
一种基于XQuery的运行专门化处理算法
2021-07-03 01:19陈俊祺
建材技术与应用 2021年3期
□□ 陈俊祺
(武警山西总队参谋部,山西 太原 030012)
引言
随着越来越多的信息被存储、交换和使用XML呈现,查询XML数据源的能力变得越来越重要。为解决这一能力需求,W3C XML查询工作组设计了XQuery程序语言。它是一种函数式语言,查询简便,易于理解,应用灵活,可以查询广泛的XML信息源,包括数据库和文档。XML近年来已经成为Web上数据表示和交换的事实标准,对XQuery处理效率的要求也越来越高。在XQuery的研究领域中,已经开发出一些新技术,用于提高处理效率,但在这一领域中很少用到“部分评估”的优化技术。为了找到一种提高XQuery处理效率的新方法,扩展了“部分评估”技术的应用范围,进一步研究了XQuery语言的部分评价技术。
部分评估,也称为“程序专门化”,是一种专门的程序转换技术。给定一个源程序和一个称为“静态输入”的输入数据一部分,部分评估根据在使用静态输入分析程序后提取程序中的不变量,生成一个剩余程序。当应用到剩余输入数据时称为“动态输入”,剩余程序产生的结果与源程序在应用于所有输入时所产生的结果相同,通常情况下,剩余程序运行比原始程序快。第一个关于程序专业化的应用出现在1980年代早期,在随后的几年里,大多数研究人员在编译时和源代码中探索了该技术,但是编译时专门化技术并不适合于应用程序领域,而用于专门化程序的不变量只能在运行时处理。因此,一些研究人员在运行时开发了一些专门的程序。在XQuery的应用程序领域中,动态生成的查询被广泛采用,如使用XQuery与Java API(XQJ)的应用程序。在XQJ中,xqpreparedex抑制的执行过程被分为两个阶段:准备阶段和执行阶段。准备阶段相当于XQuery中的静态分析阶段,在该阶段中,静态类型检查或其他静态分析可以为已完成的XQuery程序完成;与动态阶段相对应的执行阶段,在这种情况下,当“executeQuery()”方法被调用时,查询的值会被多次评估,而不需要再次静态地重新分析表达式。在运行XQJ时,数据源通常在准备阶段被知道,这可以被看作是查询的不变量。因此,可以使用运行时专门化(RTS)来提高查询的执行效率。
为此,本文设计了一种名为XQPE的XQuery编程语言的离线部分评估系统。XQPE在编程语言上扩大了部分评估技术的应用范围,使用XQuery及其应用程序,其中包括基于RTS的XQJ应用程序框架。
1 技术背景
Hornof L等[1]已经为C程序开发了一个部分评估器,名为Tempo,一个离线的部分评估器。它也不会在运行时只在编译时崩溃时专门化程序。在C程序中,有些值不能被编码到剩余程序中,应该作为非liftable(如C程序中的指针)进行注释。为了确保正确的专门化,Tempo使用评估时间分析来查找那些非liftable值。
DyC是基于特定运行时间的基于注释的C系统。其执行动态编译,在用户控制关键决策的情况下,对程序转换的灵活和系统的部分评估模型进行了动态编译。他们的注释设计是通过搜索一组灵活的原始指令来管理动态编译的,这适用于人类程序员和工具。与Tempo相比,DyC分析处理的是标量局部变量,但全局变量、指针或数据结构,DyC使用特殊编译器的专用变体,而不是像Tempo那样在现有的标准编译器上使用。
Lee P等[2]建议对法比尤斯的研究比DyC和Tempo更有限。在运行时,将在XML中编写的普通程序转换为本机代码。但与DyC和Tempo不同的是,FABIUS自动执行所有动态编译优化,没有附加注解;动态编译过程中涉及的权衡不是用户控制的。
Hidelhiko H等[3]提出了一种字节码专门化(BCS)技术,该技术可以在运行时对Java虚拟机(JVM)语言程序进行专门化。其二进制时间分析算法直接处理字节码程序,使BCS独立于源代码级语言和编译器的内部。
在部分评价技术中,特别是在运行时专门化研究的基础上,研究了XQuery编程语言离线部分评价的编译时间和运行时专门化。
2 知识准备
作为一种新的函数语言,XQuery有一些不适合程序专门化的特性。为了解决这些问题,引用敏感性分析(RSA)和两相结合时间分析(BTA),以确保精度和提高专门化的正确性。RSA和两相BTA的详细描述在文献[4]和文献[5]中都有表示。
