
基于ArcPy与定制ArcToolbox的矿山新增图斑自动编号及方法改进
2021-07-08 10:42:52陈栋姚维岭
自然资源遥感 2021年2期
陈栋,姚维岭
(中国自然资源航空物探遥感中心,北京 100083)
0 引言
长期以来,矿产资源开发给国民经济发展提供了强有力的保障,但由于多种原因,我国矿产资源开发“规模小、分布散、数量多”的局面仍然存在,矿产资源开发利用粗放、生产效率低、资源浪费严重的现象在部分地区一直有着不同程度的显现[1]。矿山遥感监测可以为矿山地质环境恢复治理工作提供决策数据和监督手段[2]。通过遥感监测了解和掌握矿业活动占地情况、矿区地质灾害分布状况和矿山环境污染情况,为矿区环境综合整治提供决策数据,同时也为矿山地质环境恢复治理工作提供监督手段。矿山遥感监测数据在矿产资源规划、保持矿产资源可持续开发与利用、维护矿业秩序及综合整治矿区环境等领域提供了重要基础信息[3]。
矿山遥感监测是我国长期开展的一项矿情调查工作,监测成果的表达方式以图件、表格、矢量数据为主。全国每年均会产生大量的矿山新增图斑,主要包括新增矿山恢复治理土地和新增矿山损毁土地两种类型。图斑是当前矿山工作中的最小单位,也是对数据进行编辑整理、分析处理以及报表图件制作的核心单位。所有的矿山监测、检查工作都是围绕着图斑来进行的[4]。图斑隶属于矿山主体,一个矿山主体可能有一个或多个图斑,若想要区分不同图斑,纳入数据库中作为基础数据管理,就需要用到图斑编号。图斑编号不仅是每一个图斑的“身份证”,也是实现多期数据对比以及统计数据生成中不可或缺的一项内容,其准确性与唯一性是矿山遥感监测数据的关键,也是保证成果数据质量的基础。
在目前矿山新增恢复治理及违法开采图斑的成果制作中,给新增图斑进行编号是一项既费时又容易出现差错的工作。若出现错误,对本期数据,甚至对未来的工作也会产生很大的影响,也不利于以数据为支撑的矿政管理服务。
目前来看,矿山遥感监测新增图斑编号的工作具有以下难点:
1)图斑数据关联密切,结构复杂,要求严格。依据目前的项目技术规范[5],矿山新增损毁和恢复治理图斑编号共15位,由4部分组成,这4部分分别与图斑的空间数据和属性数据相关联,导致结构复杂,要求严格。
2)图斑编号工作量大,重复性高,易出错。图斑编号的编制工作往往是以省或县为单元,涉及图斑少则几百,多则成千上万,数据量庞大,重复性强,容易出现因技术人员频繁、重复性的工作而导致的缺项漏项错误。另外,一旦在编制过程中某个图斑编号错误,修改过程都需要重新排序一次,导致较高的时间和人力成本。
3)图斑编号编制标准变化频繁。因矿山遥感监测工作具有持续性的特点,项目技术规范经常会根据上级管理部门或服务对象的要求进行修改,技术人员需要不断更新技术方案,按照新要求对图斑进行重新编制,对技术人员的工作经验有很高的要求。
