
一种基于FPGA的感知量化卷积神经网络加速系统设计
2021-06-30 01:43电子科技大学电子科学与工程学院贺雅娟
电子世界 2021年11期
电子科技大学电子科学与工程学院 周 航 贺雅娟
近年来,卷积神经网络(CNN)在机器视觉等方面取得了巨大成功。为提升嵌入式设备上运行CNN的速度和能效,本文针对LeNet-5网络模型,先对该网络模型进行感知量化训练,特征图和权重量化为8位整型数据。然后设计一种卷积神经网络加速器系统,该片上系统(SoC)采用Cortex-M3为处理器,所提出的系统处理一张MNIST图像所需时间5.3ms,精度达到98.2%。
CNN已成功应用于图像识别等应用,随着CNN解决更复杂的问题,计算和存储的需求急剧增加。然而,在一些低功耗的边缘计算设备中,功耗是重要指标。目前的研究主要针对CNN推理阶段模型的压缩和量化。大多数设计都用定点计算单元代替浮点单元。ESE采用12位定点权重和16位定点神经元设计,Guo等在嵌入式FPGA上使用8位单元进行设计。但之前的设计主要采用Zynq或者HLS开发,功耗较大。
本文设计了一种基于FPGA的卷积神经网络加速系统。首先,通过感知量化训练的方法,实现了将浮点CNN模型的各层权重和特征图量化成8比特整型;其次,通过采用单层时分复用的方式,设计流水线架构提高数据吞吐率;再次,设计基于Cortex-M3的SoC;最后,采用MNIST手写数字进行方案和功能验证。
1 卷积神经网络
1.1 基本概念
LeNet-5是一个典型的卷积神经网络模型,不包含输入一共有7层。分别为3层卷积层,2层池化层,以及2层全连接层。
1.2 量化原理
针对目前CNN模型较大,参数多且不适合在移动设备上使用,Google团队提出了一种量化方案。该方案在推理过程中使用纯整。量化方案是量化整数q到实数r的映射,如公式(1)所示:
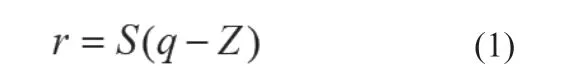
其中常数S和Z是量化参数。S表示比例系数,是一个任意的正实数。Z表示零点。CNN中主要的操作,比如卷积层的卷积,以及全连接层的乘累加,都可以看成是矩阵乘法。考虑实数两个N×N的矩阵r1和r2的乘积r3=r1r2。将每个矩阵ra的项表示为ra(r,j),其中1≤i,j≤N,用qa(r,j)表示量化项,根据矩阵乘法的定义,得到:
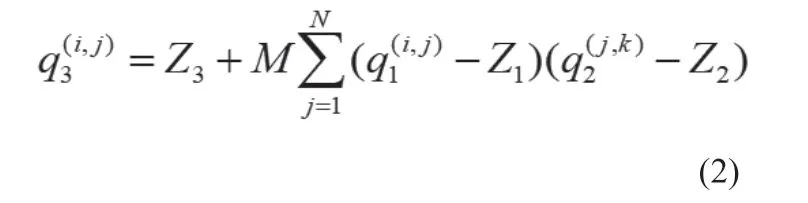
乘以浮点数M,可以转化成先乘以定点数M1,再进行右移n+31。
将公式(2)中所有零点Z1,Z2,Z3都设为0,可以大大简化推理阶段的运算。另外将偏置加法和激活函数合并到其中。比例系数Sbias=S1S2,零点Zbias=0。由于选用的激活函数是ReLU,所以只需要将结果钳位到[0,255]。
2 加速系统硬件设计
2.1 整体结构
本系统采用CPU+FPGA的架构,包括AHB互联矩阵、Cortex-M3处理器、DMA、紧耦合存储器、双端口缓存、AHB2APB桥和CNN加速器,如图1所示。
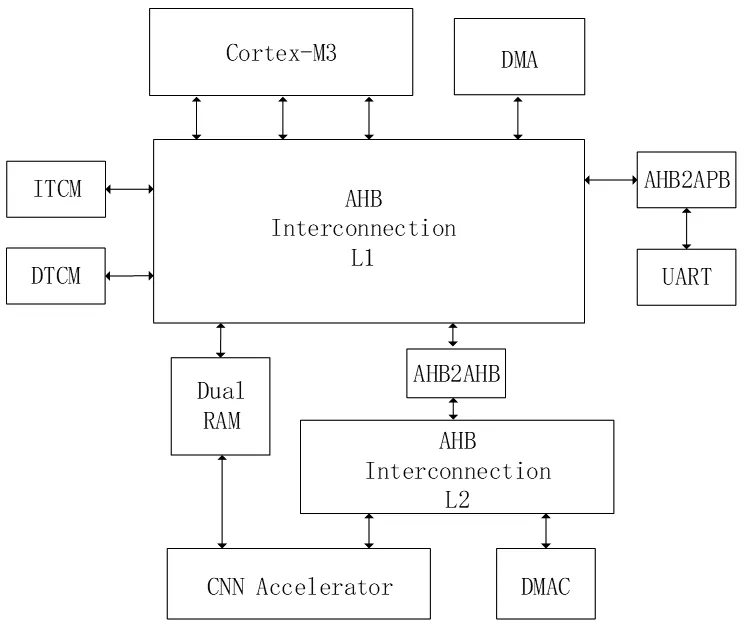
