
CARS-SVM预测哈密瓜可溶性固形物含量
2021-07-06 09:25郭俊先李雪莲刘彦岑李泽平
食品与机械 2021年6期
郭 阳 郭俊先 史 勇 李雪莲 刘彦岑 黄 华 李泽平
(1.新疆农业大学机电工程学院,新疆 乌鲁木齐 830052;2.新疆农业大学数理学院,新疆 乌鲁木齐 830052)
哈密瓜是新疆的特色农产品之一,其果肉鲜嫩,爽脆可口,深受广大消费者青睐,其中,可溶性糖含量(SSC)与其口感有很大关系。哈密瓜在生长过程中受田间环境、植株生长形态、植株冠层营养等因素影响,造成可溶性糖积累分布不均匀、含量低。可溶性固形物主要是指可溶性糖类,其是衡量哈密瓜品质好坏的重要指标,同时传统的哈密瓜中可溶性固形物含量的检测方法的准确率高,但需破坏样本。近年来,近红外光谱检测技术因其具有快速、准确及多组分同时检测等特点,已被应用于椰汁品质[1]、鸡蛋新鲜度[2]、肉类品质[3-4]、石榴糖度[5]、梨的可溶性固形物[6-7]、液态奶三聚氰胺[8]等农业生产检测方面。哈密瓜可溶性固形物检测方面,张德虎等[9]采用BiPLS光谱波长筛选方法提取哈密瓜糖度特征波长,优化后的预测模型校正集和预测集的RMSE分别为0.996 1和1.18;Greensill等[10]利用4种光电二极管陈列近红外光谱仪结合不同光谱预处理方法预测了甜瓜的SSC;Guthrie[11]建立了移动窗口偏最小二乘(MWPLS)甜瓜总糖含量的预测模型,其预测集均方根误差和标准偏差分别为1.1和0.04;毕智健等[12]比较了哈密瓜样品中可见近红外光谱数据的预处理方法的预测效果;马本学等[13]利用高光谱成像技术比较了偏最小二乘(PLS)、逐步多元线性回归(SMLR)和特征提取(PCR)3种建模方法对带皮和去皮哈密瓜糖度的检测效果。水果可溶性固形物无损检测中,高升等[14]将光谱信息和图像特征信息进行有机融合,融合后的模型精度较单一的图像与光谱模型都有较大提升,其红提糖度最优的预测模型为最小二乘支持向量机(LS-SVM),模型的校正集和预测集的相关系数分别为0.954,0.952;Dong等[15]研究苹果中可溶性固形物含量无损测定时,分别建立了偏最小二乘回归(PLSR)、LS-SVM、极限学习机(ELM)模型,最优预测模型为LS-SVM模型,其模型预测集相关系数为0.878;杨晓玉等[16]利用特征选择竞争性自适应重加权采样法(CARS)、无信息变量消除法(UVE)、连续投影算法(SPA)对灵武长枣的原始光谱特征波长进行提取,并将提取出的特征波长作为输入变量建立了PLSR和LS-SVM的灵武长枣维生素C含量预测模型,最优模型为无信息变量消除法+支持向量机(UVE-SVM)模型,其校正集和预测集的决定系数分别为0.847 1,0.714 9。
综上,非线性模型在水果理化性质无损测定中应用非常广泛,而目前对哈密瓜可溶性固形物建立的定量分析模型多是PLS、PCR等线性模型,有关非线性模型下结合特征选择和特征提取对哈密瓜可溶性固形物定量分析模型进行优化的研究尚未见报道;同时哈密瓜成熟采收时,其是否可以采摘主要通过果皮表面颜色的变化以及哈密瓜可溶性固形物含量来进行判断,而可溶性固形物含量是判断哈密瓜是否可以采摘的关键指标。研究拟采用特征波长选择和特征提取3种算法对预处理后的光谱数据进行数据降维,同时应用非线性的支持向量机(SVM)、极限学习机(ELM)、最小二乘支持向量机(LS-SVM)算法结合3种优化算法建立预测模型,并比较所有模型的优劣,最终选取最优的模型作为哈密瓜可溶性固形物含量的无损检测模型,旨在为哈密瓜可溶性固形物含量的无损检测技术的发展提供依据。
1 材料与方法
1.1 试验地点
选取新疆哈密地区巴里坤县三塘湖镇中湖村为试验地点,该地形呈西高东低之势,气候干燥酷热多风,属典型的大陆性气候。年平均大风日116.6 d,年日照时间3 373.4 h,有效积温3 440 ℃,无霜期169 d。极端最高气温40.3 ℃、最低气温-28.5 ℃,年平均气温8 ℃。年平均降水量34.4 mm,蒸发量3 790 mm。试验田位置为东经1 200.144°,北纬3 020.626°,土壤的理化性质见表1。

