
治安监控视频中暴力行为的识别与检测
2021-07-08 06:09:10谭等泰王轶群
中国人民公安大学学报(自然科学版) 2021年2期
谭等泰, 王 炜, 王轶群
(甘肃政法大学司法鉴定中心, 兰州 730070)
0 引言
近年来,示威游行、暴力犯罪和踩踏等危害社会公共安全的事件频繁发生,这些突发的恶性事件,不但会对生命财产造成危害,而且对治安秩序形成严重的威胁[1-2]。暴力行为是以人和财产为侵害对象,采取暴力手段,会对身心健康和财产构成威胁,严重情况下直接危及人的生命健康[3-5]。传统的视频识别主要依赖人工审核,但是依靠人工审核的方法很难实时检测到异常行为的发生,而且视频呈爆发式增长,这种方法无法满足实际需求。因此对治安监控视频中出现的暴力行为自动分析并预警,对维护社会治安秩序具有重要的实用价值。
暴力行为检测是行为识别中的一项特殊应用,根据输入数据的不同,暴力行为检测可分为3类,分别为基于音频特征的暴力行为检测[6-8]、基于视频特征的暴力行为检测[9-12]和基于音视频混合特征的暴力行为检测[13-15]。随着视频监控的普及,从视频中实时预判暴力事件显得尤为重要,因此重点介绍基于视频的暴力行为检测,暴力行为检测方法主要分为人工提取特征的方法和深度学习的方法。在基于人工提取特征的暴力行为检测中,文献[16-17]选取了暴力行为中常出现的血液、火焰、皮肤、爆炸和声音等特征实现暴力行为的识别与检测,但是某些暴力行为中并未出现血液、火焰等明显的暴力特征,因而文献[9]、[18]通过检测人体的姿态、运动轨迹和光流等运动特征检测暴力行为,用到的特征有加速度运动矢量[19]、暴力流[20]和韦伯局部描述符[21]等。总之,人工提取特征的暴力行为识别中,特征的提取主要靠先验知识,准确率相对比较低。
