
基于时空特征的生猪动作识别
2021-07-11 13:59:04苏森陈春雨刘文龙李诚
应用科技 2021年4期
苏森,陈春雨,刘文龙,李诚
哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001
近些年,我国的养殖业、畜牧业发展十分迅速,无论是从养殖质量还是养殖结构,都在转型为现代畜牧业方向。行业共识已经发展为规模化,集约化。同时,高污染、高耗能的小规模散养方式逐渐褪去市场优势,最终将成为历史[1]。随着每年生猪出栏总数不断达到历史新高,至2018 年底,我国生猪全年产量已突破7.2 亿头,与2000 年比较,增速为41%[2]。然而,随着养殖产业向着更大规模发展,传统人工监控、投料、饲养已经无法满足养殖的高效性。现代的、科学的生猪养殖模式被逐步推广。通过观察了解圈养生猪的生活习惯,发现生猪的姿态、行为与其情绪以及健康状况都有一定的联系[3]。例如,当生猪出现长期趴卧、食欲不振、离群活动以及单独休息等一些异常情况时,极大可能表明该生猪出现了病情[4]。在传统的生猪养殖产业中,生猪病情主要靠饲养员自主观察判断。对于大规模的养殖场,这样的工作不仅耗费大量的人力,而且十分依赖于饲养员的个人素质和知识储备。即便如此,若想详细地了解每一头生猪的健康状态,仍然是一件非常困难的事情。养殖无人化是未来的大势所趋,对于生猪研究的最终目的是用机器代替人进行实时监控、预警甚至处理,因此对生猪行为动作的检测很有研究价值。王传哲等[5]通过可穿戴微惯性传感器采集4 类动作对应的加速度、角速度和姿态角共6 000 组数据,使用BP 神经网络对数据进行训练与推理。张聪[6]建立生猪体态12 种特征数据集,使用决策树支持向量机对特征进行分类。嵇杨培等[7]通过改进YOLOv2 神经网络识别生猪进食、饮水行为。
1 动作识别网络
目前,随着计算机硬件发展,尤其是图形处理器(graphics processing unit,GPU)等运算能力的提高,促进了深度学习的发展和应用。其中动作识别是一个热门的研究方向[8]。最常见的动作识别方法应用是将给定的视频通过卷积网络分类为确定的类别。然而实际应用中视频不仅存在多种类别的动作,还有复杂的干扰背景[9]。本文使用二维卷积神经网络(2D-CNN)提取空间特征,三维卷积神经网络(3D-CNN)提取时序特征,将空间特征、时序特征相融合,提出了一种分析生猪在视频中位置和运动状态的方法。