图1 系统框图
存储器部分包含ITCM,DTCM和双端口RAM。ITCM存放程序镜像文件;DTCM作为堆栈区;Dual RAM作为权重数据,输入特征图,以及中间、最终结果缓存区,一端连接L1级总线,CPU和DMA均可以访问,另一端连接CNN加速器。
2.2 CNN加速器设计
CNN加速器设计的整体结构如图2所示,并行方案采用输出通道和权重卷积核内部并行,同时计算6个输出通道,以及卷积核25个乘法器同时计算。
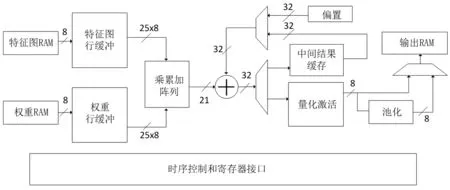
图2 CNN加速器整体结构
特征图行缓冲的窗口尺寸为5x5,可以通过数据选择器选择输入特征图的宽度。权重特征图的行缓冲设计同理,由于卷积核均为5x5,所以不需要数据选择器。
乘累加阵列输入为25个8位特征图和25个8位权重,对应相乘后采用加法树方式累加,最后得到1个位宽为21的有符号数。
偏置加法器用于累加偏置或者中间结果。选择哪一个是由数据选择器控制,输出一个32位结果。
量化激活模块包含一个32x32位的乘法器,用于将累加结果和乘法系数相乘,再经过右移,钳位到[0,255],经过四舍五入得到量化的结果。
池化模块设计思路同卷积模块,采用最大池化。包含3个比较器和一个行缓冲,针对不同层可以选择不同长度的特征图,窗口尺寸为2x2。
3 实验结果与分析
3.1 实验环境
本文采用的FPGA是Xilinx公司的Artix-7XC7A200T芯片,开发环境为Vivado 2018.3。卷积神经网络训练和推理采用Pytorch 1.7.1。实验的数据集是MNIST数,CNN模型采用LeNet-5。
3.2 实验结果
本文的SoC工作的频率为100MHz,识别一张MNIST图片的时间为5.3ms,FPGA的功耗由Vivado的Report Power工具获得,仅为0.448W。本文处理单帧的时间比较长,但是功耗是其他文献的四分之一。由于采用感知量化,识别正确率FPGA实现和软件实现一致,达到98.2%。实验结果对比如表1所示。

表1 实验结果对比
结论:为了解决嵌入式设备上实现卷积神经网络速度慢和功耗大的问题,本文提出了一种卷积神经网络加速系统。首先对卷积神经网络进行感知量化,得到8比特的权重、特征值和量化参数。采用Cortex-M3作为处理器设计片上系统,大大降低了功耗。本设计在Artix-7 Xc7a200T上实现了LeNet-5。通过MNIST数据集,实验结果表明本设计保持了准确性,降低了功耗。
猜你喜欢
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
北京航空航天大学学报(2022年7期)2022-08-06
北京航空航天大学学报(2021年9期)2021-11-02
少先队活动(2021年6期)2021-07-22
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
个人电脑(2016年12期)2017-02-13
电子制作(2016年19期)2016-08-24
电源技术(2015年11期)2015-08-22
