
面向位置聚合的泛在地图信息分类模型
2021-06-29 00:28:38王光霞田江鹏
测绘学报 2021年6期
王 思,王光霞,田江鹏
信息工程大学地理空间信息学院,河南 郑州 450052
信息分类是人类思维所固有的一种活动,是人们日常生活中用以认识、区别和判断事物的一种逻辑方法[1]。人们通过对现有的信息和知识的提取、组织、分类和管理之后才能对信息进行有效的认识和使用。地图学和GIS中,地理信息按照一定的原则和方法进行分类和编码,建立了特定的通用或专用地理信息分类体系,以便于地理信息的存储、检索、管理、分析与共享。地理信息分类是地理数据得以综合分析和共享利用的重要基础。
在ICT和大数据技术的推动下,地图学发展迎来了空前的机遇与挑战[2-3]。伴随着信息量的急剧增长,地理信息逐渐表现出实时性强、空间覆盖面广、来源多、体量大、复杂度高、碎片化和不确定性等特点,呈现出“时空泛在”[4]的新质特征。地图作为表达和传输地理信息的重要工具,也开始呈现“泛在化”的发展趋势[5-6]。与传统地图类似,泛在地图可认为是在地图投影、制图综合和地图可视化支撑下对地理对象、现象、过程等从现实空间到地图空间的映射[7],具备传输和表达地理信息的功能[2]。所不同的是,泛在地图对传统地图进行了进一步的拓展,表现出更加包罗万象的内涵和特征。特别是在时空大数据[3]的背景下,更加强调其信息价值大、复杂但稀疏[8]、实时性强等特点。因而,如何在信息层面抽象泛在地图的本质特征,抓取泛在地图的信息维度,实现泛在地图信息的科学分类和管理,已经成为地图学面向泛在化发展而衍生的新问题。
构建泛在地图信息的分类体系,旨在为如何认识和理解泛在地图,以及如何管理和使用泛在地图提供依据与规范。泛在地图信息的大数据特点使得其难以直接套用传统地理信息分类方法,需要对泛在地图信息的特征、分类模型等基本问题进行重新思考。针对这一需求,本文提出一种面向位置聚合的泛在地图分类模型,希冀以此来探究泛在地图的信息维度本征。
1 现状分析
地理信息分类在一定时期内已经形成了相对稳定的多级分类标志体系和模型[9],并作为一种概念模型长期以来支撑了地图和GIS的发展。传统地理信息分类主要依托专家的知识和经验构建地理信息分类的原则、方法和标准规范,采用规范的术语和清晰的层级关系描述地理要素,属于专家分类法(taxonomy)的范畴。在诸如《GB/T13923—2006基础地理信息要素分类与代码》等标准形成之后,分类问题逐渐面向语义一致性方向发展,出现了基于本体的地理信息分类[10-11]和基于形式语义的地理信息分类[12]等研究,旨在达成不同领域分类体系之间的共享与互操作。从广义的信息学视角来看,地理信息分类可认为是信息分类的一个具例,但将地理信息分类与信息学分类进行比较分析,可以发现地理信息分类存在下述不足:
