信息,然后用链表链接起来。然后,对含有字符串规则的条件节点做单独管理,提前使用HS算法或AC算法做预编译,这是为了使用字符串快速匹配算法做准备。节点对应的结构体节点,用哈希表链接起来。最后,再对数据节点中含有字符串的节点做单独管理,也是提前使用HS算法或AC算法做预编译。这样就生成了基于规则文件的一套信息管理方式。结构图见下。
报文匹配及信息提取
我们采用的信息提取方法是先比对条件在决定是否需要去提取的方式,这样做的好处是避免盲目的信息提取操作,因为整个操作中耗时的就是信息提取操作。首先,对于条件信息比对,我们使用的是分步、分类的条件节点匹配的方法。我们在做条件信息比对的时候,将条件信息分为了两类,一类是非字符串信息,比如,端口号、http request方法等,此类信息比对速度很快;另一类是字符串信息比对,这类信息比对起来比较耗时。因此接收到网络报文之后,我会先解析所有的条件节点中的非字符串信息做对比,然后将匹配中的条件节点所在的上层节点信息打标记。然后对于打了标记的节点中条件节点中的字符串条件做多模匹配,然后再给所有条件都匹配中的条件节点及其上层节点打上条件匹配中的最终标记。然后,我们再对规则条件匹配中了的报文做信息提取操作,这里一般需要先采用字符串匹配操作定位到具体位置,然后再根据数据节点中的规则,获取某个长度的内容或者结束符以前的内容。此种方法的好处是:1、采用逐级匹配的方式,缩减耗时操作的数量;2、采用多模匹配一次性对所有字符串做匹配的方式,提升查找速度;3、采用先匹配条件再定位信息位置的方式,避免盲目查找、提取指定内容。
总结
上述网络报文特定信息提取方法,已经应用于生产实践中了,从易用性和效果方面来看都很好。此方法可以达到比较好的效果主要是因为如下原因:1、由于提供的很好的解耦合性,所以在实现中各个功能模块可以独立开发、分别优化,并且增加新的提取项或者支持新的私有协议时,通过很小的改动就可以快速实现客户需求。2、报文信息提取方便,对于报文分析人员来说,由于他们对某些特定的协议很熟悉了,所以即使这些私有协议有升级,他们也可以迅速获取到他们想要得到的信息,去丰富我们的规则文件。这相比机器学习等方法要来的更方便、更快捷,并且有的时候可以通过只修改规则文件就能迅速的支持某些特定需求。所以用起来更方便,还不需要做代码级修改,这是使用起来最方便的地方。但是我们的方法也有很多不足:1、由于私有协议研发与各种网络安全设备厂商之间的博弈,导致协议更新换代越来越快,则我们要支持的信息提取规则也会越来越多,然后导致我们的系统处理能力不断下降。2、我们的方法无法解决加密流量的信息提取问题。因此,后续我们还会继续在易用性及快速实现需求的基础上,针对协议规则扩充及系统性能提升,对我们的系统做改善、优化。一方面,在协议规则扩充方向上,不断的加入更智能的处理方式,比如在基于机器学习的流量识别、分类系统中增加对特定协议的升级版本的监控,然后再对监控到的需要的协议内容做特定信息提取等等,并且逐渐的使这些工作趋于自动化;另一方面,系统性能提升方向上,提供可以基于协议规则库扩张而可以动态扩展软件系统处理能力的软件框架等等。上述两个方面以及加密流量中的信息提取技术,都是我们下一步的研究方向。
参考文献
[1] Deep Learn. From: https://www.deeplearningbook.org/
[2] Scikit-learn. From: https://scikit-learn.org/
[3] nDPI. From:https://www.ntop.org/products/traffic-analysis/ntop/
[4] Suricata. from: https://suricata.io/
[5] 江苏省未来网络创新研究院. 一种从网络报文中提取账号信息的方法[P]. 发明专利, CN201811508719.0. 2018-12-11
猜你喜欢
汽车电器(2022年9期)2022-11-07 02:16:24
数学小灵通(1-2年级)(2021年11期)2021-12-02 01:30:08
派出所工作(2021年4期)2021-05-17 15:19:10
铁道通信信号(2020年4期)2020-09-21 09:15:24
中国外汇(2019年11期)2019-08-27 02:06:30
中国生殖健康(2019年10期)2019-01-07 01:21:04
信息安全研究(2018年12期)2018-12-29 11:01:46
小学生必读(中年级版)(2018年4期)2018-07-05 06:00:48
铁道通信信号(2016年8期)2016-06-01 12:10:21
CHIP新电脑(2016年3期)2016-03-10 14:52:50