2.1 敏感性分析
在XQuery表达式的基本构建块,和其值都是存储为XML数据模型(一棵树)实例[5],由无约束的节点和/或原子值序列,如XML片段由节点值,表示数字“5”是由原子值5。在程序专门化中,通常对静态表达式的值进行常量折叠以生成剩余程序,这意味着这些值应该在剩余程序中进行编码。这就很容易对一个原子值进行编码,比如使用数字“5”来表示原子值5,但是没有适合的形式来编码XML节点。其原因是一个节点不仅包含XML片段的字符串值,还包含一些有用的语义信息,如节点标识和文档顺序。为了在剩余程序中对节点进行编码,除了使用构造函数操作将节点重构为XML片段之外,没有其他选择。然而,新的重构XML片段仅复制了字符串值,并且丢失了原始节点的一些语义信息,但很少有表达式通过使用XQuery中的信息计算出它们的值。如节点比较操作(“《”、“》”或“is”)需要两个参数的文档命令来完成,计算示例见表1和表2。

表1 生成错误的表达式(示例1)

表2 生成正确的剩余表达式(示例2)
表1显示了不能为节点进行专门化的情况。在表1的A示例中,“S|m”的节点比较“是”将专门用于剩余程序。“S|m”的文档顺序已经丢失(实际上,“S|m”的新构造段将被视为一个新文档,并被分配给一个新的文档顺序),因此,比较不同文档的节点是没有意义的,对应的剩余程序结果,见表1。B示例一定是一个错误的结果。这意味着即使它们的绑定时间是静态的,一些表达式也不能专门化。相反,表2显示了“S|m”的值可以按传统方式进行专门化。
从表1和表2中可以发现,如果任意地对所有节点进行特殊化,可能会出现一些操作需要丢失信息错误的专门化;如果只是简单地禁止节点的所有专门化,那么XQuery专门化的精度将会非常糟糕,因为大多数表达式的结果都是XQuery中的节点。
参考敏感性分析(RSA)发现并注释了计算将满足重建后语义信息丢失问题的表达式。在RSA之后,specializer将会得到表1中“S|m”的信息,不能专门化,但是表2中的“S|m”可以专门化,这意味着专门化的正确性和精确性可以在一定程度上得到保证。RSA的详细信息帮助专家实现了高效专业化[4]。
2.2 两个阶段绑定时间分析
RSA给出了信息,这些状态对每个被称为“引用-敏感状态(RSA)”的表达式进行了注释,以指出当它的绑定时间为静态时,表达式是否可以专门化。这意味着传统的BTA需要扩展。因此,设计了两个阶段的绑定时间分析,前一个阶段是BTA1,在这个阶段中,表达式被识别并标注了绑定时间分析状态(BTAS),它只依赖于配置中可用的静态参数值,以及程序中可用的静态信息(如常量);后一阶段是BTA2,用于根据BTA1给出的RSA和BTAS对表达式进行修改。
在表1中,在做了RSA之后,“S|m”被标注为RSA—FALSE,这意味着这个变量不能专门化。在执行BTA1之后,“$m”被注释到BTAS(静态的),然后在执行BTA2之后,BTAS“S|m”将会修改到最后的BTAS,即根据注释的RSA和BTAS保留。相反,表2中的“S|m”将被注释到最终的BTAS-STATIC,在完成RSA之后,它给出了RSA—TURE、BTA1、BTAS-STATIC。因此,表1中的变量“S|m”不能专门化,但它的对等物可以专门用于表2。
示例1和示例2的正确结果见表3。

表3 示例1和示例2的正确结果
3 运行时专门化
特定编译(compile-time specialization)目前已经被成功应用。试验结果表明,XQuery程序的效率可以显著提高。在特定编译中,不变量或静态配置被接受用于专门化;但在运行时应用程序可以在执行过程中给出信息。如在XQJ应用程序中,数据源和XQuery程序都是在准备阶段实现的,可以提取这些信息进行专门化处理。因此,为了在此场景中扩展XQuery专门化,将相应地研究运行时专门化技术。
3.1 运行时专门化
在预处理之后,解析的抽象语法树(AST)中的每个表达式都带有一个绑定时间。在特定运行时间中,对静态状态的表达式进行了评估,并在AST中完成了相应的结果,最后将AST转换为剩余代码,即Java字节码级别。设计以下步骤来实现特定运行时间:
(1)解析XQuery源代码到AST。
(2)评价AST中静态表达式的值。