在基于深度学习的暴力行为检测中,网络从数据集中自动提取特征,不需要人为设计特征。二维卷积神经网络(2D CNN, 2D Convolutional Neural Networks)在图像特征提取中取得了巨大的成功,将二维空间拓展到三维空间处理视频数据形成三维卷积神经网络(3D CNN, 3D Convolutional Neural Networks),文献[11]采用使用3DCNN对视频中的暴力行为进行检测,该方法在不依赖手工提取特征的情况下达到了较好的效果。文献[22]提出了基于RGB图像和光流的暴力行为检测算法,主要通过RGB图像和光流图像提取特征,然后融合长短期记忆网络(LSTM,Long Short-Term Memory)进行编码,可以有效地提取视频中的时空特征,但网络模型比较复杂,提取光流特征计算量比较大。卷积长短期记忆网络[23](ConvLSTM,Convolutional LSTM Network)是由香港科技大学的Shi提出的,并利用它建立了短时降水预报模型,它不但可以像LSTM网络一样捕获序列信息,而且可以提取空间特征。文献[12]将ConvLSTM应用到暴力行为检测中,能够有效地对视频进行建模,该方法在暴力行为检测中取得较好的检测效果。
深度学习的方法能够从数据中自主提取特征,在暴力行为检测领域已经远远超过了基于手工设计特征的传统算法,但是基于深度学习的方法也存在一些缺点,如通用性欠佳,在提取视频数据的特征时很难完全提取高层时序特征。因此提出了一种融合3DCNN和ConvLSTM网络的暴力行为检测模型,通过3D CNN和ConvLSTM两个模块逐级提取视频中的低层时空特征和高层时序特征,从而更好地检测暴力行为。
1 网络结构
图1为暴力行为检测结构框图,该模型主要由3D CNN模块和ConvLSTM模块两部分构成。该算法的检测流程划分为3个阶段。