1.1 动作识别网络结构
本文采取的网络结构如图1 所示。
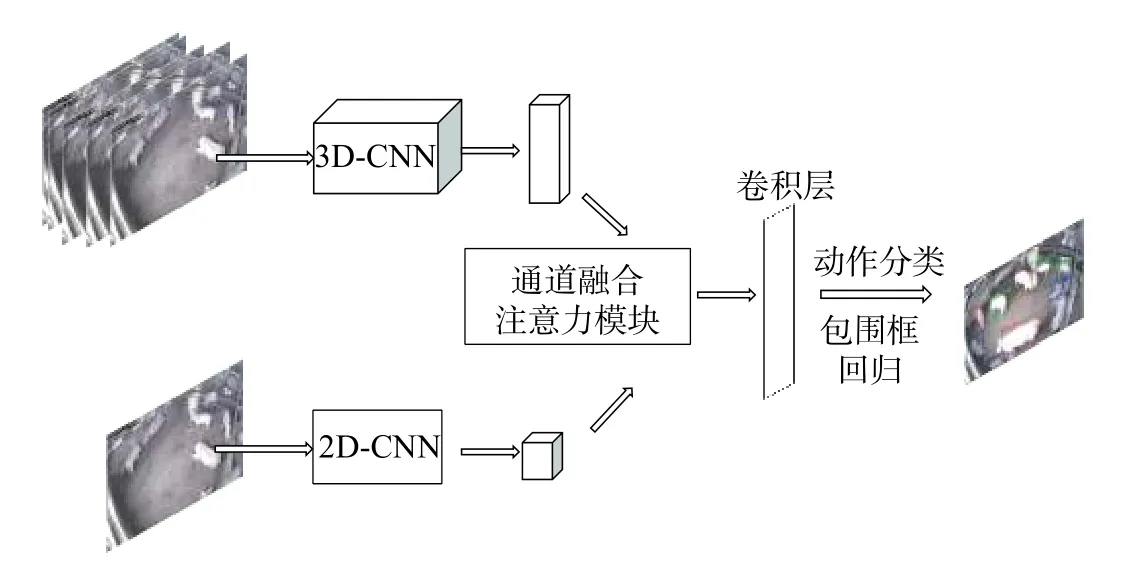
图1 本文提出的动作识别网络结构
整体设计在目标检测网络YOLOv2 的基础上,添加了1 路并行3D-CNN 支路提取时序特征信息,2D-CNN 提取空间位置信息。2 路特征融合时,使用通道注意力模块,使2 路特征进行充分的关联,最后通过一个卷积层得到边界框预测、分类的输出。
1.1.1 特征提取网络
由于时间序列信息对猪的行为理解十分重要,故本文网路结构使用3D-CNN 来提取时空特征。其计算过程如图2 所示。
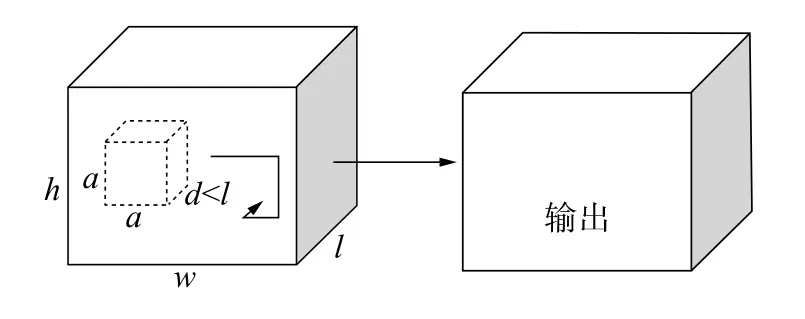
图2 3D-CNN 计算过程
采用连续视频帧数据提取特征时,将多帧数据拼接为一个数据长方体,同时卷积核也具有3 个维度,三维卷积核在数据长方体中有3 个滑动的方向,利用这种结构和计算方式,多个相邻帧的特征会映射到同一个输出,从而获得时序运动信息。并行3D 支路输入的是视频数据,如图1所示。在本文中3D 支路输入16 帧视频序列,在计算量方面,3D-CNN 相对2D-CNN 计算量较大,训练、推理耗时较长,所以本文3D-CNN 主干网络为3D-MobileNet。
2D-CNN 解决空间定位问题,视频序列最后一帧作为关键帧输入2D 支路,2D-CNN 计算过程如图3 所示。卷积核具有2 个维度,只在2 个方向上运动,可以提取二维图像中目标的特征。本文使用的主干网络为Darknet-19,能很好地平衡准确率和速率之间的关系。
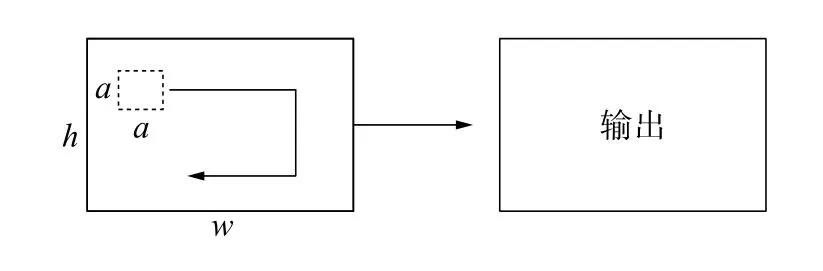
图3 2D-CNN 计算过程
1.1.2 通道注意力模块
为了使2D 支路和3D 支路的输出特征图平滑地融合,本文将3D-CNN 输出的特征图压缩一个维度,使其最后2 个维度和2D 支路输出相等,然后沿着通道方向将2 路特征图进行拼接。这2 路特征包含了位置空间信息和时序运动信息。但是这2 路特征没有进行很好地联系融合,故使用了通道注意力模块,这种注意机制有利于合理融合来自不同来源的特征,显著地提高了整体性能,通道注意力模块结构如图4 所示。