(1) 面向网络地理信息资源的分类研究不足。随着网络技术的发展,带有时空标识的泛在网络资源已经将地理信息由传统的地理空间全面扩展至社会人文空间,物理域到认知域的扩展使得专家分类法难以适应。突破分类受控词只能由专家产生的限制,基于用户协作式创建的标签实现网络资源分类的大众分类法(folksonomy)[13],成为海量网络信息快速分类的主流方法。虽然Web地图学和WebGIS已经取得长足的进步,但本质上仍沿用的是传统地图信息的分类模型,缺乏真正面向网络信息资源的地图信息分类模型与方法的研究。
(2) 缺乏兼容人机各自优势的分类模型设计。大众分类法依赖于机器学习的自动分类或者带有专家验证的自动分类。而机器分类通常有两类任务:①构建特定的类别层次;②指定待分类对象在类别层次中所属的类别[14]。这些任务的实现均依赖于算法抽取的特征。例如,ImageNet借助于图像的特征标注,已经给出了涉及地图在内的不同领域的图像数据分类方案[15]。然而,算法语义与人类语义之间存在鸿沟,机器分类算法获得的类别层次和分类效果与人的分类结果之间存在一定的差异性。这一问题虽然已经得到部分学者的关注,例如文献[16]将影像光谱特征语义词汇与地图要素分类体系进行结合的研究,但总体上仍缺乏兼容人机各自优势的分类模型的设计。
2 分类模型
2.1 基本认识约定
(1) 泛在地图信息:泛在信息的一种类型。泛在信息通常表现为文本、图表、图像、音频、视频和地图等模态,泛在地图信息即以泛地图[6]形式而存在的信息类型。泛在地图信息也是专题地图信息的一种,存在于泛在网络中用以表示自然和社会人文环境要素的地图,包括专题内容要素、表示方式和地图说明信息。
(2) 位置:特指一种扩展的“位置”概念。地图信息整体上可分为时间、空间和属性[3]3个维度,传统上的位置是指空间中的坐标或区域。在时空大数据背景下,单纯以空间位置为基本框架来组织和关联信息,并不能完全满足全息制图和表达[17]的需求。位置需由空间维扩展到时间维和语义维,突破笛卡儿几何空间至多要素相统一的高维语义空间,形成时空和语义为整体的描述能力。对位置进行拓展后,尤其到语义维,能够突破传统位置计算的“几何算法”属性,可衍化出时间位置、空间位置和语义位置[18]等更为细致的位置分类,共同支撑高维语义空间中的概念、实体及其关系的结构化描述。
(3) 位置聚合:面向时空泛在信息的信息聚合[19-20]模式。泛在信息的复杂稀疏性特点,与越来越精准化、个性化的用户需求之间形成了矛盾。为解决这一问题,一方面可通过对离散分布、异构无序的多类型“信息碎片”进行筛选、关联、组织、汇集与呈现[21];另一方面,可采用扩展的位置为框架组织和关联信息,以全面反映位置本身及其相关的事物或事件的各种属性。因此,位置聚合是一种以时空泛在信息为对象,以位置为框架关联信息碎片,以构建专题化地理场景[22]为目标的时空泛在信息应用新模式。
(4) 分类模型:特指用于指导泛在地图信息分类的理论模型。分类的两类主要任务[14],使得当前存在构建类别层次的分类模型和对象类别划分的分类模型;同时,由于研究的层次需求,存在理论模型、数据模型和算法模型等区别。本文瞄准地理信息分类研究中存在的两点不足,面向位置聚合应用需求,试图从理论的层次探讨泛在地图信息的分类问题,因此分类模型是一种侧重类别层次建模(即泛在地图信息分类分级)的理论模型。