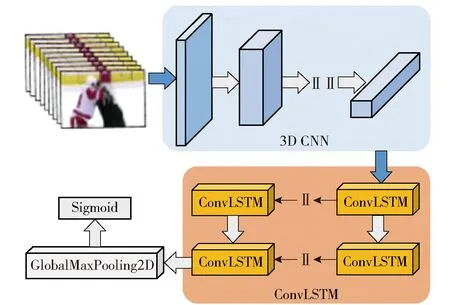
图1 暴力行为检测结构框图
第一,设计3D CNN网络提取视频的低层时空特征。3DCNN主要是用于短时序特征的建模与提取,该特征包含了暴力视频中与行为目标、场景和人体动作有关的信息,使得这些特征对不同的任务都通用。
第二,设计ConvLSTM网络对3D CNN提取的时空特征进行长时空特征建模,进一步提取局部特征并建立时序关系。ConvLSTM不但可以提取空间特征,而且可以捕获序列信息,更好地提取深度融合特征。
第三,采用全局最大池化层(GlobalMaxpooling 2D)将特征映射到低维空间中,并在全局最大池化层之后加入随机丢弃层(Dropout),并由Sigmoid层输出暴力行为类别。其中,Dropout按照一定的概率使一定数量的神经元权重等于0,在小批量的训练过程中,每次训练网络的连接方式是不同的,阻止了某些特征在特定特征下才有效的情况,这样做能够防止模型过拟合的问题,进而提升模型对未知数据的泛化能力。
2 3D CNN网络结构
视频是由一系列连续的图像数据组成,视频中包含目标的运动信息等三维信息,二维卷积神经网络具有很强的特征表达能力,但处理视频任务时,需要将视频转换为单独的图像帧,从而丢失了帧间运动信息,因此无法捕捉运动信息。为了更好地提取视频的时空特征,将2D CNN在时间维度上进行扩展形成3D CNN提取特征,并结合参考文献[24]设计了3DCNN模块。
3DCNN模块结构如图2所示,网络以80×80×3×24的视频作为输入,其中80为视频帧的高度和宽度,24为视频帧的长度,3为通道数。该模型总共由1个输入层、4个卷积层(Conv3D)、3个池化层(Pooling),3个激活层(Activiation)和3个批标准化层(BN,Batch Normalization)组成。