
基于Logistic回归算法的滑坡预报模型
2021-07-04 07:57:50陈曙东
微处理机 2021年3期
陈曙东
(西安工程大学电子信息学院,西安 710600)
1 引言
滑坡、泥石流等地质灾害作为目前影响我国人民生命财产的重要威胁来源,其发生有规模大、范围广的特点,且具有突发性[1-2]。特别是在丘陵山区,地壳运动剧烈,同时由于人类对山区进行改建扩建等相关活动,地质灾害频繁发生。根据2005~2019年我国灾害发生的相关数据的分类统计,滑坡灾害类型的发生占比达到了72.16%,因此预测滑坡灾害的发生是非常有必要的[3-4]。我国学者针对滑坡灾害的研究虽晚于国外学者,但成果显著。于怀昌[5]将物联网技术应用于多传感器组网中,在栾川魏家沟滑坡实时监测项目上得到了应用,为滑坡成灾参数选取提供一种新的可行性判据。但已有的模型都存在模型单一、预测精确度较低等问题。随着科技不断进步,新的预报模型不断涌现,集成学习算法逐渐被广泛应用。王茜[6]等人在多个数值预报模型的基础上建立了集合预报模式系统,使得空气日均浓度模拟相关系数达到了0.5~0.6,相关成果在上海世博会的空气质量预警中得到了应用,取得很好的效果。针对影响因素的选取问题,汪国新[7]、黄亮[8]、陈乐瑞[9]等引入了核主成分分析法,通过该方法对影响因素进行降维,筛选出主要影响因素,降低了模型复杂度,避免了维数灾难等问题的产生。
在此以陕西省山阳县相关监测数据为研究对象。山阳县位于陕西省东南部,地处秦岭南麓,是一个“八山一水一分田”的土石山区。在地形上,呈现出“三山夹两江”的特点。这也导致了研究区地质灾害发生较为频繁的特点,地质灾害造成的损失严重的影响了人民群众的生命财产安全。采用核主成分分析法选取预报参数,基于Logistic回归算法建立了基于滑坡灾害发生概率预报模型,并将该模型成功应用于陕西省山阳县滑坡重点灾害实验区,为滑坡灾害的预报及治理提供了一条新思路。
2 滑坡预报相关理论
2.1 KPCA核主成分分析法
通过对陕西省山阳县地质灾害的影响因子做相关的调查和分析[10],发现影响因子不仅与地质条件或者山体内部的岩层有关,与部分外部因素也存在一定的关系,但是这些因素对最终的影响结果也存在差异。对此,通过核主成分分析法[11]筛选得到影响滑坡灾害的主要因子,将各个影响因子根据重要性进行排序和选择,减少了模型训练时间。由于在高维空间中成灾因子的选取是一个非线性的问题,KPCA方法易于处理非线性问题,特别是对于高维空间中成灾因子的选取上有一定的优势,在降维筛选中应用广泛。KPCA方法实现的具体过程如下:
令样本集为:X={x1,x2,...,xM},其中xk∈RN为列向量;M为样本总数。协方差矩阵如下式:

其中,φ为满足的非线性映射。
对C进行特征分解:令λν=Cν;其中特征向量ν是由φ(x1),φ(x2),...,φ(xM)组成的空间。
当所有特征值λ≥0时,得到表达式:

式中:k,r=1,2,...,M,νr为φ(x)的线性组合:

定义M×M维矩阵K,定义内积为Kij=<φ(xi)·⋅φ(xj)>,式中i,j=1,2,...,M,将式(1)和式(2)带入式(3)得到:

其中,Mλr和cr是对应于K的特征值和特征向量。求得样本φ(x)在特征向量的投影:
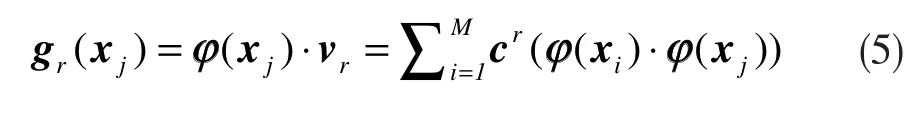
式中,r=p,p+1,...,M,g(x)为对应于φ(x)的非线性主元分量,所有投影形成一个矢量。
求解g(x)时,利用Mercer定理,使用核函数:
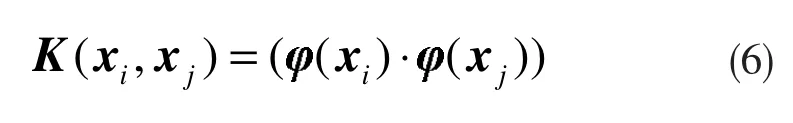
代替空间的点积运算,则:

当φ(x)的均值不为0时,空间样本变为:

最后按照如下二式计算各成分的贡献率Q及累计贡献率Qall:

2.2 Logistic回归算法预测模型
Logistic回归(逻辑回归)算法是一种广义的线性回归分析模型,由于其易于实现、解释性好、容易扩展等优点广泛应用于概率预测领域。和一般线性回归模型不同的是,逻辑回归模型是通过sigmoid函数将输出的值限定在区间[0,1]上。算法中引入的sigmoid函数形式如下:

线性回归模型为:z=wTx+b;逻辑回归模型是在线性回归的基础上,使用sigmoid函数,将线性模型的结果压缩到[0,1]之间,使其拥有概率意义。因此逻辑回归函数可变换为:

对公式(12)取对数得:

在给定样本x的条件下,将该样本类别为1的概率视为类后验概率。因为:P(y=1|x)+P(y=0|x)=1,则公式(13)可重写为:

给定训练数据集Z={(x1,y1),(x2,y2),...,(xN,yN)},其中xi∈RN,yi∈(0,1)用极大似然估计法估计模型参数w。设P(y=1|x)=f(x),P(y=0|x)=1,已知似然函数,则对数似然函数为:
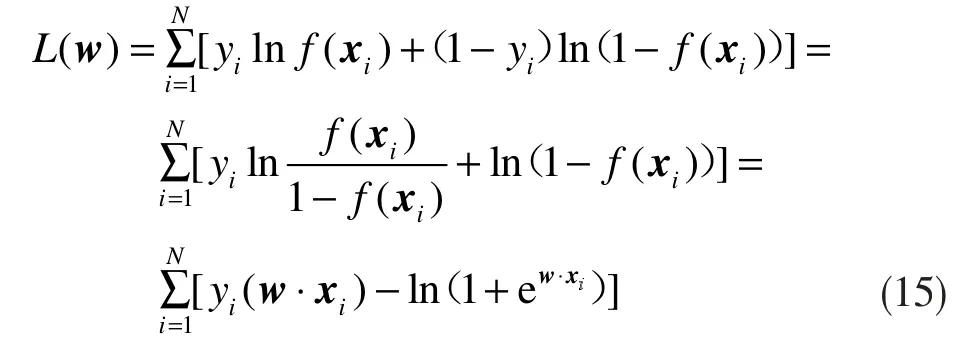
对式(15)对w求偏导,令L(w)=0,便可求解出w:

由于L(w)为上凸函数,对式(16)乘以-1,即可变为下凸函数,此时利用梯度下降法求解最小值,即:


3 滑坡预报模型应用
3.1 影响因子的选取
出于实验需要,选取陕西省山阳县地质灾害监测点的监测数据作为模型数据集,采用前80%的数据作为训练集,后20%的数据作为测试集。通过对数据的初步筛选,共选取100组样本作为滑坡预报模型的数据集。选取前80组数据作为滑坡预报模型的训练集,后20组数据作为测试集,用来验证预报模型的准确性。通过相关资料分析得到影响滑坡发生的12个主要影响因子:土壤含水率;雨量流量;坡形特征;温湿度;斜坡倾角;降雨量;裂缝位移;区蒸发量;岸坡水文地质条件;高程;孔隙水压力;土压力。对研究区监测点的历史数据进行研究,利用归一化的方法对数据进处理,随后采用KPCA方法进行筛选。
根据相关工程实践经验,将滑坡体影响因素的主成分累积贡献率设定在80%。贡献率计算结果如表1。可见,前6个影响因素的累计贡献率已经满足实验设定要求,因此将这些影响因子作为预报模型的输入参数。

表1 滑坡体影响因素特征值及各主成分贡献率
3.2 模型验证
在上述因子选取的基础上,选取降雨量、土壤含水率、土压力、裂缝位移、斜坡倾角、高程这6个变量作为滑坡预报模型的主要输入变量,所构建的样本模型结构如图1。在此模型基础上,利用逻辑回归算法对滑坡发生概率进行训练。部分样本数据如表2所示。

图1 训练样模型构建

表2 部分样本数据
将验证的20组数据数据输入上述模型进行验证。预测值与实际值的对比情况如图2所示。

图2 模型预测结果对比
由图可见,Logistic回归算法预测值与实际值较为接近,仅部分值存在差异,相关预测结果满足实验预期。所建模型已成功应用到山阳县重点灾区实验区,展示出了较高预测准确率和良好的收敛性。
4 结束语
首次将Logistic回归算法应用到滑坡灾害概率预测中。通过详细讨论KPCA核主成分分析法及建立Logistic回归算法预测模型,采用了KPCA方法将初始12种滑坡灾害影响因子降维至6维,降低了模型结构复杂度,避免维数灾难的发生,所建立的预报模型采用陕西省山阳县的部分监测点的实验数据进行了验证。然而预测灾害发生时间的方法还需进一步深入研究。后续工作的重点应放在寻找针对与时序具有相关性的预测模型进行研究,从而更准确、更有效的对滑坡灾害发生时间点进行预测、预报。
猜你喜欢
江苏安全生产(2022年8期)2022-11-01 09:15:18
江苏安全生产(2021年6期)2021-08-05 07:47:14
河北地质(2021年1期)2021-07-21 08:16:08
商场现代化(2021年6期)2021-05-28 14:14:24
江苏安全生产(2020年5期)2020-06-15 09:38:52
当代陕西(2018年24期)2019-01-21 01:24:14
新西部下半月(2018年10期)2018-11-16 12:35:42
北方交通(2016年12期)2017-01-15 13:52:59
水利科技与经济(2016年6期)2016-04-22 05:07:30
陕西林业科技(2016年3期)2016-04-06 03:47:10
