
基于MIML的OGC网络服务语义检索方法研究
2021-07-06 02:15:28孙君祯苗立志徐兴永
计算机技术与发展 2021年6期
孙君祯,苗立志,2*,徐兴永
(1.南京邮电大学 地理与生物信息学院,江苏 南京 210023;2.南京邮电大学 江苏省智慧健康大数据分析与位置服务工程实验室,江苏 南京 210023;3.南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
地理信息有着数据源广、发布形式多样以及应用多元化的特点,这使得地理信息数据表达形式也具有多样化的特点。随着云计算、大数据等相关技术的不断发展,为实现地理信息数据的有效共享,地理信息服务数据量增长趋势亦愈发明显,在有效降低地理信息数据采集难度的同时,也使得越来越多的用户在互联网上共享地理信息服务数据。但是,日益增长的地理信息服务空间数据在地理信息知识表达方面存在“数据丰富、知识匮乏”的现象,传统的检索方法已不能满足人们获取知识的需求。并且,传统的地理信息服务语义检索在元数据领域的标记方式在目前还没有统一的标准,语义标记实现后容易导致次生的共享障碍。MIML(multi-instance multi-label learning,多示例多标记学习)是针对对象的歧义性而提出的一种学习框架[1,2],在该框架下,表述地理信息服务数据的语义信息由包含多个示例的示例包来表示,且其对应的描述该地理信息服务元数据的类别标记也不再是唯一的,而是变成多个标记该元数据的标记组成的集合。因此,MIML学习可以在地理信息服务语义标记方面得到有效应用。
Zhou等[1-2]于2007年提出MIML学习框架以来,已被相关研究者广泛用于标记任务,如生物图像信息学、图像标注、视频标注、文本分类等相关领域[3-4]。唐俊等[5]基于MIML方法的手机游戏道具推荐可以与任何机器学习模型进行结合,向用户推荐所需要的游戏道具;王超俊[6]针对基于MIML方法的图像分类标注进行研究,能够提取更加全面的图像,而且图像分类也更全面,使得图像的丰富性得以显现出来;Zha等[7]基于隐含条件随机场提出了一种集成MIML方法,可以同时捕获语义标记和区域的关系以及标记间的关系;罗飞[8]基于MIML方法研究了图像语义标注方法;彭亮[9]提出利用MIML对图像与视频进行自动语义标注方法,可有效地改善图像和视频标注的准确性。由上可以看出,MIML方法在语义标注方面已有较多的研究,但未有用于地理信息服务的语义标注相关研究。因此,该文将MIML方法用于OGC(open geospatial consortium,开放地理空间联盟)地理信息服务(OGC web services)语义标注,在不破坏OWS能力文档原有机构的基础上实现海量OWS基于语义层面的检索,解决地理信息服务语义的歧义性,实现检索的查全率和查准率的双重提高。
1 服务标签值与标记词汇提取
1.1 OWS标签属性值解析
OWS文件中包含丰富的地理信息数据,每个能力文件中拥有多个描述地理信息服务的语义标签,包括:服务标题(title)、服务摘要(abstract)、图层摘要(layer abstract)、图层关键字(layer keyword)、服务提供者的联系信息(contact information)、请求能力描述(request GetCapabilities)、所支持的地图格式(GetMap format)等,如图1所示;但是,这些标签值内容存在大量的冗余的描述地理信息的语义词汇[10-11],如服务提供者的联系信息、请求能力描述、所支持的地图格式等标签。根据标签重要程度,该文选取其中四个主要的语义描述标签来表述单个OGC地理信息服务能力文件的具体内容,分别为服务标题、服务关键字、服务摘要和图层关键字,并解析提取描述地理信息服务内容的语义标签title、keyword、abstract和layer keyword,同时获取语义标签的具体地理信息数据内容,如表1所示。