(3)在全局环境中存储这些值。
(4)使用特殊的数据挛缩,称为孔洞,代替AST中评估的表达式。
(5)在全局环境中添加对孔的绑定和相应的值。
(6)用Java字节码来编译AST,Java字节码可以直接在Java虚拟机(JVM)上运行。
完成这些任务后,即完成了专门化并生成字节码级别的剩余程序。在JVM上运行剩余程序时,需要从全局环境中加载所需的孔值。
表4显示了运行时专门化和编译时专门化的比较。为了简单地表示,将使用PSEUDO代码来表示运行时专门化的结果。在表4的A中,“OP:CON”是AST中的一个表达式。参数“S|m”被一个洞取代,这里是孔(2)。孔中的参数“2”表示绑定值的索引。当执行剩余表达式时,JVM将从这个孔获取索引值。在表4的B中,编译时专门化显示了“OP:CON”与“S|m”的值应该编码到XQuery代码。

表4 运行时专门化和编译时专门化
XQuery运行时特殊化原型系统如图1所示,其包括三个部分:
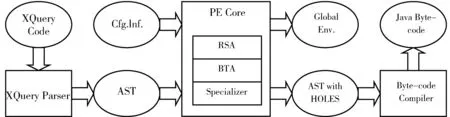
图1 XQuery RTS模型系统
(1)XQuery解析器,其输入是XQuery源代码,并输出相应的AST。
(2)XQuery部分评估核心,其输入是由配置和AST提供的不变量,其输出是具有漏洞的AST和存储索引值的全局环境。
(3)字节码编译器将AST编译成Java字节码,它使用全局环境在JVM上运行时获得索引。
3.2 代码爆炸控制
在专门化过程中,展开循环可能导致代码爆炸,这是部分评估中的一个关键问题,至今还没有一个简单有效的方法来解决该问题。在运行时专门化中,值将不会被编码到XQuery代码中,并且只保留它们的内存实例,因此在执行递归函数调用和多级“FLWOR”表达式时,会发生代码爆炸。拟使用保守的策略在一定程度上控制代码爆炸。该策略包括两个主要方面:
(1)递归函数调用的控制。使用一个动态分支状态(DBS)来标记递归函数调用,如果它属于一个“if”表达式的一个分支(也包含“typeswitch”表达式),并且它的条件绑定时间不是静态的,那么将这个函数标记为一个真实的状态,否则标记为FALSE。这意味着当为递归函数调用进行专门化时,专门化器首先检测DBS,如果DBS为真,那么它生成一个专门的函数,但不会在剩余程序中展开这个递归函数。
(2)多级“FLWOR”表达式的控制。使用阈值来控制“FLWOR”表达式是否应该展开。当专门化一个多级别的“FLWOR”时,首先检查“FLWOR”中的每个“for”子句的值,如果该值的长度大于阈值,则该“for”子句的专门化将被取消;扩展了该子句来进行专门化处理。
4 应用示例
4.1 XQJ应用程序框架
Java的XQuery API目前在Java Community Process的开发中作为JSR 225,提供了应用程序开发人员使用XQuery进行XML处理和数据集成应用程序的机会,并充分支持Java SE和Java EE平台。XQJ允许Java程序连接到XML数据源,准备和执行XQuery程序,并将查询结果作为XML文档进行处理。这个功能类似于SQL的JDBC Java API,但是XQJ的查询语言是XQuery。
用Java语言描述的程序代码见表5。此代码段仅限于表述XQJ API的使用方法,不是详尽或完整的程序段。如假设“xqds”表示一个给定数据源的“XQDataSource”对象。它说明了Java应用程序执行XQuery表达式的基本步骤(第12和17行),并在给定的XQuery实现中执行第8和第13行调用的绑定变量。

表5 一个XQL示例
这是一个典型的应用场景,在只有一些输入值改变的情况下,该应用程序可以多次执行一个查询。XQJ给出了准备表达式的概念,只有一次静态分析时可以多次执行,而不需要每次都静态分析一遍(见代码形式4~10行)。所以,XQPreparedExpression的准备阶段可以用于做专业化。而XQuery中的外部变量,通过使用接口bindXXX()绑定到动态值,可以看作是专门化的动态输入。比较第11~14行和第16~18行的代码段,只有bindInt()中的值是不同的,其他代码是相同的。在XQPrapredExpression中,“fn:doc('catalog.xml')”、“/prince”和“/name”的表达式在运行时不会再次发生变化,这些都被视为专门化的不变量。显然“XQPreparedExpression”的处理非常适合做部分评估。此外,在Java应用程序中,查询可能是动态接受的(如来自网络、I/Os,甚至是程序创建的)。