卷积层Conv1到Conv4的滤波器数量分别为64,64,128,128。第一个池化层的内核大小为(2,2,2),步长为(2,2,1),在第一层卷积层Conv1上,只对视频的空间维度进行了下采样,即视频的高度和宽度下采样,保留了帧间运动信息,其他池化层的内核大小为(2,2,2),步长为(2,2,2)。
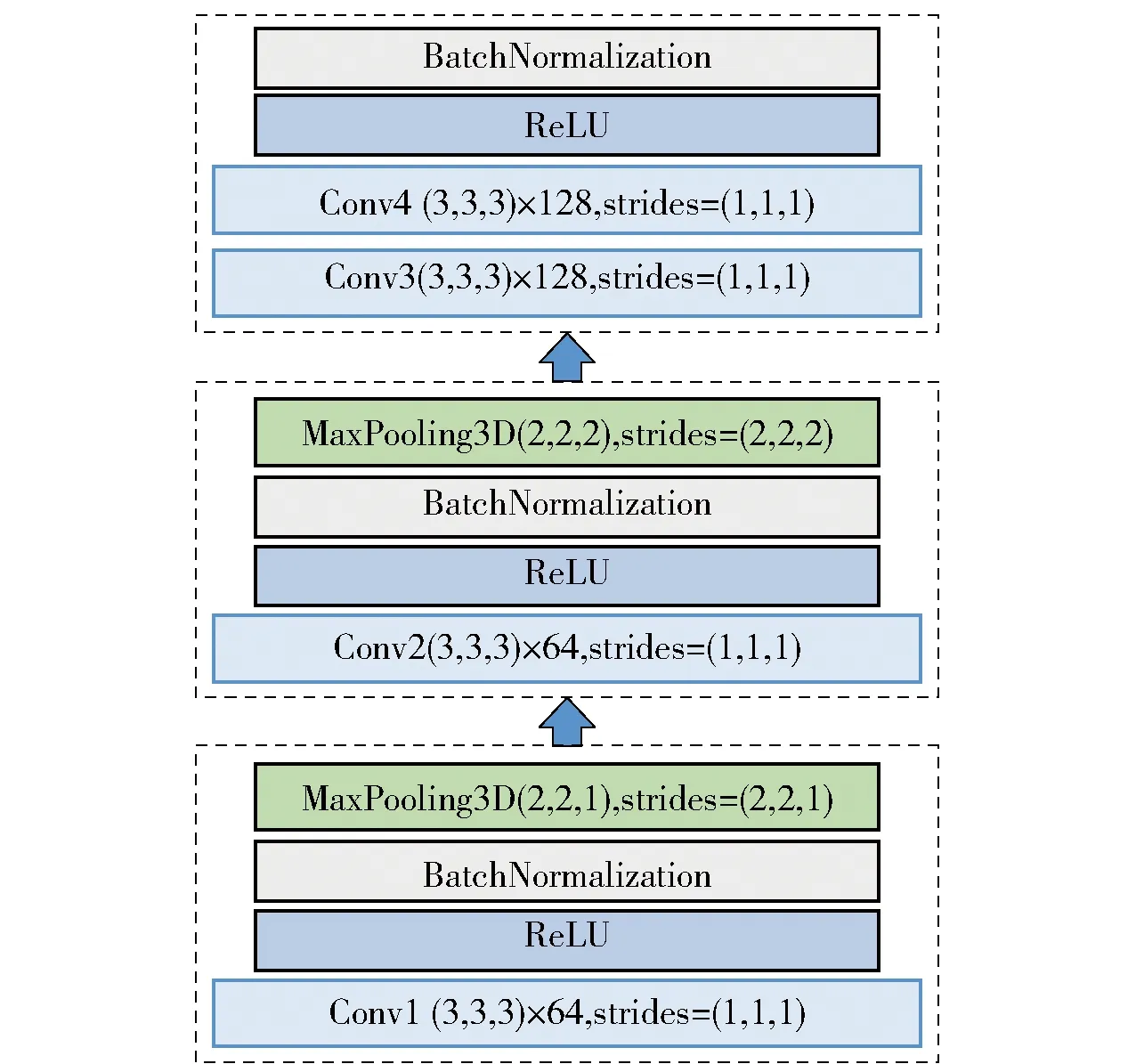
图2 3D CNN模块
为了提高分类效果,在激活层之后选用BN层,BN层是一种对数值的特殊变换方法,把越来越偏的分布变换到比较标准的分布,可以加速网络的收敛速度,有效地控制梯度爆炸和消失;池化不但可以使特征和参数减少,而且还可以使特征保持伸缩、旋转和平移不变性。最大池化(MaxPooling3D)能提取更多的纹理特征,而平均池化(AveragePooling-3D)能提取更多的背景特征,因此网络中所有的池化操作都采用MaxPooling3D,保留视频的纹理特征;激活函数选择“Relu”。Relu会使小于0的神经元置0,使网络变稀疏,减少了参数之间的依赖关系,可以有效的缓解过拟合。
3 ConvLSTM网络
LSTM[25]是由循环神经网络(RNN,Recurrent Neural Network)的发展而来,它解决了反向传播过程中梯度爆炸或梯度消失问题。虽然LSTM在序列建模任务中表现良好,但是对于空间数据来说,一般的LSTM通过整个全连接层将输入图像展平为一维矢量,这会导致图像空间信息的丢失。为了保留空间信息,ConvLSTM将卷积运算用于输入到状态的转换以及状态到状态的转换。它可以更好地捕获空间信息,ConvLSTM的内部结构如图3所示,公式如下:
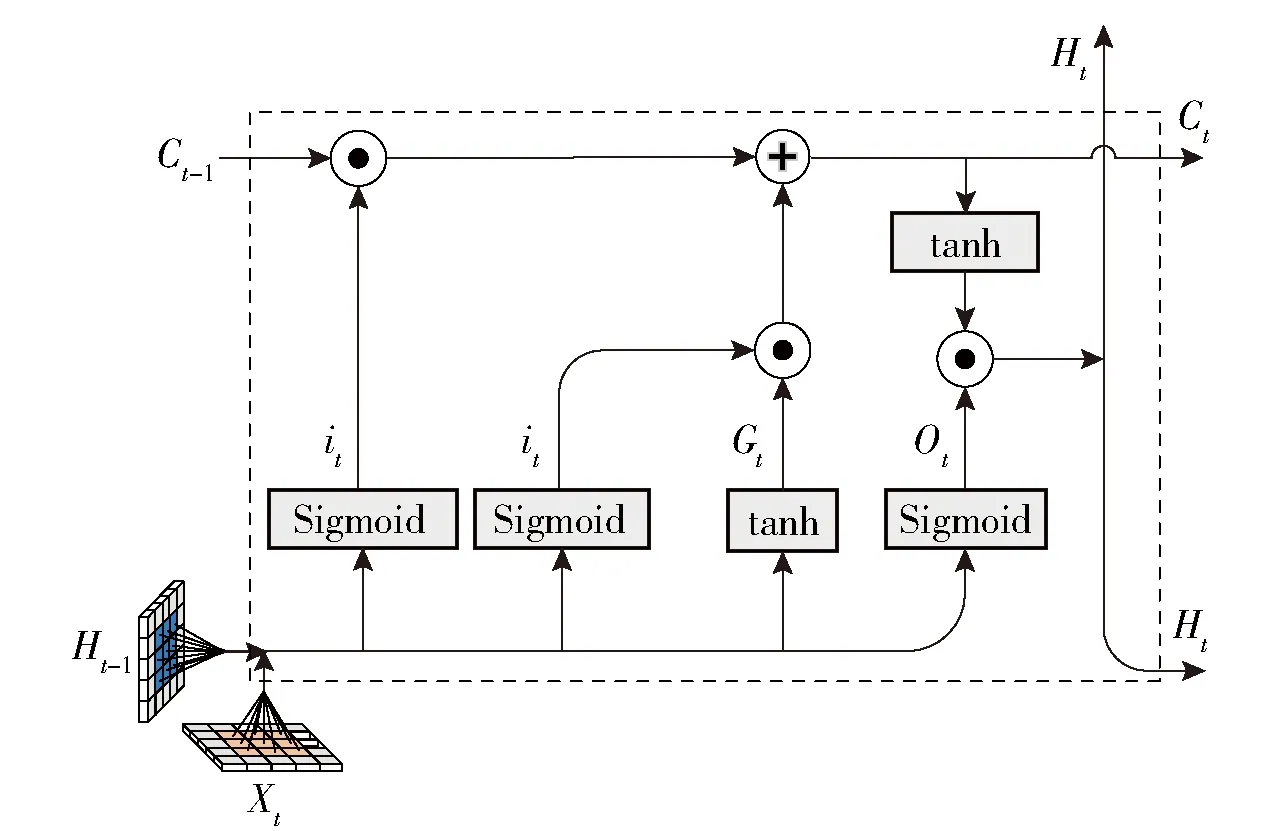
图3 ConvLSTM内部结构