图4 通道注意力模块
图中B∈RC×H×W。
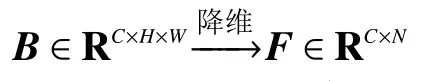
式中:C为通道数,H为特征图的高,W为特征图的宽。
通过将特征图B维度减少一维,变为矩阵F。然后对F与其转置FT进行矩阵积的操作:

得到矩阵G,它表示了不同通道的特征联系。G中每个元素表示每个通道特征向量化映射i和j之间的内积,具体表现形式为
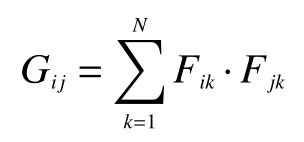
对矩阵G进行softmax 操作生成矩阵M,其中每个元素Mij是评判第j个通道对第i个通道影响的程度,所以矩阵M代表通道之间的联系程度:

使注意力模块与原始特征图相结合,将矩阵M与矩阵F进行矩阵乘法得到矩阵F′:
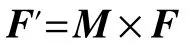
将矩阵F′增加一个维度与注意力模块原始输入特征图B维度相等:

原始输入特征图B与F′′相结合,α为可学习的参数,初始值为零:

输入特征图O的每个通道的特征是所有通道的特征和原始特征的加权和。这样的网络结构涉及到了所有通道的特征图,使2D 支路和3D 支路更加平滑且合理的融合,增强了特征识别的能力。
1.2 包围框回归和动作分类
本文采用了YOLOv2 目标检测算法进行动作的分类和包围框的回归[10],该方法是2016 年Redmon 等[11]提出的YOLO 目标检测算法的改进版本,算法在速度上大幅提升。该方法的缺点是小目标检测能力相对较弱。本文所使用的数据集中只对某一栏生猪进行检测,其体积相差不大,不存在小目标的情况,且监控视频需要在嵌入式设备中实时检测,所以本文使用的方法是基于YOLOv2 目标检测算法进行设计。
包围框回归与YOLOv2 方法遵循相同准则,对于网络输出特征图的每个网格,使用k-means算法在训练集聚类出5 个先验包围框,使网络最终输出的特征大小为[5×(Nc+5)×7×7],其中N代表数据集有Nc个动作类别,此外还有包围框4 个坐标和前景概率得分,根据所得这些参数对包围框回归与动作分类[12]。
包围框回归采用Smooth L1 损失函数,其对异常值敏感度较低,防止梯度爆炸。前景概率得分采用L2 损失函数,优点为收敛速度较快,加快了训练的时间。分类概率使用Focalloss 损失函数解决类别不平衡问题:

式中:y′为预测值;y为真实值;1 和0 分别为正例和负例;γ、α为权重影响因子,表示正例或负例对权重的影响程度,用来平衡样本不平衡的问题,需要预先设置参数。
样本越容易检出,则其贡献的损失就越少,同时,较难检测出的样本对于权重更新的比重就会变大[13]。
2 实验
2.1 生猪动作数据集
目前,关于生猪的动作姿态研究较少,相关公开数据集难以获得,所以本文的数据集通过采集某生猪养殖场真实数据,并通过人工标注的方法进行制作。采集2 个群养栏共12 段监控视频,总计1 456 f,图片分辨率大小为320× 240。动作分为躺卧、站立和移动3 类。
2.2 生猪动作识别实验
2.2.1 实验环境和设置
本文训练的设备参数如下:Ubuntu 18.04,显卡为GTX1080,显存8 G,CPU 为i7-8700K,内存16 GB。
在模型参数设置上,模型输入图片分辨率大小为224 ×224。权重更新方法采用具有动量的小批量随机梯度下降算法,动量值为0.9,学习率初始值为0.000 1。由于数据集较小,在1 000、2 000、3 000 和4 000 代后,学习率每次衰减一倍。实验代码基于深度学习框架PyTorch,实现模型端到端的训练。测试中,只检测置信度大于0.25 的包围框,使用非极大值抑制(non-maximum suppression,NMS)对包围框进行处理,交并比(intersection over union,IOU)阈值为0.4。
2.2.2 数据集包围框聚类
为了检测出的包围框和实际标注的包围框有更大的IOU,训练时加速收敛,对标注的包围框尺寸进行k-means 聚类操作。对数据集包围框的尺寸数据和聚类中心坐标数据进行可视化,如图5所示。
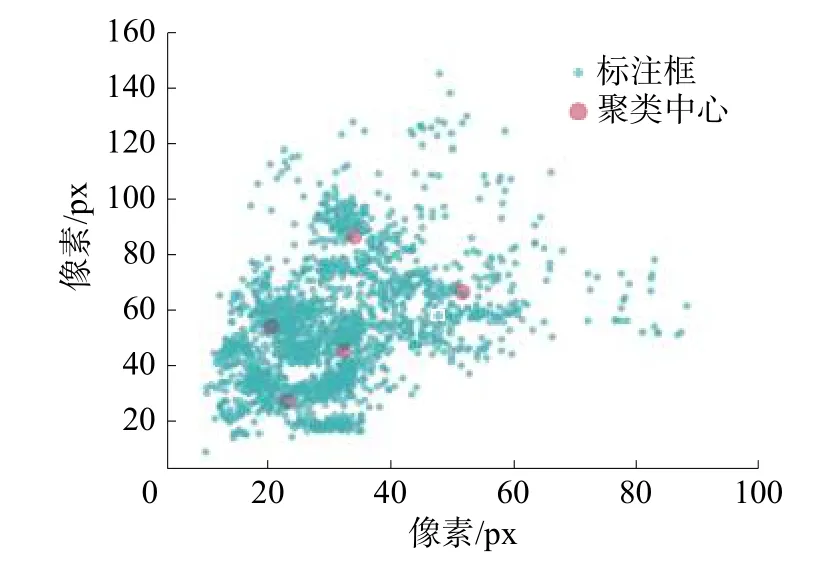
图5 生猪动作数据集检测框聚类
数据点横纵坐标是包围框所占图像像素的大小,从图5 中可以看出,自制生猪动作数据集包围框大部分分布在20 ×20 到70 ×120 之间,较小尺寸的包围框所占比例也较小。
2.2.3 并行3D-CNN 有效性实验
在连续输入16 f 的情况下,对不同网络组合结构的模型进行测试。评价标准为各个类别的平均准确率(AP0.5),下标代表检测出的包围框与真实标注值IOU 阈值为0.5。由于自制数据集数据量相对较少,容易产生过拟合现象,本次实验中3D 支路迭代1 000 次后,3D 支路参数停止更新,只更新2D 支路的参数。
测试结果如表1 所示。只使用2D 网络检测指标比较低,这是因为没有结合时序特征信息,单纯使用3D 网络;AP0.5明显优于2D 网络,说明3D 网络在获取时序动作特征时更具优势,更加关注于运动的过程,但是时间序列中生猪的位置变动会导致定位能力下降;而在2D 和3D 网络相结合时,将关键帧的空间位置信息和时间序列动作信息结合,检测指标有一定的提升。对于本文数据集所涉及的躺卧、站立和移动3 种动作,其中移动动作具有更多的时序信息,所以(表1)使用3DCNN 后,移动动作AP0.5提高最多。