表1 大田哈密瓜的土壤理化性质
甜瓜品种:金华蜜25号,俗称“新86”,晚熟品种,生育期100 d,单瓜重3.5 kg左右。
1.2 试验样本与数据采集
待哈密瓜成熟后,从试验田一次性随机采摘144个无病虫害和损伤的哈密瓜作为试验样本,标记编号运回实验室。将所有样本在室温下放置24 h后开始试验,并尽可能地快速完成试验。光谱数据的采集使用美国海洋光学公司的maya2000微型光纤光谱仪,光谱测定范围为200~1 100 nm,光谱采样间隔0.2 s。数据采集前,光谱设备预热30 min,主要工作参数设置包括积分时间7 200 s,扫描次数10,平滑点数3。光谱采集位置选取每个样本赤道中间部位,每隔120°采集一次,每个样本采集3个光谱数据,取平均值作为样本的原始光谱数据。
可溶性固形物含量测定使用ATAGO PR-101型数字折光仪(日本爱拓),测量范围为0~45 °Brix,测量精度为0.1 °Brix。切取光谱采集处对应的内缘果肉并榨汁,将汁液滴至折光仪的测量区域,重复测定读数直至3次读数稳定,记录为当前样本的可溶性固形物含量。
1.3 原始光谱数据预处理
采集原始光谱数据过程中除了包含样品本身的特征信息外,还掺杂一些影响模型准确性的无用信息,如样品表面散射带来的光程变化所产生的光谱误差、光谱的散射影响、光谱数据中的噪声、以及设备自身造成的干扰。因此,分别用均值中心化(MC)、多元散射校正(MSC)、标准正态变量交化(SNVT)、SavitZky-Golay卷积平滑法(SG-平滑)、二阶求导、归一化、移动平均平滑(MA)对原始光谱数据进行预处理。
1.4 数据降维
光谱数据具有数据量大、维度高、数据共线性等缺点,且未经过数据降维处理的光谱数据直接作为模型的输入变量,会影响模型的精确度和稳定性,同时大量的数据计算时会影响可溶性固形物含量的无损检测效率,不利于后期在线检测。分别使用特征提取主成分分析(PCA)[17]、特征选择竞争性自适应重加权采样法(CARS)和蒙特卡罗无信息变量消除法(MC-UVE)来实现数据降维。
1.5 预测模型与模型评价
支持向量机(SVM)[18]可有效克服神经网络收敛慢、预测能力差的缺点,针对小样本量的预测模型建立具有其独特的优势。SVM回归预测模型是通过非线性变化转换为某个高维空间的线性问题,并在此空间进行线性求解,实现回归预测模型的建立。极限学习机(ELM)[19]相比于前馈神经网络等在运算过程中不需设定大量的参数,且运算速度更快,只需按照实际情况选择合适的激励函数(AF),在算法运行过程中随机产生网络的输入权值及隐含层单元偏置,且不需要调整,比较容易实现。因此,ELM具有学习速度快,高强的泛化能力促使模型只有唯一的最优解等特点。最小二乘支持向量机(LS-SVM)[20]是在SVM的基础上进行改进的算法,可以完成线性和非线性的多元预测模型的建立,具有降低计算复杂度、提高模型泛化能力、并能使训练集数据在高维特征空间进行学习等优点。
预测模型的评价指标为相关系数(R)和均方根误差(RMSE)。其中校正集均方根误差为RMSEC、预测集均方根误差为RMSEP;校正集相关系数为Rc、预测集相关系数为Rp,预测模型的相关系数越大表示相关性越高;预测模型的RMSEP越小,模型的预测效果越好。
(1)
(2)
式中:
R——相关系数;
SRME——均方根误差;
xi——样本;

yi——实际值;