it=sigmoid(Wxi*Xt+Whi*Ht-1+Wci⊙Ct-1+bi)
ft=sigmoid(Wxf*xt+Whf*Ht-1+Wcf⊙Ct-1+bf)
Gt=tanh (Wxc*xt+Whc*Ht-1+bc)
Ct=ft⊙Ct-1+it⊙Gt
ot=sigmoid(Wxo*Xt+Who*Ht-1+Wco⊙Ct+b0)
Ht=ot⊙tanh (Ct)
(1)
(1)式中*表示卷积,⊙表示元素乘法,Sigmoid表示S型激活函数,tanh表示双曲正切激活函数,it表示输入门,ft表示遗忘门,Ht是隐藏状态,ot为输出门,xt是输入数据,Ct是单元状态。ConvLSTM的本质与LSTM的本质相同,取前一层的输出作为下一层的输入,主要区别在于添加卷积运算后,不仅可以获取时间关系,还可以获取空间关系。
为了提取高层时序特征,采用了两级Conv-LSTM结构,输入层为3DCNN模块提取的特征,第一级卷积核的数量为64,第二级为128,卷积核的大小都为3×3,在第一级和第二级之间依次连接了最大池化层和BN层,在第二级最后一个输出依次连接最大池化层和全局最大池化层,最后通过Dropout层输出到Sigmoid分类器输出结果,网络结构框图如图4所示。为了降低模型的过拟合现象同时结合Hockey数据集的大小,采用了两级网络结构,如果增加ConvLSTM的层数会导致模型的过拟合,无法提取高层时序特征。因为暴力行为检测是二分类问题,所以使用Sigmoid作为最终分类层,最终只需要一个神经元,给出为正样本的概率p,负样本概率即为1-p。
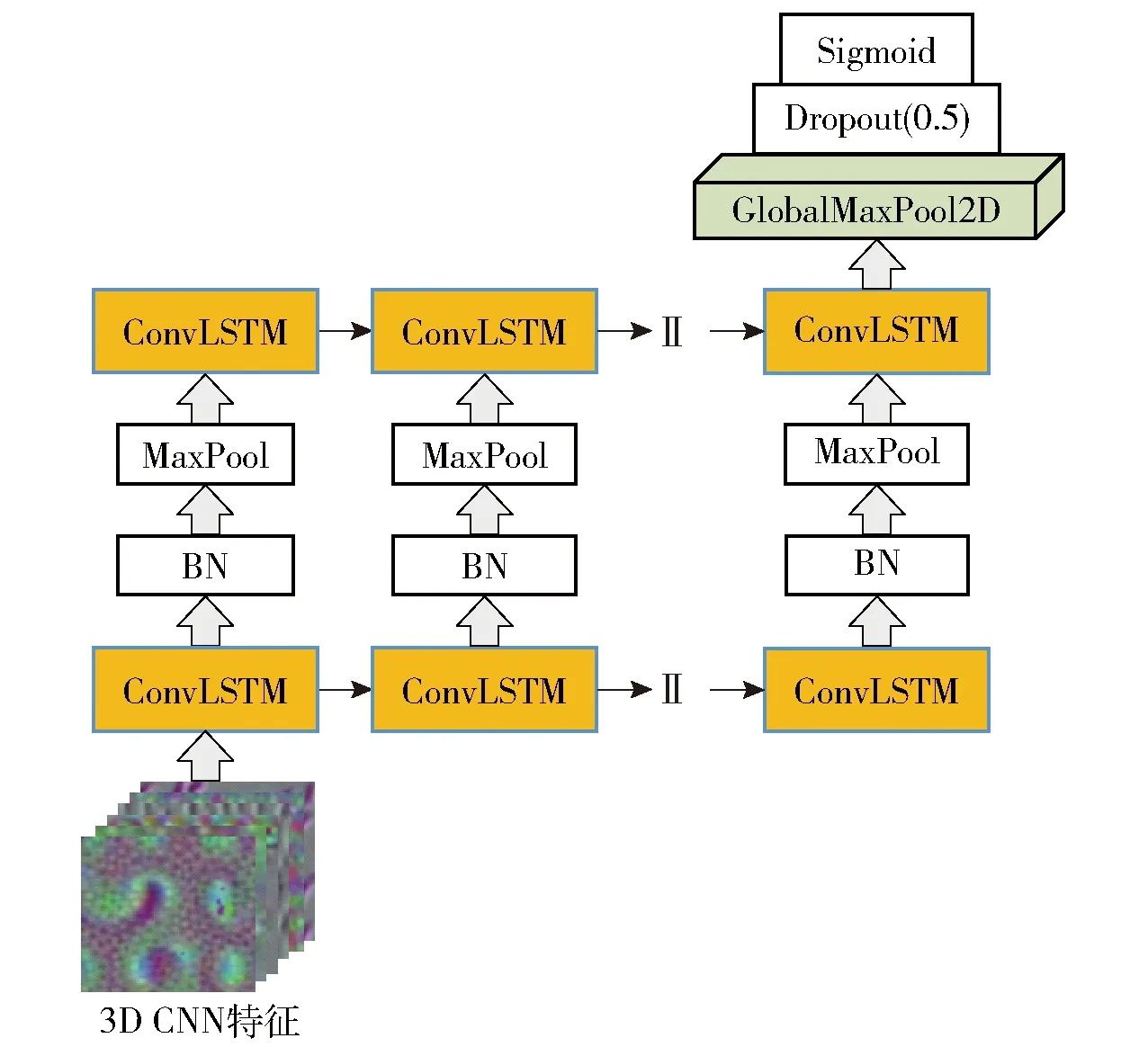
图4 网络结构框图
4 测试与分析
4.1 实验方案与参数设置