2.2 分类需求与研究思路
泛在地图信息分类既需要延续传统地理信息分类的一般原则和要求,也需要顾及泛在地图的信息维度特征。归纳起来,需要满足下述需求:①支撑位置聚合应用——分类模型旨在建立泛在地图信息的层级化组织结构,实现泛在地图信息作为一种“大数据”的管理,进而为位置聚合提供信息索引作用;②揭示微内容——泛在地图信息的稀疏性特点,使得有效揭示和描述其中蕴含的“细粒度”信息碎片成为突出需求,因此其分类应有助于信息碎片的描述;③符合认知结构——泛在地图信息分类分级结构中,类别之间应有明确、规范和清晰的语义关系,符合人们对地理事物的认知结构;④自动化分类能力——传统地理信息分类方案制定和分类实施均由人完成,费时费力且更新升级周期长,泛在地图信息分类需要一种数据驱动、自由灵活、快速迭代的自动化分类方法。
泛在地图信息分类需求,决定了其分类需要从模型和方法上进行改进和创新。基于现有的研究成果,本文的试图从以下两个方面进行改进:
2.2.1 结合专家分类法和大众分类法的各自优点
专家分类法可以认为是自顶向下的分类模式,而大众分类法则是立足资源标注的自下而上的分类模式,二者各具优劣,具有互补融合的特点[23]。泛在地图信息分类不仅需要延续传统地理信息分类的层级化结构、使用受控词描述层级语义、符合人的认知习惯等优点,也需要吸纳网络信息资源分类的细粒度语义描述、成本低、周期短、自动化程度高等优点。表1展示了泛在地图信息分类的具体特点。

表1 泛在地图信息分类需融合传统地理信息分类和网络信息资源分类的各自优点
2.2.2 耦合认知规律和数据驱动的模型设计
人工分类和机器分类有着各自的优点,人类自古以来就进化出对环境事物的抽象和分类的能力,能够轻松完成概念化、关系推理和模式识别等任务,而机器则擅长于快速、高精度的数据处理。因此,较为可行的路线是设计耦合人机各自优势的分类模型,即一方面自上而下,扩展经典地理信息分类中细粒度语义信息的描述能力;另一方面则是自下而上,基于现有机器分类模型在数据和特征层面的算力,拓展其在概念、语义和知识层面的建模能力。
这种设计理念本质上符合“视觉序列→视觉描述↔知识模式↔认知表达”这一人类理解地图的认知原理[24],也是缩短算法语义与人类语义之间的鸿沟的有益尝试。因此,耦合人机各自优势的分类模型,就是将之前全部由人类认知系统完成的工作,现在部分交由机器去完成——将泛在地图的数据组织管理、特征抽取、聚类分析等工作交由算法去实现,而人则是在概念术语、分类模式、知识推理等更高层次进行约束。
2.3 模型设计
基于上述设计理念,本文提出了由“实例层→特征层↔维度层↔主题层”4个层次构成的泛在地图信息分类模型,如图1所示。
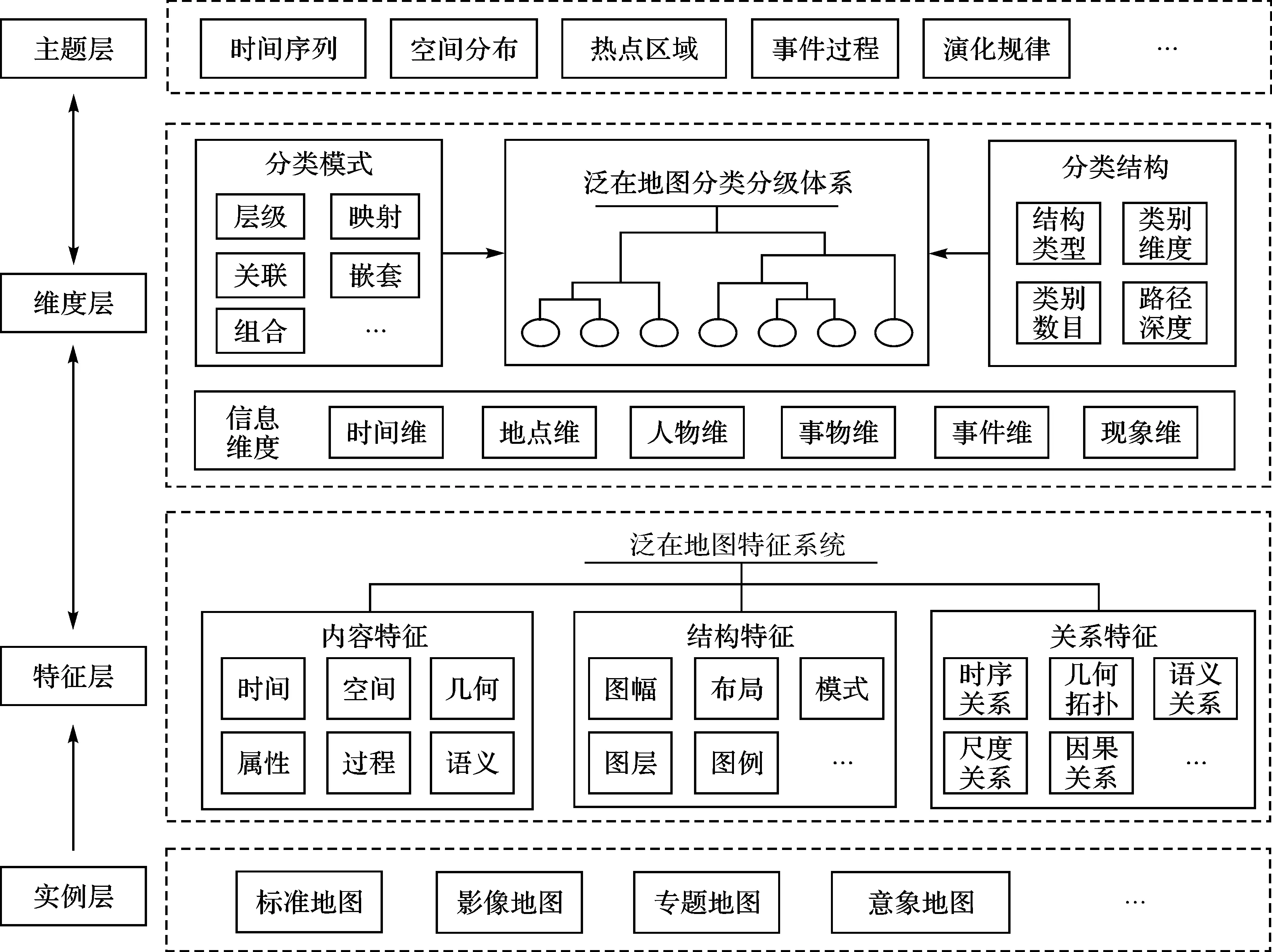
图1 面向位置聚合的泛在地图信息分类模型Fig.1 Classification model of ubiquitous map information facing location-based aggregation