运行时专门化非常适合为XQJ应用程序进行优化。为此开发了一个XQJ应用程序框架如图2所示,其中XQuery处理是通过运行时XQuery专门化来优化的。
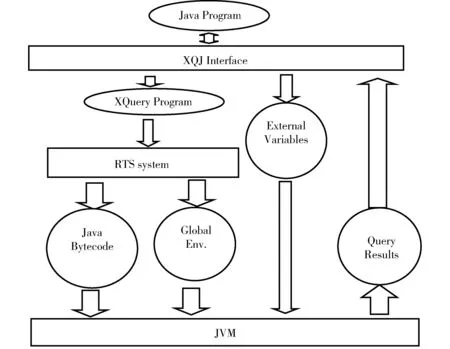
图2 基于RTS的XQJ应用程序框架
图2描述了基于RTS的XQJ应用程序框架。该框架有三个主要部分:
(1)XQJ接口。它接受java对象实例,其中存储了XQuery源代码。它的输出包括净化XQuery程序和外部变量,这些变量的值将被视为动态输入。所有这些对于用户都是透明和自动处理的。它还接受由JVM返回的Java对象实例的最终结果,并将结果输出。
(2)RTS专业化系统。它接受自动净化的XQuery程序进行专门化。在专门化之后,它会输出剩余程序(Java字节码)和相应的全局环境。
(3)JVM。它使用被接受的剩余程序和全局环境来完成计算和返回查询结果。
4.2 结果验证
测试条件:分节的标题应该是新罗马12点的粗体,只有首字母大写(注:对于子分段和次子分段,像the或者a等单词不大写,除非是分段头的第一个单词才大写。)
基于运行时专门化的XQJ已经实现,并进行了一系列的验证,以测试该工作是否能够真正提高XQJ的执行效率。下面使用14个案例在三个不同的XQJ实现中运行:
A组:在XQJ实现中,当执行exectueQuery()方法时,XQuery程序由一个解释器执行;
B组:在XQJ实现中,XQuery程序是在准备阶段编译的,然后在调用executeQuery()方法时执行它;
C组:在XQJ实现中,XQuery程序在准备阶段通过RTS进行优化,然后在调用exectueQuery()方法时执行。
所有的案例都运行在一个具有1 GB物理内存的Inter Pentium PIV-1.6处理器上。执行时间如图3所示,C组大多数病例的执行时间均小于其他两组。C组的平均执行时间为23.9%,B组为40.5%。这意味着RTS可以显著提高XQJ的处理效率。
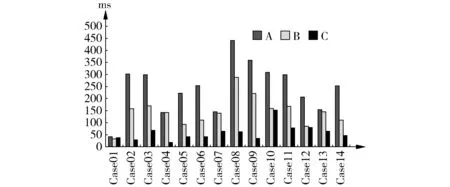
图3 三组执行时间比较
5 结语
全面介绍了一种用于XQuery编程语言的运行时专门化技术。在运行时专门化的预处理阶段,使用引用敏感性分析来发现和注释值将参与计算的表达式,这些表达式需要语义,并且这些表达式不应该在剩余程序中专门化和编码,即使它是一个静态表达式。相应地,绑定时间分析不仅根据配置参数和其他静态信息对表达式进行注释,而且根据引用敏感性分析状态对表达式进行重新注释。在专门化阶段,首先在AST中添加了一个带有索引的漏洞,以专门化静态表达式,生成一个全局环境,该环境存储被索引的专门化值,然后将此AST编译成Java字节码。一个保守策略用于防止递归函数的无限特殊化,并使用阈值来控制“for”子句的展开。开发了一个XQuery运行时专门化原型系统。
在应用领域,基于运行时专门化设计并实现了XQJ应用程序框架。测试结果表明,RTS可以显著提高XQJ应用的执行效率。XQuery程序的运行时专门化的研究并成功地将其应用于XQJ接口,从而扩大了部分评估的应用范围。为大多数应用程序需求提供了XQuery程序的编译时和运行时专门化。但是也有一些重要的后续工作要做,如利用XQuery表达式的类型信息来提高绑定时分析的精度,这可以从XML文档的XML模式中推断出来。
猜你喜欢
销售与市场(营销版)(2021年10期)2021-11-21
数学物理学报(2020年2期)2020-06-02
安顺学院学报(2020年1期)2020-04-05
销售与市场(营销版)(2019年6期)2019-06-21
现代计算机(2019年6期)2019-04-08
学术论坛(2018年4期)2018-11-12
网络安全技术与应用(2017年9期)2017-09-20
戏曲研究(2017年4期)2017-05-31
人民周刊(2016年14期)2016-08-02
当代修辞学(2013年3期)2013-01-23