为了验证本文提出算法的有效性,采用暴力行为检测中最常用的Hockey数据集。该数据集为冰球比赛中的打斗视频,一共有1 000个视频片段,其中500个为冰球比赛中的暴力视频片段,剩下的为非暴力视频片段。每个视频片段的分辨率为360×288,该数据集的部分样本如图5所示。

图5 Hockey数据集
实验硬件环境:CPU为Core i7- 8700k,GPU为NVIDIA GTX2080Ti。软件环境:Tensorflow1.12.0和Keras2.1.6深度学习框架,编程语言为Python3.6.5,开发工具为PyCharm。
实验中从原始数据随机抽取连续的24帧图像序列作为输入,图像序列大小调整为80×80×3×24,训练期间采用随机裁剪方式和随机水平翻转的方式进行数据增强。训练集、测试集的比例为8∶2,即暴力和非暴力视频片段各400个作为训练集,剩余数据作为测试集。
bacth_size的大小受到电脑内存的限制,随着 batch_size的增大,模型的训练时间减少,提高了算法的稳定性,因此实验过程中根据数据集的大小和内存的大小,令batch_size=16,迭代次数为100,即epoch=100。
通过自动调整学习率的方式提高模型的准确率,调整过程采用线性衰减的方式。如果在3次迭代中学习停滞,准确率不在提升时,学习率减少50%,直到当lr=0.000 1时停止降低学习率,如此循环。参数如表1所示。
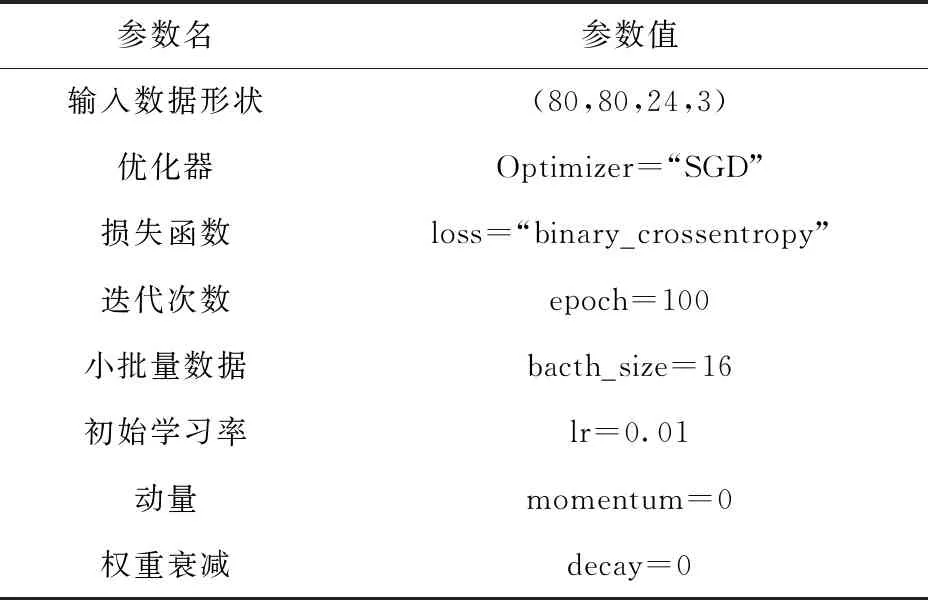
表1 训练参数
4.2 实验结果与分析
单独的3DCNN网络或ConvLSTM网络可以应用到视频分类中,为了验证融合模型的优越性,在Hockey数据集上测试了3DCNN、ConvLSTM和3DCNN+ConvLSTM网络的准确率变化曲线,如图6所示,其中,“加号”表示3D CNN+ConvLSTM融合网络的测试结果,“圆形”表示3DCNN网络,“朝右三角形”表示ConvLSTM网络。