为此,在当前矿山遥感监测工作数字信息化、流程规范化、信息提取自动化、统计分析智能化的趋势下,利用计算机快速、高效、准确地完成数量庞大且关系复杂的矿山图斑自动化编号就成为了一项亟待解决的工作,具有重要的现实意义和应用价值。
1 图斑编号编制要求
数据提交说明是为了满足矿山遥感调查与监测成果数据入库以及信息系统开发的需要,对需要提交检查并入库的成果数据内容、数据格式、数据说明等信息做出的规定和要求[5]。需提交的成果数据内容有矢量数据、切图、元数据表等,而新增图斑编号不仅是矢量内图斑的唯一编号,同时也与切图名、元数据表索引紧密相关[6]。在最新一期二级项目技术要求中规定,新增图斑编号共15位,由4部分组成,包括6位县级行政区划代码、4位影像年份、1位类别代码和4位顺序号,其中类别代码用于区分新增损毁与新增恢复治理图斑,新增损毁图斑为S,新增恢复治理图斑为H。图1是目前的矿山新增恢复治理及新增损毁图斑编号示意图。
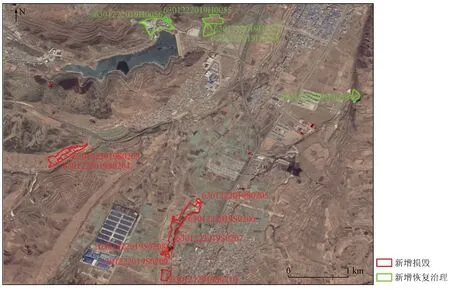
图1 矿山新增恢复治理及新增损毁图斑编号示意图Fig.1 Diagram of new restoration and new damage patches serial number
在手工编写图斑编号的过程中,行政区划代码、影像年份、类别代码同一县域内均相同,规则较为简单,保证整体一致性即可;较为复杂的是顺序号。近年来,新增图斑编号在顺序号这一项上的规则主要有两项,即在每个县域内,首先以“从左到右,从上到下”的编号顺序,同时应保证同一矿山主体内图斑的编号连续;也就是若图斑在空间上连续,但是所属矿山主体不同,也需要根据矿山主体来进行分组分别连续编号。
以图2为例。图2(a)为只遵从 “从左到右,从上到下”规则排序的示意图,其中有淡绿与淡黄色的区域分别代表两个矿山主体XKZ1与XKZ2。若引入矿山主体的约束,1,2,4,5属于同一矿山主体XKZ1;3,6,7属于另一矿山主体XKZ2,那么在图斑编号的过程中内应先对XKZ1内这4个图斑进行连续编号,再对XKZ2号矿山主体内接着上个矿山主体内最大序号进行编号,这样两许可证相交区域的图斑编号顺序就发生了改变,顺序如图2(b)。上述即为当前的新增图斑编号手动工作方式,但是在现实工作中,各种图斑之间的几何关系比上图更为复杂,所以在人工排序时时常会出现漏编、排序规则不统一的情况,对于整个项目成果的统一规范化表达、有效应用会产生不利影响。因此,自动编号的实现对于工作效率以及工作准确度的提升、成果的规范化表达具有重要价值。
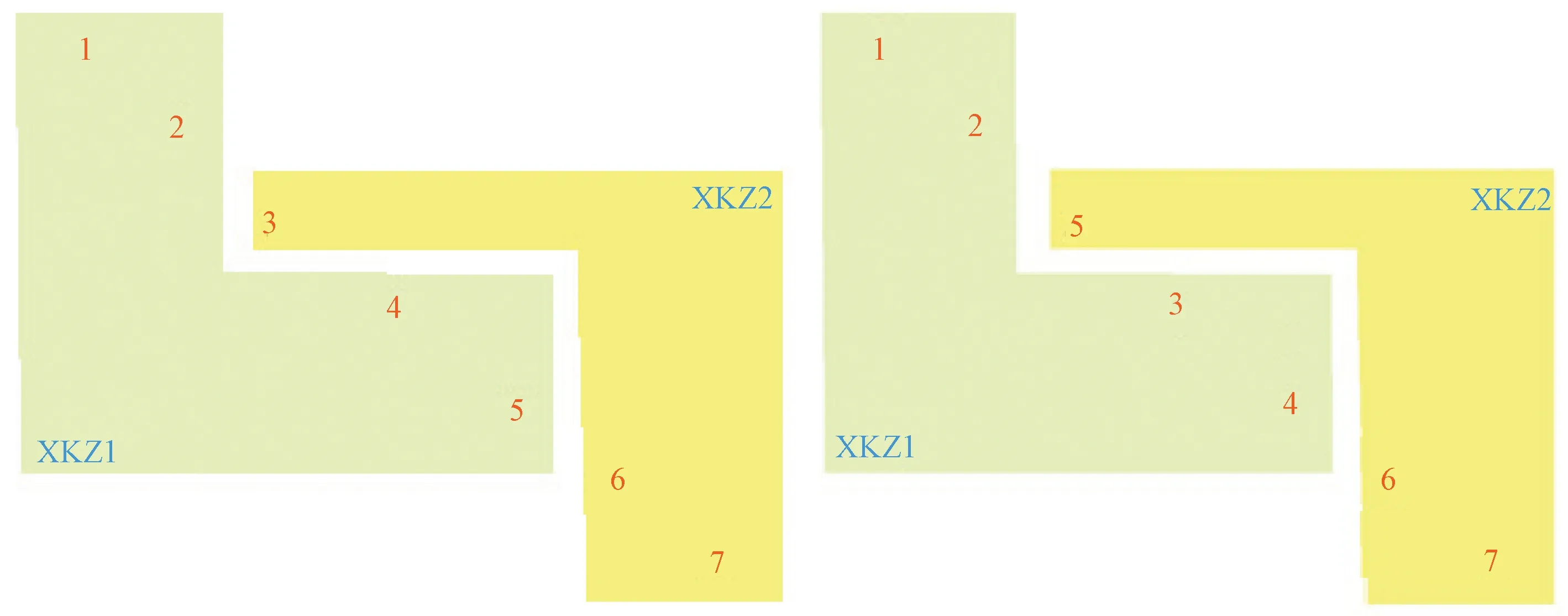