表1 元数据标签属性值提取

图1 WMS能力文件描述文档
1.2 基于TF-IDF的OWS标记词汇提取
为了从元数据标签值中提取能够体现OWS服务的标记词汇,该文采用TF-IDF算法检索、分类和过滤有价值的标记词汇。TF-IDF权值的高低由两部分组成,包括特征词汇在一个信息文本中的出现权值和该特征词汇在整个信息文本中的出现权值,两者的乘积越高TF-IDF权值越高。因此,TF-IDF算法可以过滤无用特征词汇,提取可以用于标记信息文本的重要词汇。在地理信息服务能力文件中,TF的值表述某个地理词汇在给定的能力文件中的出现频率。对于在某个特定的地理信息服务能力文件里的地理词汇ti来说,其重要性可表示为:
(1)
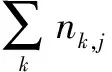
将所有地理信息服务能力文件总数除以含有该地理词汇的文件的总数,再将结果商取对数获得能力文件中某个特定地理词汇的IDF值:
其中,|D|为研究对象中地理信息服务能力文件总个数,|{j:ti∈dj}|表示含有地理词汇ti的能力文件数目,如果该地理词汇未包含在所研究的能力文件中,则会导致被除数为零;因此,式(2)中使用1+|{j:ti∈dj}|。tfi,j×idfi=tfidfi,j表示某一特定地理信息服务能力文件内的高地理词汇频率,以及该地理词汇在整个能力文件集合中的低文件频率的乘积,可以使TF-IDF占有较高的权重。
该文将OGC地理信息服务能力文件作为训练样本,对能力文件的描述内容进行数据预处理后,再对OWS文件的特征词汇提取分类并反馈,实现TF-IDF算法后向能力文件推送权值最大的标记词汇组,如表2所示。

表2 TF-IDF算法提取标记词汇组
2 基于MIMLBoost算法的语义标记
2.1 MIMLBoost算法
设X表示示例空间,Y表示标记空间,数据集D={(X1,Y1),(X2,Y2),…,(Xm,Ym)},其中,Xi⊂X为一组示例{Xi1,Xi2,…,Xi,ni},Xi,j∈X(j=1,2,…,ni)为第i个包的第j个示例,而Yi⊂Y为Xi的一组合适类别标记{yi1,yi2,…,yi,ni},ni为Xi中所含示例的个数,ki为Yi中所含标记的个数。
多示例多标记学习的目的是得到f:2X→2Y,MIMLBoost算法以多示例学习为桥梁,将学习目标转化为fm:2X×y→{-1,+1},然后再进一步转化为传统监督学习问题:给定(xi,yi),对示例空间和标记空间进行拼接,将集合转化为|Y|个多示例样本,原数据集D则转化为多个多示例单标记样本:{([Xi,y]),φ[Xi,y]|y∈Y};其中,[Xi,y]包含ni个示例{(Xi1,y),(Xi2,y),…,(Xini,y)},φ[Xi,y]=+1当且仅当y∈Yi,否则φ[Xi,y]=-1。上述转换过程完成后再利用多示例学习算法MIBoosting[12]进行求解。
2.2 基于MIMLBoost算法的语义标记
基于MIMLBoost算法实现对OGC地理信息服务的语义标记,例如对文件名为Combined Bedrock and Superficial Geology and mineral的OWS文件(http://ows.geogrid.org/GSJ_CCOP_Combined_Bedrock_and_Superficial_Geology_and_Age/wms)语义标记可以得到如表3所示的描述该OWS文件的具体地理信息数据和语义标记。

