
基于肤色学习的多人脸前景抽取方法
2021-07-02 08:54戴嫣然戴国庆袁玉波
计算机应用 2021年6期
戴嫣然,戴国庆,袁玉波,2
(1.华东理工大学信息科学与工程学院,上海 200237;2.上海大数据与互联网受众工程技术研究中心,上海 200072)
(∗通信作者电子邮箱dyr136006@163.com)
0 引言
如今,随着信息社会的发展,图像变得越来越重要,人脸又是图像中的一个重要的分支,人脸信息在人脸跟踪、人脸识别、视频监控等领域有着重要的应用。人脸检测是人脸识别的第一步,人脸检测的准确性直接影响到后面任务的可行性和效率,因此抽取正确的人脸信息是十分重要的。如何快速地提升人脸识别系统对不同人种的检测性能,是一个实用的人脸识别算法应该考虑的问题[1]。在复杂的图像中检测人类皮肤已经被证明是一个具有挑战性的问题,因为由于许多因素,如光照、种族、老化、成像条件和复杂的背景,皮肤颜色在其外观上可以有很大的变化。
颜色是简单、直观且有效的特征,颜色特征常常用于人脸检测,不同颜色空间的选择带来的结果也有所差异[2]。Hsu等[3]提出了在YCrCb(Luminance,Red-difference Chrominance,Blue-difference Chrominance)颜色空间的人脸检测,通过非线性变换,将像素投射到YCrCb空间,并用椭圆区域判断是否为肤色像素。Shaik 等[4]使用两种颜色空间进行皮肤检测的对比研究,认为HSV(Hue,Saturation,Value)颜色空间在简单背景和均匀背景下的检出率较高,而YCbCr 颜色空间在复杂背景下的检出率较高。Pujol等[5]提出基于模糊熵肤色分割的人脸检测,在RGB(Red,Green,Blue)、YCbCr和HSV 三个颜色空间进行人脸学习和模糊系统建模,最后进行人脸的检测。Bencheriet 等[6]使用肤色分割,结合局部二值模式(Local Binary Pattern,LBP)特征和高斯混合模型(Gaussian Mixed Model,GMM)模型,对人脸进行学习,然后抽取人脸。肤色特征的使用是十分重要的,是快速、有效定位人脸大致位置的方法。不同的肤色抽取策略对分割效果也不一样,目前没有明确的最佳颜色空间选择方案,本文的研究目标是提出一种新的颜色空间融合方案,为肤色抽取提出新思路。
人脸的定位一直是人脸检测的难点,基于内容的人脸检测一般使用人脸特征如眼睛、嘴巴等,构造人脸模板进行匹配。模板的大小可以使用人眼间距和人脸的比例、人脸长宽比等生物特征进行确定。早期,Brunelli 等[7]用模板匹配的方式,计算鼻子的长宽、嘴的位置和下巴的形状来进行人脸识别。Jin等[8]设定了脸部模板,由人脸框和人眼组成,然后在肤色分割后的候选区域内进行人脸检测。胡祖奎等[9]提出了一种基于分层模板的人脸检测方法,结合肤色信息和脸部分层的特征,构造人脸结构的参数,检测校园监控中的人脸。Luo等[10]使用分类决策树模型,对人脸进行初步定位,然后结合人脸肤色的概率分布,得到人脸肤色区域。Wang等[11]将肤色分为深色和浅色两种分类,并添加深色通道辅助肤色提取,然后使用模板匹配和人眼定位,将人脸框出。
不同人种的肤色信息略有差异,在肤色检测时的策略也不同,人种的肤色信息的主要差别是亮度。Tan 等[12]提出一种融合算法,结合了2D直方图和高斯模型,分亚洲人、非洲人和欧美人三个人种,在对数颜色空间(Log Opponent chromaticity space,LO)中进行肤色分割。Klevan 等[13]提出了不同的颜色空间融合方法,并将人脸分成非洲人、亚洲人、欧美人和其他人种四个分类,最后用阈值滤波器将非肤色像素剔除,从而得到肤色像素。合理地对肤色进行分类和检测是重要的,将肤色根据人种进行分割可以得到更加完整的肤色前景。
目前利用深度学习进行人脸检测的方法已经很多,Hao等[14]使用不同比例的网络计算出图像中人脸的尺度分布,然后按照该尺度归一化图像,再进行人脸检测。Hu等[15]从尺度不变性、图像分辨率、上下文推理三方面对小脸检测算法进行改进,得到很好的效果。Li等[16]提出对偶的人脸检测器,对特征进行增强,并改进锚点匹配策略,模型具有极高的鲁棒性和稳定性。目前的深度学习算法大多针对人脸检测,较少有人脸内容抽取的方法,人脸抽取相关的数据集也不足,用深度学习实现人脸抽取较困难。本文提出遗传算法,对人脸内容进行计算,判断人脸区域,对内容进行抽取,不依赖大量的数据集,也可以完成人脸抽取。
在多人场景下,根据颜色信息进行肤色分割在多人脸或复杂背景下容易失效,不同人种的检测率也不一样,白色人种和黄色人种的检测率最高。因此,为了解决不同人种的肤色分割问题和人脸抽取不完整的问题,本文提出基于肤色学习的人脸抽取方法,将肤色按照四种人种进行分割,分别是白色人种、黄色人种、棕色人种和黑色人种,并结合人脸生物特征,对人脸范围进行判断和框定,同时,利用遗传机制的思想,将人脸从肤色前景中抽取得更加准确和完整。
1 基于肤色学习的多人脸前景抽取方法
本文提出一种基于肤色学习多人脸前景抽取方法,其技术框架如图1,关键思想是对不同人种的肤色进行学习,根据学习得到的参数和阈值进行肤色前景分割,并利用遗传机制的思想,结合肤色信息,将人脸区域进行生长,得到较为完整的人脸前景。