(a)无矿山主体约束 (b)有矿山主体约束
2 自动编号的实现
当前矿山新增图斑及成果是以省为单位进行提交的,而在每个省内是分县进行的图斑编号。分析数据提交说明中对于新增图斑编号的命名规则,实现自动编号的需求,主要有如下几步:①读取全省域的矢量,根据县行政代码字段进行分割,形成每个县一个矢量;②针对每一个县域矢量,将其每一条记录按照左上到右下的顺序排列;③再根据矿山主体编号进行分组,同一主体进行顺序排号;④补齐序号前的县代码、年份、类别代码,写入属性表中对应字段。
2.1 技术手段
本文所提出的矿山新增图斑编号自动编制工具基于ArcGIS10.2版本的ArcPy以及ArcToolbox开发完成。ArcGIS软件的安装自动配置ArcPy的运行环境(Python2.7)以及简易代码编辑器IDLE,为操作人员省去繁琐的环境配置过程。
Python是一种解释型的、通用的编程语言,具有简单易学、功能强大、可跨平台、不受局限等优点[7]。ArcPy是ESRI公司针对有批处理脚本以及二次开发需求的ArcGIS使用者,提供的一个Python站点包,是以arcgisscripting模块为基础并继承了arcgisscripting功能构建而成的,目的是以实用高效的方式通过Python执行地理数据分析、数据转换、数据管理和地图自动化创建等功能[8]。简单来说,就是ArcGIS的一些核心功能,如相交分析、属性表查询等功能,可以利用代码来进行组合,实现依次运行的整合性功能组和一些需要大量重复操作的自动化运行[9-12]。
虽然ArcGIS内部也提供了Model Builder用以创建、编辑模型并集成化运行一系列的地理处理工具,但它只是为ArcGIS内部的功能提供了一个可视化、简易化的一个工作流编辑器,对于Python语言本身很多强大高效的功能却无法使用,而ArcPy而不会受此限制,拓展性更强。
2.2 矢量分割
矢量分割基本流程是:初始化一个列表结构XDM_list,来存储县代码,再使用SearchCursor游标遍历全省矢量,读取其县代码字段下的数据,若此县代码不在这个列表中,那就将此县代码添加其中;否则跳过。这一次遍历即可将此省所有县代码存储进XDM_list中。
接下来依次读取列表中每一个县代码,再次进行全省矢量的遍历,使用到核心Select_Analysis函数,此函数的主要参数有3个:待处理矢量、输出路径以及选择条件,选择条件设置为县代码字段内容等于当前循环的县代码,即可将每一个县的记录分别导出成一个单独的矢量。运行完成后就可以快速地实现在ArcMap中选择-导出各县矢量的操作。
2.3 空间位置第一次排序