2.3.1 实例层
实例层涵盖了不同类型的泛在地图实例,是分类的数据基础。根据地图的“泛化”程度,可以将标准地图、矢量地图、影像地图、专题地图和意象地图(例如旅游心象地图)等实例纳入泛在地图的分类范围之内。
2.3.2 特征层
特征层描述了能够从泛在地图中抽取的信息碎片的类型和值。泛在地图的构成和形式较为灵活多样,图名、图例和要素内容等构成元素均可能存在缺省情况,因此特征层的核心任务是建立泛在地图特征系统,以支撑不同类型泛在地图的统一特征抽取与要素描述。借鉴适用于描述复杂地理数据的地理信息六要素[25]理念,结合泛在地图自身特点,本文从内容特征、结构特征和关系特征3个方面构建泛在地图的特征系统。①内容特征——侧重描述地图中所表达的信息,例如地理对象或现象发生的时间和空间节点(时间定位、空间定位),地理对象的组成和演化结构(几何形态),地理对象和现象的固有属性(属性特征)、地理现象的发生与演化(演化过程)以及基于人类认知的地理特征(语义描述)。②结构特征——侧重描述地图的元数据或幅面构成,例如图名、副图名、出版单位、出版时间、图廓等,可以抽象地概括为图幅、布局、模式、图层、图例等部分。③关系特征——侧重描述特征之间存在的定性或定量的关系。泛在地图需要显式地抽取和描述这些基本关系,并作为特征记录下来,例如时序关系(例如正序、逆序、插序)、拓扑关系(例如九元组模型)、语义关系(例如部分整体关系、上下义关系)、尺度关系和因果关系等。
2.3.3 维度层
借鉴文献[6]的观点,在分类层级系统中,一个维度实质上就是它的一个侧面,同一维度下的具体维度值形成了视角面,不同维度值按照一定规则关联并叠加组合构成了泛在地图信息的一个种类。因此,维度是泛在地图信息的基本量,一个维度实际上代表了信息特征的一个侧面,能够使用不同细化程度的特征予以表示。鉴于泛在地图信息的社会属性和大数据特点,由时空信息X和属性信息Z构成最简二元组〈X,Z〉的地理信息描述范式[26],已经难以覆盖泛在信息范畴。因此,引入社会学领域信息分类[27]思想,并借鉴场景学[22]理论,宏观上将泛在信息划分为时间维、地点维、人物维、事物维、事件维和现象维6个维度。信息维度的划分来源于社会学的归纳,在认知层面界定了地图信息的不同归属,是信息层面的范畴划定,理论上任何粒度或类型的泛在地图信息均可以划分到此6个信息维度之中。
信息维度的划分,为不同特征值提供了类型标注,形成了〈特征,维度〉最简二元标注单位。分类分级体系通常是一个层次化、结构化的多维层级系统。因此以〈特征,维度〉标注单位为基本信息单元构建泛在地图信息分类分级,具有以下优势。一是最简二元标注单位能够让分类分级体系具备多维特征描述特点,这是实现由特征数据(算法语义)到分类分级(人类语义)之间衔接的关键。二是采用最简二元标注单位标注的泛在地图信息,能够与扩展的位置(时间位置、空间位置和语义位置等)之间产生深层次的关联性:时间维信息与时间位置是同质的,地点维信息和空间位置是同质的,人物维、事物维、事件维和现象维信息适宜于使用语义位置进行关联,这种关联性是实现信息和位置之间进行关联和聚合计算的基础。