图1 基于肤色学习的多人脸前景抽取方法流程Fig.1 Flow chart of multi-face foreground extraction method based on skin color learning
首先,建立基于肤色学习的肤色分割模型。本文将人种分为四种:白种人、黄种人、棕种人和黑种人,从各种图像中抽取不同肤色人种的肤色块,对肤色块进行颜色空间的转换和像素分布分析,可以得到肤色像素的分布情况,从而计算肤色阈值,构造肤色模型。
其次,对输入多人脸图像进行光线补偿。真实场景照片会受到不同光线的影响,图像中可能会存在光线不平衡的情况而造成色彩偏差,为了抵消这种整个图像中存在的色彩偏差,进行光线补偿。根据建立好的肤色模型,对光线补偿后的图像进行肤色前景分割。
然后,确定遗传机制的初始种子块和生长区域。利用自适应回归窗模型[17],检测人脸特征点,结合肤色模型抽取到的前景信息,选出在人脸前景中的特征点,作为初始种子块,人脸的最大范围作为遗传机制的生长区域。
最后,构造遗传机制的适应性函数,在生长区域范围内进行遗传生长,经过选择、交叉、变异后,可以提取出更加完整的人脸区域。
2 基于肤色学习的人脸前景分割模型
对于给定的包含多人脸的图像I,人脸前景分割的问题定义如下:
定义1对于给定的含有N(N≥3)个人脸彩色图像I,表示如下:
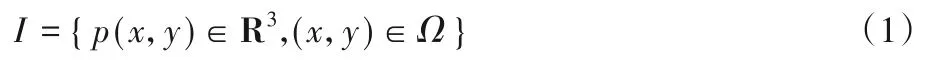
其中:p(x,y)表示(x,y)处的像素值;Ω为整个图像区域。
多人脸前景抽取的目标定义是寻找最优的子集F*⊂I,使得F*里面非人脸的像素点尽可能少,模型表示如下:

其中C(pi)是计算器,记录F*中非人脸像素点的数目,表达式如下:

该问题的关键在于如何判断pi是人脸点。事实上,多人脸前景抽取模型可以等价定义为区域分割问题,即寻找Ω的N个子集Ωi(i=1,2,…,N),满足:

人脸前景即为:

也称Ωb为背景。
从上面模型可以看出,每一个人脸区域Ωi应该具备两个重要的特征:首先要是皮肤点,其次要在人脸区域内。从技术层面看,第一任务是从图像I里抽取肤色点,定义为肤色前景。
2.1 肤色前景抽取
肤色前景定义如下:
定义2人脸彩色图像I的肤色前景S定义为其子集S⊂I,使得S里面包含尽可能多的肤色点,模型表示如下:

其中s(pi)是计算器,记录S中肤色点的像素数目,表达式如下:

从上面定义可以看出,肤色前景的关键在于如何判断pi是肤色点,由于肤色是人种的主要特征,不同的人种,肤色有差异,因此这个问题的关键在于以下两个问题:
问题1 地球上常见人种有几类?
问题2 每一种人种肤色均值E(pr)是多少?
根据本文第1 章的叙述,问题1 的答案是四种;但是对于问题2,由于每一种族的个体差异也是比较大的,所以由于样本选择不同其均值必有差异,通过对国际上现有人脸图像进行分析,本文选择了著名的SFA 数据库作为肤色的参考数据库。四种人种肤色样本图片块如图2所示。

图2 四种人种肤色样本图片块Fig.2 Sampled image blocks of four racial skin color
判断种族的模型定义如下:
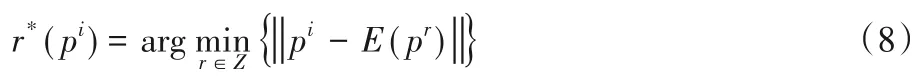
其中E(pr)表示第r种人种肤色的像素期望值。
肤色的像素期望值E(pr)的计算模型如下:

其中c(Nr)表示第r种人种标准样本肤色块的像素点数量。
标准肤色块方差σr定义如下:

由此,第r种人种的肤色点判定区间定义为:

2.2 人脸种子区域抽取
人脸的种子区域定义如下:
定义3人脸种子区域C定义为各个人脸种子区域Ci的并集。
人脸肤色前景S与人脸特征点所围区域G*的交集,使得C中的点均为人脸上的点,模型表示如下:

其中N为人脸彩色图像I的人脸个数。
人脸特征点使用基于自适应回归窗模型的特征点定位方法,抽取初步定位的68个人脸特征点,记为:

其中,Ki为模型抽取到的单个人脸的68 个特征点,1~18 号点为人脸轮廓点,记为Ki*。

将人脸轮廓点Ki*与肤色前景S作交集,在肤色前景S中的点,就作为种子点

最后将各个种子点作凸集合,得到种子区域Ci。因此,人脸特征点所围区域Ci可以定义为:

2.3 人脸再生
根据前面得到的候选人脸前景C,人脸再生的目标是在给定的有效范围内,对不完整的人脸进行像素级的判断,利用遗传机制,生长出完整的人脸区域。

其中r(pi)是计算器,记录Ωi中人脸区域的像素数目。Ei是第i张候选人脸的生长有效范围,确定模型如下:

其中(xi,yi)是候选人脸区域的中心点,计算式如下:
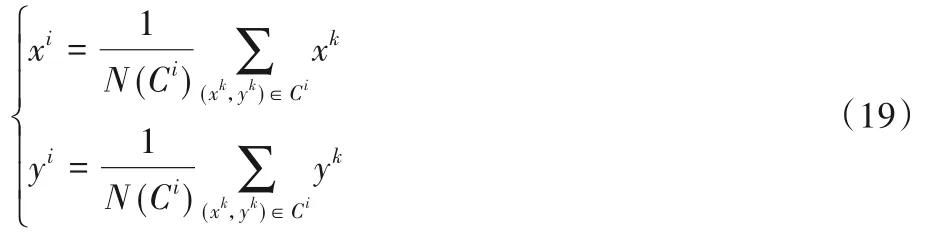
a、b是椭圆区域的短半轴和长半轴,计算式如下:

人脸再生的有效范围如图3 所示。在式(17)中,Ωi的生成采用遗传机制,基本像素生成原理参照文献[18]。

图3 人脸特征点示意图Fig.3 Schematic diagram of face features
3 实验与结果分析
3.1 数据集
本文实验从网络及现有数据库中,随机选择多人脸图像,构建包括100 张多人脸图像的数据集,人脸图像分别来自网络高清图像、Pratheepan Dataset[19]和 BaoDataBase。Pratheepan Dataset 图像是从谷歌随机下载的用来进行人体皮肤检测方法的研究,这些图像是在不同的光照下,并通过不同的色彩增强方法处理得到的。BaoDataBase 由274 张不同场景下的单一人脸和多人脸图像组成。
第一类图像来自网络高清图片,包括不同场景的合照,选取的场景包括室内和室外和合影,共50 张,示意图如图4所示。