这一步的核心是进行图斑在空间位置上的排序。先直接使用ArcPy内置的排序函数,即Sort_management函数。此函数的主要参数有4项:待排序矢量、排序完成后输出矢量路径、待排序的字段及升降序、空间位置排序规则(如左上、左下等)。此函数可以2种方式进行矢量排序:UL排序和属性数值排序。属性数值只是根据第3项参数的大小进行排序;UL排序则是根据矢量具体的空间位置,按着给定规则进行排序。因为在矿山新增图斑编号规则中,序号就是以从左到右、上到下的规则进行排序,等同于从左上开始依次排序,则首先就是以空间位置排序规则来进行排序,代码如下:
arcpy.Sort_management(goal_layer,sortedgoal_layer,["Shape"],"UL")
需要说明一点,若想在Sort_management函数中使用空间位置排序,函数的第3个参数便要固定为“Shape”,才可以使得第4项参数有效,其中,UL代表从左上角开始排序,UR代表右上,LL代表左下,LR代表右下。
这一步完成后,已经输出了从左上角开始排序且每个县单独一个的矢量,接下来就要针对矿山主体编号来进行二次编号。
2.4 矿山主体分组后二次排序
矿山主体分组后二次排序首先初始化一个记录矿山主体编号的列表xkzSeq,针对某一个县的矢量,遍历所有记录,使用类似于第一步中记录所有县代码的方法,将此县中所有出现过的矿山主体编号进行记录。同时,因为此矢量中的记录已经在空间上排序完成,那么,xkzSeq中的顺序也代表着不同矿山主体在空间上的顺序;接下来,初始化一个计数器i,按顺序提取xkzSeq中的矿山主体编号,每提取一个矿山主体编号,就遍历一次矢量中的记录,对比xkzSeq中与记录中的矿山主体编号,若相等,就可给当前记录赋值顺序号i,同时i自增1,不相等就跳转到下一条记录。这样循环下来,既保证了空间顺序的一致性,又保证了技术要求中“同一矿山主体的图斑顺序号要连续”的规定。
2.5 属性类编号内容补足
第4步操作较为简单,根据县代码、矢量类型和年份补足图斑编号的其他位数。当所有步骤完成后,即可使用UpdateCursor,setValue和updateRow方法来对矢量内容进行更新。若有需要,可将所有编好号的分县矢量使用Merge_management方法来进行合并,形成全省总矢量。至此,便实现了矿山新增图斑编号的自动编制工作。
2.6 定制ArcToolbox
ArcGIS为用户提供了一套地理处理任务的工具集,不仅提供基础的数据处理、分析和制图功能,而且提供脚本编程批处理、空间分析和建模功能,这些优势都为降低开发成本和实现难度提供了充分的技术条件[13]。这些地理处理任务都包含在ArcToolbox工具箱中,其中包含了ArcGIS地理处理的大部分分析工具和数据管理工具[14-15]。大部分情况下软件使用者都是单独使用这些工具。对于一些需要整合不同工具形成流程化工作流的需求,ArcGIS也提供了定制工具箱方法,只保留需要用户填写的内容,以ArcToolbox式的可交互界面形式展现在用户面前,本文便是使用这种方法对编写的代码进行整合。