基于信息维度,可通过设置不同分类模式、分类结构参数等构建泛在地图信息的分类分级体系。分类分级体系包含了谱系、模式(schema)和特征等部分。谱系体现了层级化结构,模式体现了受控词和信息维度之间的关联关系,而特征则映射了细粒度地图信息内容。
2.3.4 主题层
主题层描述了面向不同聚合主题的分类需求,例如按照时间序列、空间分布、事件过程、演化规律等主题进行分类。
概括而言,该模型立足泛在地图信息自身特点,以不同的位置聚合主题为牵引,通过对地图实例中抽取的信息碎片进行信息维度分析和聚类,构建数据驱动、全面系统、精确合理的泛在地图信息分类分级体系,为实现海量、多源异构泛在地图的管理、聚类和分析等提供认知结构保证。本质上,该分类模型将传统地理信息分类的“实例→维度↔主题”模式扩展为“实例→特征↔维度↔主题”模式,特征层的扩展为机器提供了细粒度语义信息的描述能力,同时也能够保持经典地理信息分类模型的层级化认知结构,这种扩展是满足泛在地图信息分类需求的根本原因。
3 模型验证
3.1 验证方法
为了验证泛在地图信息分类模型,本文设计并实现了一种泛在地图信息分类建模方法,技术路线如下:①输入泛在地图数据集;②主题特征标注——面向位置聚合主题需求,以〈特征,维度〉为基本单元抽取泛在地图中的特征信息并标注信息维度;③特征频率矩阵构建——将不同信息维度的非结构化特征数据映射到统一的向量空间中;④层次聚类——基于特征频率矩阵进行层次聚类计算,建立泛在地图信息分类分级体系;⑤输出分类分级体系。
3.1.1 主题特征标注
主题特征标注旨在从泛在地图中抽取出与位置聚合主题相关的特征信息,侧重解决两个问题:
(1) 特征描述框架,即抽取和标注哪些信息。根据分类模型,为了实现非结构化泛在地图的统一解构,可从特征系统和信息维度两个方面建立泛在地图特征描述框架,并抽取获得〈特征,维度〉基本标注单元。以图2所示的“蔷薇”台风路径概率预报图的标注为例。该图的结构包括图名、附图名、出版单位、发布时间和图例等,不同的结构可以抽取不同的特征,例如在图名结构中可以抽取得到〈今年,时间维〉、〈未来48 h,时间维〉、〈“蔷薇”台风,事件维〉、〈路径概率预报图,事物维〉等特征。内容结构中主要包括底图和专题图层,例如在专题图层中,可以抽取得到〈8月9日05时,时间维〉、〈概率范围,地点维〉、〈热带风暴,现象维〉、〈蔷薇,事件维〉等不同特征值。
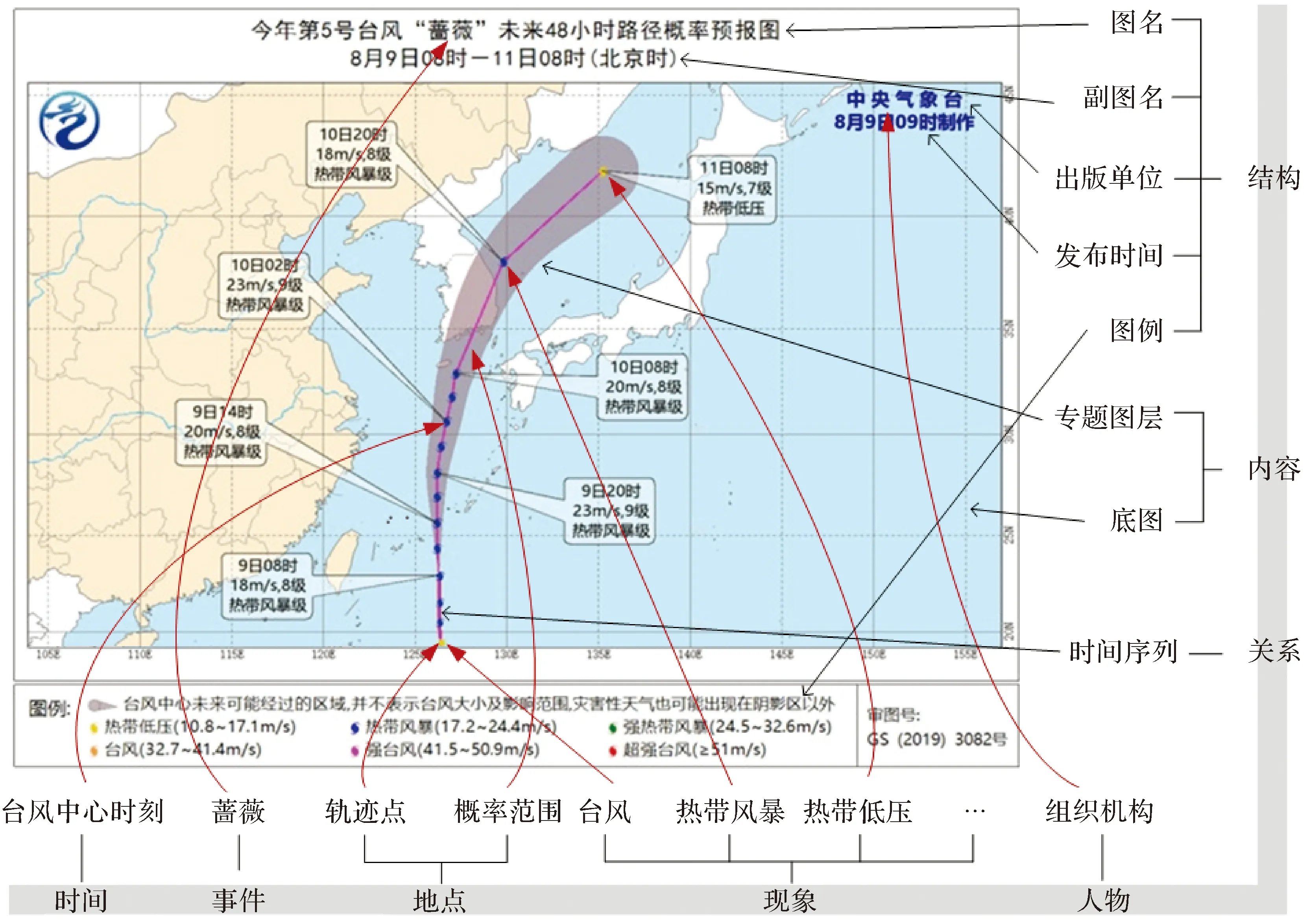
注:本图仅作地图样图展示,不涉及国家版图相关问题。图2 泛在地图解构与特征抽取示例Fig.2 Deconstruction and feature extraction of ubiquitous map