图4 第一类图片Fig.4 Images of first class
第二类图像来自Pratheepan Dataset,包括不同家庭的合照,共25张,示意图如图5所示。

图5 第二类图片Fig.5 Images of second class
第三类图像来自BaoDataBase,共25 张,示意图如图6所示。

图6 第三类图片Fig.6 Images of third class
3.2 评价指标及实验结果
本实验的运行环境为:Windows10 64位操作系统,硬件配置是Intel Core i5-7200U 的CPU,2.50 GHz 的主频和8 GB 的RAM,在Python3.6.5的环境中编程实现。
本文采用准确率(Precision,P)、召回率(Recall,R)和Fβ三个评价指标,其计算式如下:

其中:TP表示实际为正、预测成正的个数;FP表示实际为负、预测成正的个数;FN实际为正、预测成负的个数。
Fβ能够很好地评估分割结果的整体性能,计算式如下:

因为人脸前景提取中准确率的重要程度高于召回率,因此这里取β为1,即F1。
准确率越高表示算法返回的相关结果比不相关的结果越多,召回率越高表示算法返回的相关结果越多。Fβ是准确率和召回率的加权调和平均数。Fβ越高表示一个方法在不牺牲精度的情况下越能达到高的查全值。
针对人脸前景区域,选择文献[20]的基于高斯变差的自动前景提取(autoMatic Foreground extraction based on Difference Of Gaussian,FMDOG)方法、文献[18]的基于遗传机制和高斯变差的前景目标提取(FOreground extraction with Genetic mechanism and difference of Guassian,GFO)方法、文献[17]的人脸关键点检测方法和文献[21]的人脸分割方法与本文方法进行收取结果对比。文献[20]方法使用图像分割算子,结合高斯变差提取关键点,构建自动前景目标提取模型。文献[18]方法使用改进的图像分割算子(Normalized cut,Ncut),结合遗传算法,自动抽取前景。文献[21]方法使用维诺图和2D(Dimensional)直方图算法进行人脸分割。三类图片的实验结果如图7~9所示。

图7 不同方法对第一类图片的人脸分割结果Fig.7 Face segmentation results of first-class images by different methods

图8 不同方法对第二类图片的人脸分割结果Fig.8 Face segmentation results of second-class images by different methods

图9 不同方法对第三类图片的人脸分割结果Fig.9 Face segmentation results of third-class images by different methods
文献[20]方法可以提取大部分目标前景,但是前景存在目标缺损或者冗余等问题。文献[18]方法是对文献[20]方法的改进,它可以很好地解决文献[20]方法存在的问题,可以提取到更加精确的目标前景,但是对于人脸前景的提取仍不完整。文献[17]方法主要提取特征区域,提取到的部分肯定为人脸区域,但是会丢失人脸边缘和轮廓信息,缺乏完整性,也无法提取整个脸部区域。文献[21]方法对于单人脸的简单场景效果较好,但是对于室外的场景,会引入非人脸的像素点。本文所提的方法可以有效剔除非人脸的肤色区域,并且将整个人脸区域,包括额头等区域都提取完整,是更加有效的人脸前景抽取方法。
五种方法的准确率、召回率、F1值对比如图10~图12所示。
由图10 可以看出,本文所提方法的准确率明显高于文献[20]方法和文献[21]方法,略低于文献[17]方法。文献[20]方法会存在很多非人脸的区域如脖子、手臂等,结果过于冗余,造成误检率的升高,因此平均准确率为85.6%。文献[18]方法可以更准确提取到前景,减少冗余,因此为人脸的概率很大,因此误检率较少,平均准确率也提升到95.7%。文献[17]方法侧重于人脸特征点的提取,抽取区域基本都是人脸区域,因此误检率较少,但是仍有很多人脸区域无法捕捉到。文献[21]方法基于维诺图和直方图的分割,会引入与肤色像素相近的像素。本文方法可以检测完整的人脸区域,抽取到完成的人脸前景,平均准确率提升至98.4%;但是当头发与背景的颜色和人脸很接近时,会造成误检率的上升。