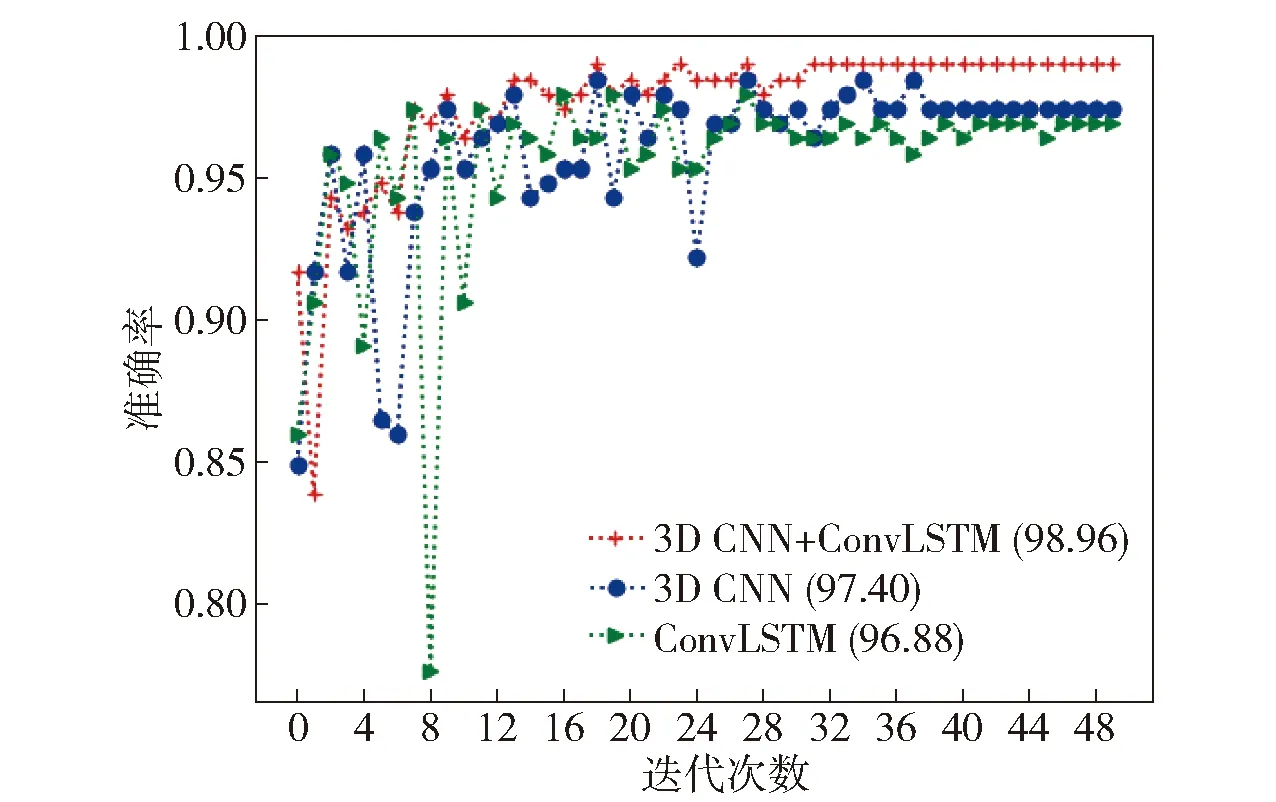
图6 准确率变化曲线
网络训练初期,3种网络的准确率提升非常快,随着迭代次数的逐步增加,准确率上升速度比较缓慢,经过30轮左右的迭代后,融合网络和3D CNN网络趋于稳定,但ConvLSTM网络在整个训练过程中出现了波动。单独的3DCNN网络和ConvLSTM网络分别达到了97.40%和96.88%的准确率,在暴力行为检测中取得了不错的效果,虽然两种网络精度相差不大,但是处理的思路完全不同,3DCNN网络通过三维卷积核捕获视频中的时间和空间信息,而ConvLSTM网络首先提取单帧图像的特征,然后对特征进行时序建模。
融合网络的准确率明显高于单独的3D CNN网络和ConvLSTM网络,达到了98.96%的识别精度,它利用了两种网络的优点,3DCNN网络的优势在于提取视频的低层时序特征,而ConvLSTM网络对数据的时序特征建模有一定的优势,融合网络很好地结合了它们的优点,因此在Hockey数据集上取得了最先进的识别精度,具有较好的泛化能力。
4.3 与其他暴力行为检测算法比较
为了比较融合算法的高效性,表2列举了本文融合算法与其他算法在Hockey数据集上的识别精度。融合算法在Hockey数据集上达到了98.96%的识别精度,优于大多数的暴力行为检测算法。与传统的暴力行为检测算法相比,比准确率最高的传统算法MoIWLD高2.16%,而且大多传统算法使用了光流信息,这样会大大增加算法的计算量,无法做到端到端的训练与识别。与深度学习的算法相比,比识别精度最高的ConvLSTM网络提升了1.86%。同时,也测试了单独的3DCNN网络和ConvLSTM网络在Hockey数据集上的识别精度,分别为97.40%、96.88%,高于传统算法,进一步表明了深度学习方法优于人工提取特征的方式。