在封装工具箱之前,需要将代码中需要用户填写的路径、字段名等等内容挖空,如图3(a)。接下来就可在ArcGIS新建自己的工具箱了。通过将挖空参数与界面中填空区域进行一一对应,如图3(b),定制工具箱就可以开始运行并实现新增图斑编号的全自动编制工作。
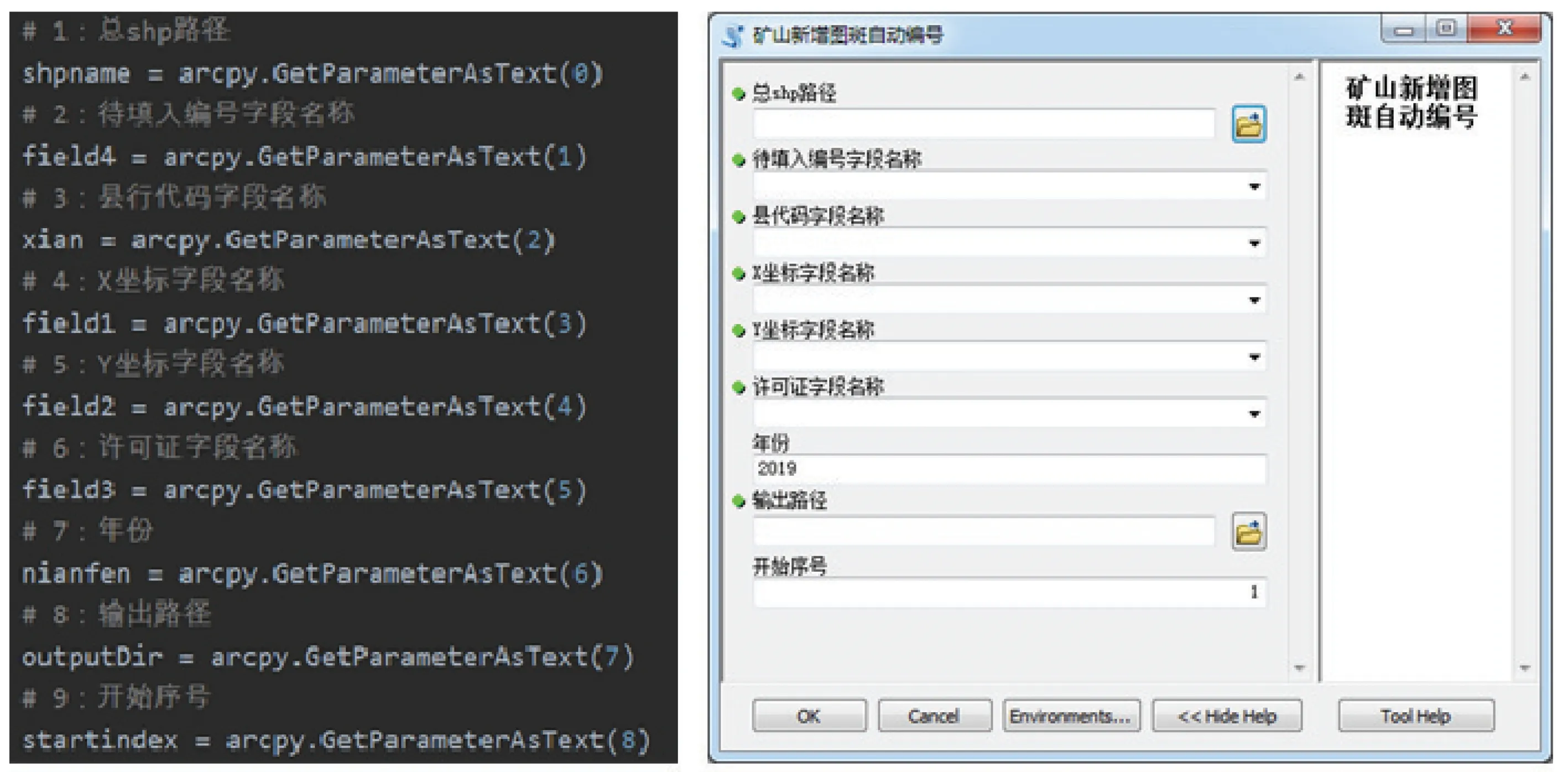
(a)参数挖空代码 (b)定制工具箱界面
3 自动编号方法的改进
经过试验,本方法虽然在排列较为规律的图斑时能够取得较为良好的效果,但是在处理现实中排列方式十分复杂的矿山图斑的时候,空间位置第一次排序会出现不合理的结果。以西宁市大通回族土族自治县的部分图斑为例,如图4(a)是使用Sort_management函数中UL的排序方式,可以发现,在这种情况下,2,3,4,5位的顺序会出现左右方向较为大范围的跨度;而且可以看出,直接使用UL参数进行的排序,更多的是遵循从上到下的顺序,左右顺序的混乱使这种排序方式不能应用到实际的工作当中。

(a)UL方法排序结果 (b)XY数值方法排序结果
图4(b)是采用属性数值方式排序。因从X,Y值的角度来看,从左到右、从上到下的顺序就是X升序、Y降序在空间上的一种表现方式,所以,将参数改为X值升序,Y值降序的方式排序观察效果,即
arcpy.Sort_management
(in_layer,out_layer,[["X","ASCENDING"],["Y","DESCENDING"]])
会发现排序的结果会更加混乱,如图4(b)。此时感觉更多的是以从左到右,即X升序的方式进行排序,Y方向已无法看出明显的规律,不符合排序规范,影响实际工作。所以,考虑改良排序方法,使之在X和Y方向上均能遵循一定的规范。
3.1 改良排序方法
本文考虑的是根据矢量的X值,首先对矢量空间进行分带,这样再从左向右依带进行处理,就可实现整体范围上从左向右依次排序的目标,不会出现图中左右大范围来回横移的现象;在每一个分带内,使用Y值从大到小依次排列,便可实现从上到下的排序。这种处理方法,虽然没有实现从左到右、从上到下排序同时进行,但是在相对小尺度上能够保证序号的基本连续与规范。排序方法的流程图如图5所示。
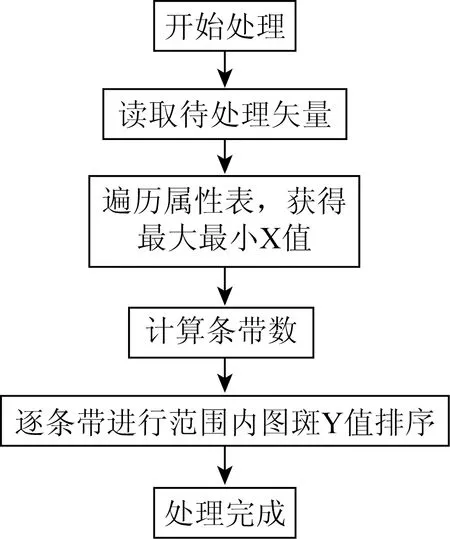
图5 改良排序方法流程图Fig.5 Flow chart of improved sorting method
3.2 改良排序方法的代码实现