N——样本数。
以上光谱数据处理和定量预测模型的建立均使用Matlab2017b软件完成(美国,MathWorks),采用Matlab2017b和OriginPro 8软件绘图。
2 结果与分析
2.1 样本划分
考虑到光谱理化值共生距离法(SPXY)算法能同时研究光谱特征与样本理化性质的能力,使用该划分法按3∶1将原始数据划分为样本校正集和预测集,其测定结果见表2。
由表2可知,哈密瓜可溶性固形物含量的最大值和最小值都被划分到了校正集中,并且划分到预测集的数据值均在校正集区间内,表明利用SPXY划分的样本集的分布合理,所建的预测模型也能产生较好的结果。

表2 哈密瓜的可溶性固形物含量
2.2 光谱预处理
将原始光谱和7种预处理后的光谱变量分别结合PLS建立预测模型,通过对比多个PLS的预测模型的精度,选择最优模型的光谱预处理方法作为哈密瓜光谱变量的预处理方法,建模结果见表3。
由表3可知,最优光谱预处理方法为二阶求导,这是因为利用此种预处理方法处理光谱原始数据可以提高光谱分辨率,减小噪声并提高信噪比,模型的预测精度会有所提高。从所有全波长建模角度来看,相关系数基本为0.60~0.75,表明全波段作为模型的输入变量建立的预测模型效果不是很理想,说明全波长的变量中存在冗余信息和数据共线等问题,导致模型的准确性不高,故需对全波长的光谱信息进行变量选择和变量提取。

表3 不同光谱预处理结合PLS哈密瓜可溶性固形物的预测效果
2.3 基于CARS数据降维
图1为CARS算法筛选特征波长变量过程。由图1可知,特征波长变量筛选过程中,随着迭代次数的增加,波长变量的总数减少,直至选取最优迭代次数为止。迭代次数最优时,RMSECV越小迭代次数越好,当RMSECV为0.199 7时,对应的最优迭代次数为41。因此,确定从原始1 600个波长中筛选的特征波长变量为110个。
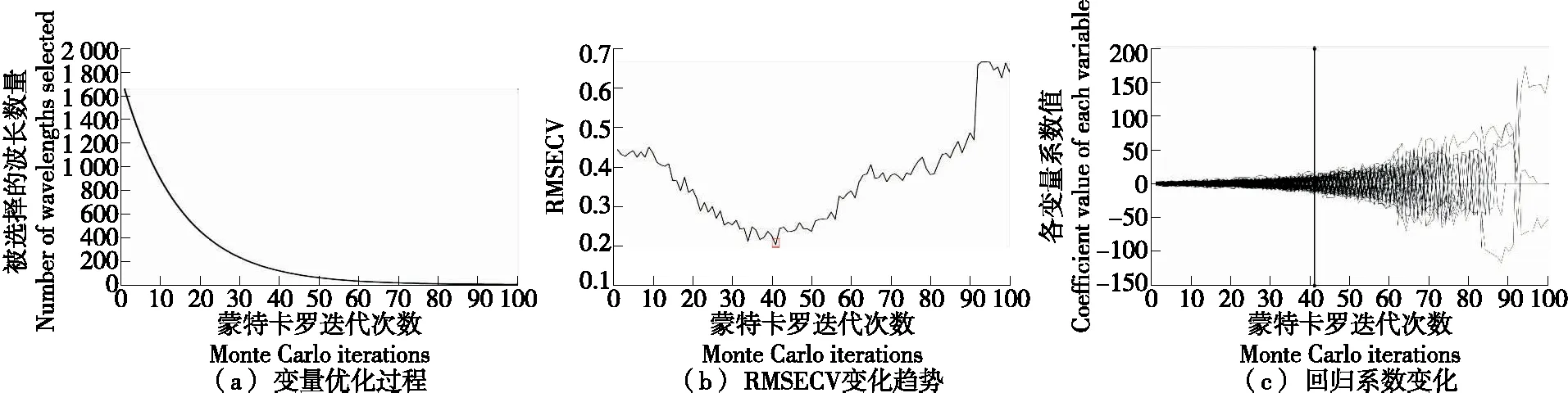
图1 CARS筛选光谱变量过程
2.4 基于MC-UVE数据降维
当N=1 000时,波长变量的稳定值如图2所示。

图2 光谱变量稳定图
MC-UVE算法仅给出了光谱变量的稳定值,未给出最终筛选的光谱变量数作为后续模型建立的输入变量。因此为了剔除多余的变量,减少变量的共线性并提高模型的泛化能力,通过前向变量选择程序选择光谱变量。经MC-UVE算法筛选的光谱变量曲线如图3所示。由图3可知,RMSEP的最小值为0.307 9,对应的组数为13,因此筛选前13组作为最佳变量,即共有130个特征波长变量。