(2) 主题信息过滤。基于特征描述框架抽取的特征可能覆盖不同的特征结构和信息维。然而这些特征与位置聚合主题的相关性不尽相同,其能够发挥出的作用有大有小,部分作用小的特征甚至无法反映地图的核心信息,在一定程度上会干扰后续地图信息分类的准确性。因此,在具体的抽取实现过程中,需顾及位置聚合的主题需求,选取出能最能代表地图主题特色的那部分特征,并作为泛在地图信息维度抽象的数据基础。
3.1.2 特征频率矩阵构建
泛在地图中抽取的特征,通常是由符号、文字、数字等构成,但这些特征信息通常不能直接参与分类体系构建,需要通过特定的运算转换形成统一向量空间的表达,以便于后续的聚类计算。特征频率矩阵是一种特征的向量空间表示,即每个特征项在向量空间某一维度上都采用特定的数值表示,使得符号、文字、数字等形式的特征值能够统一转化为向量表示。特征频率矩阵构建的总体思路如图3所示。
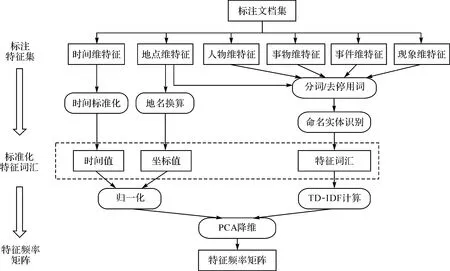
图3 特征频率矩阵构建流程Fig.3 Construction process of feature frequency matrix
(1) 对特征值进行规范化处理。时间类特征值通常表现出相对性和模糊性特点,需要将相对时间、时间省略现象等表示为统一的、标准的表达形式。参照时间规范化[28]的方法进行转换,例如“8月9日05时”可转换为数值“2020-08-09 T05:00:00”。地点类特征值通常表现为坐标形式和地名形式,具有多级别性、相对性和模糊性等特点。特别对于地名值,一种方法是采用地名解析和换算方法,转换为坐标数值;另一种方法则是针对无法完成坐标换算的情形,可将其作为自然语言文本进行处理。对于人物、事物、事件和现象类特征值,由于它们通常表现为自然语言描述形式,可采取自然语言处理中的词袋[29]模型表示,并采取分词/去停用词、命名实体识别等技术,计算得到特征词汇集合。
(2) 生成特征频率矩阵。对时间值和坐标值采用归一化、特征词汇采用TF-IDF[30]计算方法,获得标注文档的全部特征频率矩阵。初步获得的特征频率矩阵通常具有高维、稀疏的特点,为提高后续分类计算效率,还需对其进行降维计算。降维是在保证向量空间基本特性不变的前提下,将高维度的特征空间映射到一个较低维度的空间中。本文采用主元分析(PCA)[31]降维计算方法,获得最后的低维度的特征频率矩阵。
3.1.3 基于层聚类分析的分类分级体系生成
以特征频率矩阵为基础,可以通过聚类分析将特征区分为不同的类别,不同的类别又可进一步通过聚类分析区分为更高层次的类别,如此不断迭代收敛,最终可获得基于特征值的泛在地图信息分类分级体系。
本文基于BIRCH算法[32]实现分类维度聚类,并使用LDA(latent Dirichlet allocation)算法对每一个聚类簇进行主题提取,算法描述如下。
输入:特征频率矩阵weight,特征字典dict,距离阈值T,分支数量约束B
输出:带有节点主题标签的CFTree
(1) 将特征频率矩阵weight转化为向量{v1,v2,…,vn}
(2) 初始化CFTree,使其根节点为一个空的node