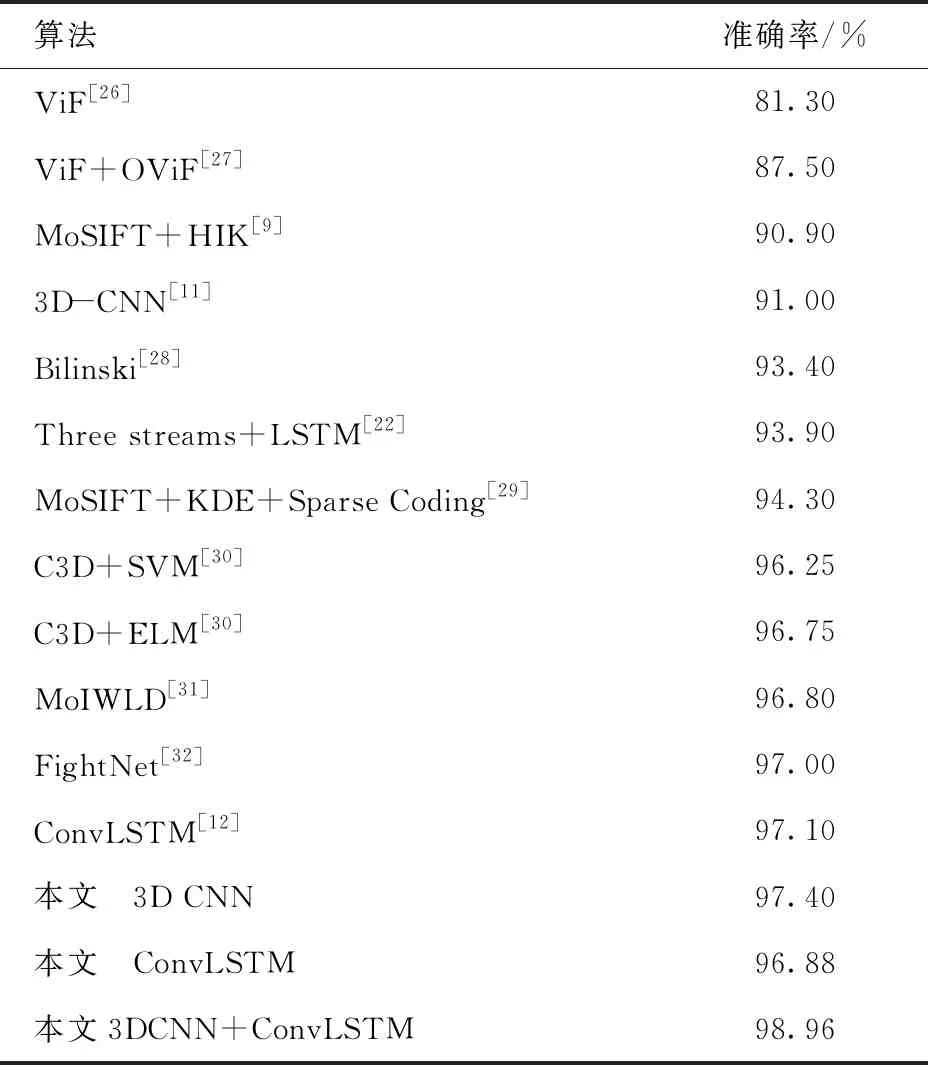
表2 与其他暴力行为检测算法比较
本文方法具有先进的识别精度,有两方面的原因。第一,采用了3DCNN网络提取了短时空特征,它包含了暴力视频中与行为目标、场景、人体动作有关的信息,使得这些特征对不同的行为分类任务都有用,是一种高效的视频描述符。第二,利用ConvLSTM网络对3D CNN提取的特征建模,提取视频的长时空特性,更深层次的提取暴力监控视频中的隐藏信息。
5 结论
针对治安监控视频中暴力行为的识别与检测,提出了一种基于3DCNN和ConvLSTM网络的暴力行为识别与检测模型,3DCNN网络是一种高效的视频描述符,能够很好地提取短时空特征,ConvLSTM网络通过对短时空特征的建模,来提取视频的长时空特性,因而对两种网络进行融合,提取了视频的高层时序特征,为了验证本文提出算法的高效性和鲁棒性,分别对3DCNN和ConvLSTM网络进行了单独的测试,在暴力行为识别Hockey数据集上分别达到了97.40%和96.88%的识别精度,而融合网络达到了98.96%的识别精度,表明了融合网络优于单独的3DCNN和ConvLSTM网络。
猜你喜欢
中国农业信息(2023年3期)2023-03-18 08:19:04
中国农业信息(2021年3期)2021-11-22 06:44:48
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
电子制作(2016年15期)2017-01-15 13:39:08
戏剧之家(2016年6期)2016-04-16 13:01:01
妇女生活(2015年6期)2015-07-13 06:17:20
河南科技(2014年15期)2014-02-27 14:12:36