图3 MC-UVE筛选光谱变量曲线
2.5 基于PCA数据降维
主成分分析结果如图4所示,其前15个主成分累计贡献率达95%以上,可以很好地表征原光谱数据的特征,故使用前15个主成分得分值作为模型的输入变量。

图4 前20个主成分的累计贡献率
2.6 哈密瓜可溶性固形物含量建模预测分析
3种数据降维方式结合SVM、ELM、LS-SVM的哈密瓜可溶性固形物预测分析结果如表4~表6所示。由表4~表6可知,主成分分析下的建模效果都不是很理想,相关系数仅有0.79,0.77,0.86,可能是主成分分析只降低了光谱数据的维度,并未减少光谱的变量数;相比而言,特征选择下的数据降维效果优于主成分分析,且二者优于全波长下的PLS预测模型。最优的预测模型为二阶求导+CARS+SVM,其校正集相关系数为0.981 4,预测集相关系数为0.900 2;表明该模型可以准确、快速地预测哈密瓜中可溶性固形物含量。3种数据降维方法结合ELM建立的模型预测精度都不是很理想,可能是因为ELM属于神经网络模型的一种,且神经网络都有收敛慢、预测能力差的缺点,故相比于SVM、LS-SVM的建模效果,ELM的价值是最低的。同时,证明CARS算法在定量预测建模中可以对光谱变量中与理化性质相关性高的变量进行准确提取。

表4 数据降维下结合SVM的建模预测效果
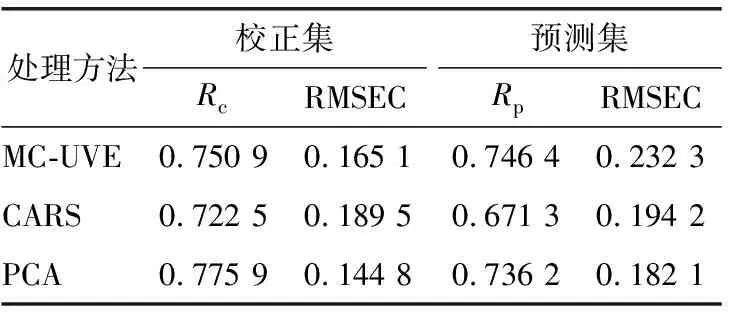
表5 数据降维下结合ELM的建模预测效果

表6 数据降维下结合LSSVM的建模预测效果
3 结论
通过对原始光谱以及经均值中心化、多元散射校正、标准正态变量正交化、SavitZky-Golay卷积平滑法、二阶求导、归一化、移动平均平滑预处理获得的光谱数据建立全波长的PLS预测模型并分析,得出最优的预处理方式为二阶求导法;在二阶求导的基础上再分别使用两种特征选择方法(特征选择竞争性自适应重加权采样法和蒙特卡罗无信息变量消除法)和特征提取主成分分析法对光谱作进一步处理;基于处理后光谱数据分别结合非线性模型支持向量机、极限学习机和最小二乘支持向量机建立定量分析模型。结果表明,最优的预测模型为二阶求导+特征选择竞争性自适应重加权采样法+支持向量机,模型的校正集和预测集相关系数分别为0.981 4,0.900 2,模型预测效果得到了提升;表明光谱数据与理化性质之间也存在非线性的相关信息,且非线性模型可以准确地预测哈密瓜可溶性固形物含量,实现哈密瓜内部品质的无损检测,同时也为田间便携式哈密瓜是否成熟判别设备的研制提供了新思路。后续应考虑如何将特征选择与特征提取进行有效融合,结合两者的优点实现光谱数据的压缩且保证关键信息不会被丢失,以期建立准确且稳定的定量分析模型。
猜你喜欢
车主之友(2022年4期)2022-08-27
农产品市场周刊(2022年2期)2022-03-31
农产品市场周刊(2022年2期)2022-03-09
阅读(科学探秘)(2021年8期)2021-09-01
海峡姐妹(2019年12期)2020-01-14
中国惯性技术学报(2019年6期)2019-03-04
中国科学院大学学报(2019年1期)2019-01-21
创新作文(1-2年级)(2017年5期)2017-12-07
火控雷达技术(2016年1期)2016-02-06