(3) forviin {v1,v2,…,vn}
寻找CFTree中与vi距离最近的节点node(k)以及距离d(i,k)
ifd(i,k)≤T
将vi插入到节点node(k)中,计算node(k)节点数num(k)
if num (k)≤B
更新node(k)节点到根节点路径上的所有结点的(N,LS,SS,TAG)值
else
分裂node(k)为两个新节点node(k1)和node(k2),按照距离重新分配node(k)中的向量
更新node(k1)和node(k2)到根节点路径上的所有结点(N,LS,SS,TAG)值
else
创建一个新的节点node并插入node(k)之中,将vi插入到节点node中
更新node节点到根节点路径上的所有结点的(N,LS,SS,TAG)值
(4) 遍历CFTree所有节点,基于TAG值自底向上对每个节点使用LDA算法获得主题标签
(5) 打印输出CFTree
BIRCH算法是典型的聚类算法之一,能够通过拆分特征向量构建树状层次结构,较好地适应本文的聚类需求。根据BIRCH算法原理,本文对聚类特征树(cluster feature tree,CFTree)进行了改进设计,将树中每一个节点由(N,LS,SS)三元组扩展为(N,LS,SS,TAG)四元组,使得特征个数N、特征之和LS以及特征的平方和SS 3个参数用于树的构建,TAG记录当前节点包含的特征值,用于当前节点主题的计算。
3.2 试验与分析
3.2.1 数据说明
地图的泛在性体现在数据来源、内容信息和表达形式等方面。为了验证分类模型的可行性,本文围绕地图内容信息的泛在性,通过网络爬虫构建了一个以各类图像格式为主的泛地图数据集。数据集包含地图共计1605幅,表2按照分类模型的实例层对所收集的地图数据进行了归纳,并结合地图实例进行了说明。数据集的信息内容涉及行政区划、经济生产、交通出行、人文旅游、自然资源、日常生活等多个方面,特别是手绘地图、语义地图和知识地图等这类非标准化但广泛存在于社会媒介中的地图实例的纳入,力图体现对地理空间和社会人文空间的覆盖。

表2 试验数据说明和统计
3.2.2 分类体系生成
为了验证面向特定主题的地图数据特征标注和分类分级建模方法的可行性,并展现建模过程细节,从专题地图数据集中按照气象主题选取的部分地图实例,涵盖台风事件、大风/降水预报、干旱、火险等专题内容进行试验。图4为按照分类建模的流程,取距离阈值T=1.8,分支数量约束因子B=8的分类体系效果图。
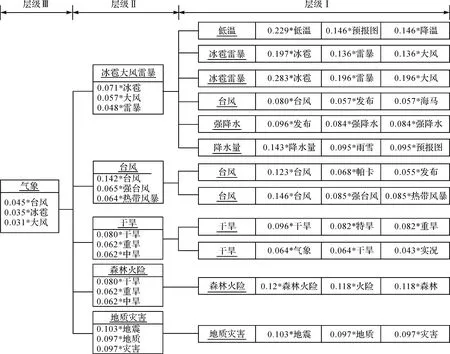
图4 气象主题分类体系生成效果Fig.4 Generation result of the meteorological theme classification system
分类体系展现了整体的分类结构和分类节点的细节信息。本试验结果共分为3个层级:层级Ⅰ为一级聚类节点,层级Ⅱ为二级聚类节点,层级Ⅲ为三级聚类节点。每一个节点中均包含了LDA算法获得的按照概率排序的主题特征,例如“0.045*台风”表示台风主题的概率为0.045;带有下划线的是专家分类受控词,通过主题特征词汇匹配获得。