首先,对X值进行分带,分别进行处理。考虑到我国大部分县域以及矿山图斑的跨度,结合已有的工作经验,本文使用10′(约0.166 7°)一带进行分带,数值也可根据不同工作区进行手动调整。某个县内的分带数g计算公式为:
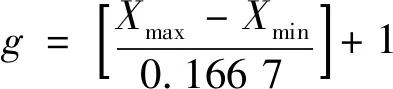
(1)
式中:Xmax与Xmin为最大和最小X值,通过Python的max()和min()方法可快速实现;[·]为向下取整符号。
接下来就是对每一个条带内的Y值从大到小排列,因为此排序结果并没有考虑矿山主体,不是最终结果,所以新建一个Seq_Long字段作为临时记录的一个字段,待最后排序完成将编号写入原有字段中,再将此字段删除。
遍历当前县矢量的过程中,判断X值是否在此条带范围内,若在便可将当前图斑的FID和Y值写入FID_X字典中;当此条带遍历完成后,将FID_X根据Y值进行降序排列。排列代码如下:
FID_X =sorted(FID_X.items(),key=lambda x:x[1],reverse=True)
在此需要注意,sorted方法虽然针对的是字典对象,但是在排序完成后,会将原字典变成列表,所以复制一个FID_X命名为FID_X2,用以二次循环时的键值比对。
最后就是将按排序好的顺序,将序号写入Seq_Long字段中,此时使用到了UpdateCursor,updateRow,getValue与setValue函数,用于对属性表值的获取及编辑。当遍历完所有条带后,当前县所有图斑的序号也就写入完成了。写入的代码如下:
row.setValue("Seq_Long",get_Index(row.getValue("FID"),FID_X)+ firstIndex)
updateCursor.updateRow(row)
接下来也是根据矿山主体编号来分组再次排序,以及补齐其他位代码形成完整的编号,方法与上述相同在此不再赘述。
使用相同的数据进行排序效果如图6,可以看到1,2号图斑分在了一个条带中,余下其他图斑分在了另一个。在每个条带中按照由上到下顺序排列,这样就完成了在大范围上由左向右,在小范围上由上到下的排序方式。

图6 改良方法排序结果Fig.6 Sequence in improved sorting method
4 实验结果
本文对青海省化隆回族自治县22个、门源回族自治县53个、共和县91个、大通湟中平安三县共215个,以及全青海省(有图斑共32个县)近千个图斑进行人工和自动编制的对比实验。可以看出,随着工作量的增加,自动编号的效率对比手工编号越高;同时,本文也对五种数量下进行的人工和自动编制出现的误差进行了比对,因手动编制出现编号错误后需要对当前县再进行依次重新排序与编号,每一次误差的返工耗时量在10 min左右,误差代价十分巨大,而自动编号则不会出现错误,时间及误差对比如表1。