表3 基于MIMLBoost算法的示例包
OGC地理信息服务元数据里的语义标签服务标题(title)、服务摘要(abstract)、服务关键字(keyword)、层关键字(layer keyword)分别表示MIMLBoost算法里的示例包的示例单元,如表4所示。
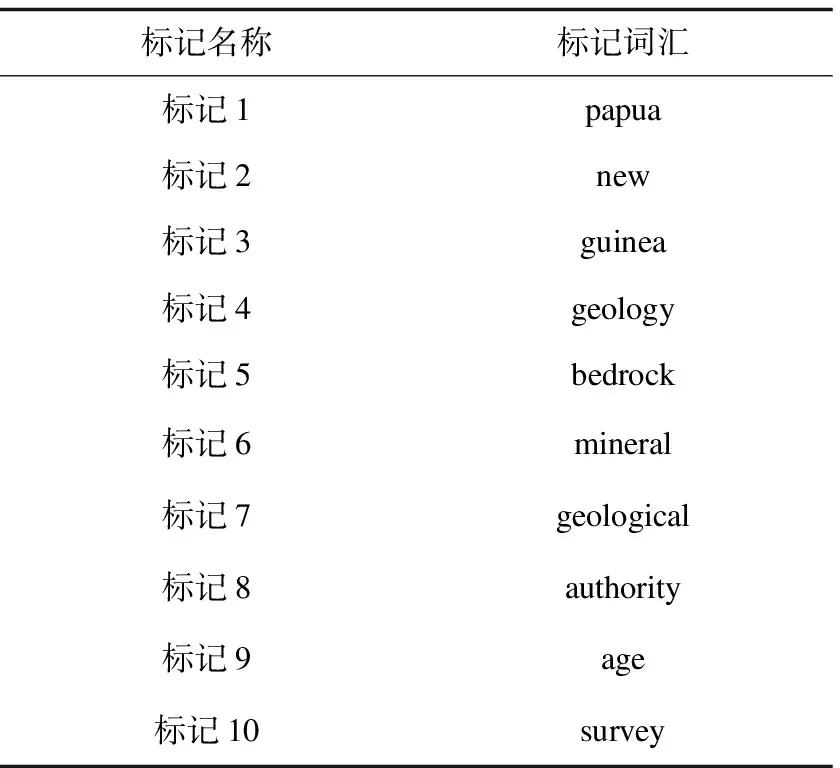
表4 基于MIMLBoost算法的标记包
基于MIMLBoost算法示例包里的示例内容与每个标记关键字分别放入集合中,当集合中的每个地理关键字分别在四个示例单元中出现,则认为该地理关键字可以作为代表性描述词汇用来标记OWS文件。结合表2和表3,OWS文件Combined Bedrock and Superficial Geology and mineral则可以用bedrock、geology、mineral对其主要描述内容进行语义标记。
3 实验验证
为验证基于MIMLBoost的OGC地理信息服务的语义检索系统的查准率和查全率,采用来源于OneGeology[13]开放网站和美国地质勘探局(USGS)数据共享中心[14]的300条可正常访问的地理信息服务数据。用户在执行检索界面查询“mineral”时,查询关键字通过地质矿产本体库扩展,获取该查询关键字的本体词集,检索结果界面检索出与“mineral”及与之相关的本体词集相匹配的所有地理信息服务,检索结果如图2所示。

图2 以“mineral”为关键字的检索结果
该文分别基于GeoNetwork[15]检索、基于MIMLBoost学习框架的语义检索和MIMLBoost匹配与本体库结合的检索3种方式进行实验,其对应的查全率和查准率如图3所示。

图3 基于“金属矿”为关键字检索结果对比
与基于GeoNetwork的查询结果相比,在应用基于MIMLBoost学习框架的语义检索后,查全率与查准率两个指标都有较大程度的提高,分别提高了10%和7.86%;而将基于MIMLBoost的多示例多标记的学习框架、TF-IDF加权算法与地质矿产领域的本体库结合后,OWS查全率与查准率与基于GeoNetwork的查询相比分别提高22%和16.34%,达到92%、93.48%,对OGC Web Service地理信息服务检索的查全率与查准率有较为明显的提高。
4 结束语
OWS地理信息服务的元数据描述是基于XML的文件,包含大量的领域信息,但目前所使用的面向OWS的检索软件仅基于关键词层面,而无法发现其蕴含的语义信息。该研究通过将MIML与地理本体相结合的方式,实现了面向OWS地理信息服务的语义层面的检索,解决了用户在查询应用地理信息服务时,难以获取其真正所需的OWS数据的问题。该方法无论在查全率还是查准率方面都有较大程度的提高,为OWS地理信息服务语义检索相关研究提供了一种参考思路。
猜你喜欢
作文周刊·小学一年级版(2023年40期)2023-10-18 08:07:57
华人时刊(2022年1期)2022-04-26 13:39:28
新世纪智能(语文备考)(2019年10期)2019-12-18 02:46:14
山东冶金(2019年5期)2019-11-16 09:09:22
动漫界·幼教365(大班)(2019年10期)2019-10-28 01:54:09
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
中学生数理化·七年级数学人教版(2018年9期)2018-11-09 01:24:56
专利代理(2016年1期)2016-05-17 06:14:36
智能计算机与应用(2011年4期)2012-05-15 02:24:18
质量与标准化(2010年5期)2010-05-03 04:15:40