定义准确率(P)=分类簇中正确的地图数/分类簇中地图总数,召回率(R)=分类簇中正确的地图数/分类簇中应有的地图数,F1=2PR/(P+R)。对不同层级的分类结果进行评价,计算每一分类层级准确率、召回率和F1值的均值,结果见表3。
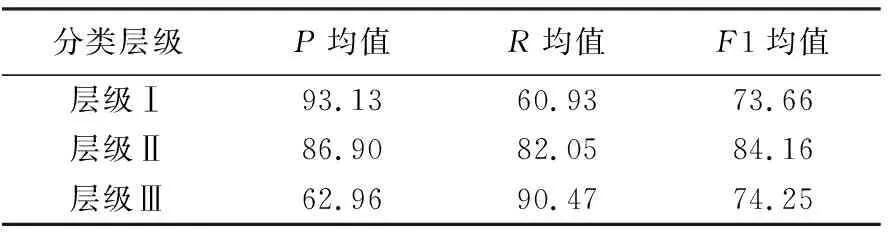
表3 不同分类层级的评测
试验结果表明:①层级Ⅰ为直接分类簇,93.13%的P均值表明地图实例得到较好的分类,但层级Ⅰ的R均值不高,其原因在于同一类型信息易被划分为多个分类簇,例如台风、干旱、冰雹雷暴分类簇;②随着分类层级的递增,P均值整体下降表明聚类性能逐级递减,但R均值整体上升表明分类簇的语义综合度得到一定的保证;③所有分类层级的F1均值均保持相对稳定水平,表明试验能够取得一定的分类分级效果,但仍存在进一步优化和提高的空间。
4 结 语
本文从泛在地图的位置聚合应用需求出发,提出了一种泛在地图信息分类模型,并通过相关试验进行了验证。该分类模型本质上是一种认知规律约束下数据驱动的分类体系自动建模,对泛在地图数据分类、管理、分析和应用等具有参考价值。
本文的研究意义包括2个方面。一是能够推进从海量泛在地图数据中挖掘地理信息分类体系的自动化处理水平;二是能够进一步改变地理信息分类模式,特征层将算法语义和人类语义有效衔接起来,使得传统上由人类专家完成的认知分类模式,变为人机协作、甚至完全智能化的地理信息分类模式。
本文的局限性包括3个方面。一是特征抽取的有效性。精准、快速挖掘泛在地图中的信息块,并重建信息块之间的关联关系,需要进一步构建泛在地图的理解模型,以及基于深度学习算法的高效自动标注方法。二是信息维度聚类算法的参数调优。例如BIRCH算法的参数B和T,对聚类的结构、分类粒度和收敛性等均具有重要影响,B和T参数如何调优并能够解释其实际意义,特别是对于不同量级和规模的数据集,乃是需要进一步研究的问题。三是分类结果的有效性。验证方法虽然能够得到分类分级结构,但相较于传统地理信息的分类受控词,其语义精准度还需进一步提高。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
开放教育研究(2020年2期)2020-03-31 01:54:14
中华诗词(2019年7期)2019-11-25 01:43:00
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
灯与照明(2016年4期)2016-06-05 09:01:45
现代语文(2016年21期)2016-05-25 13:13:44
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:24
大连民族大学学报(2015年2期)2015-02-27 08:28:11