工作所用机器配置为戴尔P7920台式工作站,Intel Xeon 4110 2.2 GHz CPU,96 GB内存。编号流程自动化的实现,不仅可以节省时间,提高工作效率。一旦出现编号规范变化的情况,重新编号仅仅需要修改少量代码,大大降低时间和劳动成本。
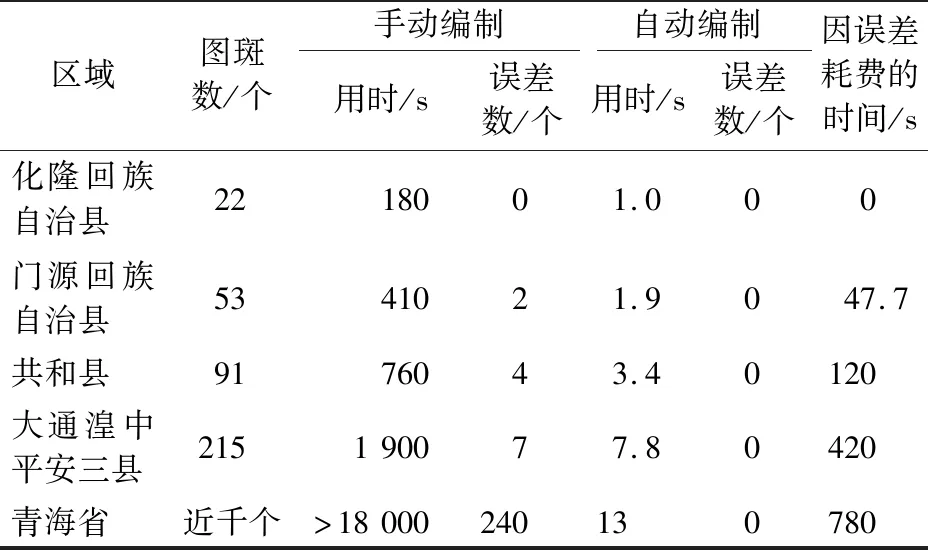
表1 手动与自动图斑编号时间及误差对比Tab.1 Time and error comparison of manual and automatic patch numbering
5 结论
针对批量图斑编号效率低、易出错的问题,本文利用ArcPy并结合定制ArcToolbox实现了这一工作批量自动化处理,并用不同数据量的图斑进行了对比实验,结果表明新增矿山图斑编制工作的效率得到提高,有助于矿山监测遥感工作信息化水平向更高层次发展。具体完成了以下几项内容:
1)基于ArcPy编写代码,将过去在ArcGIS新增图斑编号的编制工作中需要手动操作的部分进行整合处理,并且将代码整合成ArcToolbox添加到ArcMap中直接使用,使得程序的分发与应用更加便捷高效,免去繁琐的重复劳动,保证编号准确性,工作效率大大提升。
2)针对ArcPy中自带的空间位置排序方法不适应于矿山遥感工作中要求的问题,将图斑排序方法进行改良,能够满足在大尺度上从左到右,小尺度上从上到下的排序要求,使得图斑编号更加规范,有据可查。
3)针对日后可能发生变化的技术要求与提交说明,只需更改排序方法内部的逻辑代码即可实现对程序功能的更新,重新进行图斑编号的工作量和时间成本也会大大减少。
4)此自动编号方法不仅适用于矿山新增图斑,也适用于土地新增图斑等有一定规则与数据量的编号工作。矢量自动编号是图件编制的基础,有助于矿山遥感监测成果统一规范化,只有高质量的成果数据和成果图件,才能更有效服务于国家矿政管理工作、国土空间用途管制和矿山生态修复工作。
猜你喜欢
北京测绘(2022年9期)2022-10-11 12:25:14
绿色科技(2021年5期)2021-11-28 14:57:37
中学生数理化·高一版(2021年11期)2021-09-05 12:21:24
计算机技术与发展(2020年4期)2020-04-30 04:36:30
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
现代防御技术(2016年1期)2016-06-01 12:13:28
新高考·高一物理(2016年1期)2016-03-05 22:47:39