表1 不同网络结构实验结果
该实验证明了在目标检测网络中,添加3DCNN 提取时序信息,有助于时空动作识别和定位。
2.2.4 通道注意力模块实验
2D 支路与3D 支路特征融合时,本文使用了通道融合注意力机制。如表2 所示,该实验研究了通道注意力模块对检测结果的影响。结果表明通道注意力模块对特征融合具有积极作用。

表2 通道注意力模块对网络的影响
2.2.5 不同序列采样间隔实验
模型输入为不同采样间隔的视频序列,输入跨度为16 f,序列保留最后一帧作为关键帧输入2D 支路。实验结果如表3 所示。

表3 视频序列采样间隔网络实验效果
采样间隔为1 时,AP0.5优于连续输入16 f,该实验表明了对于本文所采用的生猪动作数据集中视频帧之间存在冗余信息。
采样间隔继续增大到2 时,移动动作AP0.5开始下降,而静止动作躺卧、站立的AP0.5基本保持不变或略有上升。这表明检测静态动作时,2D 图像就可以提取足够的特征信息;而对于动态动作,需要有足够的时序信息。
采样间隔继续增大到3 时,3D 支路实际输入的视频序列只有5 f,这时各个动作的AP0.5都有下降,但是与表1 所得结果相比,仍然优于只使用2D 支路的网络结构。
3 结论
本文针对生猪动态运动特征,采用了并联一路3D 网络和一个用于融合不同特征的注意力机制,提出了一种结合时空信息的动作识别与定位的方法。
1)本文通过实验证明了3D 加2D 的特征提取网络结构和通道注意力机制在生猪动作的时空定位任务上具有充分的有效性。
2)将深度学习技术运用到生猪的动作识别,有利于实际的应用。
3)本文算法适用于目标相对较大的场景,针对小目标检测问题还有研究空间。
接下来还可以考虑使用FPN 结构优化小目标检测能力,提高算法在不同场景下的泛化能力和鲁棒性。另外3D 卷积参数量巨大,计算时间较长,因此对模型的压缩剪枝也将成为未来研究的重点。
猜你喜欢
中国农业信息(2023年3期)2023-03-18 08:19:04
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中国农业信息(2021年3期)2021-11-22 06:44:48
能源工程(2020年6期)2021-01-26 00:55:22
传媒评论(2017年3期)2017-06-13 09:18:10
电子制作(2016年15期)2017-01-15 13:39:08
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
电信科学(2016年9期)2016-06-15 20:27:30
电测与仪表(2016年13期)2016-04-11 11:21:20
电工技术学报(2014年7期)2014-11-15 05:53:48