图10 不同方法的准确率对比Fig.10 Precision comparison of different methods
由图11 可以看出,本文所提方法的召回率稳定优于其他四种方法。文献[20]方法的结果涵盖与皮肤颜色相近的像素,因此漏检率较低,平均召回率为81%。文献[18]方法的结果作为人脸种子块,要确保种子点都在肤色人脸椭圆范围内,因此比人脸小很多,造成了漏检率的升高,平均召回率也相较文献[20]方法要低很多,为57.8%。文献[17]方法抽取人脸主要特征区域,会漏检非特征区域,导致人脸前景抽取不完整。文献[21]方法使用距离变化选择感兴趣的区域,因此人脸区域能有效检出,平均召回率为95.5%。本文所提方法能有效抽取人脸,遗传机制可以补全人脸区域,减少漏检的像素数,但如果人脸在极端光线下,抽取结果较差,导致漏检率升高,平均召回率为89.5%,低于文献[21]方法。

图11 不同方法的召回率对比Fig.11 Recall comparison of different methods
由图12 可以看出,作为准确率和召回率的调和,F1值可以通过使用准确率和召回率来提供对测试表现更现实的度量。可以看出,本文所提方法的F1值均大于其他四种方法,达到87.3%,表明本文方法的总体结果优于其他四种方法,具有更强的可靠性和鲁棒性。文献[17]方法能有效抽取人脸特征,在抽取人脸区域时也具有较好的效果,虽然漏检率高,但是抽取的区域均为人脸区域,降低了误检率,因此F1值为78.2%。文献[20]方法和文献[21]方法的误检率高,文献[18]方法的漏检率高,因此这三个方法F1值的均值在42.2%~70.9%。
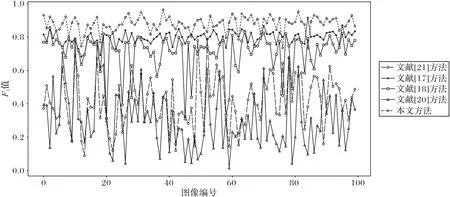
图12 不同方法的F1值对比Fig.12 F1 value comparison of different methods
3.3 时间评估
对100张人脸图像的修复耗时箱型图如图13所示。本文方法在人脸抽取耗时上略多于其他方法。对于所有人脸图像进行实验,文献[20]方法的平均耗时为27.5 s,文献[18]方法的平均耗时为34.6 s,文献[17]方法的平均耗时为4.4 s,文献[21]方法的平均耗时为11.1 s,本文方法的平均耗时为48.4 s。算法耗时与图片像素有关,文献[18]方法与本文方法使用遗传算法,在精确抽取的同时会增加时间消耗。文献[17]方法使用学习好的模型,人脸抽取的速度较快。

图13 不同方法的耗时箱型图对比Fig.13 Comparison of time-consuming box plots of different methods
4 结语
在多人脸场景下,现有基于内容的人脸抽取并不是很完善,无法抽取完整的人脸区域,因此本文提出了基于肤色学习的人脸抽取技术。首先,按照四个人种的肤色进行肤色学习,四个人种分别为白色人种、黄色人种、棕色人种和黑色人种,根据学习到的肤色模型进行肤色分割,可以分割到更加完整的肤色区域;然后,利用遗传机制的思想,结合人脸特征点的先验信息,对人脸区域进行遗传生长,从而将人脸区域抽取得更加完整。本文方法虽然具有较高的复杂度,但其准确率和召回率相较其他方法有明显提升。
未来的工作中,可研究改进遗传种子和遗传区域的选取,基于深度学习进行人脸范围确定,并选取种子点,提高遗传算法的精确度。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
奥秘(2021年5期)2021-06-15
文学港(2021年12期)2021-02-28
好孩子画报(2020年3期)2020-05-14
孩子·小学版(2020年7期)2020-02-24
当代陕西(2019年19期)2019-11-23
小天使·四年级语数英综合(2019年9期)2019-11-09
少年文艺·开心阅读作文(2018年10期)2018-10-16
米娜·女性大世界(2016年8期)2016-08-17
奇闻怪事(2014年5期)2014-05-13
